













Сегодняшние большие виртуальные инфраструктуры генерируют огромное количество данных. Это приводит к увеличению объема резервных данных и расходов на инфраструктуру резервного хранения, включая хранилища и их обслуживание. По этой причине сетевые администраторы ищут способы экономии места на носителях при создании частых резервных копий важных машин и приложений.
Одной из широко используемых техник является дедупликация резервных данных. В этом блоге рассматривается, что такое дедупликация данных, типы дедупликации и сценарии использования с акцентом на резервные копии.
Что такое дедупликация?
Дедупликация данных – это технология оптимизации объема хранения. Она включает в себя чтение исходных данных и данных, уже находящихся в хранилище, чтобы передавать или сохранять только уникальные блоки данных. Ссылки на дубликаты данных сохраняются. Используя эту технологию для избегания дубликатов на томе, можно экономить место на диске и снижать накладные расходы на хранение.
Истоки дедупликации данных
Предшественниками дедупликации данных являются алгоритмы сжатия LZ77 и LZ78, введенные соответственно в 1977 и 1978 годах. Они заключаются в замене повторяющихся последовательностей данных ссылками на оригинальные.
Этот концепт повлиял на другие популярные методы сжатия. Самым известным из них является DEFLATE, который используется в форматах изображений PNG и файлов ZIP. Теперь давайте посмотрим, как работает дедупликация с резервными копиями ВМ и как именно она помогает экономить место на носителях и снижать расходы на инфраструктуру.
Что такое дедупликация в резервном копировании?
Во время резервного копирования дедупликация данных проверяет идентичные блоки данных между исходным хранилищем и целевым резервным хранилищем. Дубликаты не копируются, а создается ссылка или указатель на существующие блоки данных в целевом резервном хранилище.
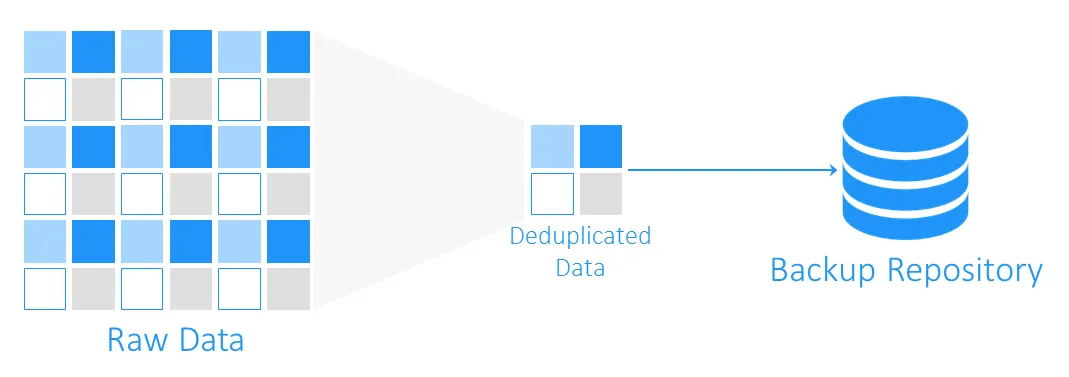
На сколько места можно сэкономить с помощью дедупликации данных?
Чтобы понять, сколько места для хранения можно выиграть с помощью дедупликации, рассмотрим пример. Минимальные системные требования для установки Windows Server 2016 составляют не менее 32 ГБ свободного дискового пространства. Если у вас есть десять виртуальных машин, работающих под этой ОС, резервные копии составят как минимум 320 ГБ, и это только чистая операционная система без каких-либо приложений или баз данных.
Скорее всего, если вам нужно развернуть более одной виртуальной машины (ВМ) с той же системой, вы будете использовать шаблон, и это означает, что изначально у вас будет десять идентичных машин. И это также означает, что вы получите 10 наборов дублирующихся блоков данных. В этом примере у вас будет коэффициент экономии места для хранения 10:1. В целом сбережения в диапазоне от 5:1 до 10:1 считаются хорошими.
Коэффициент дедупликации данных
Коэффициент дедупликации данных – это метрика, используемая для измерения размера исходных данных по сравнению с размером данных после удаления избыточных частей. Эта метрика позволяет оценить эффективность процесса дедупликации данных. Для расчета значения необходимо разделить объем данных до дедупликации на объем хранилища, занимаемого этими данными после дедупликации.
Например, коэффициент дедупликации 5:1 означает, что вы можете хранить в памяти резервного копирования в пять раз больше данных, чем требуется для хранения тех же данных без дедупликации.
Вы должны определить коэффициент дедупликации и сокращение места хранения. Эти два параметра иногда путаются. Коэффициенты дедупликации не изменяются пропорционально к выгодам от сокращения данных, так как закон убывающей отдачи обязательно начнет действовать за определенный момент. См. график ниже.
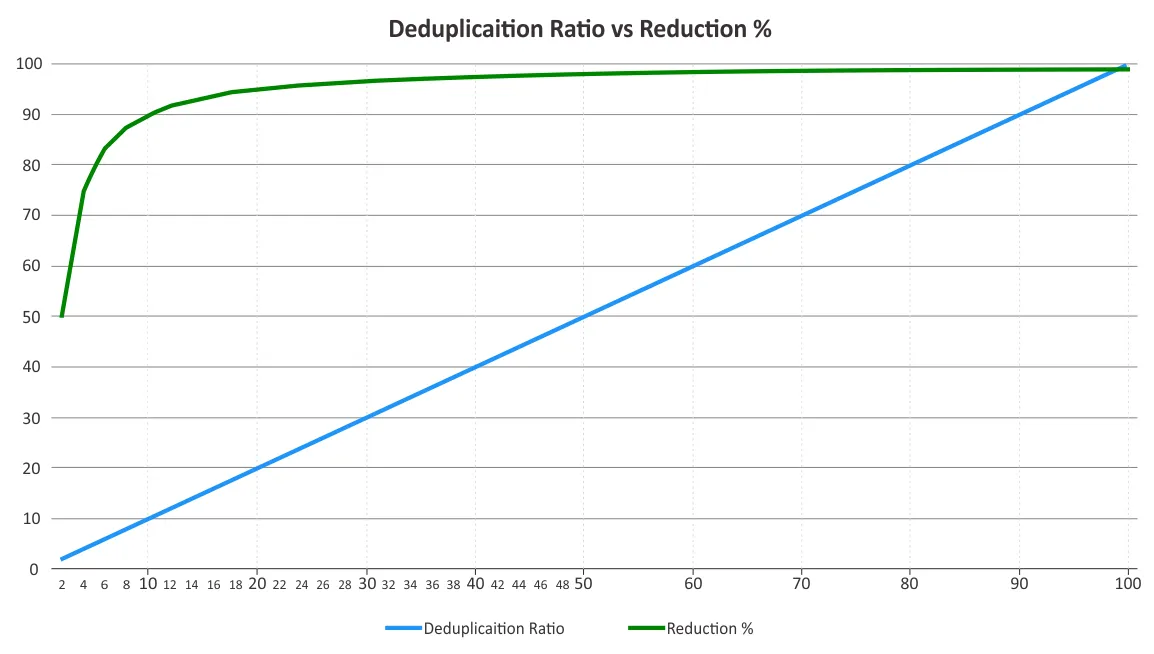
Это означает, что более низкие коэффициенты могут принести более значительные сбережения, чем более высокие. Например, коэффициент дедупликации 50:1 не в пять раз лучше, чем коэффициент 10:1. Коэффициент 10:1 обеспечивает сокращение занимаемого места хранения на 90%, в то время как коэффициент 50:1 увеличивает это значение до 98%, учитывая, что большая часть избыточности уже была устранена. Для получения дополнительной информации о том, как рассчитываются эти проценты, вы можете посмотреть документ Ассоциации хранения данных в сети (SNIA) о дедупликации данных.
Факторы, влияющие на эффективность дедупликации данных
Трудно предсказать эффективность сжатия данных до тех пор, пока данные фактически не будут дедуплицированы из-за нескольких факторов. Вот некоторые из факторов, которые влияют на сокращение данных при использовании дедупликации:
- Типы и политики резервного копирования данных. Дедупликация для полных резервных копий более эффективна, чем для инкрементных или дифференциальных резервных копий.
- Скорость изменений. Если нужно сделать много изменений данных для резервного копирования, то коэффициент дедупликации ниже.
- Настройки хранения. Чем дольше вы храните резервные копии данных в хранилище резервного копирования, тем более эффективной может быть дедупликация данных на этом хранилище.
- Тип данных. Дедупликация для файлов, в которых данные уже сжаты, таких как JPG, PNG, MPG, AVI, MP4, ZIP, RAR и т. д., неэффективна. То же самое относится к данным, богатым метаданными и зашифрованным данным. Типы данных, содержащие повторяющиеся части, лучше подходят для дедупликации.
- Объем данных. Дедупликация данных более эффективна для большого объема данных. Глобальная дедупликация может сэкономить больше места для хранения по сравнению с локальной дедупликацией.
Примечание: Локальная дедупликация работает на одном узле/устройстве диска. Глобальная дедупликация анализирует весь набор данных на всех узлах/устройствах диска для устранения дубликатов данных. Если у вас есть несколько узлов с локальной дедупликацией, включенной на каждом из них, дедупликация не будет так эффективна, как если бы она была включена глобальная дедупликация.
- Программное и аппаратное обеспечение. Комбинирование программных решений и аппаратного обеспечения для дедупликации может предложить лучшие коэффициенты дедупликации, чем только программное обеспечение. Например, решение по резервному копированию NAKIVO обеспечивает интеграцию с устройствами дедупликации HP StoreOnce, Dell EMC Data Domain и NEC HYDRAstor для коэффициентов дедупликации до 17:1.
Техники дедупликации резервного копирования
Техники дедупликации резервного копирования могут быть классифицированы на основе следующего:
- Где выполняется дедупликация данных
- Когда выполняется дедупликация
- Как выполняется дедупликация
Где выполняется дедупликация данных
Дедупликация резервного копирования может выполняться на стороне источника или на стороне назначения, и эти техники называются дедупликацией на стороне источника и дедупликацией на стороне назначения соответственно.
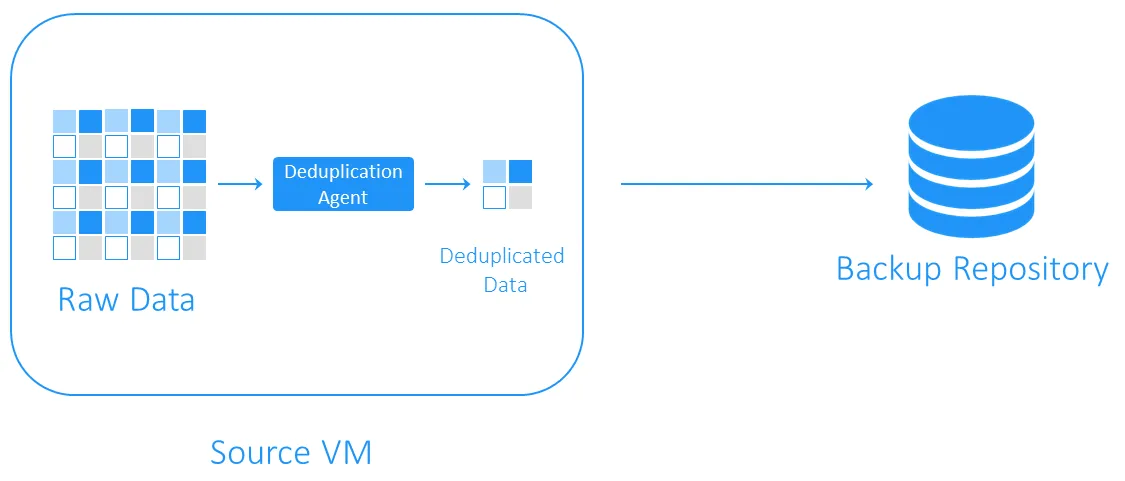
Дедупликация на стороне источника
Source-side deduplication уменьшает нагрузку на сеть, поскольку при резервном копировании передается меньше данных. Однако для этого требуется установка агента по удалению дубликатов на каждую виртуальную машину или на каждый хост. Недостатком является то, что source-side deduplication может замедлять работу виртуальных машин из-за вычислений, необходимых для идентификации дублирующихся блоков данных.
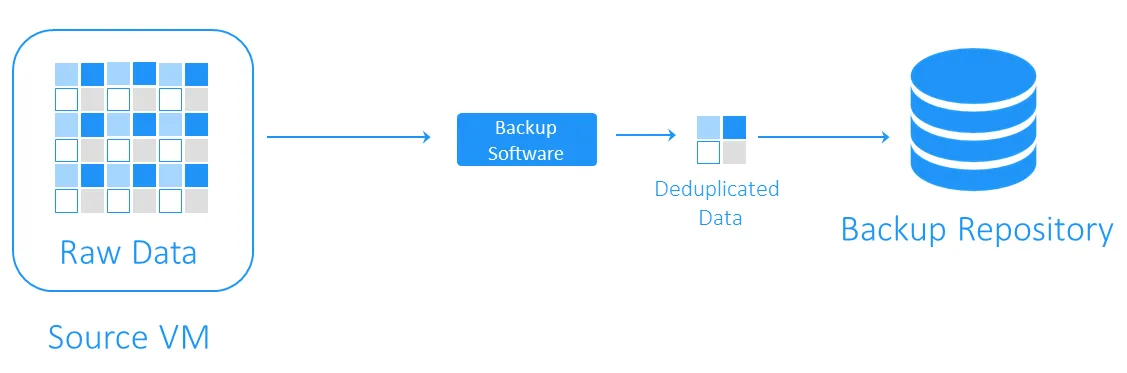
Target-side deduplication
Target-side deduplication сначала передает данные в хранилище резервных копий, а затем выполняет удаление дубликатов. Тяжелые вычислительные задачи выполняются программным обеспечением, отвечающим за удаление дубликатов.
Когда выполняется удаление дублирования данных
Резервное копирование с удалением дубликатов может быть инлайновым или послеобработчиком.
- Inline deduplication проверяет дубликаты данных перед записью их в хранилище резервных копий. Этот метод требует меньше места для хранения в хранилище резервных копий, так как он очищает поток данных резервного копирования от избыточностей, но при этом время резервного копирования увеличивается, так как инлайновое удаление дубликатов происходит во время выполнения задания резервного копирования.
- Post-processing deduplication обрабатывает данные после их записи в хранилище резервных копий. Очевидно, что этот подход требует больше свободного места в хранилище, но резервное копирование выполняется быстрее, и все необходимые операции выполняются после этого. Post-processing deduplication также называют асинхронным удалением дубликатов.
Как выполняется удаление дублирования данных
Наиболее распространенными методами идентификации дубликатов являются хэш-базированные и модифицированные хэш-базированные методы.
- С хэш-методом программа дедупликации делит данные на блоки фиксированной или переменной длины и вычисляет хэш для каждого из них с использованием криптографических алгоритмов, таких как MD5, SHA-1 или SHA-256. Каждый из этих методов дает уникальный отпечаток данных, поэтому блоки с похожими хэшами считаются идентичными. Недостатком этого метода является то, что для его выполнения может потребоваться значительные вычислительные ресурсы, особенно в случае больших резервных копий.
- В измененном хэш-методе используются более простые алгоритмы генерации хэшей, такие как CRC, которые производят всего 16 бит (по сравнению с 256 битами в SHA-256). Затем, если блоки имеют похожие хэши, они сравниваются байт-за-байтом. Если они полностью идентичны, блоки считаются одинаковыми. Этот метод немного медленнее, чем хэш-метод, но требует меньше вычислительных ресурсов.
Выбор программного обеспечения для дедупликации резервных копий
Дедупликация резервных копий – одно из наиболее популярных применений дедупликации. Тем не менее, для реализации этой технологии сокращения данных вам нужно иметь соответствующее программное обеспечение и оборудование для хранения.
NAKIVO Backup & Replication – это резервное решение, которое поддерживает использование глобальной постобработки целевой дедупликации с обнаружением измененных хэш-дубликатов. Вы также можете воспользоваться дедупликацией на стороне источника, интегрировав устройство дедупликации, такое как DELL EMC Data Domain с DD Boost, NEC HYDRAstor и HP StoreOnce с поддержкой Catalyst, с решением NAKIVO.
Source:
https://www.nakivo.com/blog/backup-deduplication-explained/