













今日の大規模な仮想インフラストラクチャは膨大な量のデータを生成します。これにより、バックアップデータの増加とバックアップストレージインフラストラクチャ(ストレージアプライアンスおよびそれらのメンテナンスを含む)への支出が増加します。そのため、ネットワーク管理者は、重要なマシンやアプリケーションの頻繁なバックアップを作成する際に、ストレージスペースを節約する方法を探しています。
広く利用されているテクニックの1つは、バックアップのデデュプリケーションです。このブログ記事では、データデデュプリケーションとは何か、デデュプリケーションの種類、およびバックアップに焦点を当てたユースケースについてカバーしています。
デデュプリケーションとは何ですか?
データデデュプリケーションは、ストレージ容量の最適化技術です。データデデュプリケーションは、ソースデータと既存のストレージデータを読み取り、ユニークなデータブロックのみを転送または保存することを含みます。重複データへの参照が維持されます。このテクノロジーを使用してボリューム内の重複を回避することで、ディスクスペースを節約し、ストレージオーバーヘッドを削減できます。
データデデュプリケーションの起源
データデデュプリケーションの前身は、1977年と1978年に導入されたLZ77およびLZ78圧縮アルゴリズムです。これらは、繰り返されるデータシーケンスを元のものへの参照で置き換えることを含みます。
このコンセプトは、他の人気のある圧縮方法にも影響を与えました。その中でも最もよく知られているのは、PNG画像やZIPファイル形式で使用されているDEFLATEです。さて、VMバックアップでのデデュプリケーションの動作と、ストレージスペースとインフラストラクチャに費やされるコストの節約に具体的にどのように役立つかを見てみましょう。
バックアップにおけるデデュプリケーションとは何ですか?
バックアップ中、データの重複排除は、ソースストレージとターゲットのバックアップリポジトリ間で同一のデータブロックを確認します。重複したデータはコピーされず、既存のデータブロックへの参照またはポインタがターゲットのバックアップストレージに作成されます。
データ重複排除はどれだけのスペースを節約できますか?
重複排除によってどれだけのストレージスペースが得られるかを理解するには、例を考えてみましょう。インストールに必要な最小システム要件Windows Server 2016は、少なくとも32 GBの空きディスクスペースが必要です。このOSを実行しているVMが10個ある場合、バックアップは少なくとも320 GBになります。これは、アプリケーションやデータベースがないクリーンなオペレーティングシステムだけです。
同じシステムを使用して複数の仮想マシン(VM)を展開する必要がある場合、テンプレートを使用する可能性が高いです。これは、最初に10個の同一のマシンを持つことを意味します。そして、これはまた、重複するデータブロックの10セットを取得することを意味します。この例では、10:1のストレージスペース節約率が得られます。一般的に、5:1から10:1の節約が良いと考えられています。
データ重複率
データの重複排除率は、元のデータサイズと、冗長な部分が削除された後のデータサイズとの比率を測定するために使用される指標です。この指標により、データの重複排除プロセスの効果を評価することができます。この値を計算するには、重複排除前のデータ量を、重複排除後のこのデータが消費するストレージスペースで割る必要があります。
たとえば、5:1の重複排除率は、重複排除せずに同じデータを保存するために必要なストレージスペースよりも、バックアップストレージに5倍のデータを保存できることを意味します。
あなたは、重複排除率とストレージスペースの削減を決定すべきです。これら2つのパラメータは、時々混同されます。重複排除率は、ある一定のポイントを超えると収益の減少の法則が適用されるため、データ削減の利点に比例して変化しません。以下のグラフを参照してください。
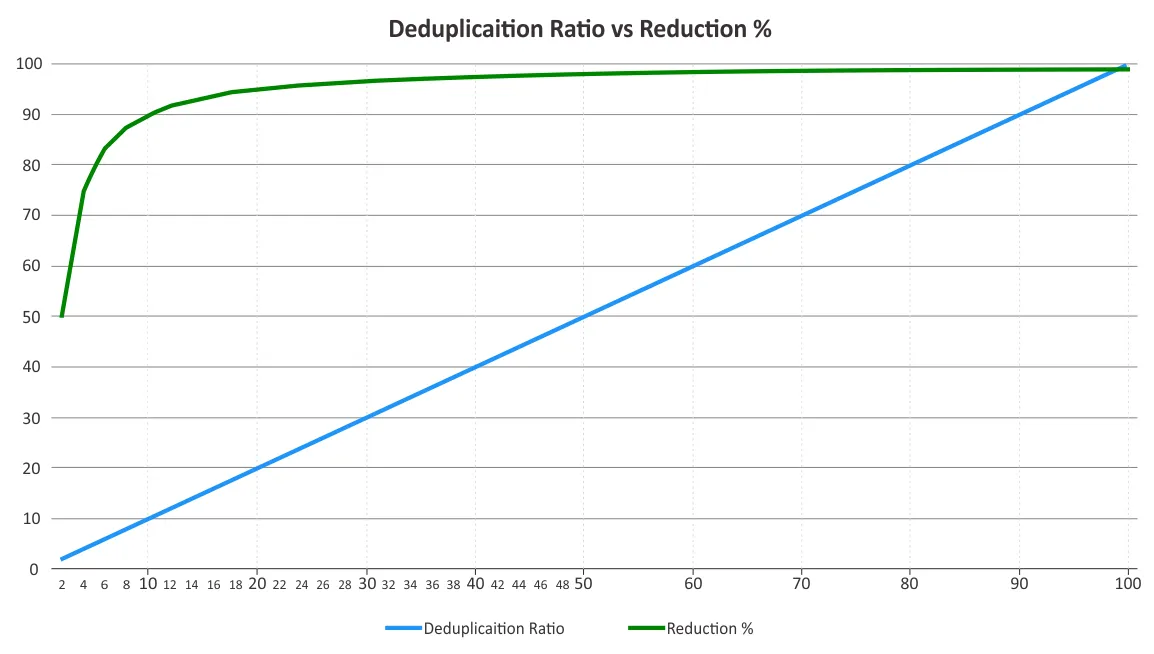
これは、低い比率の方が高い比率よりもより大きな節約をもたらす可能性があることを意味します。たとえば、50:1の重複排除率は、10:1の比率よりも5倍優れているわけではありません。10:1の比率は、消費されるストレージスペースを90%削減し、50:1の比率は、ほとんどの冗長性が既に排除されているため、この値を98%に増やします。これらのパーセンテージがどのように計算されるかの詳細については、Storage Networking Industry Association(SNIA)のデータ重複排除に関する文書をご覧ください。
データ重複排除効率に影響を与える要因
実際にデータが重複排除されるまで、いくつかの要因によりデータ削減効率を予測するのは難しいです。データ重複排除を使用する際にデータ削減に影響を与えるいくつかの要因は以下の通りです:
- データバックアップの種類とポリシー。フルバックアップに対するデータ重複排除は、増分バックアップや差分バックアップよりも効果的です。
- 変更率。バックアップするデータの変更が多い場合、データ重複排除率は低くなります。
- 保持設定。バックアップストレージにデータバックアップを保存する期間が長いほど、このストレージ上のデータの重複排除がより効果的になります。
- データタイプ。すでに圧縮されたデータを含むファイル(JPG、PNG、MPG、AVI、MP4、ZIP、RARなど)のデータ重複排除は効果的ではありません。メタデータ豊富なデータや暗号化されたデータにも同様です。繰り返し部分を含むデータタイプは、データ重複排除に適しています。
- データ範囲。データ重複排除はデータの広範囲に対してより効果的です。グローバル重複排除は、ローカル重複排除と比較してより多くのストレージスペースを節約できます。
注意: ローカルデデュプリケーションは単一のノード/ディスクデバイスで機能します。グローバルデデュプリケーションは、すべてのノード/ディスクデバイス上の全データセットを分析してデータの重複を排除します。各ノードにローカルデデュプリケーションが有効になっている複数のノードがある場合、それらに対してグローバルデデュプリケーションが有効になっている場合と比較して、デデュプリケーションは効率的ではありません。
- ソフトウェアとハードウェア。 ソフトウェアソリューションとデデュプリケーションハードウェアを組み合わせることで、ソフトウェア単体よりも優れたデデュプリケーション比を提供することができます。たとえば、NAKIVOのバックアップソリューションは、HP StoreOnce、Dell EMC Data Domain、NEC HYDRAstorデデュプリケーションアプライアンスとの統合を提供し、最大17:1のデデュプリケーション比を実現します。
バックアップデデュプリケーション技術
バックアップデデュプリケーション技術は、以下に基づいてカテゴリ分けすることができます:
- データデデュプリケーションが行われる場所
- デデュプリケーションが行われるタイミング
- デデュプリケーションが行われる方法
データデデュプリケーションが行われる場所
バックアップデデュプリケーションは、ソース側またはターゲット側で行うことができ、これらの技術はそれぞれソース側デデュプリケーションとターゲット側デデュプリケーションと呼ばれます。
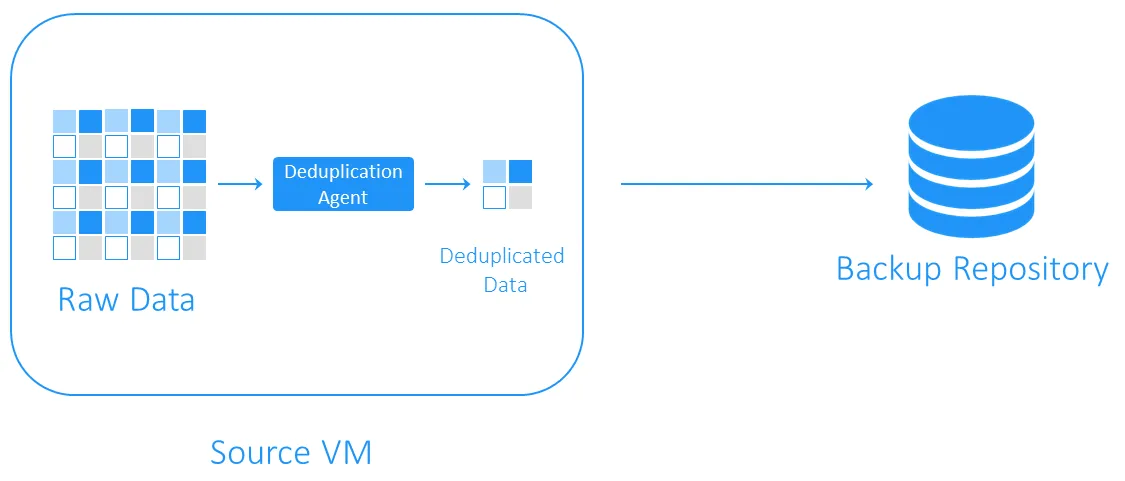
ソース側デデュプリケーション
ソース側の重複排除は、バックアップ中に転送されるデータが少なくなるため、ネットワーク負荷が減少します。しかし、それには各VMまたは各ホストに重複排除エージェントをインストールする必要があります。もう1つの欠点は、重複データブロックを特定するために必要な計算によってVMの速度が低下する可能性があることです。
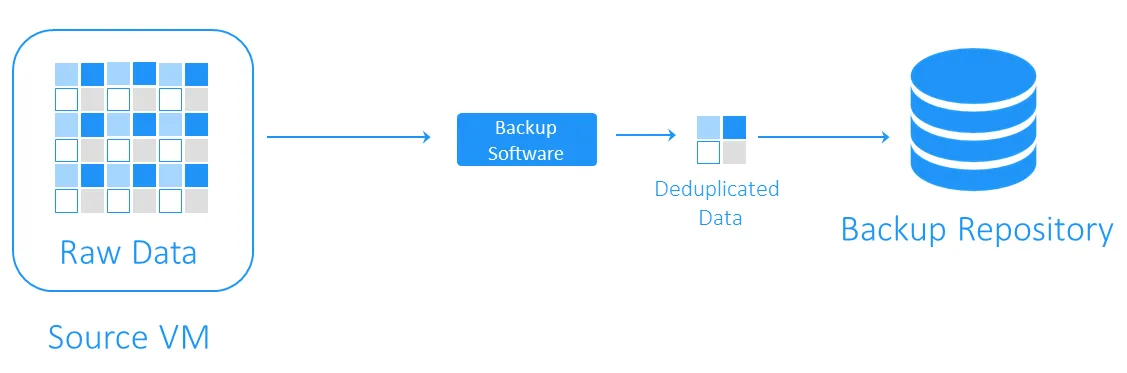
ターゲット側の重複排除
ターゲット側の重複排除は、まずデータをバックアップリポジトリに転送し、その後に重複排除を実行します。重複排除を担当するソフトウェアによって重い計算タスクが実行されます。
データ重複排除の方法
バックアップの重複排除は、インラインまたはポストプロセスになります。
- インライン重複排除は、バックアップリポジトリに書き込まれる前にデータの重複をチェックします。この技術は、バックアップデータストリームから冗長性をクリアするため、バックアップリポジトリでのストレージスペースを少なくするが、インライン重複排除はバックアップジョブ中に発生するため、バックアップ時間が長くなります。
- ポストプロセス重複排除は、データをバックアップリポジトリに書き込んだ後にデータを処理します。明らかに、このアプローチではリポジトリ内により多くの空き容量が必要ですが、バックアップはより速く実行され、すべての必要な操作がその後に行われます。ポストプロセス重複排除は非同期重複排除とも呼ばれます。
データ重複排除の方法
重複を特定する最も一般的な方法は、ハッシュベースおよび修正されたハッシュベースの方法です。
- ハッシュベースのメソッドを使用すると、デデュープソフトウェアは、データを固定長または可変長のブロックに分割し、MD5、SHA-1、またはSHA-256などの暗号アルゴリズムを使用してそれぞれのハッシュを計算します。これらのメソッドはそれぞれデータブロックのユニークなフィンガープリントを生成するため、類似したハッシュを持つブロックは同一と見なされます。この方法の欠点は、特に大規模なバックアップの場合には、かなりの計算リソースが必要になる可能性があることです。
- 変更されたハッシュベースのメソッドは、CRCなどのよりシンプルなハッシュ生成アルゴリズムを使用し、SHA-256の256ビットに比べてわずか16ビットしか生成しません。その後、ブロックが類似したハッシュを持っている場合、バイトごとに比較されます。完全に類似している場合、ブロックは同一と見なされます。この方法はハッシュベースの方法よりもやや遅くなりますが、計算リソースを少なく必要とします。
バックアップデデュプソフトウェアの選択
バックアップデデュプソフトウェアの選択は、デデュプ技術の中で最も人気のある用途の1つです。ただし、このデータ削減技術を実装するには、適切なソフトウェアソリューションとストレージ用のハードウェアが必要です。
NAKIVO Backup & Replicationは、変更されたハッシュベースの重複検出を使用したグローバルターゲットのポスト処理デデュプリケーションをサポートするバックアップソリューションです。また、DELL EMC Data Domain with DD Boost、NEC HYDRAstor、HP StoreOnce with Catalyst supportなどのデデュプリケーションアプライアンスを統合することで、NAKIVOソリューションを活用できます。
Source:
https://www.nakivo.com/blog/backup-deduplication-explained/