













התשתיות הווירטואליות הגדולות של היום יוצרות כמות עצומה של נתונים. זה מביא להגברת הנתונים הגיבוי ולהוצאות נוספות על תשתיות אחסון גיבוי, שכוללות מכשירי אחסון ואחזקתם. מכאן, מנהלי רשת מחפשים דרכים לחסוך מקום אחסון ביצירת גיבויים תדירים של מכונות ויישומים חיוניים.
אחת מהטכניקות הנפוצות היא הכפלת גיבוי. פוסט הבלוג הזה מכסה מהו הכפלת נתונים, סוגי הכפלה ומקרי שימוש עם דגש על גיבויים.
מהו הכפלת נתונים?
הכפלת נתונים היא טכנולוגית אופטימיזציה של נפח אחסון. הכפלת נתונים כוללת קריאה של הנתונים המקוריים והנתונים שכבר נמצאים באחסון כדי להעביר או לשמור רק בלוקים ייחודיים. הפניות לנתונים כפולים מתווכות. באמצעות הטכנולוגיה הזו להימנע מכפילויות בנפח, ניתן לחסוך מקום בדיסק ולהפחית את העלות של אחסון.
מקורות הכפלת נתונים
הקודמים של הכפלת נתונים הם אלגוריתמי הדחיסה LZ77 ו-LZ78 שהוצגו בשנת 1977 ו-1978 בהתאמה. הם כוללים החלפת רצפי נתונים חוזרים עם הפניות לנתונים המקוריים.
הרעיון הזה השפיע על שיטות דחיסה פופולריות אחרות. הידועה ביותר מביניהן היא DEFLATE, שמשמשת בתצורות קובץ תמונת PNG ו-ZIP. עכשיו נבחן איך הכפלת נתונים עובדת עם גיבויי VM וכיצד בדיוק היא עוזרת לחסוך מקום אחסון ועל עלויות התשלום על תשתיות.
מהו הכפלת נתונים בגיבוי?
בזמן חיסון גיבוי, בדיקת דיסקריפציה מחפשת בלוקים מדויקים אחד של מידע בין המאגר המקורי למאגר הגיבוי היעד. עותקים מוכרים אינם מעתיקים, ומיוצעת הפניית או מצבר אל המידע הקיים במאגר הגיבוי היעד.
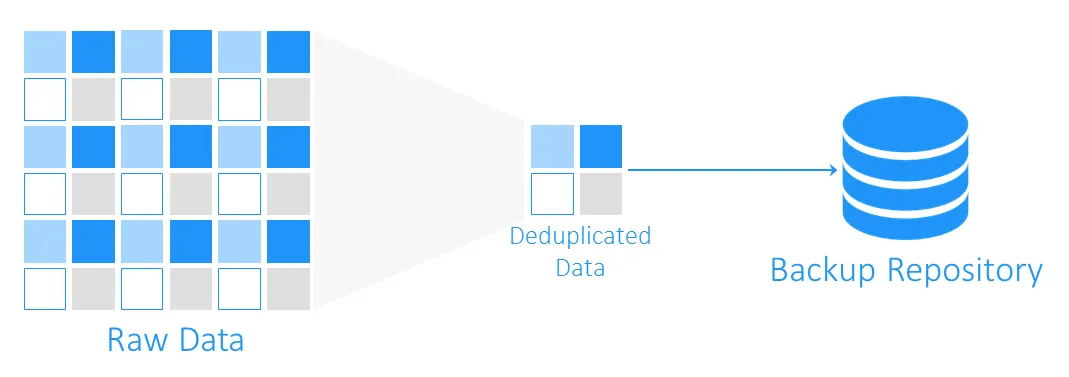
כמה מרחב אפשר לחסוך בעזרת דיסקריפציה?
כדי להבין כמה מרחב אפשר לחסוך בעזרת דיסקריפציה, בואו נחשוב על דוגמה. הדרישות המינימליות להתקנת Windows Server 2016 הם לפחות 32 ג 'בים של חלק ריק. אם יש על עשרה מכונות מופע אותה הסיסמה, הגיבויים יגייסו לפחות 320 ג'בים, וזה רק סדרה חיתוך של המערכת העיקרית ללא יישומים או בסיסמאות על הדברים האלה.
הסבירות היא שאם צריך להתקין יותר מאחת מכונת מופע מודלית (VM), תהיה בעלת תבנית, וזה אומר שבהתחלה, יהיו עשרה מכונות אחת ואחת. וזה גם אומר שיהיו לך 10 ערכים של בלוקים מדויקים. בדוגמה זו, תקבל שיעור חסוך המרחב 10:1. באופן כללי, חסוך של 5:1 עד 10:1 נתפס כטוב.
שיעור דיסקריפציה המידע.
יחס הכפילויות של הנתונים הוא מדד המשמש למדוד את גודל הנתונים המקוריים לעומת גודל הנתונים לאחר הסרת החלקים המיותרים. מדד זה מאפשר לך לדרג את יעילות תהליך הכפילויות של הנתונים. כדי לחשב את הערך, עליך לחלק את כמות הנתונים לפני הכפילויות בנפח האחסון שנצרך על ידי הנתונים אלו לאחר הכפילויות.
לדוגמה, יחס כפילויות 5:1 אומר שתוכל לאחסן חמישה פעמים יותר נתונים מגיבוי באחסון הגיבוי מאשר מה שנדרש לאחסן את אותם הנתונים בלעדיו של כפילויות.
עליך לקבוע את יחס הכפילויות וההפחתה בנפח האחסון. שני הפרמטרים הללו מטעים לבלבול לעיתים. יחסי הכפילויות אינם משתנים ביחס ישיר ליתרונות ההפחתה בנתונים, מאחר וחוק התשובה המועטה מתקיים מעבר לנקודה מסוימת. ראה את הגרף למטה.
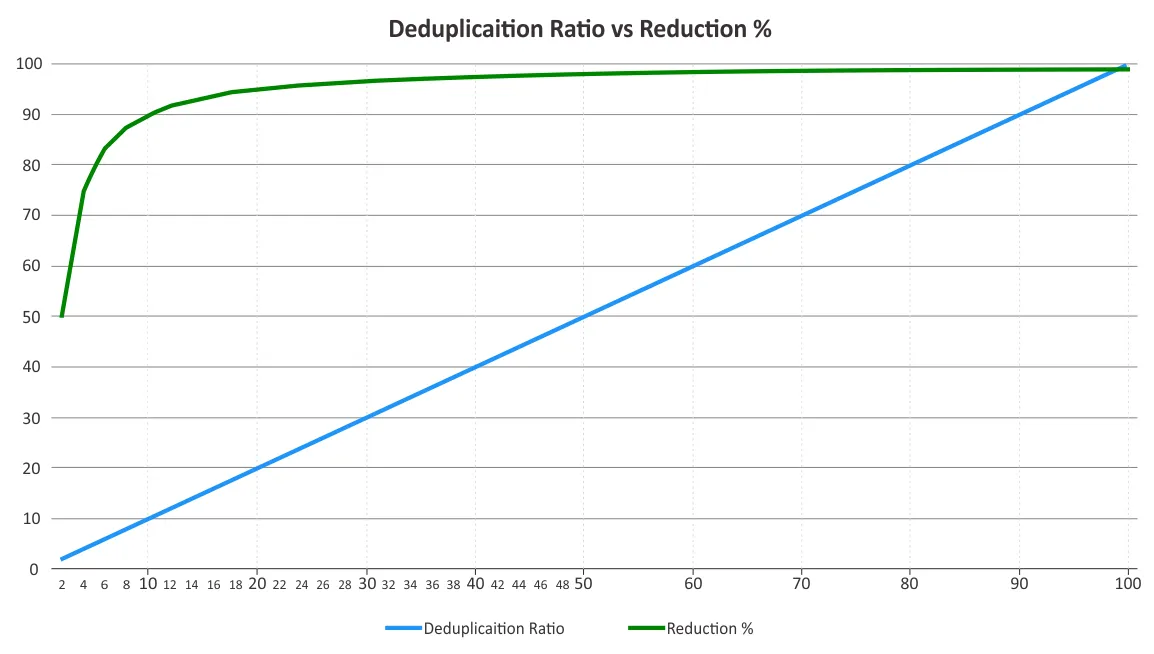
כך שיחסי הכפילויות הנמוכים יכולים להביא לחסכונות יותר משמעותיים מהיחס הגבוה. למשל, יחס כפילויות של 50:1 אינו פעמיים טוב יותר מיחס 10:1. יחס 10:1 מספק הפחתה של 90% בנפח האחסון הצריך, בעוד שיחס 50:1 מעלה את הערך הזה ל-98%, בהנחה שרוב החוזרות כבר נמחקו. למידע נוסף על כיצד מחושבות אחוזי הללו, ניתן לראות את מסמך המכון לתקשורת ואחסון נתונים (SNIA) על כפילויות הנתונים.
גורמים המשפיעים על יעילות הכפילויות של הנתונים
קשה לחזות את יעילות הפחתת הנתונים עד שהנתונים מודדופליקצים בפועל עקב מספר גורמים. הנה כמה מהגורמים שיש להם השפעה על הפחתת הנתונים בעת השימוש בדידופליקציה:
- סוגי גיבוי נתונים ומדיניות. דידופליקציה עבור גיבויים מלאים היא יותר אפקטיבית מאשר עבור גיבויים צמודים או חלקיים.
- שיעור השינוי. אם יש הרבה שינויים בנתונים לצורך גיבוי, אז יחס הדידופליקציה נמוך יותר.
- הגדרות ניצור. ככל שתאחסן גיבויים באחסון הגיבויים לגודל יותר, כך הדידופליקציה של הנתונים באחסון זה יכולה להיות יותר אפקטיבית.
- סוג הנתונים. דידופליקציה עבור קבצים שבהם הנתונים כבר דחוסים, כמו גוגל, PNG, MPG, AVI, MP4, ZIP, RAR וכו ', אינה אפקטיבית. אותו דבר נכון גם לנתונים עשירי מטה ומוצפנים. סוגי נתונים המכילים חלקים חוזרים יותר טובים לדידופליקציה.
- טווח הנתונים. דידופליקציה של נתונים היא יותר אפקטיבית עבור טווח נתונים גדול. דידופליקציה גלובלית יכולה לחסוך יותר מקום אחסון בהשוואה לדידופליקציה מקומית.
הערה: ההכפלה מקומית עובדת על מכשיר נפרד / דיסק בודד. ההכפלה הגלובלית נותחת את סט הנתונים כולו בכל המכשירים / דיסקים כדי להסיר כפילויות נתונים. אם יש לך מספר רב של צמתים עם הכפלה מקומית מופעלת על כל אחד, ההכפלה לא תהיה כהילה כמו עם ההכפלה הגלובלית המופעלת עבורם.
- תוכנה וחומרה. שילוב פתרונות תוכנה וחומרת הכפלה יכול לספק יחסי הכפלה טובים יותר מאשר תוכנה בלבד. לדוג' , פתרון הגיבוי של NAKIVO מספק שילוב עם HP StoreOnce, Dell EMC Data Domain, ומכשירי הכפלה NEC HYDRAstor ליחסי הכפלה של עד 17:1.
טכניקות הכפלת גיבוי
טכניקות הכפלת הגיבוי ניתן לסווג לפי הבא:
- היכן ההכפלה מתבצעת
- מתי ההכפלה מתבצעת
- כיצד ההכפלה מתבצעת
היכן ההכפלה מתבצעת
הכפלת גיבוי ניתן לבצע בצד מקור או בצד יעד, והטכניקות הללו נקראות הכפלת צד מקור והכפלת צד יעד בהתאמה.
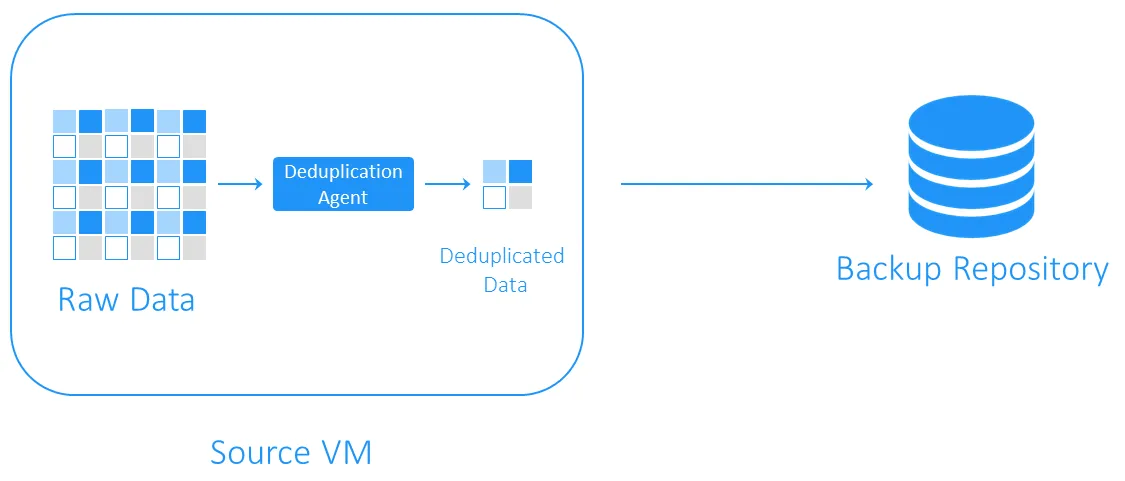
הכפלת צד מקור
ההפשרה בצד המקור מפחיתה את העומס על הרשת מאחר ופחות נתונים מועברים במהלך הגיבוי. עם זאת, היא דורשת התקנת סוכן להפשרה על כל מכונה וירטואלית או על כל מארח. החסרון האחר הוא שההפשרה בצד המקור עשויה להאט VMs בשל החישובים הדרושים לזיהוי מקטעי נתונים כפולים.
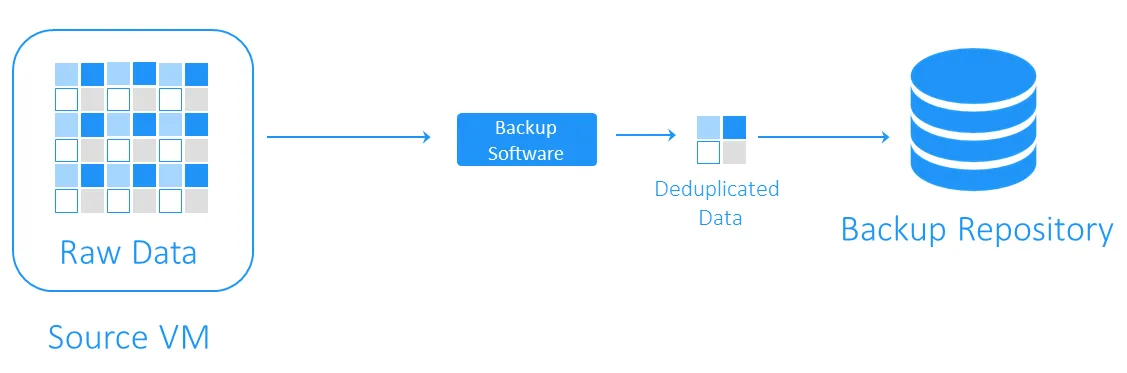
הפשרה בצד היעד
ההפשרה בצד היעד מעבירה תחילה את הנתונים למאגר הגיבוי ואז מבצעת הפשרה. המשימות המחשבתיות הכבדות מבוצעות על ידי התוכנה האחראית על ההפשרה.
כאשר מבצעים הפשרה של נתונים
הפשרת הגיבוי יכולה להיות מתוך השורה או לאחר עיבוד.
- הפשרה מתוך השורה בודקת כפילויות של נתונים לפני שהם נכתבים למאגר הגיבוי. טכניקה זו דורשת פחות מקום אחסון במאגר הגיבוי מאחר והיא מנקה את זרם הנתונים מהגיבוי מתוך שכפולים, אך היא מובילה לזמן גיבוי ארוך יותר מאחר שההפשרה מתוך השורה מתרחשת במהלך המשרד.
- הפשרה לאחר עיבוד מעבדת נתונים לאחר שהם נכתבים למאגר הגיבוי. ברור שגישה זו דורשת יותר מקום פנוי במאגר, אך הגיבויים מתבצעים מהר יותר, וכל הפעולות הנדרשות מתבצעות לאחר מכן. הפשרה לאחר עיבוד נקראת גם הפשרה אסינכרונית.
איך מבצעים הפשרה של נתונים
השיטות הנפוצות ביותר לזיהוי כפילויות הן באמצעות האש והמשונה.
- עם השיטה המבוססת על הגבלה, תוכנת ההכפלת נתונים מחלקת את הנתונים לבלוקים באורך קבוע או משתנה ומחשבת גיבוב עבור כל אחד מהם באמצעות אלגוריתמים קריפטוגרפיים כמו MD5, SHA-1, או SHA-256. כל אחת מהשיטות הללו מספקת טביעת אצבע ייחודית של בלוקי הנתונים, ולכן הבלוקים עם גיבובים דומים נחשבים זהים. החסרון של שיטה זו הוא שיתכן שתידרשנה משאבי חישוב משמעותיים, במיוחד במקרה של גיבויים גדולים.
- השיטה המבוססת על גיבוב משונה משתמשת באלגוריתמי גיבוב פשוטים יותר כמו CRC, המייצרים רק 16 ביטים (בניגוד ל-256 ביטים ב-SHA-256). לאחר מכן, אם הבלוקים מכילים גיבובים דומים, הם נשווים בבת על בת. אם הם דומים לחלוטין, הבלוקים נחשבים זהים. שיטה זו מעט איטית יותר מהשיטה המבוססת על גיבוב, אך דורשת פחות משאבי חישוב.
בחירת תוכנת הכפלת גיבוי
הכפלת גיבוי היא אחת מתרחישי השימוש הפופולריים ביותר של הכפלה. עם זאת, עליך לקבל את הפתרון התוכנה המתאים ואת החומרה המתאימה לאחסון כדי ליישם טכנולוגיית זירוי הנתונים הזו.
NAKIVO Backup & Replication היא פתרון גיבוי התומך בשימוש בזירוי מוקדם של מטרה גלובלית עם איתור כפילויות מבוסס גיבוב משונה. תוכל גם להשתמש בזירוי מצד המקור על ידי שילוב מכשיר זירוי כמו DELL EMC Data Domain עם DD Boost, NEC HYDRAstor ו- HP StoreOnce עם תמיכת Catalyst עם הפתרון של NAKIVO.
Source:
https://www.nakivo.com/blog/backup-deduplication-explained/