













Die heutigen großen virtuellen Infrastrukturen erzeugen eine enorme Menge an Daten. Dies führt zu einem Anstieg der Backup-Daten und der Ausgaben für Backup-Speicherinfrastruktur, die Speichergeräte und deren Wartung umfasst. Aus diesem Grund suchen Netzwerkadministratoren nach Möglichkeiten, Speicherplatz zu sparen, wenn sie häufige Backups von wichtigen Maschinen und Anwendungen erstellen.
Eine der weit verbreiteten Techniken ist die Backup-Deduplizierung. Dieser Blogbeitrag behandelt, was Daten-Deduplizierung ist, Deduplizierungstypen und Anwendungsfälle mit Schwerpunkt auf Backups.
Was ist Deduplizierung?
Daten-Deduplizierung ist eine Technologie zur Optimierung der Speicherkapazität. Daten-Deduplizierung beinhaltet das Lesen der Quelldaten und der bereits im Speicher befindlichen Daten, um nur einzigartige Datenblöcke zu übertragen oder zu speichern. Verweise auf die doppelten Daten werden beibehalten. Durch die Verwendung dieser Technologie, um Duplikate auf einem Volume zu vermeiden, können Sie Speicherplatz sparen und den Speicheroverhead reduzieren.
Ursprung der Daten-Deduplizierung
Die Vorläufer der Daten-Deduplizierung sind die LZ77- und LZ78-Kompressionsalgorithmen, die 1977 bzw. 1978 eingeführt wurden. Sie beinhalten den Ersatz wiederholter Datensequenzen durch Verweise auf die Originaldaten.
Dieses Konzept beeinflusste andere beliebte Kompressionsmethoden. Die bekannteste davon ist DEFLATE, die in den Bildformaten PNG und ZIP verwendet wird. Schauen wir uns nun an, wie Deduplizierung bei VM-Backups funktioniert und wie genau sie hilft, Speicherplatz zu sparen und die Kosten für die Infrastruktur zu reduzieren.
Was ist Deduplizierung im Backup?
Während eines Backups überprüft die Daten-Deduplizierung identische Datenblöcke zwischen dem Quellspeicher und dem Ziel-Backup-Repository. Duplikate werden nicht kopiert, und es wird ein Verweis oder Zeiger auf die vorhandenen Datenblöcke im Ziel-Backup-Speicher erstellt.
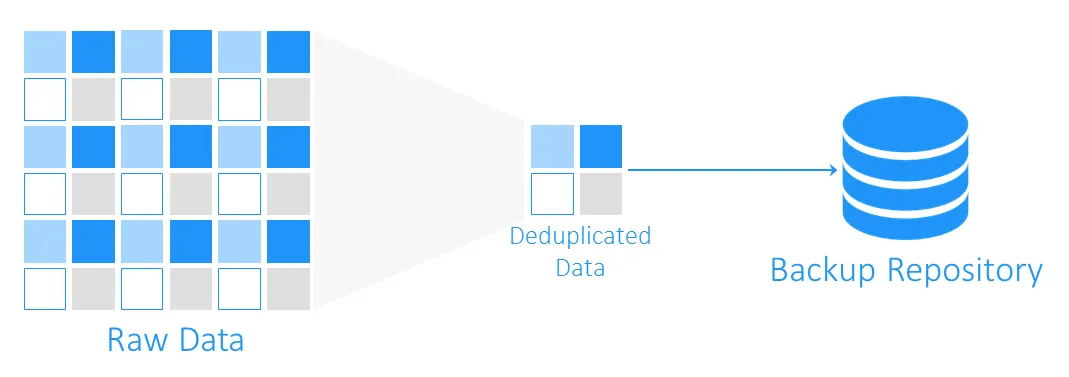
Wie viel Speicherplatz kann die Daten-Deduplizierung sparen?
Um zu verstehen, wie viel Speicherplatz durch Deduplizierung gewonnen werden kann, betrachten wir ein Beispiel. Die minimalen Systemanforderungen für die Installation von Windows Server 2016 betragen mindestens 32 GB freier Festplattenspeicher. Wenn Sie zehn VMs mit diesem Betriebssystem ausführen, werden Backups mindestens 320 GB betragen, und das ist nur ein sauberes Betriebssystem ohne Anwendungen oder Datenbanken darauf.
Die Wahrscheinlichkeit ist hoch, dass Sie, wenn Sie mehr als eine virtuelle Maschine (VM) mit demselben System bereitstellen müssen, eine Vorlage verwenden, und das bedeutet, dass Sie zunächst zehn identische Maschinen haben werden. Und das bedeutet auch, dass Sie 10 Sätze von duplizierten Datenblöcken erhalten werden. In diesem Beispiel haben Sie ein Speichereinsparungsverhältnis von 10:1. Im Allgemeinen gelten Einsparungen von 5:1 bis 10:1 als gut.
Daten-Deduplizierungsverhältnis
Der Daten-Deduplikationsfaktor ist eine Metrik, die verwendet wird, um die Originaldatengröße im Vergleich zur Größe der Daten nach Entfernung redundanter Teile zu messen. Diese Metrik ermöglicht es Ihnen, die Effektivität des Daten-Deduplikationsprozesses zu bewerten. Um den Wert zu berechnen, sollten Sie die Datenmenge vor der Deduplikation durch den Speicherplatz teilen, der durch diese Daten nach der Deduplikation verbraucht wird.
Zum Beispiel bedeutet ein Deduplikationsverhältnis von 5:1, dass Sie fünfmal mehr gesicherte Daten in Ihrem Backup-Speicher speichern können, als es erforderlich ist, um dieselben Daten ohne Deduplikation zu speichern.
Sie sollten das Deduplikationsverhältnis und Speicherplatzreduktion bestimmen. Diese beiden Parameter werden manchmal verwechselt. Deduplikationsverhältnisse ändern sich nicht proportional zu den Vorteilen der Datenreduktion, da das Gesetz des abnehmenden Grenzertrags über einen bestimmten Punkt hinaus zum Tragen kommt. Siehe das untenstehende Diagramm.
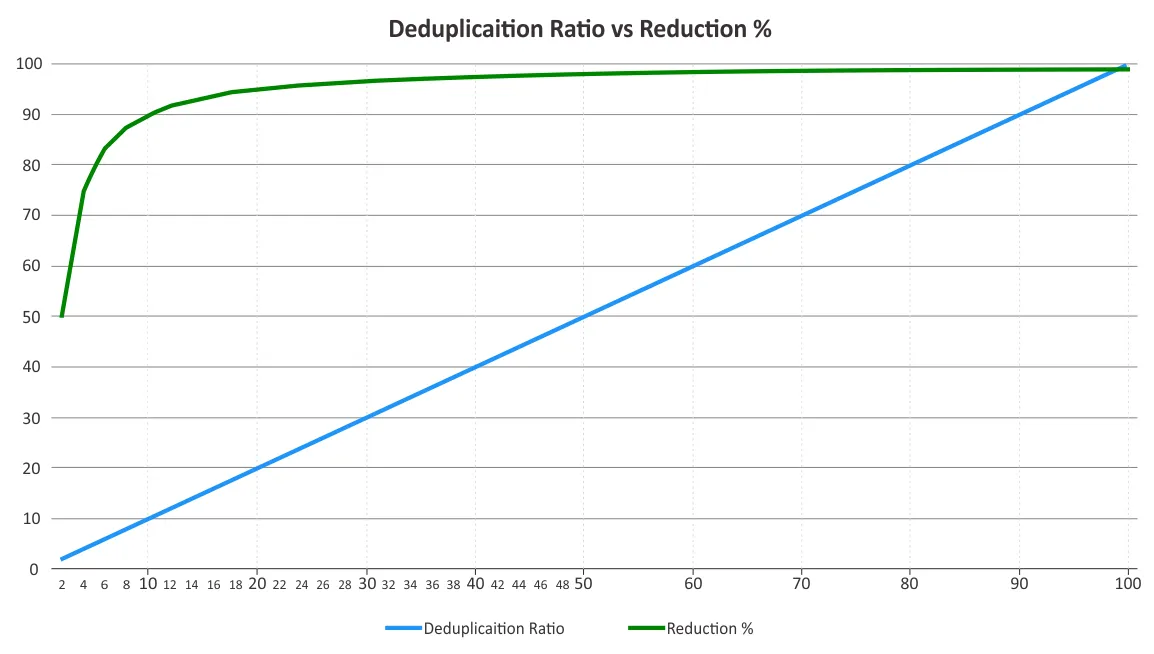
Dies bedeutet, dass niedrigere Verhältnisse größere Einsparungen bringen können als höhere. Zum Beispiel ist ein Deduplikationsverhältnis von 50:1 nicht fünfmal besser als ein Verhältnis von 10:1. Das Verhältnis von 10:1 bietet eine Reduzierung des verbrauchten Speicherplatzes um 90%, während das Verhältnis von 50:1 diesen Wert auf 98% erhöht, da die meisten Redundanzen bereits beseitigt wurden. Für weitere Informationen darüber, wie diese Prozentsätze berechnet werden, können Sie das Dokument der Storage Networking Industry Association (SNIA) zur Daten-Deduplikation einsehen.
Faktoren, die die Effizienz der Daten-Deduplikation beeinflussen
Es ist schwierig, die Effizienz der Datenreduzierung vorherzusagen, bis die Daten tatsächlich dedupliziert wurden, aufgrund mehrerer Faktoren. Die folgenden sind einige der Faktoren, die die Datenreduktion bei der Verwendung von Deduplizierung beeinflussen können:
- Datensicherungstypen und -richtlinien. Deduplizierung für Voll-Backups ist effektiver als für inkrementelle oder differentielle Backups.
- Änderungsrate. Wenn es viele Datenänderungen zu sichern gibt, ist das Deduplizierungsverhältnis geringer.
- Retentionseinstellungen. Je länger Sie Datenbackups im Backup-Speicher speichern, desto effektiver kann die Daten-Deduplizierung auf diesem Speicher sein.
- Datentyp. Deduplizierung für Dateien, in denen Daten bereits komprimiert sind, wie z.B. JPG, PNG, MPG, AVI, MP4, ZIP, RAR, etc., ist nicht effektiv. Das gleiche gilt für metadatenreiche und verschlüsselte Daten. Datentypen, die repetitive Teile enthalten, sind besser für die Deduplizierung geeignet.
- Datenumfang. Daten-Deduplizierung ist effektiver für einen großen Datenumfang. Globale Deduplizierung kann im Vergleich zur lokalen Deduplizierung mehr Speicherplatz sparen.
Hinweis: Die lokale Deduplizierung funktioniert auf einem einzelnen Knoten/Festplattengerät. Die globale Deduplizierung analysiert den gesamten Datensatz auf allen Knoten/Festplattengeräten, um Daten-Duplikate zu eliminieren. Wenn Sie mehrere Knoten mit lokaler Deduplizierung aktiviert auf jedem haben, wäre die Deduplizierung nicht so effizient wie bei globaler Deduplizierung, die für sie aktiviert ist.
- Software und Hardware. Die Kombination von Softwarelösungen und Deduplizierungshardware kann bessere Deduplizierungsverhältnisse bieten als nur Software allein. Zum Beispiel bietet die Backup-Lösung von NAKIVO Integration mit HP StoreOnce, Dell EMC Data Domain und NEC HYDRAstor Deduplizierungsgeräten für Deduplizierungsverhältnisse von bis zu 17:1.
Backup-Deduplizierungstechniken
Die Backup-Deduplizierungstechniken können basierend auf folgendem kategorisiert werden:
- Wo die Daten-Deduplizierung durchgeführt wird
- Wann die Deduplizierung durchgeführt wird
- Wie die Deduplizierung durchgeführt wird
Wo die Daten-Deduplizierung durchgeführt wird
Die Backup-Deduplizierung kann auf der Quellseite oder auf der Zielseite durchgeführt werden, und diese Techniken werden jeweils Quellseiten-Deduplizierung und Zielseiten-Deduplizierung genannt.
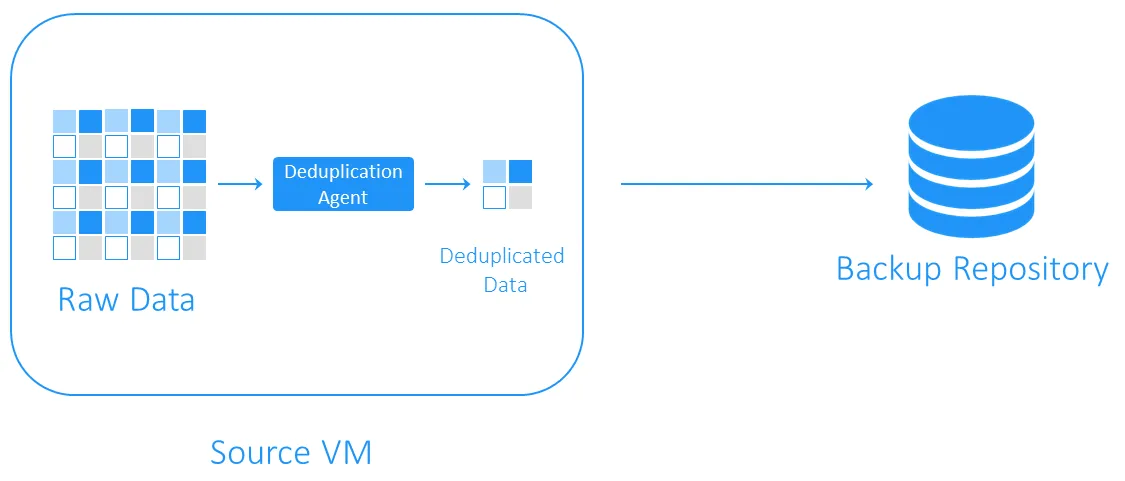
Quellseiten-Deduplizierung
Quellseitiges Deduplizieren verringert die Netzwerklast, weil weniger Daten während der Sicherung übertragen werden. Allerdings erfordert es, dass ein Deduplizierungs-Agent auf jeder VM oder jedem Host installiert ist. Ein weiterer Nachteil ist, dass die Quellseitigkeit die VM-Ausführung verlangsamen kann, da Berechnungen für die Identifizierung von identischen Datenblöcken notwendig sind.
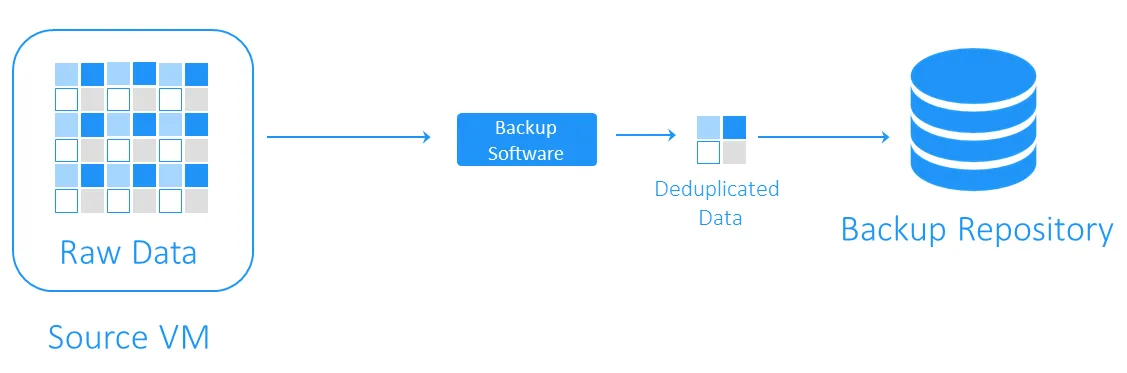
Zielseitiges Deduplizieren
Zielseitiges Deduplizieren sendet zunächst die Daten an das Backup-Repository und führt dann die Deduplizierung durch. Die rechenintensiveren Aufgaben werden von der für die Deduplizierung verantwortlichen Software ausgeführt.
Wenn Deduplizierung von Daten durchgeführt wird
Backup-Deduplizierung kann inline oder nachträglich erfolgen.
- Inline Deduplizierungsucht nach Datenduplikaten, bevor sie in ein Backup-Repository geschrieben werden. Diese Technik erfordert weniger Speicherplatz im Backup-Repository, da sie den Datenstrom von Redundanzen bereinigt, aber es führt zu einer Verlängerung des Backup-Zeitpunkts, da die Inline-Deduplizierung während der Backup-Aufgaben stattfindet.
- Nachträgliche Deduplizierungverarbeitet Daten nachdem sie ins Backup-Repository geschrieben wurden.offensichtlich erfordert diese Methode mehr freien Platz im Repository, aber die Backups laufen schneller und alle notwendigen Operationen erfolgen anschließend. Nachträgliche Deduplizierung wird auch als asynchrones Deduplizieren bezeichnet.
Wie Datendeduplizierung durchgeführt wird
Die häufigsten Methoden zur Identifizierung von Duplikaten sind hashbasiert und modifizierte hashbasierte Methoden.
- Mit der hashbasierten Methode teilt die Deduplikationssoftware Daten in Blöcke fester oder variabler Länge auf und berechnet für jeden von ihnen einen Hash unter Verwendung kryptografischer Algorithmen wie MD5, SHA-1 oder SHA-256. Jede dieser Methoden liefert einen eindeutigen Fingerabdruck der Datenblöcke, sodass Blöcke mit ähnlichen Hashes als identisch betrachtet werden. Der Nachteil dieser Methode ist, dass sie möglicherweise erhebliche Rechenressourcen erfordert, insbesondere im Fall großer Backups.
- Die modifizierte hashbasierte Methode verwendet einfachere hashgenerierende Algorithmen wie CRC, die nur 16 Bits produzieren (im Vergleich zu 256 Bits bei SHA-256). Dann werden, wenn die Blöcke ähnliche Hashes haben, sie byteweise verglichen. Wenn sie vollständig identisch sind, gelten die Blöcke als identisch. Diese Methode ist etwas langsamer als die hashbasierte, erfordert jedoch weniger Rechenressourcen.
Auswahl der Backup-Deduplikationssoftware
Die Deduplizierung von Backups ist einer der beliebtesten Anwendungsfälle der Deduplizierung. Sie benötigen jedoch die geeignete Softwarelösung und Hardware für die Speicherung, um diese Technologie zur Datenreduzierung umzusetzen.
NAKIVO Backup & Replication ist eine Backup-Lösung, die die globale Ziel-Post-Processing-Deduplikation mit modifizierter hashbasierter Duplikaterkennung unterstützt. Sie können auch von der Quellseiten-Deduplikation profitieren, indem Sie eine Deduplikationsappliance integrieren, wie z. B. DELL EMC Data Domain mit DD Boost, NEC HYDRAstor und HP StoreOnce mit Catalyst-Unterstützung mit der NAKIVO-Lösung.
Source:
https://www.nakivo.com/blog/backup-deduplication-explained/