













As grandes infraestruturas virtuais de hoje geram uma imensa quantidade de dados. Isso leva a um aumento nos dados de backup e nos gastos com infraestrutura de armazenamento de backup, que inclui dispositivos de armazenamento e sua manutenção. Por esse motivo, os administradores de rede procuram maneiras de economizar espaço de armazenamento ao criar backups frequentes de máquinas e aplicativos críticos.
Uma das técnicas amplamente utilizadas é a deduplicação de backup. Esta postagem no blog aborda o que é a deduplicação de dados, os tipos de deduplicação e os casos de uso com foco em backups.
O que é deduplicação?
A deduplicação de dados é uma tecnologia de otimização de capacidade de armazenamento. A deduplicação de dados envolve a leitura dos dados de origem e dos dados já armazenados para transferir ou salvar apenas blocos de dados únicos. As referências aos dados duplicados são mantidas. Ao usar essa tecnologia para evitar duplicatas em um volume, é possível economizar espaço em disco e reduzir a sobrecarga de armazenamento.
Origens da deduplicação de dados
Os predecessores da deduplicação de dados são os algoritmos de compressão LZ77 e LZ78, introduzidos em 1977 e 1978, respectivamente. Eles envolvem a substituição de sequências de dados repetidos por referências às originais.
Esse conceito influenciou outros métodos populares de compressão. O mais conhecido deles é o DEFLATE, usado nos formatos de imagem PNG e de arquivo ZIP. Agora vamos ver como a deduplicação funciona com backups de máquinas virtuais e como exatamente ela ajuda a economizar espaço de armazenamento e custos gastos na infraestrutura.
O que é deduplicação em backups?
Durante um backup, a deduplicação de dados verifica blocos de dados idênticos entre o armazenamento de origem e o repositório de backup de destino. Duplicatas não são copiadas, e uma referência, ou ponteiro, para os blocos de dados existentes no armazenamento de backup de destino é criada.
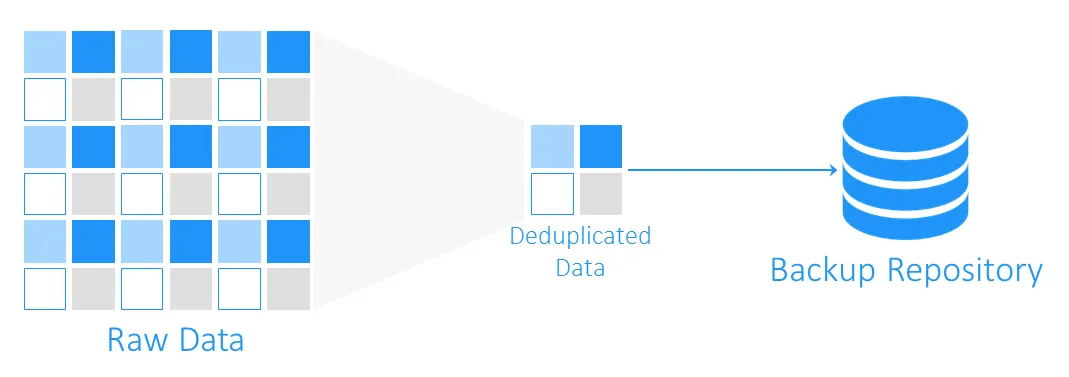
Quanto Espaço a Deduplicação de Dados Pode Economizar Para Você?
Para entender quanto espaço de armazenamento pode ser ganho com a deduplicação, vamos considerar um exemplo. Os requisitos mínimos do sistema para instalar Windows Server 2016 são pelo menos 32 GB de espaço livre em disco. Se você tiver dez VMs executando este SO, os backups totalizarão pelo menos 320 GB, e este é apenas um sistema operacional limpo sem quaisquer aplicativos ou bancos de dados nele.
O mais provável é que se você precisar implantar mais de uma máquina virtual (VM) com o mesmo sistema, você usará um modelo, e isso significa que inicialmente você terá dez máquinas idênticas. E isso também significa que você obterá 10 conjuntos de blocos de dados duplicados. Neste exemplo, você terá uma taxa de economia de espaço de armazenamento de 10:1. Em geral, economias variando de 5:1 a 10:1 são consideradas boas.
Razão de Deduplicação de Dados
A taxa de deduplicação de dados é uma métrica usada para medir a quantidade de dados originais em relação à quantidade de dados depois que as partes redundantes foram removidas. Essa métrica permite-lhe avaliar a eficácia do processo de deduplicação de dados. Para calcular o valor, você deve dividir a quantidade de dados antes da deduplicação pela espaço de armazenamento consumido por esses dados depois de deduplicados.
Por exemplo, a taxa de deduplicação de 5:1 significa que você pode armazenar cinco vezes mais dados de backup em seu armazenamento de backup do que seria necessário para armazenar os mesmos dados sem deduplicação.
Você deve determinar a taxa de deduplicação e a redução do espaço de armazenamento. Esses dois parâmetros são às vezes confundidos. As taxas de deduplicação não mudam proporcionalmente aos benefícios da redução de dados, já que a lei do retorno cada vez menor está sempre para entrar em jogo além de certo ponto. Veja o gráfico abaixo.
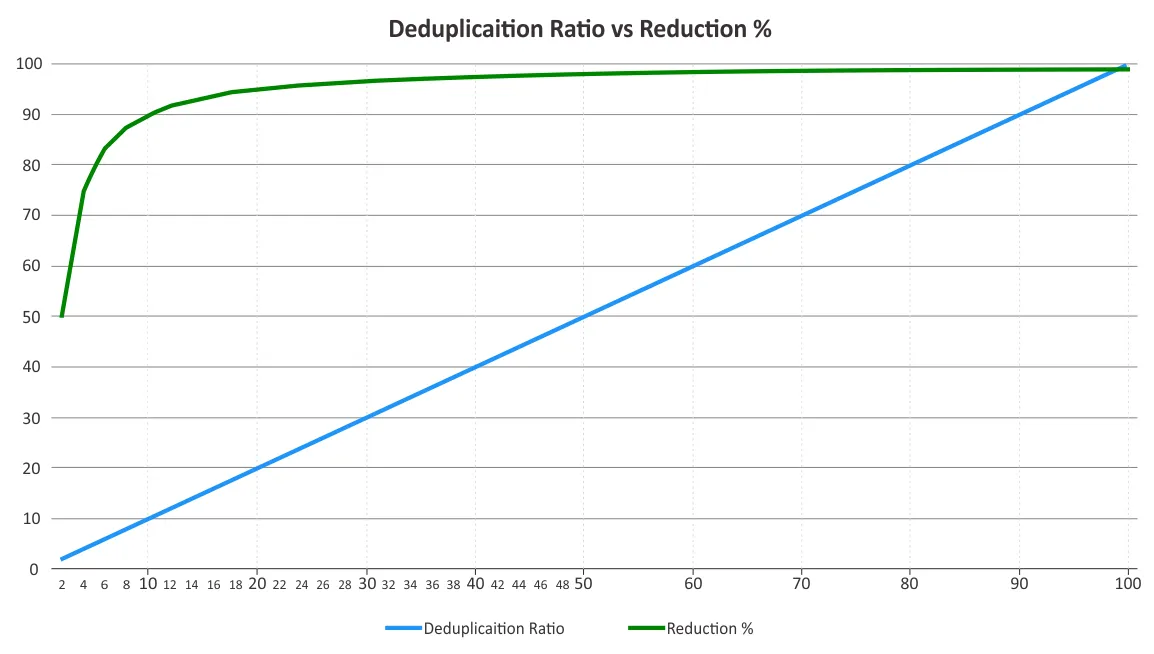
Isso significa que as taxas mais baixas podem trazer economias mais significativas do que as taxas mais altas. Por exemplo, uma taxa de deduplicação de 50:1 não é cinco vezes melhor do que uma taxa de 10:1. A taxa de 10:1 fornece uma redução de 90% do espaço de armazenamento consumido, enquanto a taxa de 50:1 aumenta esse valor para 98%, dado que a maioria da redundância já foi eliminada. Para obter informações adicionais sobre como esses percentuais são calculados, você pode ver documento da Associação de Redes de Armazenamento (SNIA) sobre deduplicação de dados.
Fatores que afetam a eficiência da deduplicação de dados.
É difícil prever a eficiência de redução de dados até que os dados sejam deduplicados realmente, devido a vários fatores. As seguintes são algumas das variáveis que afetam a redução de dados ao usar deduplicação:
- Tipos de cópia de backup de dados e políticas. A deduplicação para cópias de backup completas é mais eficaz do que para cópias incrementais ou cópias diferenciais.
- Taxa de mudança. Se houver muitas mudanças em dados para serem backup, então a taxa de deduplicação é menor.
- Configurações de retenção. Quanto maior o período de tempo que você armazena cópias de backup de dados em armazenamento de backup, mais eficaz a deduplicação de dados neste armazenamento pode ser.
- Tipo de dado. A deduplicação para arquivos em que os dados já foram comprimidos, como JPG, PNG, MPG, AVI, MP4, ZIP, RAR, etc., não é eficaz. O mesmo é verdade para dados com muitos metadados e dados criptografados. Os tipos de dados que contêm partes repeditas são melhores para deduplicação.
- Escopo de dados. A deduplicação de dados é mais eficaz para um grande escopo de dados. A deduplicação global pode economizar mais espaço de armazenamento do que a deduplicação local.
Nota: A deduplicação local funciona em um único nó/dispositivo de disco. A deduplicação global analisa todo o conjunto de dados em todos os nós/dispositivos de disco para eliminar os duplicatas de dados. Se você tiver vários nós com deduplicação local habilitada em cada um, a deduplicação não seria tão eficiente quanto com a deduplicação global habilitada para eles.
- Software e hardware. A combinação de soluções de software e hardware de deduplicação pode oferecer melhores taxas de deduplicação do que o software sozinho. Por exemplo, a solução de backup NAKIVO fornece integração com HP StoreOnce, Dell EMC Data Domain e NEC HYDRAstor dispositivos de deduplicação para taxas de deduplicação de até 17:1.
Técnicas de Deduplicação de Backup
As técnicas de deduplicação de backup podem ser categorizadas com base em:
- Onde a deduplicação de dados é feita
- Quando a deduplicação é feita
- Como a deduplicação é feita
Onde a deduplicação de dados é feita
A deduplicação de backup pode ser feita no lado fonte ou no lado alvo, e essas técnicas são chamadas de deduplicação de lado fonte e deduplicação de lado alvo, respectivamente.
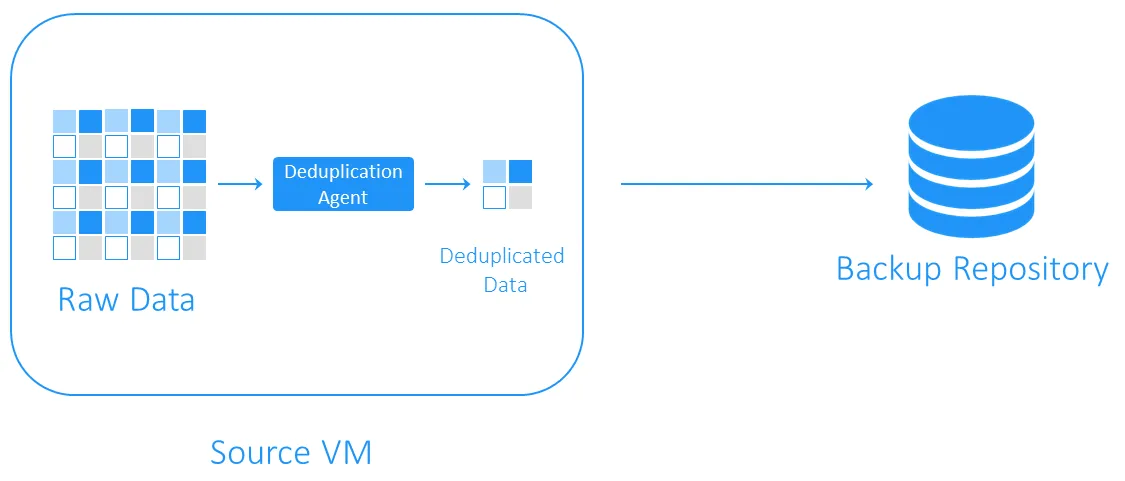
Deduplicação de lado fonte
A deduplicação do lado da fonte diminui a carga da rede porque menos dados são transferidos durante o backup. No entanto, requer um agente de deduplicação a ser instalado em cada VM ou em cada host. A outra desvantagem é que a deduplicação do lado da fonte pode desacelerar as VMs devido aos cálculos necessários para a identificação de blocos de dados duplicados.
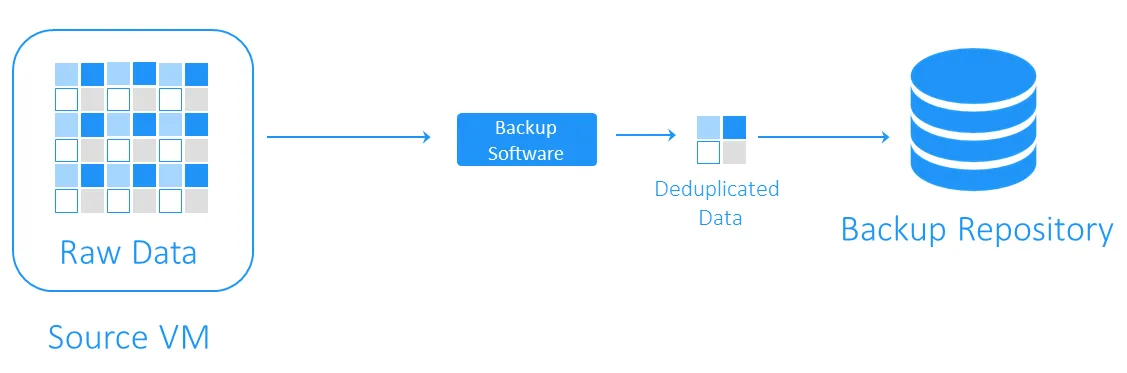
A deduplicação do lado do destino
A deduplicação do lado do destino primeiro transfere os dados para o repositório de backup e depois realiza a deduplicação. As tarefas de computação pesadas são realizadas pelo software responsável pela deduplicação.
Quando a deduplicação de dados é feita
A deduplicação de backup pode ser em linha ou pós-processamento.
- Deduplicação em linha verifica duplicatas de dados antes de serem gravadas em um repositório de backup. Esta técnica requer menos espaço de armazenamento em um repositório de backup, pois limpa o fluxo de dados de backup de redundâncias, mas resulta em um tempo de backup mais longo, pois a deduplicação em linha ocorre durante o trabalho de backup.
- Deduplicação pós-processamento processa dados após serem gravados no repositório de backup. Obviamente, este método requer mais espaço livre no repositório, mas os backups são mais rápidos, e todas as operações necessárias são feitas posteriormente. A deduplicação pós-processamento também é chamada de deduplicação assíncrona.
Como a deduplicação de dados é feita
Os métodos mais comuns para identificar duplicatas são baseados em hash e baseados em hash modificados.
- Com o método baseado em hash, o software de deduplicação divide os dados em blocos de comprimento fixo ou variável e calcula um hash para cada um deles usando algoritmos criptográficos como MD5, SHA-1 ou SHA-256. Cada um desses métodos gera uma impressão digital única dos blocos de dados, então os blocos com hashes semelhantes são considerados idênticos. A desvantagem deste método é que pode exigir muitos recursos computacionais, especialmente no caso de backups grandes.
- O método modificado baseado em hash usa algoritmos de geração de hash mais simples, como CRC, que produzem apenas 16 bits (em comparação com 256 bits no SHA-256). Então, se os blocos tiverem hashes semelhantes, eles são comparados byte a byte. Se forem completamente semelhantes, os blocos são considerados idênticos. Este método é um pouco mais lento que o baseado em hash, mas exige menos recursos computacionais.
Escolhendo o Software de Deduplicação de Backup
A deduplicação de backup é um dos casos de uso mais populares de deduplicação, mas você precisa ter a solução de software e o hardware de armazenamento adequados para implementar essa tecnologia de redução de dados.
O NAKIVO Backup & Replication é uma solução de backup que suporta o uso de deduplicação baseada em alvos globais com detecção modificada de duplicatas baseadas em hash. Você também pode tirar proveito da deduplicação do lado da fonte, integrando um appliance de deduplicação, como o DELL EMC Data Domain com DD Boost, NEC HYDRAstor e HP StoreOnce com suporte Catalyst, à solução NAKIVO.
Source:
https://www.nakivo.com/blog/backup-deduplication-explained/