













Primeiro, veremos o que é o Redis e seu uso, bem como por que é adequado para aplicações modernas de microserviços complexos. Falaremos sobre como o Redis suporta o armazenamento de vários formatos de dados para diferentes fins por meio de seus módulos. Em seguida, veremos como o Redis, como um banco de dados em memória, pode persistir dados e se recuperar de perdas de dados. Também falaremos sobre como o Redis otimiza os custos de armazenamento de memória usando o Redis em Flash.
Em seguida, veremos casos de uso muito interessantes de dimensionamento do Redis e replicação em várias regiões geográficas. Finalmente, como uma das plataformas mais populares para executar microsserviços é o Kubernetes, e como rodar aplicativos com estado no Kubernetes é um pouco desafiador, veremos como você pode executar facilmente o Redis no Kubernetes.
O que é o Redis?
O Redis, que na verdade significa Remote Dictionary Server, é um banco de dados em memória. Muitas pessoas o utilizam como cache em cima de outros bancos de dados para melhorar o desempenho da aplicação. No entanto, o que muitas pessoas não sabem é que o Redis é um banco de dados primário totalmente capaz que pode ser usado para armazenar e persistir múltiplos formatos de dados para aplicações complexas.
Exemplo de Aplicação de Mídia Social Complexa
Vamos analisar uma configuração comum para uma aplicação de microserviços. Digamos que temos uma aplicação de mídia social complexa com milhões de usuários. E vamos supor que nossa aplicação de microserviços usa um banco de dados relacional como o MySQL para armazenar os dados. Além disso, como estamos coletando toneladas de dados diariamente, temos um banco de dados Elasticsearch para filtragem e busca rápida dos dados.
Agora, os usuários estão todos conectados uns aos outros, então precisamos de um banco de dados gráfico para representar essas conexões. Além disso, nossa aplicação tem muito conteúdo de mídia que os usuários compartilham entre si diariamente, e para isso, temos um banco de dados de documentos. Finalmente, para melhor desempenho da aplicação, temos um serviço de cache que armazena em cache os dados de outros bancos de dados e os torna acessíveis mais rapidamente.
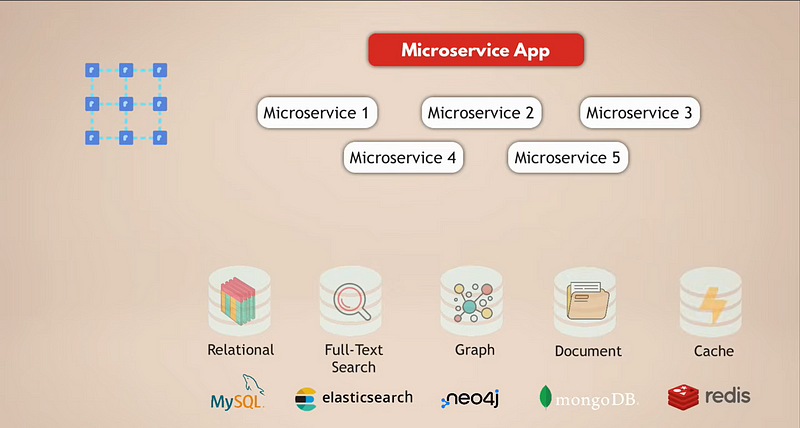
Agora, é óbvio que esta é uma configuração bastante complexa. Vamos ver quais são os desafios dessa configuração:
1. Implantação e Manutenção
Todos esses serviços de dados precisam ser implantados, executados e mantidos. Isso significa que sua equipe precisa ter algum tipo de conhecimento sobre como operar todos esses serviços de dados.
2. Escalabilidade e Requisitos de Infraestrutura
Para alta disponibilidade e melhor desempenho, você vai querer escalar seus serviços. Cada um desses serviços de dados escala de forma diferente e tem diferentes requisitos de infraestrutura, e isso pode ser um desafio adicional. Portanto, no geral, usar vários serviços de dados para sua aplicação aumenta o esforço de manutenção de toda a configuração da sua aplicação.
3. Custos na Nuvem
Claro, como uma alternativa mais fácil para executar e gerenciar os serviços você mesmo, você pode utilizar os serviços de dados gerenciados de provedores de nuvem. Mas isso pode ser muito caro, porque, nas plataformas de nuvem, você paga por cada serviço de dados gerenciado separadamente.
4. Complexidade de Desenvolvimento
5. Latência Mais Alta
Por que o Redis Simplifica Essa Complexidade
Em comparação com um banco de dados multimodal como o Redis, você resolve a maioria desses desafios:
- Serviço de dados único. Você executa e mantém apenas um serviço de dados. Então, sua aplicação também precisa se comunicar com um único armazenamento de dados, o que significa apenas uma interface programática para esse serviço de dados.
- Latência reduzida. A latência será reduzida ao acessar um único ponto de dados e eliminar várias etapas internas de rede.
- Múltiplos tipos de dados em um só. Ter um banco de dados como o Redis que permite armazenar diferentes tipos de dados (ou seja, múltiplos tipos de bancos de dados em um único) bem como atuar como um cache resolve tais desafios.
Como o Redis Suporta Múltiplos Formatos de Dados
Então, vamos ver como o Redis realmente funciona. Em primeiro lugar, como o Redis suporta múltiplos formatos de dados em um único banco de dados?
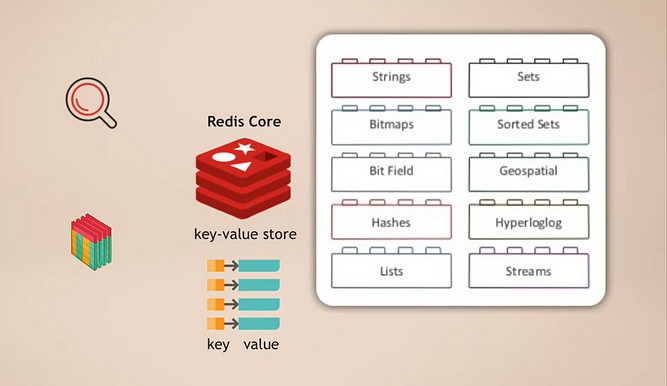
Núcleo do Redis e Módulos
A maneira como funciona é que você tem o Redis core, que é um armazenamento chave-valor que já suporta o armazenamento de vários tipos de dados. Em seguida, você pode estender esse core com o que é chamado de módulos para diferentes tipos de dados, que sua aplicação precisa para diferentes fins. Por exemplo:
- RedisSearch para funcionalidade de pesquisa (como Elasticsearch)
- RedisGraph para armazenamento de dados de grafo
Uma grande vantagem disso é que é modular. Esses diferentes tipos de funcionalidades de banco de dados não estão intimamente integrados em um banco de dados como em muitos outros bancos de dados multimodais, mas sim, você pode escolher exatamente qual funcionalidade de serviço de dados você precisa para sua aplicação e basicamente adicionar esse módulo.
Cache Incorporado
E, é claro, ao usar o Redis como banco de dados principal, você não precisa de um cache adicional porque você já tem isso automaticamente pronto para uso com o Redis. Isso significa, novamente, menos complexidade em sua aplicação porque você não precisa implementar a lógica para gerenciar, popular e invalidar o cache.
Alto Desempenho e Testes Mais Rápidos
Finalmente, como um banco de dados em memória, o Redis é super rápido e eficiente, o que, é claro, torna a aplicação em si mais rápida. Além disso, também torna a execução dos testes da aplicação muito mais rápida, pois o Redis não precisa de um esquema como outros bancos de dados. Portanto, não é necessário tempo para inicializar o banco de dados, construir o esquema, e assim por diante antes de executar os testes. Você pode começar com um banco de dados Redis vazio toda vez e gerar dados para os testes conforme necessário. Testes rápidos podem realmente aumentar a produtividade do seu desenvolvimento.
Persistência de Dados no Redis
Nós entendemos como o Redis funciona e todos os seus benefícios. Mas, neste ponto, você pode estar se perguntando: Como um banco de dados em memória pode persistir dados? Pois se o processo do Redis ou o servidor em que o Redis está sendo executado falhar, todos os dados em memória desaparecem, certo? E se eu perder os dados, como posso recuperá-los? Basicamente, como posso ter certeza de que meus dados estão seguros?
A maneira mais simples de ter backups de dados é replicando o Redis. Portanto, se a instância mestre do Redis falhar, as réplicas ainda estarão em execução e terão todos os dados. Se você tiver um Redis replicado, as réplicas terão os dados. Mas é claro, se todas as instâncias do Redis falharem, você perderá os dados porque não haverá nenhuma réplica restante.
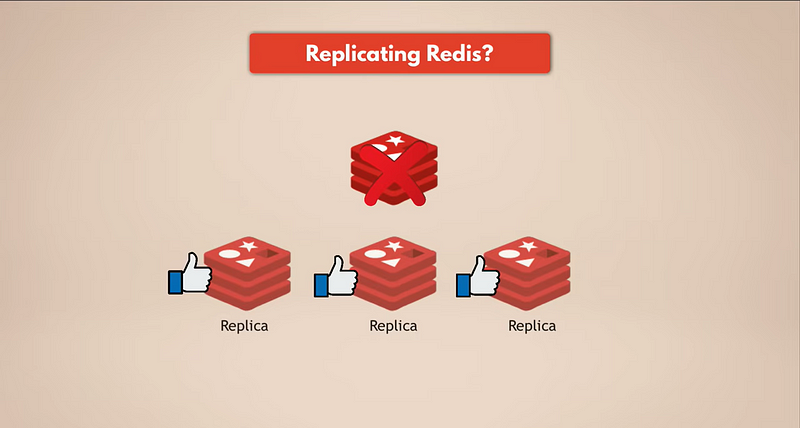
Precisamos de real persistência.
Snapshot (RDB)
O Redis possui múltiplos mecanismos para persistir os dados e mantê-los seguros. O primeiro é instantâneas, que você pode configurar com base no tempo, no número de solicitações, etc. As instantâneas dos seus dados serão armazenadas em um disco, que você pode usar para recuperar seus dados caso o banco de dados Redis inteiro desapareça. Mas note que você perderá os últimos minutos de dados, pois geralmente você faz instantâneas a cada cinco minutos ou uma hora, dependendo das suas necessidades.
AOF (Arquivo Somente Anexo)
Como alternativa, o Redis usa algo chamado AOF, que significa Arquivo Somente Anexo. Neste caso, cada alteração é salva no disco para persistência continuamente. Ao reiniciar o Redis ou após uma queda, o Redis irá reproduzir os logs do Arquivo Somente Anexo para reconstruir o estado. Assim, o AOF é mais durável, mas pode ser mais lento do que as instantâneas.
Combinação de Instantâneas e AOF
E, claro, você também pode usar uma combinação de AOF e instantâneas, onde o arquivo somente anexo está persistindo dados da memória para o disco continuamente, além de você ter instantâneas regulares entre elas para salvar o estado dos dados caso precise recuperá-lo. Isso significa que mesmo se o banco de dados Redis em si ou os servidores, a infraestrutura subjacente onde o Redis está rodando, falharem, você ainda terá todos os seus dados seguros e poderá facilmente recriar e reiniciar um novo banco de dados Redis com todos os dados.
Onde Está Esse Armazenamento Persistente?
Uma pergunta muito interessante é: onde está esse armazenamento persistente? Então, onde está aquele disco que contém suas instantâneas e os logs do arquivo somente anexo? Eles estão nos mesmos servidores onde o Redis está rodando?
Esta questão na verdade nos leva à tendência ou melhor prática de persistência de dados em ambientes de nuvem, que é que é sempre melhor separar os servidores que executam sua aplicação e serviços de dados do armazenamento persistente que armazena seus dados.
Com um exemplo específico: Se suas aplicações e serviços são executados na nuvem, digamos, em uma instância AWS EC2, você deve usar EBS ou Armazenamento de Bloco Elástico para persistir seus dados em vez de armazená-los no disco rígido da instância EC2. Porque se essa instância EC2 falhar, você não terá acesso a nenhum de seus armazenamentos, seja RAM ou armazenamento em disco ou o que quer que seja. Então, se você deseja persistência e durabilidade para seus dados, você deve colocar seus dados fora das instâncias em um armazenamento de rede externo.
Como resultado, ao separar esses dois elementos, se a instância do servidor falhar ou se todas as instâncias falharem, você ainda terá o disco e todos os dados nele, sem serem afetados. Basta iniciar outras instâncias e obter os dados do EBS, e pronto. Isso torna sua infraestrutura muito mais fácil de gerenciar, porque cada servidor é igual; você não tem nenhum servidor especial com dados ou arquivos especiais nele. Então, não importa se você perder toda a sua infraestrutura, porque você pode simplesmente recriar uma nova e recuperar os dados de um armazenamento separado, e está tudo pronto para continuar.
Voltando ao exemplo do Redis, o serviço Redis estará em execução nos servidores e usando a RAM do servidor para armazenar os dados, enquanto os logs de arquivos somente de apêndice e instantâneos serão persistidos em um disco fora desses servidores, tornando seus dados mais duráveis.
Otimização de Custos com Redis em Flash
Agora sabemos que você pode persistir dados com Redis para durabilidade e recuperação, enquanto usa RAM ou armazenamento em memória para ótimo desempenho e velocidade. Então, a pergunta que você pode ter aqui é: Armazenar dados em memória não é caro? Porque você precisaria de mais servidores em comparação a um banco de dados que armazena dados no disco, simplesmente porque a memória é limitada em tamanho. Há um trade-off entre custo e desempenho.
Bem, o Redis na verdade tem uma maneira de otimizar isso usando um serviço chamado Redis em Flash, que faz parte do Redis Enterprise.
Como o Redis em Flash Funciona
É um conceito bem simples, na verdade: o Redis em Flash estende a RAM para a unidade flash ou SSD, onde valores frequentemente usados são armazenados em RAM e os que são usados com menos frequência são armazenados no SSD. Então, para o Redis, é apenas mais RAM no servidor. Isso significa que o Redis pode usar mais da infraestrutura subjacente ou dos recursos do servidor subjacente, usando tanto RAM quanto unidade SSD para armazenar os dados, aumentando a capacidade de armazenamento em cada servidor e, dessa forma, economizando custos de infraestrutura.
Escalando o Redis: Replicação e Sharding
Já falamos sobre armazenamento de dados para o banco de dados Redis e como tudo funciona, incluindo as melhores práticas. Agora, outro tópico muito interessante é como escalamos um banco de dados Redis?
Replicação e Alta Disponibilidade
Vamos supor que minha única instância Redis fique sem memória, então os dados se tornam grandes demais para serem mantidos na memória, ou o Redis se torna um gargalo e não consegue lidar com mais solicitações. Nesse caso, como posso aumentar a capacidade e o tamanho da memória do meu banco de dados Redis?
Temos várias opções para isso. Primeiro de tudo, o Redis suporta clustering, o que significa que você pode ter uma instância primária ou mestre do Redis que pode ser usada para ler e gravar dados, e você pode ter várias réplicas dessa instância primária para leitura dos dados. Dessa forma, você pode escalar o Redis para lidar com mais solicitações e, além disso, aumentar a alta disponibilidade do seu banco de dados. Se o mestre falhar, uma das réplicas pode assumir, e seu banco de dados Redis pode basicamente continuar funcionando sem problemas.
Essas réplicas manterão todas cópias dos dados da instância primária. Portanto, quanto mais réplicas você tiver, mais espaço de memória precisará. E um servidor pode não ter memória suficiente para todas as suas réplicas. Além disso, se você tiver todas as réplicas em um servidor e esse servidor falhar, todo o seu banco de dados Redis estará perdido, e você terá um tempo de inatividade. Em vez disso, você quer distribuir essas réplicas entre vários nós ou servidores. Por exemplo, sua instância mestre estará em um nó e duas réplicas nos outros dois nós.
Sharding para Conjuntos de Dados Maiores
Bem, isso parece bom o suficiente, mas e se seu conjunto de dados crescer muito e não couber na memória de um único servidor? Além disso, escalamos as leituras no banco de dados, então todas as solicitações basicamente apenas consultam os dados, mas nossa instância mestre ainda está sozinha e ainda precisa lidar com todas as gravações. Então, qual é a solução aqui?

Para isso, utilizamos o conceito de sharding, que é um conceito geral em bancos de dados e que o Redis também suporta. Sharding basicamente significa que você pega seu conjunto de dados completo e divide em pedaços menores ou subconjuntos de dados, onde cada shard é responsável por seu próprio subconjunto de dados.
Isso significa que, em vez de ter uma instância mestre que lida com todas as gravações no conjunto de dados completo, você pode dividi-lo em, digamos, quatro shards, cada um responsável por leituras e gravações em um subconjunto dos dados. Cada shard também precisa de menos capacidade de memória porque ele só tem um quarto dos dados. Isso significa que você pode distribuir e executar shards em nós menores e basicamente escalar seu cluster horizontalmente. E, é claro, à medida que seu conjunto de dados cresce e você precisa de ainda mais recursos, você pode re-shardar seu banco de dados Redis, o que basicamente significa que você apenas divide seus dados em pedaços ainda menores e cria mais shards.

Portanto, ter vários nós que executam várias réplicas do Redis, todos sharded, lhe dá um banco de dados Redis muito performático e altamente disponível que pode lidar com muito mais solicitações sem criar gargalos.
Agora, devo observar aqui que essa configuração é ótima, mas você precisaria gerenciá-la sozinho, fazer o escalonamento, adicionar nós, fazer o sharding e depois o re-sharding, etc. Para algumas equipes que estão mais focadas no desenvolvimento de aplicativos e na lógica de negócios do que em executar e manter serviços de dados, isso poderia ser um esforço indesejado. Portanto, como uma alternativa mais fácil, no Redis Enterprise, você obtém esse tipo de configuração automaticamente porque o escalonamento, o sharding e assim por diante são todos gerenciados para você.
Replicação Global com Redis: Implantação Ativa-Ativa
Vamos considerar outro cenário interessante para aplicações que precisam de ainda maior disponibilidade e desempenho em várias localizações geográficas. Então, digamos que tenhamos este cluster de banco de dados Redis replicado e particionado em uma região, no centro de dados de Londres, Europa. Mas temos os dois seguintes casos de uso:
- Nossos usuários estão distribuídos geograficamente, então estão acessando a aplicação de todo o mundo. Queremos distribuir nossos serviços de aplicação e dados globalmente, próximos aos usuários, para dar aos nossos usuários um melhor desempenho.
- Se o centro de dados completo em Londres, Europa, por exemplo, falhar, queremos uma mudança imediata para outro centro de dados para que o serviço Redis permaneça disponível. Em outras palavras, queremos réplicas de todo o cluster Redis em centros de dados em múltiplas localizações geográficas ou regiões.
Múltiplos Clusters Redis em Diferentes Regiões
Isto significa que um único dado deve ser replicado para muitos clusters espalhados por múltiplas regiões, com cada cluster sendo totalmente capaz de aceitar leituras e escritas. Nesse caso, você teria múltiplos clusters Redis que atuariam como instâncias locais do Redis em cada região, e os dados seriam sincronizados entre esses clusters distribuídos geograficamente. Isso é uma funcionalidade disponível no Redis Enterprise e é chamada de implantação ativa-ativa porque você tem múltiplas bases de dados ativas em diferentes localizações.

Com essa configuração, teremos menor latência para os usuários. E mesmo que o banco de dados Redis em uma região falhe completamente, as outras regiões não serão afetadas. Se a conexão ou sincronização entre as regiões for interrompida por um curto período de tempo devido a algum problema de rede, por exemplo, os clusters Redis nessas regiões podem atualizar os dados de forma independente, e uma vez que a conexão seja restabelecida, eles podem sincronizar essas alterações novamente.
Resolução de Conflitos Com CRDTs
Agora, é claro, quando você ouve isso, a primeira pergunta que pode surgir em sua mente é: Como o Redis resolve as alterações em várias regiões para o mesmo conjunto de dados? Então, se os mesmos dados mudam em várias regiões, como o Redis garante que as alterações de dados de qualquer região não sejam perdidas e os dados sejam sincronizados corretamente, e como ele garante a consistência dos dados?
Especificamente, o Redis Enterprise usa um conceito chamado CRDTs, que significa tipos de dados replicados sem conflito, e esse conceito é usado para resolver automaticamente quaisquer conflitos no nível do banco de dados e sem perda de dados. Basicamente, o Redis em si possui um mecanismo para mesclar as alterações feitas no mesmo conjunto de dados a partir de várias fontes de maneira que nenhuma das alterações de dados seja perdida e quaisquer conflitos sejam resolvidos corretamente. E como, como você aprendeu, o Redis suporta vários tipos de dados, cada tipo de dado usa suas próprias regras de resolução de conflitos de dados, que são as mais adequadas para aquele tipo de dado específico.

Simplificando, em vez de apenas substituir as alterações de uma fonte e descartar todas as outras, todas as alterações paralelas são mantidas e resolvidas de forma inteligente. Novamente, isso é feito automaticamente para você com este recurso de replicação geográfica ativa-ativa, então você não precisa se preocupar com isso.
Executando Redis no Kubernetes
E o último tópico que quero abordar com o Redis é executar Redis no Kubernetes. Como eu disse, o Redis é uma ótima opção para microserviços complexos que precisam suportar múltiplos tipos de dados e que necessitam de uma escalabilidade fácil de um banco de dados sem se preocupar com a consistência dos dados. E também sabemos que o novo padrão para executar microserviços é a plataforma Kubernetes. Assim, executar Redis no Kubernetes é um caso de uso muito interessante e comum. Então, como isso funciona?

Redis Open Source no Kubernetes
Com o Redis de código aberto, você pode implantar o Redis replicado como um gráfico Helm ou arquivos de manifesto do Kubernetes e, basicamente, usando as regras de replicação e escalabilidade que já discutimos, configurar e executar um banco de dados Redis altamente disponível. A única diferença seria que os hosts onde o Redis será executado serão pods do Kubernetes em vez de, por exemplo, instâncias EC2 ou qualquer outro servidor físico ou virtual. Mas os mesmos conceitos de sharding, replicação e escalabilidade se aplicam aqui também quando você deseja executar um cluster Redis no Kubernetes, e você basicamente teria que gerenciar essa configuração por conta própria.
Operador Redis Enterprise
No entanto, como mencionei, muitas equipes não querem fazer o esforço de manter esses serviços de terceiros porque preferem investir seu tempo e recursos no desenvolvimento de aplicativos ou em outras tarefas. Portanto, ter uma alternativa mais fácil também é importante aqui. O Redis Enterprise possui um cluster Redis gerenciado, que você pode implantar como um operador Kubernetes.

Se você não conhece operadores, um operador no Kubernetes é basicamente um conceito onde você pode agrupar todos os recursos necessários para operar um determinado aplicativo ou serviço, de modo que você não precise gerenciá-lo você mesmo ou não precise operá-lo você mesmo. Em vez de um humano operar um banco de dados, você basicamente tem toda essa lógica em uma forma automatizada para operar um banco de dados para você. Muitos bancos de dados têm operadores para Kubernetes, e cada um desses operadores tem, claro, sua própria lógica baseada em quem os escreveu e como os escreveu.
O operador Redis Enterprise no Kubernetes automatiza especificamente a implantação e configuração de todo o banco de dados Redis em seu cluster Kubernetes. Ele também cuida da escalabilidade, realiza backups e recupera o cluster Redis se necessário, etc. Assim, ele assume a operação completa do cluster Redis dentro do cluster Kubernetes.
Conclusão
Espero que você tenha aprendido muito neste blog e que eu tenha conseguido responder a muitas de suas perguntas. Se você quiser aprender mais sobre tecnologias e conceitos semelhantes, então certifique-se de me seguir, pois escrevo blogs regularmente sobre IA, DevOps e tecnologias em nuvem.
Além disso, comente abaixo se você tiver alguma dúvida sobre o Redis ou sugestões de novos tópicos. E com isso, obrigado por ler e até o próximo blog.
Vamos nos conectar no LinkedIn!
Source:
https://dzone.com/articles/redis-as-a-primary-database-for-complex-applications