













Nos últimos anos, os transformadores transformaram o domínio de NLP em aprendizado de máquina. Modelos como GPT e BERT estabeleceram novos padrões na compreensão e geração da linguagem humana. Agora, o mesmo princípio está sendo aplicado ao domínio da visão computacional.
Um desenvolvimento recente no campo da visão computacional são os transformadores de visão ou ViTs. Como detalhado no artigo “Uma Imagem Vale 16×16 Palavras: Transformadores para Reconhecimento de Imagens em Escala”, os ViTs e os modelos baseados em transformadores foram projetados para substituir as redes neurais convolucionais (CNNs).
Os Transformadores de Visão oferecem uma nova abordagem para resolver problemas na visão computacional. Em vez de depender das tradicionais redes neurais convolucionais (CNNs), que têm sido a espinha dorsal das tarefas relacionadas a imagens por décadas, os ViTs usam a arquitetura de transformadores para processar imagens. Eles tratam os pedaços da imagem como palavras em uma frase, permitindo que o modelo aprenda as relações entre esses pedaços, assim como aprende o contexto em um parágrafo de texto.
Ao contrário das CNNs, os ViTs dividem as imagens de entrada em partes, serializam-nas em vetores e reduzem sua dimensionalidade usando multiplicação de matrizes. Um codificador transformer então processa esses vetores como embeddings de tokens. Neste artigo, exploraremos os transformers de visão e suas principais diferenças em relação às redes neurais convolucionais. O que os torna particularmente interessantes é sua capacidade de entender padrões globais em uma imagem, algo com o qual as CNNs podem ter dificuldades.
Pré-requisitos
- Fundamentos das Redes Neurais: Compreensão de como as redes neurais processam dados.
- Redes Neurais Convolucionais (CNNs): Familiaridade com as CNNs e seu papel na visão computacional.
- Arquitetura Transformer: Conhecimento sobre transformers, especialmente seu uso em PNL.
- Processamento de Imagens: Compreensão de conceitos básicos como representação de imagens, canais e matrizes de pixels.
- Mecanismo de Atenção: Compreensão da autoatenção e sua capacidade de modelar relações entre entradas.
O que são transformers de visão?
Transformadores de visão usam o conceito de atenção e transformadores para processar imagens—isso é semelhante aos transformadores em um contexto de processamento de linguagem natural (PLN). No entanto, em vez de usar tokens, a imagem é dividida em patches e fornecida como uma sequência de embeddings lineares. Esses patches são tratados da mesma forma que tokens ou palavras são tratados em PLN.
Em vez de olhar para a imagem inteira simultaneamente, um ViT corta a imagem em pequenos pedaços como um quebra-cabeça. Cada pedaço é transformado em uma lista de números (um vetor) que descreve suas características, e então o modelo observa todos os pedaços e descobre como eles se relacionam entre si usando um mecanismo de transformador.
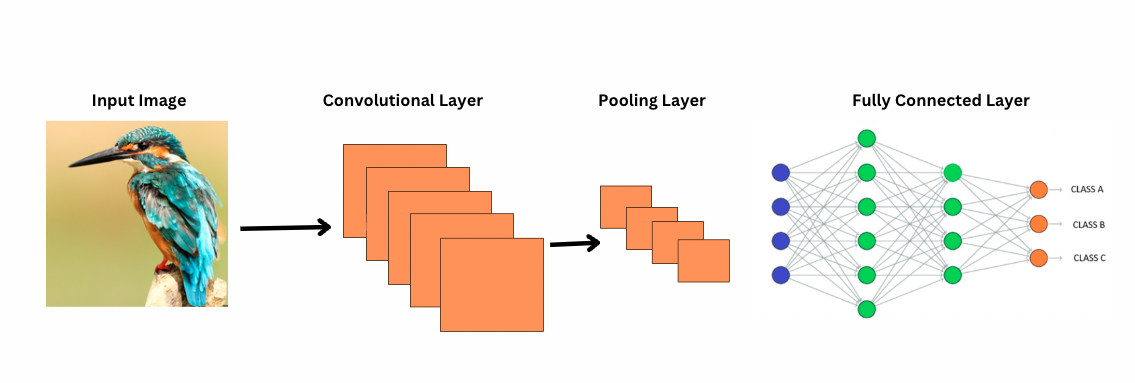
Diferente das CNNs, ViTs funcionam aplicando filtros ou núcleos específicos sobre uma imagem para detectar características específicas, como padrões de borda. Este é o processo de convolução que é muito semelhante a uma impressora digitalizando uma imagem. Esses filtros deslizam por toda a imagem e destacam características significativas. A rede então empilha múltiplas camadas desses filtros, identificando gradualmente padrões mais complexos.
Com as CNNs, camadas de pooling reduzem o tamanho dos mapas de características. Essas camadas analisam as características extraídas para fazer previsões úteis para reconhecimento de imagem, detecção de objetos, etc. No entanto, as CNNs têm um campo receptivo fixo, limitando assim a capacidade de modelar dependências de longo alcance.
Como as CNNs veem imagens?
ViTs, apesar de terem mais parâmetros, utilizam mecanismos de autoatenção para uma melhor representação de características e reduzir a necessidade de camadas mais profundas. CNNs exigem uma arquitetura significativamente mais profunda para alcançar um poder representacional similar, o que leva a um aumento no custo computacional.
Além disso, as CNNs não conseguem capturar padrões de imagem em nível global porque seus filtros se concentram em regiões locais da imagem. Para entender a imagem inteira ou as relações distantes, as CNNs dependem de empilhar muitas camadas e pooling, expandindo o campo de visão. No entanto, esse processo pode perder informações globais à medida que agrega detalhes passo a passo.
Por outro lado, os ViTs dividem a imagem em patches que são tratados como tokens de entrada individuais. Usando autoatenção, os ViTs comparam todos os patches simultaneamente e aprendem como eles se relacionam. Isso permite que capturem padrões e dependências em toda a imagem sem construí-los camada por camada.
O que é Viés Indutivo?
Antes de prosseguir, é importante entender o conceito de viés indutivo. Viés indutivo refere-se à suposição que um modelo faz sobre a estrutura dos dados; durante o treinamento, isso ajuda o modelo a ser mais generalizado e reduzir o viés. Nas CNNs, os viéses indutivos incluem:
- Localidade: As características em imagens (como bordas ou texturas) são localizadas em pequenas regiões.
- **Estrutura de vizinhança bidimensional**: Os pixels próximos têm mais probabilidade de estar relacionados, então os filtros atuam em regiões adjacentes espacialmente.
- **Equivalência de tradução**: Recursos detectados em uma parte da imagem, como uma borda, mantêm o mesmo significado se aparecerem em outra parte.
Esses vieses tornam as CNNs altamente eficientes para tarefas de imagem, pois são projetadas de forma inerente para explorar propriedades espaciais e estruturais das imagens.
Os Transformadores de Visão (ViTs) têm significativamente menos vieses indutivos específicos de imagem do que as CNNs. Nos ViTs:
- **Processamento global**: As camadas de autoatenção operam em toda a imagem, permitindo que o modelo capture relacionamentos e dependências globais sem ser restrito por regiões locais.
- **Estrutura 2D mínima**: A estrutura 2D da imagem é usada apenas no início (quando a imagem é dividida em patches) e durante o ajuste fino (para ajustar os embeddings posicionais para diferentes resoluções). Ao contrário das CNNs, os ViTs não assumem que pixels próximos são necessariamente relacionados.
- **Relações espaciais aprendidas**: Os embeddings posicionais nos ViTs não codificam relações espaciais 2D específicas na inicialização. Em vez disso, o modelo aprende todas as relações espaciais a partir dos dados durante o treinamento.
**Como os Transformadores de Visão Funcionam**
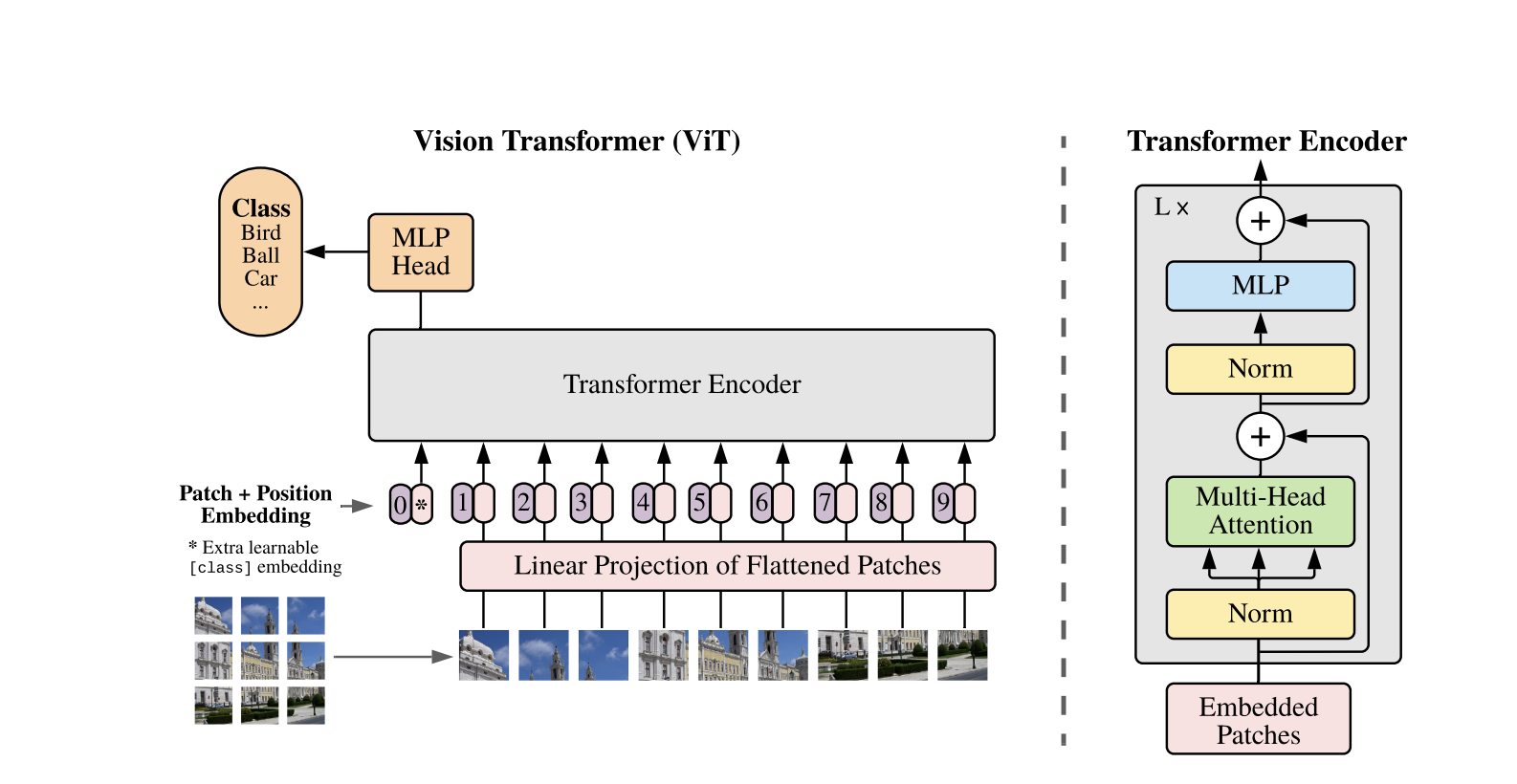
Os Vision Transformers usam a arquitetura padrão de Transformer desenvolvida para sequências de texto 1D. Para processar as imagens 2D, elas são divididas em pequenos patches de tamanho fixo, como P P pixels, que são achatados em vetores. Se a imagem tiver dimensões H W com C canais, o número total de patches é N = H W / P P, que é o comprimento efetivo da sequência de entrada para o Transformer. Esses patches achatados são então projetados linearmente em um espaço de dimensão fixa D, chamado de embutimentos de patch.
Um token especial aprendível, semelhante ao token [CLS] no BERT, é adicionado ao início da sequência de embutimentos de patch. Esse token aprende uma representação global da imagem que é posteriormente usada para classificação. Além disso, embutimentos posicionais são adicionados aos embutimentos de patch para codificar informações posicionais, ajudando o modelo a entender a estrutura espacial da imagem.
A sequência de embeddings é passada pelo codificador Transformer, que alterna entre duas operações principais: Autoatenção Multi-Cabeça (MSA) e uma rede neural feedforward, também chamada de bloco MLP. Cada camada inclui Normalização de Camada (LN) aplicada antes dessas operações e conexões residuais adicionadas posteriormente para estabilizar o treinamento. A saída do codificador Transformer, especificamente o estado do token [CLS], é usada como representação da imagem.
Uma cabeça simples é adicionada ao token [CLS] final para tarefas de classificação. Durante o pré-treinamento, essa cabeça é um pequeno perceptron multi-camadas (MLP), enquanto no ajuste fino, geralmente é uma única camada linear. Essa arquitetura permite que os ViTs modelem efetivamente as relações globais entre os patches e utilizem todo o poder da autoatenção para compreender a imagem.
Em um modelo híbrido de Vision Transformer, em vez de dividir diretamente as imagens brutas em patches, a sequência de entrada é derivada de mapas de características gerados por uma CNN. A CNN processa a imagem primeiro, extraindo características espaciais significativas, que são então usadas para criar patches. Esses patches são achatados e projetados em um espaço de dimensão fixa usando a mesma projeção linear treinável que nos Vision Transformers padrão. Um caso especial dessa abordagem é usar patches de tamanho 1×1, onde cada patch corresponde a uma única localização espacial no mapa de características da CNN.
Neste caso, as dimensões espaciais do mapa de características são achatadas, e a sequência resultante é projetada na dimensão de entrada do Transformer. Assim como no ViT padrão, um token de classificação e incorporações posicionais são adicionados para manter informações posicionais e permitir o entendimento global da imagem. Esta abordagem híbrida aproveita as forças de extração de características locais das CNNs enquanto as combina com as capacidades de modelagem global dos Transformers.
Exemplo de Código
Aqui está o bloco de código sobre como usar os transformadores de visão em imagens.
O modelo ViT processa a imagem. Ele compreende um codificador semelhante ao BERT e uma cabeça de classificação linear situada no topo do estado oculto final do token [CLS].
Aqui está uma implementação básica do Vision Transformer (ViT) usando o PyTorch. Este código inclui os componentes principais: incorporação de patches, codificação posicional e o codificador Transformer. Isso pode ser usado para tarefas simples de classificação.
Componentes Chave:
- Incorporação de Patch: As imagens são divididas em patches menores, achatadas e transformadas linearmente em embeddings.
- Codificação Posicional: Informações de posição são adicionadas às incorporações de patch, já que os Transformers são agnósticos em relação à posição.
- Codificador Transformer: Aplica autoatenção e camadas feed-forward para aprender relacionamentos entre os patches.
- Cabeçalho de Classificação: Saídas as probabilidades de classe usando o token CLS.
Você pode treinar este modelo em qualquer conjunto de dados de imagem usando um otimizador como Adam e uma função de perda como a entropia cruzada. Para melhor desempenho, considere pré-treinar em um conjunto de dados grande antes do ajuste fino.
Trabalhos de Acompanhamento Populares
-
DeiT (Transformadores de Imagem Eficientes em Dados) pela Facebook AI: Estes são transformadores de visão treinados de forma eficiente com destilação de conhecimento. DeiT oferece quatro variantes: deit-tiny, deit-small, e dois modelos deit-base. Use
DeiTImageProcessorpara preparar imagens. -
BEiT (Preparação prévia BERT de Transformadores de Imagem) pela Microsoft Research: Inspirado pelo BERT, o BEiT utiliza modelagem de imagem mascarada auto-supervisionada e supera os ViTs supervisionados. Ele depende do VQ-VAE para treinamento.
-
DINO (Treinamento Auto-supervisionado de Transformadores de Visão) pela Facebook AI: Os ViTs treinados pelo DINO podem segmentar objetos sem treinamento explícito. Pontos de verificação estão disponíveis online.
-
MAE (Autoencoders Mascarados) do Facebook pré-treina ViTs reconstruindo patches mascarados (75%). Quando ajustado, este método simples supera o pré-treinamento supervisionado.
Conclusão
Em conclusão, ViTs são uma excelente alternativa para CNNs, pois aplicam transformers ao reconhecimento de imagens, minimizam o viés indutivo e tratam imagens como patches de sequência. Esta abordagem simples, mas escalável, demonstrou desempenho de ponta em muitos benchmarks de classificação de imagens, especialmente quando combinada com pré-treinamento em grandes conjuntos de dados. No entanto, desafios potenciais permanecem, incluindo a extensão dos ViTs para tarefas como detecção de objetos e segmentação, melhorias adicionais nos métodos de pré-treinamento auto-supervisionado e a exploração do potencial de escalar os ViTs para um desempenho ainda melhor.
Recursos Adicionais
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision