













Introdução
Olá leitores, esse é mais um post em uma série que estamos fazendo sobre PyTorch. Este post é direcionado a usuários de PyTorch que estão familiarizados com os fundamentos do PyTorch e que gostariam de avançar para um nível intermediário. Enquanto nossos posts anteriores abordaram como implementar um classificador básico, neste post, iremos discutir como implementar funções de aprendizado profundo mais complexas usando PyTorch. Algumas das objetivas deste post são tornar você compreensivo.
- O que é a diferença entre as classes de PyTorch como
nn.Module,nn.Functional,nn.Parametere quando usar cada uma - Como personalizar suas opções de treinamento, como diferentes taxas de aprendizado para diferentes camadas, diferentes agendas de taxa de aprendizado
- Inicialização personalizada de pesos
Então, vamos começar.
nn.Module vs nn.Functional
Isso é algo que aparece muito especialmente quando você está lendo código aberto. Em PyTorch, as camadas são frequentemente implementadas como objetos de um de torch.nn.Module ou funções de torch.nn.Functional. Qual usar? Qual é melhor?
Como já abordamos na Parte 2, torch.nn.Module é basicamente a pedra angular de PyTorch. A maneira como funciona é que primeiro você define um objeto nn.Module, e então chama seu método forward para executá-lo. Esta é uma maneira orientada a objetos de fazer as coisas.
Por outro lado, nn.functional fornece algumas camadas/ativações sob a forma de funções que podem ser chamadas diretamente no input em vez de definir um objeto. Por exemplo, para reescalar um tensor de imagem, você chama torch.nn.functional.interpolate em um tensor de imagem.
Então, como escolher o que usar quando? Quando a camada/ativação/perda que estamos implementando tiver uma perda.
Entendendo a Estado-ness
Normalmente, qualquer camada pode ser vista como uma função. Por exemplo, uma operação de convolução é apenas um monte de operações de multiplicação e adição. Então, faz sentido para nós implementá-la como uma função certo? Mas espere, a camada mantém pesos que precisam ser armazenados e atualizados enquanto estamos treinando. Portanto, a partir de uma perspectiva programática, uma camada é mais do que uma função. Ela também precisa manter dados, que mudam conforme treinamos sua rede.
Agora quero que você destaque o fato de que os dados mantidos pela camada convolucional mudam. Isso significa que a camada tem um estado que muda conforme treinamos. Para implementar uma função que realiza a operação de convolução, nós também precisaríamos definir uma estrutura de dados para manter os pesos da camada separadamente da própria função. E depois, tornar essa estrutura de dados externa um input para nossa função.
Ou apenas para evitar o esforço, poderíamos simplesmente definir uma classe para manter a estrutura de dados e fazer a operação de convolução como um membro da função. Isso realmente simplificaria nossa tarefa, já que não precisaríamos se preocupar com variáveis estado fora da função. Nesses casos, preferiríamos usar objetos nn.Module onde temos pesos ou outros estados que podem definir o comportamento da camada. Por exemplo, uma camada de dropout / Batch Norm age de forma diferente durante o treinamento e na inferência.
Por outro lado, onde nenhum estado ou pesos são necessários, poderia-se usar o nn.functional. Exemplos sendo, redimensionar (nn.functional.interpolate), pooling médio (nn.functional.AvgPool2d).
Apesar das razões acima, a maioria das classes nn.Module têm suas contrapartes no nn.functional. No entanto, a linha de raciocínio acima deve ser respeitada durante o trabalho prático.
nn.Parameter
Uma classe importante em PyTorch é a classe nn.Parameter, que surpreendeu-me, pois obteve pouca cobertura em textos de Introdução a PyTorch. Considere o seguinte caso.
Cada nn.Module tem uma função parameters() que retorna, bem, seus parâmetros treináveis. Temos que definir implícitamente o que esses parâmetros são. Na definição de nn.Conv2d, os autores de PyTorch definiram os pesos e bias como parâmetros de uma camada. No entanto, note uma coisa, quando definimos net, não precisamos adicionar os parameters de nn.Conv2d aos parameters de net. Isso acontece implicitamente ao colocar o objeto nn.Conv2d como um membro do objeto net.
Isto é facilitado internamente pela classe nn.Parameter, que é uma subclasse da classe Tensor. Quando chamamos a função parameters() the um objeto nn.Module, ela retorna todos os seus membros que são objetos nn.Parameter.
Na verdade, todos os pesos de treinamento das classes nn.Module são implementados como objetos nn.Parameter. Sempre que um nn.Module (nn.Conv2d no nosso caso) é atribuído como membro de outro nn.Module, os “parâmetros” do objeto atribuído (isto é, os pesos de nn.Conv2d) são também adicionados aos “parâmetros” do objeto ao qual está sendo atribuído (parâmetros do objeto net). Isso é chamado de registro de “parâmetros” the um nn.Module.
Se você tentar atribuir um tensor a um objeto nn.Module, ele não aparecerá na lista de parâmetros do parameters() se você não o definir como um objeto nn.Parameter. Isso foi feito para facilitar os casos onde você pode precisar cachear um tensor não diferenciável, por exemplo, cachear o output anterior em casos de RNNs.
nn.ModuleList e nn.ParameterList()
Eu lembro que eu tive que usar um nn.ModuleList quando eu estava implementando o YOLO v3 no PyTorch. Eu tinha que criar a rede parseando um arquivo de texto que continha a arquitetura. Eu armazenou todos os objetos nn.Module correspondentes em uma lista Python e depois fez a lista um membro de meu objeto nn.Module representando a rede.
Para simplificar, algo como isso.
Como você vê, ao contrário de quando nós registrariamos módulos individuais, atribuir uma Lista Python não registra os parâmetros dos Módulos dentro da lista. Para corrigir isso, nós envolvemos nossa lista com a classe nn.ModuleList e, em seguida, atribuímos como um membro da classe de rede.
Similarmente, uma lista de tensores pode ser registrada envolvendo a lista com uma nn.ParameterList classe.
Inicialização de Pesos
A inicialização de pesos pode influenciar os resultados do seu treinamento. Mais ainda, você pode necessitar de diferentes esquemas de inicialização de pesos para diferentes tipos de camadas. Isso pode ser conseguido pelas funções modules e apply. modules é uma função membro da classe nn.Module que retorna um iterador contendo todos os objetos membros nn.Module de uma função nn.Module. Em seguida, a função apply pode ser chamada em cada nn.Module para definir sua inicialização.
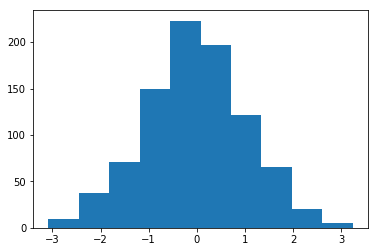
Histograma de pesos inicializados com Média = 1 e std = 1
Existem uma miríade de funções de inicialização inplace encontradas no módulo torch..nn.init.
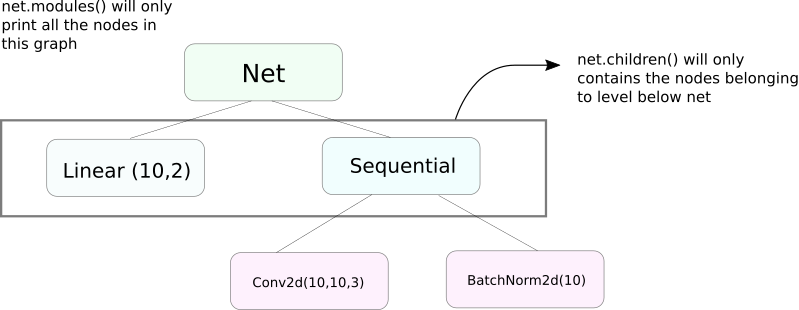
módulos() vs filhos()
Uma função muito semelhante a modules é children. A diferença é pequena, mas importante. Como sabemos, um objeto nn.Module pode conter outros objetos nn.Module como membros de dados.
children() retornará apenas uma lista de objetos nn.Module que são membros de dados do objeto em que children está sendo chamado.
Por outro lado, nn.Modules vai recursivamente dentro de cada objeto nn.Module, criando uma lista de cada objeto nn.Module que aparece no caminho até que não houver mais objetos nn.module. Observe, modules() também retorna o nn.Module em que foi chamado como parte da lista.
Observe que o comentário acima é verdadeiro para todos os objetos/classes que herdam da classe nn.Module.
Então, quando inicializamos os pesos, talvez queira usar a função modules() porque não podemos entrar no objeto nn.Sequential e inicializar o peso para seus membros.
Imprimindo Informações Sobre a Rede
Poderemos precisar imprimir informações sobre a rede, quer seja para o usuário ou para fins de depuração. O PyTorch fornece uma maneira muito legal de imprimir muitas informações sobre sua rede usando suas funções named_*. Existem 4 funções desse tipo.
named_parameters. Retorna um iterador que dá um tuplo contendo nome dos parâmetros (se uma camada convolucional for atribuída comoself.conv1, então seus parâmetros seriamconv1.weighteconv1.bias) e o valor retornado pela função__repr__donn.Parameter
2. named_modules. O mesmo que acima, mas o iterador retorna módulos como a função modules() faz.
3. named_children O mesmo que acima, mas o iterador retorna módulos como a função children() retorna
4. named_buffers Retorna tensores de buffer tais como média móvel de um layer de Normalização de lote.
Diferentes Taxas de Aprendizado para Diferentes Camadas
Nesta seção, vamos aprender a usar diferentes taxas de aprendizado para nossas diferentes camadas. Em geral, vamos cobrir como ter diferentes hiperparâmetros para diferentes grupos de parâmetros, quer seja diferente taxa de aprendizado para diferentes camadas ou diferente taxa de aprendizado para bias e pesos.
A ideia de implementar algo assim é relativamente simples. Na nossa postagem anterior, na qual implementamos um classificador CIFAR, passamos todos os parâmetros da rede como um todo para o objeto optimizador.
No entanto, a classe torch.optim permite que nós fornecamos diferentes conjuntos de parâmetros com diferentes taxas de aprendizado em formato de dicionário.
No cenário acima, os parâmetros de `fc1` usam uma taxa de aprendizado de 0.01 e momento de 0.99. Se um hiperparâmetro não é especificado para um grupo de parâmetros (como `fc2`), eles usam o valor padrão desse hiperparâmetro, fornecido como argumento de entrada para a função optimizadora. Você pode criar listas de parâmetros com base em camadas diferentes, ou seja, se o parâmetro é um peso ou um bias, usando a função named_parameters() que abordamos acima.
Agendamento da Taxa de Aprendizado
Agendar sua taxa de aprendizado é um hiperparâmetro principal que você quer ajustar. O PyTorch fornece suporte para agendar taxas de aprendizado com seu módulo torch.optim.lr_scheduler, que tem uma variedade de agendamentos de taxa de aprendizado. O exemplo seguinte demonstra um exemplo tão simples.
O agendador acima, multiplica a taxa de aprendizagem por gamma cada vez que alcançamos epochs contidos na lista milestones. Em nosso caso, a taxa de aprendizagem é multiplicada por 0.1 no 10nº e no 20nº epoch. Você também terá que escrever a linha scheduler.step no loop no seu código que percorre os epochs para que a taxa de aprendizagem seja atualizada.
Geralmente, o loop de treinamento é composto de dois laços aninhados, onde um loop percorre os epochs e o outro aninhado percorre as batches nesses epochs. Certifique-se de chamar scheduler.step no início do loop de epoch para que sua taxa de aprendizagem seja atualizada. Tome cuidado não escrever em loop de batch, caso contrário sua taxa de aprendizagem pode ser atualizada no 10º batch e não no 10nº epoch.
Também lembre-se que scheduler.step não é um substituto para optim.step e você precisará chamar optim.step toda vez que você realizar backpropagation para trás. (Isto aconteceria no “loop de batch”).
Salvando seu Modelo
Você pode querer salvar seu modelo para uso posterior em inferência ou talvez queira criar pontos de verificação de treinamento. Quando se trata de salvar modelos no PyTorch, tem duas opções.
A primeira é usar torch.save. Isto é equivalente a serializar todo o objeto nn.Module usando Pickle. Este método salva todo o modelo no disco. Você pode carregar este modelo posteriormente na memória com torch.load.
O texto acima salva todo o modelo com pesos e arquitetura. Se você precisar apenas salvar os pesos, em vez de salvar todo o modelo, você pode salvar apenas o state_dict do modelo. O state_dict é basicamente um dicionário que mapeia os objetos nn.Parameter de uma rede para seus valores.
Como mostrado acima, é possível carregar um state_dict existente em um objeto nn.Module. Observe que isso não envolve salvar todo o modelo, mas apenas os parâmetros. Você precisará criar a rede com camadas antes de carregar o state dict. Se a arquitetura da rede não for exatamente a mesma que a do state_dict que você salvou, o PyTorch lançará um erro.
Um objeto de otimizador do torch.optim também tem um objeto state_dict que é usado para armazenar os hiperparâmetros dos algoritmos de otimização. Ele pode ser salvo e carregado de forma semelhante à que fizemos acima, chamando load_state_dict the um objeto de otimizador.
Conclusão
Isso conclui nossa discussão sobre algumas funcionalidades avançadas do PyTorch. Espero que as coisas que você leu neste post o ajude a implementar ideias complexas de aprendizado profundo que você pode ter criado. Aqui estão links para estudos futuros caso você se interesse.
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced