













Inleiding
Meervoudige lineaire regressie is een fundamentele statistische techniek die wordt gebruikt om de relatie tussen één afhankelijke variabele en meerdere onafhankelijke variabelen te modelleren. In Python bieden tools zoals scikit-learn en statsmodels robuuste implementaties voor regressieanalyse. Deze tutorial begeleidt je bij het implementeren, interpreteren en evalueren van meervoudige lineaire regressiemodellen met behulp van Python.
Vereisten
Voordat je in de implementatie duikt, zorg ervoor dat je het volgende hebt:
- Basisbegrip van Python. Je kunt verwijzen naar Python Tutorial voor Beginners.
- Bekendheid met scikit-learn voor machine learning taken. Je kunt verwijzen naar Python scikit-learn Tutorial.
- Begrip van datavisualisatieconcepten in Python. Je kunt verwijzen naar Hoe gegevens te plotten in Python 3 met matplotlib en Data-analyse en visualisatie met pandas en Jupyter Notebook in Python 3.
- Python 3.x geïnstalleerd met de volgende bibliotheken
numpy,pandas,matplotlib,seaborn,scikit-learnenstatsmodelsgeïnstalleerd.
Wat is meervoudige lineaire regressie?
Meervoudige lineaire regressie (MLR) is een statistische methode die de relatie tussen een afhankelijke variabele en twee of meer onafhankelijke variabelen modelleert. Het is een uitbreiding van eenvoudige lineaire regressie, die de relatie tussen een afhankelijke variabele en een enkele onafhankelijke variabele modelleert. In MLR wordt de relatie gemodelleerd met de formule:
.png)
Waar:
.png)
Voorbeeld: Het voorspellen van de prijs van een huis op basis van de grootte, het aantal slaapkamers en de locatie. In dit geval zijn er drie onafhankelijke variabelen, namelijk grootte, aantal slaapkamers en locatie, en één afhankelijke variabele, namelijk prijs, die de waarde is die voorspeld moet worden.
Aannames van Meervoudige Lineaire Regressie
Voordat meervoudige lineaire regressie wordt toegepast, is het essentieel om ervoor te zorgen dat aan de volgende aannames wordt voldaan:
-
Lineariteit: De relatie tussen de afhankelijke variabele en de onafhankelijke variabelen is lineair.
-
Onafhankelijkheid van Fouten: Residuen (fouten) zijn onafhankelijk van elkaar. Dit wordt vaak geverifieerd met de Durbin-Watson test.
-
Homoscedasticiteit: De variantie van de residuen is constant over alle niveaus van de onafhankelijke variabelen. Een residuplot kan helpen dit te verifiëren.
-
Geen Multicollineariteit: Onafhankelijke variabelen zijn niet sterk gecorreleerd. Variance Inflation Factor (VIF) wordt vaak gebruikt om multicollineariteit te detecteren.
-
Normaliteit van Residuen: Residuen moeten een normale verdeling volgen. Dit kan worden gecontroleerd met een Q-Q plot.
-
Invloed van Uitschieters: Uitschieters of hoog-leveraged punten mogen het model niet onevenredig beïnvloeden.
Deze aannames zorgen ervoor dat het regressiemodel geldig is en de resultaten betrouwbaar zijn. Het niet voldoen aan deze aannames kan leiden tot bevooroordeelde of misleidende resultaten.
Gegevens Voorbereiden
In deze sectie leer je het Multiple Linear Regression-model in Python te gebruiken om woningprijzen te voorspellen op basis van kenmerken uit de California Housing Dataset. Je leert hoe je gegevens voorbereidt, een regressiemodel past en de prestaties evalueert, terwijl je veelvoorkomende uitdagingen zoals multicollineariteit, uitschieters en kenmerkselectie aanpakt.
Stap 1 – Laad de Dataset
Je zult de California Housing Dataset gebruiken, een populaire dataset voor regressietaken. Deze dataset bevat 13 kenmerken over huizen in de voorsteden van Boston en hun bijbehorende mediane woningprijs.
Eerst installeren we de benodigde pakketten:
Je zou de volgende uitvoer van de dataset moeten observeren:
Hier is wat elk van de attributen betekent:
| Variable | Description |
|---|---|
| MedInc | Mediaan inkomen in blok |
| HouseAge | Mediaan huis leeftijd in blok |
| AveRooms | Gemiddeld aantal kamers |
| AveBedrms | Gemiddeld aantal slaapkamers |
| Population | Blok populatie |
| AveOccup | Gemiddelde woningbezetting |
| Latitude | Breedtegraad van het huis blok |
| Longitude | Lengtegraad van het huis blok |
Stap 2 – Voorbereiden van de Gegevens
Controleer op Ontbrekende Waarden
Zorg ervoor dat er geen ontbrekende waarden in de dataset zijn die de analyse kunnen beïnvloeden.
Uitvoer:
Kenmerken Selectie
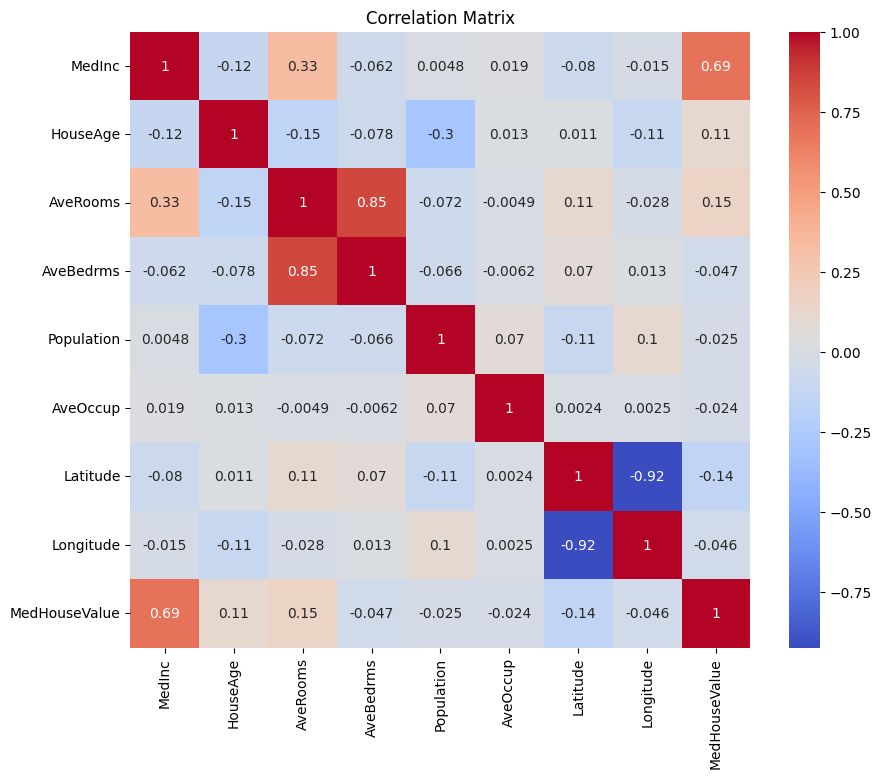
Laten we eerst een correlatiematrix maken om de afhankelijkheden tussen de variabelen te begrijpen.
Uitvoer:
Je kunt de bovenstaande correlatiematrix analyseren om de afhankelijke en onafhankelijke variabelen voor ons regressiemodel te selecteren. De correlatiematrix biedt inzicht in de relaties tussen elk paar variabelen in de dataset.
In de gegeven correlatiematrix is MedHouseValue de afhankelijke variabele, aangezien dit de variabele is die we proberen te voorspellen. De onafhankelijke variabelen hebben een significante correlatie met MedHouseValue.
Op basis van de correlatiematrix kun je de volgende onafhankelijke variabelen identificeren die een significante correlatie hebben met MedHouseValue:
MedInc: Deze variabele heeft een sterke positieve correlatie (0.688075) metMedHouseValue, wat aangeeft dat naarmate het mediane inkomen toeneemt, de mediane woningwaarde ook de neiging heeft om te stijgen.AveRooms: Deze variabele heeft een gematigde positieve correlatie (0.151948) metMedHouseValue, wat suggereert dat naarmate het gemiddelde aantal kamers per huishouden toeneemt, de mediane woningwaarde ook de neiging heeft om te stijgen.AveOccup: Deze variabele heeft een zwakke negatieve correlatie (-0.023737) metMedHouseValue, wat aangeeft dat naarmate de gemiddelde bezetting per huishouden toeneemt, de mediane huiswaarde tendeert te dalen, maar het effect is relatief klein.
Door deze onafhankelijke variabelen te selecteren, kun je een regressiemodel opbouwen dat de relaties tussen deze variabelen en MedHouseValue vastlegt, waardoor we voorspellingen kunnen doen over de mediane huiswaarde op basis van het mediane inkomen, het gemiddelde aantal kamers en de gemiddelde bezetting.
Je kunt ook de correlatiematrix in Python plotten met de onderstaande code:
Je richt je op een paar belangrijke kenmerken voor de eenvoud op basis van het bovenstaande, zoals MedInc (mediaan inkomen), AveRooms (gemiddelde kamers per huishouden) en AveOccup (gemiddelde bezetting per huishouden).
De bovenstaande code selecteert specifieke kenmerken uit de housing_df DataFrame voor analyse. De geselecteerde kenmerken zijn MedInc, AveRooms en AveOccup, die zijn opgeslagen in de selected_features lijst.
De DataFrame housing_df wordt vervolgens onderverdeeld om alleen deze geselecteerde kenmerken te bevatten en het resultaat wordt opgeslagen in de X lijst.
De doelvariabele MedHouseValue wordt geëxtraheerd uit housing_df en opgeslagen in de y lijst.
Schalen van Kenmerken
Je zult standaardisatie gebruiken om ervoor te zorgen dat alle kenmerken op dezelfde schaal zijn, wat de prestaties en vergelijkbaarheid van het model verbetert.
Standaardisatie is een preprocessing techniek die numerieke kenmerken schaalt zodat ze een gemiddelde van 0 en een standaardafwijking van 1 hebben. Dit proces zorgt ervoor dat alle kenmerken op dezelfde schaal zijn, wat essentieel is voor machine learning-modellen die gevoelig zijn voor de schaal van de invoerkenmerken. Door de kenmerken te standaardiseren, kun je de prestaties en vergelijkbaarheid van het model verbeteren door het effect van kenmerken met grote bereiken die het model domineren te verminderen.
Output:
De output vertegenwoordigt de geschaalde waarden van de kenmerken MedInc, AveRooms, en AveOccup na het toepassen van de StandardScaler. De waarden zijn nu gecentreerd rond 0 met een standaardafwijking van 1, wat ervoor zorgt dat alle kenmerken op dezelfde schaal zijn.
De eerste rij [ 2.34476576 0.62855945 -0.04959654] geeft aan dat voor het eerste datapunt de geschaalde MedInc waarde 2.34476576 is, AveRooms 0.62855945 is, en AveOccup -0.04959654 is. Evenzo vertegenwoordigt de tweede rij [ 2.33223796 0.32704136 -0.09251223] de geschaalde waarden voor het tweede datapunt, enzovoort.
De geschaalde waarden variëren van ongeveer -1.14259331 tot 2.34476576, wat aangeeft dat de kenmerken nu genormaliseerd en vergelijkbaar zijn. Dit is essentieel voor machine learning-modellen die gevoelig zijn voor de schaal van invoerkenmerken, omdat het voorkomt dat kenmerken met grote bereiken het model domineren.
Implementeer Meervoudige Lineaire Regressie
Nu je klaar bent met de gegevensvoorverwerking, laten we meervoudige lineaire regressie in Python implementeren.
De train_test_split functie wordt gebruikt om de gegevens op te splitsen in trainings- en testsets. Hier wordt 80% van de gegevens gebruikt voor training en 20% voor testen.
Het model wordt geëvalueerd met behulp van Mean Squared Error en R-kwadraat. Mean Squared Error (MSE) meet het gemiddelde van de kwadraten van de fouten of afwijkingen.
R-kwadraat (R2) is een statistische maat die de proportie van de variantie voor een afhankelijke variabele vertegenwoordigt die wordt verklaard door een onafhankelijke variabele of variabelen in een regressiemodel.
Uitvoer:
De bovenstaande uitvoer biedt twee belangrijke metrische gegevens om de prestaties van het meervoudige lineaire regressiemodel te evalueren:
Gemiddelde Kwadratische Fout (MSE): 0.7006855912225249
De MSE meet het gemiddelde van de gekwadrateerde verschillen tussen de voorspelde en werkelijke waarden van de doelvariabele. Een lagere MSE duidt op een betere modelprestaties, omdat dit betekent dat het model nauwkeurigere voorspellingen doet. In dit geval is de MSE 0.7006855912225249, wat aangeeft dat het model niet perfect is maar een redelijke nauwkeurigheid heeft. De MSE-waarden zouden doorgaans dichter bij 0 moeten liggen, waarbij lagere waarden duiden op betere prestaties.
R-kwadraat (R2): 0.4652924370503557
R-kwadraat meet de proportie van de variantie in de afhankelijke variabele die voorspelbaar is vanuit de onafhankelijke variabelen. Het varieert van 0 tot 1, waarbij 1 perfecte voorspelling is en 0 geen lineaire relatie aangeeft. In dit geval is de R-kwadraatwaarde 0.4652924370503557, wat aangeeft dat ongeveer 46,53% van de variantie in de doelvariabele kan worden verklaard door de onafhankelijke variabelen die in het model zijn gebruikt. Dit suggereert dat het model in staat is om een aanzienlijk deel van de relaties tussen de variabelen vast te leggen, maar niet alles.
Laten we een aantal belangrijke grafieken bekijken:

.png)
Gebruik makend van statsmodels
De Statsmodels bibliotheek in Python is een krachtig hulpmiddel voor statistische analyse. Het biedt een breed scala aan statistische modellen en tests, waaronder lineaire regressie, tijdreeksanalyse en niet-parametrische methoden.
In de context van meerdere lineaire regressie kan statsmodels worden gebruikt om een lineair model op de gegevens te passen en vervolgens verschillende statistische tests en analyses op het model uit te voeren. Dit kan bijzonder nuttig zijn om de relaties tussen de onafhankelijke en afhankelijke variabelen te begrijpen en om voorspellingen op basis van het model te doen.
Uitvoer:
Hier is de samenvatting van de bovenstaande tabel:
Model Samenvatting
Het model is een Ordinary Least Squares regressiemodel, wat een type lineair regressiemodel is. De afhankelijke variabele is MedHouseValue, en het model heeft een R-kwadraat waarde van 0.485, wat aangeeft dat ongeveer 48.5% van de variatie in MedHouseValue verklaard kan worden door de onafhankelijke variabelen. De gecorrigeerde R-kwadraat waarde is 0.484, wat een aangepaste versie is van R-kwadraat die het model bestraft voor het opnemen van extra onafhankelijke variabelen.
Model Fit
Het model is gefit met behulp van de Methode van de Kleinste Kwadraten, en de F-statistiek is 5173, wat aangeeft dat het model goed past. De waarschijnlijkheid om een F-statistiek te observeren die minstens zo extreem is als degene die waargenomen wordt, onder de aanname dat de nulhypothese waar is, is ongeveer 0. Dit suggereert dat het model statistisch significant is.
Model Coëfficiënten
De modelcoëfficiënten zijn als volgt:
- De constante term is 2.0679, wat aangeeft dat wanneer alle onafhankelijke variabelen 0 zijn, de voorspelde MedHouseValue ongeveer 2.0679 is.
- De coëfficiënt voor x1 (In dit geval MedInc) is 0.8300, wat aangeeft dat voor elke eenheidstoename in MedInc, de voorspelde MedHouseValue met ongeveer 0.83 eenheden toeneemt, mits alle andere onafhankelijke variabelen constant worden gehouden.
- Het coëfficiënt voor
x2(in dit gevalAveRooms) is -0.1000, wat aangeeft dat voor elke eenheid toename inx2, de voorspeldeMedHouseValuemet ongeveer 0.10 eenheden daalt, ervan uitgaande dat alle andere onafhankelijke variabelen constant worden gehouden. - Het coëfficiënt voor
x3(in dit gevalAveOccup) is -0.0397, wat aangeeft dat voor elke eenheid toename inx3, de voorspeldeMedHouseValuemet ongeveer 0.04 eenheden daalt, ervan uitgaande dat alle andere onafhankelijke variabelen constant worden gehouden.
Modeldiagnostiek
De modeldiagnostiek is als volgt:
- De Omnibusteststatistiek is 3981.290, wat aangeeft dat de residuen niet normaal verdeeld zijn.
- De Durbin-Watson-statistiek is 1.983, wat aangeeft dat er geen significante autocorrelatie in de residuen is.
- De Jarque-Bera-teststatistiek is 11583.284, wat aangeeft dat de residuen niet normaal verdeeld zijn.
- De scheefheid van de residuen is 1.260, wat aangeeft dat de residuen naar rechts zijn scheefgetrokken.
- De kurtosis van de residuen is 6.239, wat aangeeft dat de residuen leptokurtisch zijn (d.w.z. ze hebben een hogere piek en zwaardere staarten dan een normale verdeling).
- De conditiegetal is 1.42, wat aangeeft dat het model niet gevoelig is voor kleine veranderingen in de gegevens.
.png)
Omgaan met multicollineariteit
Multicollineariteit is een veelvoorkomend probleem in meervoudige lineaire regressie, waarbij twee of meer onafhankelijke variabelen sterk gecorreleerd zijn met elkaar. Dit kan leiden tot onstabiele en onbetrouwbare schattingen van de coëfficiënten.
Om multicollineariteit te detecteren en aan te pakken, kunt u de Variansie-inflatie factor gebruiken. De VIF meet hoeveel de variantie van een geschatte regressiecoëfficiënt toeneemt als uw voorspellers gecorreleerd zijn. Een VIF van 1 betekent dat er geen correlatie is tussen een bepaalde voorspeller en de andere voorspellers. VIF-waarden die hoger zijn dan 5 of 10 duiden op een problematische mate van collineariteit.
In het onderstaande codeblok, laten we de VIF berekenen voor elke onafhankelijke variabele in ons model. Als een VIF-waarde hoger is dan 5, moet u overwegen om de variabele uit het model te verwijderen.
Output:
De VIF-waarden voor elke functie zijn als volgt:
MedInc: De VIF-waarde is 1.120166, wat duidt op een zeer lage correlatie met andere onafhankelijke variabelen. Dit suggereert datMedIncniet sterk gecorreleerd is met andere onafhankelijke variabelen in het model.AveRooms: De VIF-waarde is 1.119797, wat duidt op een zeer lage correlatie met andere onafhankelijke variabelen. Dit suggereert datAveRoomsniet sterk gecorreleerd is met andere onafhankelijke variabelen in het model.AveOccup: De VIF-waarde is 1.000488, wat aangeeft dat er geen correlatie is met andere onafhankelijke variabelen. Dit suggereert datAveOccupniet gecorreleerd is met andere onafhankelijke variabelen in het model.
Over het algemeen liggen deze VIF-waarden allemaal onder de 5, wat aangeeft dat er geen significante multicollineariteit is tussen de onafhankelijke variabelen in het model. Dit suggereert dat het model stabiel en betrouwbaar is, en dat de coëfficiënten van de onafhankelijke variabelen niet significant worden beïnvloed door multicollineariteit.
.png)
Kruisvalideringstechnieken
Kruisvalidering is een techniek die wordt gebruikt om de prestaties van een machine learning-model te evalueren. Het is een hersteekprocedure die wordt gebruikt om een model te evalueren als we een beperkte datamonster hebben. De procedure heeft een enkele parameter die k wordt genoemd en verwijst naar het aantal groepen waarin een gegeven datamonster moet worden verdeeld. Daarom wordt de procedure vaak k-voudige kruisvalidering genoemd.
Uitvoer:
De kruisvalideringscores geven aan hoe goed het model presteert op ongeziene gegevens. De scores variëren van 0.31191043 tot 0.51269138, wat aangeeft dat de prestaties van het model variëren over verschillende vouwen. Een hogere score geeft een betere prestatie aan.
De gemiddelde CV R^2-score is 0,41864482644003276, wat suggereert dat het model gemiddeld ongeveer 41,86% van de variantie in de doelvariabele verklaart. Dit is een matig niveau van verklaring, wat aangeeft dat het model enigszins effectief is in het voorspellen van de doelvariabele, maar mogelijk baat heeft bij verdere verbetering of verfijning.
Deze scores kunnen worden gebruikt om de generaliseerbaarheid van het model te evalueren en mogelijke verbeterpunten te identificeren.
.png)
Methoden voor functieselectie
De Recursive Feature Elimination-methode is een techniek voor functieselectie die recursief de minst belangrijke functies elimineert totdat een gespecificeerd aantal functies is bereikt. Deze methode is bijzonder nuttig bij het omgaan met een groot aantal functies en het doel is om een subset van de meest informatieve functies te selecteren.
In de verstrekte code importeer je eerst de klasse RFE uit sklearn.feature_selection. Vervolgens maak je een instantie van RFE met een gespecificeerde schatter (in dit geval LinearRegression) en stel je n_features_to_select in op 2, wat aangeeft dat we de top 2 functies willen selecteren.
Vervolgens passen we het RFE-object aan op onze geschaalde kenmerken X_scaled en doelvariabele y. Het support_-attribuut van het RFE-object geeft een booleaanse masker terug dat aangeeft welke kenmerken geselecteerd zijn.
Om de rangschikking van de kenmerken te visualiseren, maak je een DataFrame aan met de kenmerknamen en hun overeenkomstige rangschikkingen. Het ranking_-attribuut van het RFE-object geeft de rangschikking van elk kenmerk terug, waarbij lagere waarden duiden op belangrijkere kenmerken. Vervolgens maak je een staafdiagram van de kenmerkrangschikkingen, gesorteerd op hun rangschikkingswaarden. Deze plot helpt ons het relatieve belang van elk kenmerk in het model te begrijpen.
Output:
.png)
Op basis van het bovenstaande diagram zijn de 2 meest geschikte kenmerken MedInc en AveRooms. Dit kan ook bevestigd worden door de uitvoer van het model hierboven, aangezien de afhankelijke variabele MedHouseValue, voornamelijk afhankelijk is van MedInc en AveRooms.
Veelgestelde vragen
Hoe voer je meervoudige lineaire regressie uit in Python?
Om meerdere lineaire regressie in Python te implementeren, kun je bibliotheken zoals statsmodels of scikit-learn gebruiken. Hier is een snel overzicht met scikit-learn:
Dit demonstreert hoe je het model kunt aanpassen, de coëfficiënten kunt verkrijgen en voorspellingen kunt doen.
Wat zijn de aannames van meerdere lineaire regressie in Python?
Meerdere lineaire regressie berust op verschillende aannames om geldige resultaten te waarborgen:
- Lineariteit: De relatie tussen voorspellers en de doelvariabele is lineair.
- Onafhankelijkheid: Waarnemingen zijn onafhankelijk van elkaar.
- Homoscedasticiteit: De variantie van de residuen (fouten) is constant over alle niveaus van de onafhankelijke variabelen.
- Normaliteit van Residuen: Residuen zijn normaal verdeeld.
- Geen Multicollineariteit: Onafhankelijke variabelen zijn niet sterk gecorreleerd met elkaar.
Je kunt deze aannames testen met tools zoals residuele plots, Variance Inflation Factor (VIF) of statistische tests.
Hoe interpreteer je de resultaten van meervoudige regressie in Python?
Belangrijke metrics uit regressieresultaten zijn:
- Coëfficiënten (coef_): Geven de verandering in de doelvariabele aan voor een eenheidsverandering in de bijbehorende voorspeller, met de andere variabelen constant.
Voorbeeld: Een coëfficiënt van 2 voor X1 betekent dat de doelvariabele met 2 toeneemt voor elke 1-eenheid verhoging in X1, terwijl andere variabelen constant blijven.
2.Intercept (intercept_): Vertegenwoordigt de voorspelde waarde van de doelvariabele wanneer alle voorspellers nul zijn.
3.R-kwadraat: Verklaart het aandeel van de variantie in de doelvariabele dat door de voorspellers wordt verklaard.
Voorbeeld: Een R^2 van 0,85 betekent dat 85% van de variabiliteit in de doelvariabele door het model wordt verklaard.
4.P-waarden (in statsmodels): Beoordelen de statistische significantie van voorspellers. Een p-waarde < 0,05 geeft doorgaans aan dat een voorspeller significant is.
Wat is het verschil tussen eenvoudige en meervoudige lineaire regressie in Python?
| Feature | Simple Linear Regression | Multiple Linear Regression |
|---|---|---|
| Aantal Onafhankelijke Variabelen | Eén | Meer dan één |
| Model Vergelijking | y = β0 + β1x + ε | y = β0 + β1×1 + β2×2 + … + βnxn + ε |
| Aannames | Hetzelfde als meervoudige lineaire regressie, maar met een enkele onafhankelijke variabele | Hetzelfde als eenvoudige lineaire regressie, maar met extra aannames voor meerdere onafhankelijke variabelen |
| Interpretatie van Coëfficiënten | De verandering in de doelvariabele voor een eenheidswijziging in de onafhankelijke variabele, terwijl alle andere variabelen constant worden gehouden (niet van toepassing bij eenvoudige lineaire regressie) | De verandering in de doelvariabele voor een eenheidswijziging in één onafhankelijke variabele, terwijl alle andere onafhankelijke variabelen constant worden gehouden |
| Model Complexiteit | Minder complex | Meer complex |
| Model Flexibiliteit | Minder flexibel | Meer flexibel |
| Risico op Overpassing | Lager | Hoger |
| Interpretatie | Eenvoudiger te interpreteren | Moeilijker te interpreteren |
| Toepasbaarheid | Geschikt voor eenvoudige relaties | Geschikt voor complexe relaties met meerdere factoren |
| Voorbeeld | Voorspellen van huisprijzen op basis van het aantal slaapkamers | Voorspellen van huisprijzen op basis van het aantal slaapkamers, vierkante meters en locatie |
Conclusie
In deze uitgebreide tutorial heb je geleerd om Meervoudige Lineaire Regressie te implementeren met behulp van de California Housing Dataset. Je hebt belangrijke aspecten zoals multicollineariteit, kruisvalidatie, kenmerke selectie en regularisatie behandeld, wat zorgt voor een grondig begrip van elk concept. Je hebt ook geleerd om visualisaties op te nemen om residuen, belangrijkheid van kenmerken en algehele modelprestaties te illustreren. Je kunt nu eenvoudig robuuste regressiemodellen in Python construeren en deze vaardigheden toepassen op echte problemen.
Source:
https://www.digitalocean.com/community/tutorials/multiple-linear-regression-python