













مقدمة
الانحدار الخطي المتعدد هو تقنية إحصائية أساسية تُستخدم لنمذجة العلاقة بين متغير تابع وعدة متغيرات مستقلة. في Python ، توفر أدوات مثل scikit-learn و statsmodels تنفيذات قوية لتحليل الانحدار. ستقوم هذه الدورة التعليمية بإرشادك خلال تنفيذ وتفسير وتقييم نماذج الانحدار الخطي المتعدد باستخدام Python.
المتطلبات المسبقة
قبل الانغماس في التنفيذ ، تأكد من أن لديك ما يلي:
- فهم أساسي للغة Python. يمكنك الرجوع إلى دورة Python للمبتدئين.
- الإلمام بـ scikit-learn لمهام تعلم الآلة. يمكنك الرجوع إلى دورة Python scikit-learn.
- فهم مفاهيم تصوير البيانات في لغة البرمجة بايثون. يمكنك الرجوع إلى كيفية رسم البيانات في بايثون 3 باستخدام matplotlib و تحليل البيانات وتصويرها باستخدام pandas ودفتر ملاحظات Jupyter في بايثون 3.
- يجب تثبيت Python 3.x مع المكتبات التالية
numpy,pandas,matplotlib,seaborn,scikit-learn, وstatsmodels.
ما هو الانحدار الخطي المتعدد؟
الانحدار الخطي المتعدد (MLR) هو طريقة إحصائية تقوم بنمذجة العلاقة بين متغير تابع واثنين أو أكثر من المتغيرات المستقلة. إنه تمديد للانحدار الخطي البسيط الذي يقوم بنمذجة العلاقة بين متغير تابع واحد منفصل. في MLR، تتم نمذجة العلاقة باستخدام الصيغة:
.png)
حيث:
.png)
مثال: توقع سعر منزل بناءً على حجمه، عدد غرف النوم، والموقع. في هذه الحالة، هناك ثلاث متغيرات مستقلة، أي الحجم، عدد غرف النوم، والموقع، ومتغير تابع واحد، أي السعر، الذي يتم التنبؤ به.
افتراضات الانحدار الخطي المتعدد
قبل تنفيذ الانحدار الخطي المتعدد، من الضروري التأكد من تحقق الافتراضات التالية:
-
الخطية: العلاقة بين المتغير التابع والمتغيرات المستقلة هي خطية.
-
استقلال الأخطاء: الباقيات (الأخطاء) مستقلة من بعضها. يتم التحقق من ذلك غالبًا باستخدام اختبار دوربين-واتسون.
-
الهمسكيدية: تكون تباين الباقيات ثابتًا عبر جميع مستويات المتغيرات المستقلة. يمكن أن يساعد رسم الباقيات في التحقق من ذلك.
-
عدم وجود تعدد الانسجام: المتغيرات المستقلة غير مرتبطة بشكل كبير. يُستخدم العامل الانتفاخي للتباين (VIF) بشكل شائع لاكتشاف تعدد الانسجام.
-
الانحراف الطبيعي للباقيات: يجب أن تتبع الباقيات توزيعًا طبيعيًا. يمكن التحقق من ذلك باستخدام مخطط Q-Q.
-
تأثير القيم الشاذة: لا ينبغي أن تؤثر القيم الشاذة أو نقاط الرافعة العالية بشكل مفرط على النموذج.
تضمن هذه الافتراضات أن النموذج الخطي صالح وأن النتائج موثوقة. فشل تحقيق هذه الافتراضات قد يؤدي إلى نتائج غير موضوعية أو مضللة.
قبل معالجة البيانات
في هذا القسم، ستتعلم كيفية استخدام نموذج الانحدار الخطي المتعدد في لغة البرمجة Python لتوقع أسعار المنازل استنادًا إلى الميزات من مجموعة بيانات سكن كاليفورنيا. ستتعلم كيفية معالجة البيانات، وتناسب نموذج الانحدار، وتقييم أدائه مع التعامل مع التحديات الشائعة مثل التعددية، والقيم الشاذة، واختيار الميزات.
الخطوة 1 – تحميل المجموعة البيانات
ستستخدم مجموعة البيانات سكن كاليفورنيا، وهي مجموعة بيانات شهيرة لمهام الانحدار. تحتوي هذه المجموعة على 13 ميزة حول المنازل في ضواحي بوسطن وسعرها المتوسط المقابل.
أولا، دعنا نقوم بتثبيت الحزم الضرورية:
يجب ملاحظة الناتج التالي لمجموعة البيانات:
وهنا ما تعنيه كل سمة:
| Variable | Description |
|---|---|
| MedInc | الدخل الوسيط في البلوك |
| HouseAge | عمر المنزل الوسيط في البلوك |
| AveRooms | متوسط عدد الغرف |
| AveBedrms | متوسط عدد غرف النوم |
| Population | سكان البلوك |
| AveOccup | متوسط احتلال المنزل |
| Latitude | خط العرض للبلوك |
| Longitude | خط الطول للبلوك |
الخطوة 2 – معالجة البيانات
التحقق من القيم المفقودة
يضمن عدم وجود قيم مفقودة في مجموعة البيانات التي قد تؤثر على التحليل.
الناتج:
اختيار الميزات
لنقم أولاً بإنشاء مصفوفة ترابط لفهم الارتباطات بين المتغيرات.
الناتج:
يمكنك تحليل مصفوفة الترابط أعلاه لتحديد المتغيرات التابعة والمستقلة لنموذج الانحدار لدينا. توفر مصفوفة الترابط رؤى حول العلاقات بين كل زوج من المتغيرات في مجموعة البيانات.
في المصفوفة الترابطية المعطاة، MedHouseValue هو المتغير التابع، لأنه المتغير الذي نحاول التنبؤ به. المتغيرات المستقلة لها ترابط كبير مع MedHouseValue.
بناءً على مصفوفة الترابط، يمكنك تحديد المتغيرات المستقلة التالية التي لها ترابط كبير مع MedHouseValue:
MedInc: يمتلك هذا المتغير ترابط إيجابي قوي (0.688075) معMedHouseValue، مما يشير إلى أنه مع زيادة الدخل الوسيط، يميل قيمة البيوت الوسيطة أيضًا إلى الزيادة.AveRooms: يمتلك هذا المتغير ترابط إيجابي معتدل (0.151948) معMedHouseValue، مما يوحي بأنه كلما زاد عدد الغرف في المنزل الواحد، كلما زادت قيمة البيت الوسيطة أيضًا.AveOccup: تحمل هذه المتغيرات ترابط سلبي ضعيف (-0.023737) معMedHouseValue، مما يشير إلى أنه كلما زادت متوسط الاحتلال لكل منزل، يميل قيمة البيت الوسيطة إلى الانخفاض، لكن التأثير صغير نسبيًا.
من خلال اختيار هذه المتغيرات المستقلة، يمكنك بناء نموذج انحدار يلتقط العلاقات بين هذه المتغيرات وMedHouseValue، مما يتيح لنا عمل توقعات حول قيمة البيت الوسيطة استنادًا إلى الدخل الوسيط، وعدد الغرف الوسطي، والاحتلال الوسطي.
يمكنك أيضًا رسم مصفوفة الترابط في Python باستخدام الكود التالي:
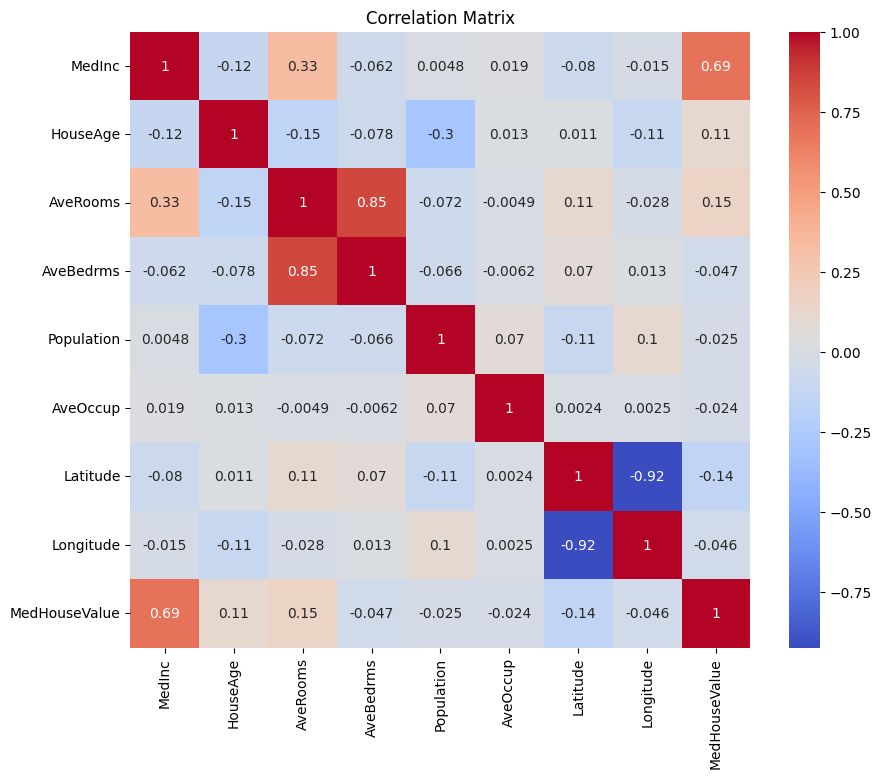
ستركز على بعض الميزات الرئيسية للبساطة استنادًا إلى ما سبق، مثل MedInc (الدخل الوسيط)، AveRooms (متوسط الغرف لكل منزل)، وAveOccup (متوسط الاحتلال لكل منزل).
يقوم الكود أعلاه بتحديد ميزات محددة من إطار البيانات housing_df للتحليل. الميزات المحددة هي MedInc، AveRooms، وAveOccup، والتي يتم تخزينها في قائمة selected_features.
يتم ثم تقسيم إطار البيانات housing_df لتشمل فقط هذه الميزات المحددة ويتم تخزين النتيجة في قائمة X.
يتم استخراج المتغير الهدف MedHouseValue من housing_df ويتم تخزينه في القائمة y.
تقييس الميزات
سوف تستخدم عملية التوحيد (Standardization) لضمان أن جميع الميزات على نفس المقياس، مما يعزز أداء النموذج وقابليته للمقارنة.
التوحيد هو تقنية معالجة مسبقة تقوم بتوحيد الميزات الرقمية لتكون لها متوسط قيمة يساوي 0 وانحراف معياري يساوي 1. تضمن هذه العملية أن جميع الميزات على نفس المقياس، وهو أمر ضروري لنماذج التعلم الآلي التي تكون حساسة لمقياس ميزات الإدخال. من خلال توحيد الميزات، يمكنك تحسين أداء النموذج وقابليته للمقارنة عن طريق تقليل تأثير الميزات ذات النطاقات الكبيرة التي تهيمن على النموذج.
الناتج:
الناتج يمثل القيم المقيدة للميزات MedInc، AveRooms، و AveOccup بعد تطبيق StandardScaler. القيم الآن مركزة حول الصفر بانحراف معياري يساوي 1، مما يضمن أن جميع الميزات على نفس المقياس.
الصف الأول [ 2.34476576 0.62855945 -0.04959654] يشير إلى أن قيمة MedInc المقيدة للنقطة البيانات الأولى هي 2.34476576، AveRooms هي 0.62855945، و AveOccup هي -0.04959654. بالمثل، الصف الثاني [ 2.33223796 0.32704136 -0.09251223] يمثل القيم المقيدة للنقطة البيانات الثانية، وهكذا.
القيم المقيّسة تتراوح تقريباً من -1.14259331 إلى 2.34476576، مما يشير إلى أن الميزات تم تطويعها وجعلها قابلة للمقارنة الآن. هذا أمر أساسي لنماذج تعلم الآلة التي تكون حساسة لمقياس ميزات الإدخال، حيث يمنع السماح للميزات ذات النطاقات الكبيرة من السيطرة على النموذج.
نفذ الانحدار الخطي المتعدد
تنفيذ الانحدار الخطي المتعدد
الآن بعد الانتهاء من تجهيز البيانات دعونا نقوم بتنفيذ الانحدار الخطي المتعدد في بايثون.
يتم استخدام دالة train_test_split لتقسيم البيانات إلى مجموعات تدريب واختبار. هنا، يتم استخدام 80% من البيانات للتدريب و 20% للاختبار.
يتم تقييم النموذج باستخدام خطأ المربعات المتوسطة ومعامل R-squared. يقيس خطأ المربعات المتوسطة (MSE) المتوسط لمربعات الأخطاء أو التحويلات.
معامل R-squared (R2) هو مقياس إحصائي يُمثل النسبة المئوية للتباين لمتغير تابع يُفسره متغير مستقل أو متغيرات في نموذج الانحدار.
الناتج:
يوفر الناتج أعلاه مقاييس رئيسية اثنتان لتقييم أداء نموذج الانحدار الخطي المتعدد:
معدل الخطأ المربعي (MSE): 0.7006855912225249
MSE يقيس الفرق المربع المتوسط بين القيم المتوقعة والفعلية للمتغير الهدف. يشير MSE الأقل إلى أداء نموذج أفضل، حيث يعني ذلك أن النموذج يقوم بتوقعات أكثر دقة. في هذه الحالة، قيمة MSE هي 0.7006855912225249، مما يشير إلى أن النموذج ليس مثاليًا ولكن لديه مستوى معقول من الدقة. قيم MSE عادة ما تكون أقرب إلى 0، حيث تشير القيم الأقل إلى أداء أفضل.
مربع الارتباط (R-squared): 0.4652924370503557
R-squared يقيس نسبة التباين في المتغير المعتمد القابل للتنبؤ من المتغيرات المستقلة. يتراوح بين 0 و 1، حيث 1 هو التنبؤ المثالي و 0 يشير إلى عدم وجود علاقة خطية. في هذه الحالة، قيمة R-squared هي 0.4652924370503557، مما يشير إلى أن حوالي 46.53٪ من التباين في المتغير الهدف يمكن تفسيره بواسطة المتغيرات المستقلة المستخدمة في النموذج. يقترح ذلك أن النموذج قادر على التقاط جزء كبير من العلاقات بين المتغيرات ولكن ليس كلها.
لنلقي نظرة على بعض الرسوم البيانية الهامة:

.png)
استخدام statsmodels
مكتبة Statsmodels في لغة البرمجة Python هي أداة قوية لتحليل الإحصائيات. توفر مجموعة واسعة من النماذج الإحصائية والاختبارات، بما في ذلك تحليل الانحدار الخطي، وتحليل سلاسل الزمن، والأساليب غير المعلمية.
في سياق تحليل الانحدار الخطي المتعدد، يمكن استخدام statsmodels لتناسب نموذجاً خطياً للبيانات، ثم إجراء مختلف الاختبارات والتحاليل الإحصائية على النموذج. يمكن أن يكون ذلك مفيدًا بشكل خاص لفهم العلاقات بين المتغيرات المستقلة والتابعة، ولعمل توقعات استنادًا إلى النموذج.
الناتج:
إليك ملخص الجدول أعلاه:
ملخص النموذج
النموذج هو نموذج تحويلات Ordinary Least Squares، وهو نوع من نماذج التحويلات الخطية. المتغير التابع هو MedHouseValue، والنموذج يحتوي على قيمة R-squared تبلغ 0.485، مما يشير إلى أن حوالي 48.5% من التباين في MedHouseValue يمكن تفسيره بواسطة المتغيرات المستقلة. قيمة R-squared المعدلة هي 0.484، وهي نسخة معدلة من R-squared تعاقب النموذج لاحتوائه على متغيرات مستقلة إضافية.
ملاءمة النموذج
تم تناسب النموذج باستخدام طريقة الأقل مربعات، والإحصاء F هو 5173، مما يشير إلى أن النموذج يتناسب بشكل جيد. احتمال رصد إحصاء F بمقدار على الأقل مثل الذي رصد، بشرط أن فرضية الفراغ صحيحة، يبلغ تقريبًا 0. هذا يقترح أن النموذج ذو دلالة إحصائية.
معاملات النموذج
معاملات النموذج هي كالتالي:
- مصطلح الثابت هو 2.0679، مما يشير إلى أنه عندما تكون جميع المتغيرات المستقلة 0، يكون تنبؤي
MedHouseValueتقريبًا 2.0679. - معامل
x1(في هذه الحالةMedInc) هو 0.8300، مما يشير إلى أنه مع كل زيادة في وحدة فيMedInc، يزيد تنبؤيMedHouseValueبحوالي 0.83 وحدة، مع افتراض ثبوت جميع المتغيرات المستقلة الأخرى. - يبلغ معامل
x2(في هذه الحالةAveRooms) -0.1000، مما يشير إلى أنه مع كل زيادة في وحدة فيx2، ينخفضMedHouseValueالمتوقع بحوالي 0.10 وحدة، بشرط أن تبقى جميع المتغيرات المستقلة الأخرى ثابتة. - يبلغ معامل
x3(في هذه الحالةAveOccup) -0.0397، مما يشير إلى أنه مع كل زيادة في وحدة فيx3، ينخفضMedHouseValueالمتوقع بحوالي 0.04 وحدة، بشرط أن تبقى جميع المتغيرات المستقلة الأخرى ثابتة.
تشخيص النموذج
نتائج تشخيص النموذج كما يلي:
- إحصاء اختبار أومنيبوس هو 3981.290، مما يشير إلى أن الباقي غير منتظم بشكل طبيعي.
- إحصاء دربين-واتسون هو 1.983، مما يشير إلى عدم وجود تباين تتبعي significant في الباقي.
- إحصاء اختبار جارك-بيرا هو 11583.284، مما يشير إلى أن الباقي غير منتظم بشكل طبيعي.
- انحراف الباقي هو 1.260، مما يشير إلى أن الباقي مائل لليمين.
- كورتوز الباقي هو 6.239، مما يشير إلى أن الباقي شبه ذو ذروة عالية وذي أذيال أثقل من التوزيع الطبيعي.
- عدد الشرط هو 1.42، مما يشير إلى أن النموذج ليس حساسًا للتغييرات الصغيرة في البيانات.
.png)
معالجة تعدد الاندماج
التعدد الخطي هو مشكلة شائعة في الانحدار الخطي المتعدد، حيث تكون هناك علاقة قوية بين اثنين أو أكثر من المتغيرات المستقلة. يمكن أن يؤدي ذلك إلى تقديرات غير مستقرة وغير موثوقة للمعاملات.
لاكتشاف ومعالجة التعدد الخطي، يمكنك استخدام عامل تضخم التباين. يقيس VIF مقدار زيادة التباين في معامل الانحدار المقدر إذا كانت المتغيرات التنبؤية مرتبطة. يعني VIF بقيمة 1 أنه لا توجد علاقة بين متنبئ معين وبقية المتنبئين. تشير قيم VIF التي تتجاوز 5 أو 10 إلى وجود كمية مشكلة من التعدد الخطي.
في الكود أدناه، دعنا نحسب VIF لكل متغير مستقل في نموذجنا. إذا كانت أي قيمة VIF تتجاوز 5، يجب عليك التفكير في إزالة المتغير من النموذج.
الإخراج:
قيم VIF لكل خاصية هي كما يلي:
MedInc: قيمة VIF هي 1.120166، مما يشير إلى وجود علاقة منخفضة جداً مع المتغيرات المستقلة الأخرى. وهذا يشير إلى أنMedIncليست مرتبطة بشكل كبير مع المتغيرات المستقلة الأخرى في النموذج.AveRooms: قيمة VIF هي 1.119797، مما يشير إلى وجود علاقة منخفضة جداً مع المتغيرات المستقلة الأخرى. وهذا يشير إلى أنAveRoomsليست مرتبطة بشكل كبير مع المتغيرات المستقلة الأخرى في النموذج.AveOccup: قيمة VIF هي 1.000488، مما يشير إلى عدم وجود ترابط مع المتغيرات المستقلة الأخرى. وهذا يوحي بأنAveOccupغير مرتبط بالمتغيرات المستقلة الأخرى في النموذج.
بشكل عام، تكون قيم VIF هذه جميعًا أقل من 5، مما يشير إلى عدم وجود تعددية الانحدار الكبيرة بين المتغيرات المستقلة في النموذج. وهذا يوحي بأن النموذج مستقر وموثوق، وأن معاملات المتغيرات المستقلة لا تتأثر بشكل كبير بالتعددية في الانحدار.
.png)
تقنيات التقييم المتقاطع
التقييم المتقاطع هو تقنية تُستخدم لتقييم أداء نموذج تعلم الآلة. إنه إجراء إعادة عينة يُستخدم لتقييم نموذج إذا كان لدينا عينة بيانات محدودة. الإجراء له معلمة واحدة تُسمى k تشير إلى عدد المجموعات التي يجب تقسيم عينة البيانات المعطاة إليها. ولذلك، يُطلق على الإجراء كثنائي التقييم المتقاطع.
الإخراج:
تشير علامات التقييم المتقاطع إلى كيفية أداء النموذج على البيانات غير المرئية. تتراوح العلامات بين 0.31191043 و 0.51269138، مما يشير إلى تغير أداء النموذج عبر الطيات المختلفة. تشير العلامة العالية إلى أداء أفضل.
متوسط نقطة CV R^2 هو 0.41864482644003276، مما يشير إلى أن النموذج يفسر بمتوسط حوالي 41.86٪ من التباين في المتغير المستهدف. هذا مستوى معتدل من الشرح، مما يدل على أن النموذج فعال إلى حد ما في توقع المتغير المستهدف ولكن قد يستفيد من تحسين أو تنقيح إضافي.
يمكن استخدام هذه النتائج لتقييم قابلية تعميم النموذج وتحديد المجالات المحتملة للتحسين.
.png)
طرق اختيار الميزات
طريقة الإقصاء التلقائي للميزات هي تقنية اختيار الميزات التي تقوم بإزالة الميزات الأقل أهمية بشكل تكراري حتى يتم الوصول إلى عدد محدد من الميزات. تكون هذه الطريقة مفيدة بشكل خاص عند التعامل مع عدد كبير من الميزات والهدف هو اختيار مجموعة من الميزات الأكثر إفادة.
في الشفرة المقدمة، يتم استيراد فئة RFE أولاً من sklearn.feature_selection. ثم يتم إنشاء مثيل من RFE بمقدار محدد للمقدر (في هذه الحالة، LinearRegression) وتعيين n_features_to_select إلى 2، مما يشير إلى رغبتنا في اختيار أفضل 2 ميزة.
بعد ذلك، نقوم بملاءمة كائن RFE مع ميزاتنا المقيَّسة X_scaled والمتغير الهدف y. يُرجع السمة support_ لكائن RFE قناعًا بوليانيًا يشير إلى السمات التي تم اختيارها.
لتصوير تصنيف الميزات، قم بإنشاء إطار بيانات باسماء الميزات وتصنيفاتها المقابلة. تُرجع السمة ranking_ لكائن RFE تصنيف كل ميزة، حيث تشير القيم الأقل إلى الميزات الأكثر أهمية. ثم قم برسم رسم بياني شريطي لتصنيف الميزات، مرتبًا حسب قيم التصنيف الخاصة بها. يساعد هذا الرسم في فهم الأهمية النسبية لكل ميزة في النموذج.
الناتج:
.png)
بناءً على الرسم البياني أعلاه، تعتبر أكثر ميزتين مناسبة هما MedInc و AveRooms. يمكن التحقق من ذلك أيضًا من إخراج النموذج أعلاه حيث يعتمد المتغير التابع MedHouseValue بشكل كبير على MedInc و AveRooms.
الأسئلة الشائعة
كيفية تنفيذ الانحدار الخطي المتعدد في Python؟
لتنفيذ الانحدار الخطي المتعدد في Python ، يمكنك استخدام مكتبات مثل statsmodels أو scikit-learn. إليك نظرة عامة سريعة باستخدام scikit-learn:
هذا يوضح كيفية تدريب النموذج والحصول على المعاملات وعمل التوقعات.
ما هي افتراضات الانحدار الخطي المتعدد في Python؟
يعتمد الانحدار الخطي المتعدد على عدة افتراضات لضمان النتائج الصحيحة:
- الخطية: العلاقة بين المتغيرات العاملة والمتغير المستهدف خطية.
- الاستقلالية: الرصد غير مترابطة مع بعضها البعض.
- الهوموسيداستيسية: تكون تباين الباقيات (الأخطاء) ثابتة عبر جميع مستويات المتغيرات المستقلة.
- الانحدار الطبيعي للباقيات: الباقيات موزعة بشكل طبيعي.
- لا توجد تعددية في التعلق: المتغيرات المستقلة ليست مرتبطة تمامًا ببعضها البعض.
يمكنك اختبار هذه الافتراضات باستخدام أدوات مثل الرسوم البيانية للباقي، معامل تضخم التباين (VIF)، أو الاختبارات الإحصائية.
كيف يمكنك تفسير نتائج التحويلات المتعددة في Python؟
المقاييس الرئيسية من نتائج التحويلات تشمل:
- المعاملات (coef_): تشير إلى التغيير في المتغير الهدف لوحدة التغيير في العامل التنبؤي المقابل، مع الحفاظ على المتغيرات الأخرى ثابتة.
مثال: معامل قيمته 2 لـ X1 يعني أن المتغير الهدف يزيد بمقدار 2 لكل زيادة بوحدة واحدة في X1، مع الحفاظ على المتغيرات الأخرى ثابتة.
2.التقاطع (intercept_): يمثل القيمة المتوقعة للمتغير الهدف عندما تكون جميع العوامل تنبؤية على الصفر.
3.R-squared: يشرح نسبة التباين في المتغير الهدف يتم شرحها بواسطة العوامل التنبؤية.
مثال: R^2 بقيمة 0.85 يعني أن 85% من التغير في المتغير الهدف يتم شرحه بواسطة النموذج.
4.قيم P (في statsmodels): تقييم الأهمية الإحصائية للعوامل التنبؤية. قيمة P < 0.05 عادة ما تشير إلى أن العامل التنبؤي ذو أهمية.
ما الفرق بين الانحدار الخطي البسيط والمتعدد في Python؟
| Feature | Simple Linear Regression | Multiple Linear Regression |
|---|---|---|
| عدد المتغيرات المستقلة | واحد | أكثر من واحد |
| معادلة النموذج | y = β0 + β1x + ε | y = β0 + β1×1 + β2×2 + … + βnxn + ε |
| الافتراضات | نفس افتراضات الانحدار الخطي المتعدد، ولكن مع متغير مستقل واحد | نفس افتراضات الانحدار الخطي البسيط، ولكن مع افتراضات إضافية لمتغيرات متعددة المستقلة |
| تفسير معاملات الانحدار | التغيير في المتغير المستهدف لزيادة واحدة في المتغير المستقل، مع الاحتفاظ بكل المتغيرات الأخرى ثابتة (لا ينطبق في الانحدار الخطي البسيط) | التغيير في المتغير المستهدف لزيادة واحدة في متغير مستقل واحد، مع الاحتفاظ بكل المتغيرات المستقلة الأخرى ثابتة |
| تعقيد النموذج | أقل تعقيداً | أكثر تعقيداً |
| مرونة النموذج | أقل مرونة | أكثر مرونة |
| مخاطر الانحراف | أقل | أعلى |
| قابلية التفسير | أسهل في التفسير | أكثر تحدياً في التفسير |
| التطبيقية | مناسبة للعلاقات البسيطة | مناسبة للعلاقات المعقدة مع عوامل متعددة |
| مثال | توقع أسعار المنازل استنادًا إلى عدد غرف النوم | توقع أسعار المنازل استنادًا إلى عدد غرف النوم والمساحة بالقدم المربع والموقع |
الاستنتاج
في هذا البرنامج التعليمي الشامل، تعلمت كيفية تنفيذ الانحدار الخطي المتعدد باستخدام مجموعة بيانات الإسكان في كاليفورنيا. لقد تناولت جوانب حاسمة مثل التعدد الخطي بين المتغيرات، التقييم المتقاطع، اختيار الميزات، والتنظيم، مما قدم لك فهماً شاملاً لكل مفهوم. كما تعلمت كيفية دمج التصورات البصرية لتوضيح الباقيات، أهمية الميزات، وأداء النموذج بشكل عام. يمكنك الآن بناء نماذج انحدارية قوية بسهولة باستخدام Python وتطبيق هذه المهارات على مشاكل العالم الحقيقي.
Source:
https://www.digitalocean.com/community/tutorials/multiple-linear-regression-python