













Einführung
Die multiple lineare Regression ist eine grundlegende statistische Technik, die verwendet wird, um die Beziehung zwischen einer abhängigen Variablen und mehreren unabhängigen Variablen zu modellieren. In Python bieten Tools wie scikit-learn und statsmodels robuste Implementierungen für Regressionsanalysen. Dieses Tutorial führt Sie durch die Implementierung, Interpretation und Auswertung von multiplen linearen Regressionsmodellen mit Python.
Voraussetzungen
Vor dem Einstieg in die Implementierung stellen Sie sicher, dass Sie Folgendes haben:
- Grundlegendes Verständnis von Python. Sie können sich an das Python Tutorial für Anfänger wenden.
- Vertrautheit mit scikit-learn für Aufgaben im Bereich maschinelles Lernen. Sie können sich an das Python scikit-learn Tutorial wenden.
- Verständnis der Datenvisualisierungskonzepte in Python. Sie können sich auf Wie man Daten in Python 3 mit matplotlib darstellt und Datenanalyse und Visualisierung mit pandas und Jupyter Notebook in Python 3 beziehen.
- Python 3.x installiert mit den folgenden Bibliotheken
numpy,pandas,matplotlib,seaborn,scikit-learnundstatsmodelsinstalliert.
Was ist Multiple Lineare Regression?
Die Multiple Lineare Regression (MLR) ist eine statistische Methode, die die Beziehung zwischen einer abhängigen Variable und zwei oder mehr unabhängigen Variablen modelliert. Sie ist eine Erweiterung der einfachen linearen Regression, die die Beziehung zwischen einer abhängigen Variable und einer einzigen unabhängigen Variable modelliert. Bei MLR wird die Beziehung mit der Formel modelliert:
.png)
Wo:
.png)
Beispiel: Vorhersage des Preises eines Hauses basierend auf seiner Größe, Anzahl der Schlafzimmer und Lage. In diesem Fall gibt es drei unabhängige Variablen, d.h. Größe, Anzahl der Schlafzimmer und Lage, und eine abhängige Variable, d.h. Preis, die der zu prognostizierende Wert ist.
Annahmen der Multiplen Linearen Regression
Vor der Implementierung der multiplen linearen Regression ist es wichtig sicherzustellen, dass die folgenden Annahmen erfüllt sind:
-
Linearität: Die Beziehung zwischen der abhängigen Variablen und den unabhängigen Variablen ist linear.
-
Unabhängigkeit der Fehler: Residuen (Fehler) sind voneinander unabhängig. Dies wird oft mit dem Durbin-Watson-Test überprüft.
-
Homoskedastizität: Die Varianz der Residuen ist über alle Ebenen der unabhängigen Variablen konstant. Ein Residualplot kann dabei helfen, dies zu überprüfen.
-
Keine Multikollinearität: Unabhängige Variablen sind nicht stark korreliert. Der Varianzinflationsfaktor (VIF) wird häufig verwendet, um Multikollinearität zu erkennen.
-
Normalität der Residuen: Die Residuen sollten einer normalen Verteilung folgen. Dies kann mithilfe eines Q-Q-Plots überprüft werden.
-
Ausreißereinfluss: Ausreißer oder hoch leveragierte Punkte sollten das Modell nicht überproportional beeinflussen.
Diese Annahmen stellen sicher, dass das Regressionsmodell gültig ist und die Ergebnisse zuverlässig sind. Das Nichterfüllen dieser Annahmen kann zu verfälschten oder irreführenden Ergebnissen führen.
Daten vorverarbeiten
In diesem Abschnitt lernen Sie, wie Sie das Multiple-Linear-Regressionsmodell in Python verwenden, um Hauspreise basierend auf Merkmalen aus dem California Housing Dataset vorherzusagen. Sie werden lernen, wie man Daten vorverarbeitet, ein Regressionsmodell anpasst und seine Leistung bewertet, während man auf häufige Herausforderungen wie Multikollinearität, Ausreißer und Merkmalsauswahl eingeht.
Schritt 1 – Laden Sie das Dataset
Sie werden das California Housing Dataset verwenden, ein beliebtes Dataset für Regressionsaufgaben. Dieses Dataset enthält 13 Merkmale über Häuser in den Vororten von Boston und deren entsprechenden Medianhauspreis.
Zuerst installieren wir die notwendigen Pakete:
Sie sollten die folgende Ausgabe des Datensatzes beobachten:
Hier ist, was jeder der Attribute bedeutet:
| Variable | Description |
|---|---|
| MedInc | Medianer Blockeinkommen |
| HouseAge | Medianes Hausalter im Block |
| AveRooms | Durchschnittliche Anzahl der Zimmer |
| AveBedrms | Durchschnittliche Anzahl der Schlafzimmer |
| Population | Blockbevölkerung |
| AveOccup | Durchschnittliche Hausbelegung |
| Latitude | Hausblockbreitengrad |
| Longitude | Hausblocklängengrad |
Schritt 2 – Daten vorverarbeiten
Überprüfen auf fehlende Werte
Stellt sicher, dass im Datensatz keine fehlenden Werte vorhanden sind, die die Analyse beeinträchtigen könnten.
Ausgabe:
Feature-Auswahl
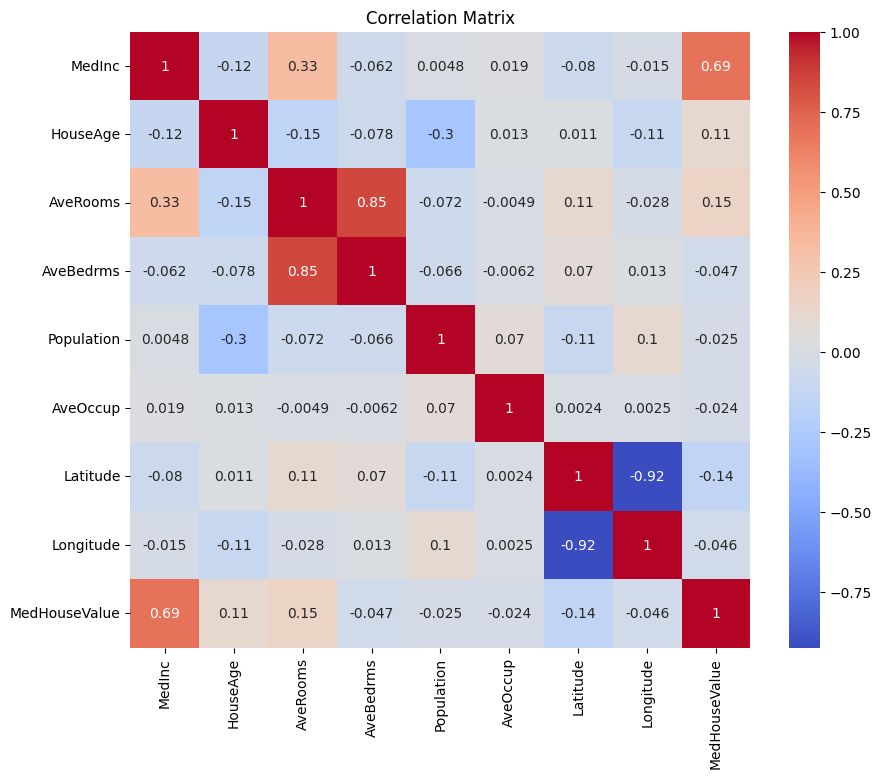
Lassen Sie uns zunächst eine Korrelationsmatrix erstellen, um die Abhängigkeiten zwischen den Variablen zu verstehen.
Ausgabe:
Sie können die obige Korrelationsmatrix analysieren, um die abhängigen und unabhängigen Variablen für unser Regressionsmodell auszuwählen. Die Korrelationsmatrix liefert Einblicke in die Beziehungen zwischen jedem Variablenpaar im Datensatz.
In der gegebenen Korrelationsmatrix ist MedHouseValue die abhängige Variable, da es die Variable ist, die wir zu prognostizieren versuchen. Die unabhängigen Variablen korrelieren signifikant mit MedHouseValue.
Basierend auf der Korrelationsmatrix können Sie die folgenden unabhängigen Variablen identifizieren, die eine signifikante Korrelation mit MedHouseValue aufweisen:
MedInc: Diese Variable hat eine starke positive Korrelation (0,688075) mitMedHouseValue, was darauf hindeutet, dass mit steigendem Median-Einkommen auch der Median-Hauswert tendenziell steigt.AveRooms: Diese Variable hat eine mäßige positive Korrelation (0,151948) mitMedHouseValue, was darauf hindeutet, dass mit zunehmender durchschnittlicher Anzahl von Zimmern pro Haushalt auch der Median-Hauswert tendenziell steigt.AveOccup: Diese Variable hat eine schwache negative Korrelation (-0.023737) mitMedHouseValue, was darauf hindeutet, dass mit zunehmender durchschnittlicher Belegung pro Haushalt der mittlere Hauswert tendenziell abnimmt, der Effekt jedoch relativ gering ist.
Indem Sie diese unabhängigen Variablen auswählen, können Sie ein Regressionsmodell erstellen, das die Beziehungen zwischen diesen Variablen und MedHouseValue erfasst, um Vorhersagen über den mittleren Hauswert basierend auf dem mittleren Einkommen, der durchschnittlichen Anzahl von Zimmern und der durchschnittlichen Belegung zu treffen.
Sie können die Korrelationsmatrix auch in Python mit dem folgenden Code plotten:
Sie werden sich zur Vereinfachung auf einige wichtige Merkmale konzentrieren, wie z.B. MedInc (mittleres Einkommen), AveRooms (durchschnittliche Zimmer pro Haushalt) und AveOccup (durchschnittliche Belegung pro Haushalt), basierend auf dem oben Genannten.
Der obige Codeblock wählt spezifische Merkmale aus dem housing_df-Datenrahmen für die Analyse aus. Die ausgewählten Merkmale sind MedInc, AveRooms und AveOccup, die in der Liste selected_features gespeichert sind.
Der Datenrahmen housing_df wird dann so unterteilt, dass nur diese ausgewählten Merkmale enthalten sind, und das Ergebnis wird in der Liste X gespeichert.
Die Zielvariable MedHouseValue wird aus housing_df extrahiert und in der Liste y gespeichert.
Skalierung der Merkmale
Sie werden die Standardisierung verwenden, um sicherzustellen, dass alle Merkmale auf der gleichen Skala liegen, was die Leistung und Vergleichbarkeit des Modells verbessert.
Die Standardisierung ist eine Vorverarbeitungstechnik, die numerische Merkmale so skaliert, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 haben. Dieser Prozess stellt sicher, dass alle Merkmale auf derselben Skala liegen, was für Machine-Learning-Modelle, die empfindlich auf die Skala der Eingabemerkmale reagieren, unerlässlich ist. Durch die Standardisierung der Merkmale können Sie die Leistung und Vergleichbarkeit des Modells verbessern, indem Sie den Einfluss von Merkmalen mit großen Bereichen reduzieren, die das Modell dominieren.
Ergebnis:
Die Ausgabe repräsentiert die skalierten Werte der Merkmale MedInc, AveRooms und AveOccup nach Anwendung des StandardScaler. Die Werte sind nun um 0 zentriert und haben eine Standardabweichung von 1, was sicherstellt, dass alle Merkmale auf derselben Skala liegen.
Die erste Zeile [ 2.34476576 0.62855945 -0.04959654] zeigt, dass für den ersten Datenpunkt der skalierte Wert von MedInc 2,34476576 beträgt, AveRooms 0,62855945 und AveOccup -0,04959654 ist. Ebenso repräsentiert die zweite Zeile [ 2.33223796 0.32704136 -0.09251223] die skalierten Werte für den zweiten Datenpunkt und so weiter.
Die skalierten Werte reichen von ungefähr -1,14259331 bis 2,34476576, was darauf hindeutet, dass die Merkmale nun normalisiert und vergleichbar sind. Dies ist für Machine-Learning-Modelle, die empfindlich auf den Maßstab der Eingabemerkmale reagieren, unerlässlich, da verhindert wird, dass Merkmale mit großen Spannen das Modell dominieren.
Implementieren Sie Multiple Lineare Regression
Nachdem Sie mit der Datenverarbeitung fertig sind, implementieren wir jetzt multiple lineare Regression in Python.
Die Funktion train_test_split wird verwendet, um die Daten in Trainings- und Testsets aufzuteilen. Hier werden 80 % der Daten für das Training und 20 % für Tests verwendet.
Das Modell wird anhand des Mean Squared Error und des R-Quadrats evaluiert. Der Mean Squared Error (MSE) misst den Durchschnitt der Quadrate der Fehler oder Abweichungen.
Das R-Quadrat (R2) ist ein statistisches Maß, das den Anteil der Varianz für eine abhängige Variable darstellt, der durch eine unabhängige Variable oder Variablen in einem Regressionsmodell erklärt wird.
Ausgabe:
Die obige Ausgabe liefert zwei wichtige Metriken zur Bewertung der Leistung des Modells der multiplen linearen Regression:
Mittlerer quadratischer Fehler (MSE): 0.7006855912225249
Der MSE misst die durchschnittliche quadrierte Differenz zwischen den vorhergesagten und tatsächlichen Werten der Zielvariablen. Ein niedriger MSE deutet auf eine bessere Modellleistung hin, da dies bedeutet, dass das Modell genauere Vorhersagen trifft. In diesem Fall beträgt der MSE 0.7006855912225249, was darauf hindeutet, dass das Modell nicht perfekt ist, aber ein vernünftiges Maß an Genauigkeit aufweist. Die MSE-Werte sollten in der Regel näher an 0 liegen, wobei niedrigere Werte eine bessere Leistung anzeigen.
Bestimmtheitsmaß (R2): 0.4652924370503557
R2 misst den Anteil der Varianz in der abhängigen Variablen, der aus den unabhängigen Variablen vorhergesagt werden kann. Es reicht von 0 bis 1, wobei 1 eine perfekte Vorhersage und 0 keine lineare Beziehung angibt. In diesem Fall beträgt der R2-Wert 0.4652924370503557, was darauf hindeutet, dass etwa 46,53% der Varianz in der Zielvariablen durch die im Modell verwendeten unabhängigen Variablen erklärt werden können. Dies legt nahe, dass das Modell einen signifikanten Teil der Beziehungen zwischen den Variablen erfassen kann, aber nicht alle.
Werfen wir einen Blick auf einige wichtige Diagramme:

.png)
Verwendung von statsmodels
Die Statsmodels-Bibliothek in Python ist ein leistungsstolles Werkzeug für statistische Analysen. Sie bietet eine Vielzahl von statistischen Modellen und Tests, einschließlich linearer Regression, Zeitreihenanalyse und nichtparametrischer Methoden.
Im Kontext der multiplen linearen Regression kann statsmodels verwendet werden, um ein lineares Modell an die Daten anzupassen und dann verschiedene statistische Tests und Analysen am Modell durchzuführen. Dies kann besonders nützlich sein, um die Beziehungen zwischen den unabhängigen und abhängigen Variablen zu verstehen und Vorhersagen auf Basis des Modells zu treffen.
Ausgabe:
Hier ist die Zusammenfassung der obigen Tabelle:
Modellzusammenfassung
Das Modell ist ein Ordinary Least Squares Regressionsmodell, das eine Art von linearem Regressionsmodell darstellt. Die abhängige Variable ist MedHouseValue und das Modell hat einen R-Quadrat-Wert von 0,485, was darauf hindeutet, dass etwa 48,5 % der Variation in MedHouseValue durch die unabhängigen Variablen erklärt werden können. Der angepasste R-Quadrat-Wert beträgt 0,484, was eine modifizierte Version des R-Quadrats ist, die das Modell bestraft, wenn zusätzliche unabhängige Variablen aufgenommen werden.
Modellanpassung
Das Modell wurde mit der Methode der kleinsten Quadrate angepasst, und die F-Statistik beträgt 5173, was darauf hinweist, dass das Modell gut passt. Die Wahrscheinlichkeit, eine F-Statistik zu beobachten, die mindestens so extrem ist wie die beobachtete, unter der Annahme, dass die Nullhypothese wahr ist, beträgt ungefähr 0. Dies deutet darauf hin, dass das Modell statistisch signifikant ist.
Modellkoeffizienten
Die Modellkoeffizienten sind wie folgt:
- Der konstante Term beträgt 2,0679, was bedeutet, dass der vorhergesagte
MedHouseValueungefähr 2,0679 beträgt, wenn alle unabhängigen Variablen 0 sind. - Der Koeffizient für
x1(in diesem FallMedInc) beträgt 0,8300, was bedeutet, dass bei jedem Anstieg von einer Einheit inMedIncder vorhergesagteMedHouseValueum ungefähr 0,83 Einheiten steigt, vorausgesetzt, alle anderen unabhängigen Variablen bleiben konstant. - Der Koeffizient für
x2(in diesem FallAveRooms) beträgt -0.1000, was darauf hinweist, dass bei jeder Einheitserhöhung vonx2der vorhergesagte Wert vonMedHouseValueum etwa 0,10 Einheiten sinkt, unter der Annahme, dass alle anderen unabhängigen Variablen konstant gehalten werden. - Der Koeffizient für
x3(in diesem FallAveOccup) beträgt -0.0397, was darauf hinweist, dass bei jeder Einheitserhöhung vonx3der vorhergesagte Wert vonMedHouseValueum etwa 0,04 Einheiten sinkt, unter der Annahme, dass alle anderen unabhängigen Variablen konstant gehalten werden.
Modell-Diagnostik
Die Modell-Diagnostik erfolgt wie folgt:
- Der Omnibus-Teststatistik beträgt 3981.290, was darauf hinweist, dass die Residuen nicht normal verteilt sind.
- Die Durbin-Watson-Statistik beträgt 1.983, was darauf hinweist, dass keine signifikante Autokorrelation in den Residuen vorhanden ist.
- Der Jarque-Bera-Teststatistik beträgt 11583.284, was darauf hinweist, dass die Residuen nicht normal verteilt sind.
- Die Schiefe der Residuen beträgt 1.260, was darauf hinweist, dass die Residuen nach rechts geneigt sind.
- Die Kurtosis der Residuen beträgt 6.239, was darauf hinweist, dass die Residuen leptokurtisch sind (d.h. sie haben einen höheren Peak und schwerere Schwänze als eine Normalverteilung).
- Die Konditionszahl beträgt 1,42, was darauf hinweist, dass das Modell nicht empfindlich auf kleine Änderungen in den Daten reagiert.
.png)
Umgang mit Multikollinearität
Multikollinearität ist ein häufiges Problem bei der multiplen linearen Regression, bei dem zwei oder mehr unabhängige Variablen stark miteinander korreliert sind. Dies kann zu instabilen und unzuverlässigen Schätzungen der Koeffizienten führen.
Um Multikollinearität zu erkennen und zu behandeln, können Sie den Varianzinflationsfaktor verwenden. Der VIF misst, wie sehr die Varianz eines geschätzten Regressionskoeffizienten ansteigt, wenn Ihre Prädiktoren korreliert sind. Ein VIF von 1 bedeutet, dass es keine Korrelation zwischen einem bestimmten Prädiktor und den anderen Prädiktoren gibt. VIF-Werte über 5 oder 10 deuten auf eine problematische Menge an Kollinearität hin.
Im folgenden Code-Block berechnen wir den VIF für jede unabhängige Variable in unserem Modell. Wenn ein VIF-Wert über 5 liegt, sollten Sie erwägen, die Variable aus dem Modell zu entfernen.
Ausgabe:
Die VIF-Werte für jedes Merkmal sind wie folgt:
MedInc: Der VIF-Wert beträgt 1,120166, was auf eine sehr geringe Korrelation mit anderen unabhängigen Variablen hinweist. Dies legt nahe, dassMedIncnicht stark mit anderen unabhängigen Variablen im Modell korreliert ist.AveRooms: Der VIF-Wert beträgt 1,119797, was auf eine sehr geringe Korrelation mit anderen unabhängigen Variablen hinweist. Dies legt nahe, dassAveRoomsnicht stark mit anderen unabhängigen Variablen im Modell korreliert ist.AveOccup: Der VIF-Wert beträgt 1,000488, was darauf hinweist, dass keine Korrelation mit anderen unabhängigen Variablen besteht. Dies legt nahe, dassAveOccupnicht mit anderen unabhängigen Variablen im Modell korreliert ist.
Im Allgemeinen liegen diese VIF-Werte alle unter 5, was darauf hindeutet, dass keine signifikante Multikollinearität zwischen den unabhängigen Variablen im Modell besteht. Dies legt nahe, dass das Modell stabil und zuverlässig ist und dass die Koeffizienten der unabhängigen Variablen nicht signifikant von der Multikollinearität beeinflusst werden.
.png)
Kreuzvalidierungstechniken
Kreuzvalidierung ist eine Technik, die zur Bewertung der Leistung eines maschinellen Lernmodells verwendet wird. Es handelt sich um ein Resampling-Verfahren, um ein Modell zu bewerten, wenn wir eine begrenzte Datenprobe haben. Das Verfahren hat einen einzelnen Parameter namens k, der sich auf die Anzahl der Gruppen bezieht, in die eine bestimmte Datenprobe aufgeteilt werden soll. Als solches wird das Verfahren oft als k-fache Kreuzvalidierung bezeichnet.
Ausgabe:
Die Kreuzvalidierungswerte geben an, wie gut das Modell auf nicht gesehenen Daten funktioniert. Die Werte reichen von 0,31191043 bis 0,51269138, was darauf hinweist, dass die Leistung des Modells je nach verschiedenen Falten variiert. Ein höherer Wert deutet auf eine bessere Leistung hin.
Der durchschnittliche CV R^2-Score beträgt 0,41864482644003276, was darauf hindeutet, dass das Modell im Durchschnitt etwa 41,86% der Varianz der Zielvariable erklärt. Dies ist ein moderates Erklärungsniveau, das darauf hinweist, dass das Modell in gewissem Maße effektiv ist, um die Zielvariable vorherzusagen, aber von weiteren Verbesserungen oder Verfeinerungen profitieren könnte.
Diese Werte können verwendet werden, um die Generalisierbarkeit des Modells zu bewerten und potenzielle Verbesserungsbereiche zu identifizieren.
.png)
Feature-Auswahlmethoden
Die Methode der rekursiven Merkmalseliminierung ist eine Feature-Auswahltechnik, die rekursiv die am wenigsten wichtigen Merkmale eliminiert, bis eine bestimmte Anzahl von Merkmalen erreicht ist. Diese Methode ist besonders nützlich, wenn es um eine große Anzahl von Merkmalen geht und das Ziel darin besteht, eine Teilmenge der informativsten Merkmale auszuwählen.
Im bereitgestellten Code importieren Sie zunächst die Klasse RFE aus sklearn.feature_selection. Erstellen Sie dann eine Instanz von RFE mit einem spezifizierten Schätzer (in diesem Fall LinearRegression) und setzen Sie n_features_to_select auf 2, was darauf hindeutet, dass wir die besten 2 Merkmale auswählen möchten.
Als nächstes passen wir das RFE-Objekt an unsere skalierten Features X_skaliert und die Zielvariable y an. Das Attribut support_ des RFE-Objekts gibt eine boolesche Maske zurück, die anzeigt, welche Features ausgewählt wurden.
Um das Ranking der Features zu visualisieren, erstellen Sie ein DataFrame mit den Feature-Namen und ihren entsprechenden Rankings. Das Attribut ranking_ des RFE-Objekts gibt das Ranking jedes Features zurück, wobei niedrigere Werte auf wichtigere Features hinweisen. Anschließend erstellen Sie ein Balkendiagramm der Feature-Rankings, sortiert nach ihren Ranking-Werten. Dieses Diagramm hilft uns zu verstehen, wie wichtig jedes Feature im Modell ist.
Ausgabe:
.png)
Basierend auf dem obigen Diagramm sind die 2 am besten geeigneten Features MedInc und AveRooms. Dies kann auch durch die Ausgabe des Modells oben bestätigt werden, da die abhängige Variable MedHouseValue hauptsächlich von MedInc und AveRooms abhängt.
FAQs
Wie implementiert man die multiple lineare Regression in Python?
Um eine multiple lineare Regression in Python zu implementieren, können Sie Bibliotheken wie statsmodels oder scikit-learn verwenden. Hier ist eine kurze Übersicht zur Verwendung von scikit-learn:
Dies zeigt, wie man das Modell anpasst, die Koeffizienten erhält und Vorhersagen trifft.
Was sind die Annahmen der multiplen linearen Regression in Python?
Die multiple lineare Regression stützt sich auf mehrere Annahmen, um gültige Ergebnisse sicherzustellen:
- Linearität: Die Beziehung zwischen Prädiktoren und der Zielvariablen ist linear.
- Unabhängigkeit: Beobachtungen sind voneinander unabhängig.
- Homoskedastizität: Die Varianz der Residuen (Fehler) ist konstant über alle Ebenen der unabhängigen Variablen.
- Normalverteilung der Residuen: Die Residuen sind normalverteilt.
- Keine Multikollinearität: Unabhängige Variablen korrelieren nicht stark miteinander.
Sie können diese Annahmen mithilfe von Tools wie Restplots, Variance Inflation Factor (VIF) oder statistischen Tests überprüfen.
Wie interpretiert man Mehrfachregressions-Ergebnisse in Python?
Wichtige Kennzahlen aus den Regressions-Ergebnissen sind:
- Koeffizienten (coef_): Zeigen die Veränderung der Zielvariablen für eine Einheit Veränderung im entsprechenden Prädiktor, unter Beibehaltung der anderen Variablen konstant.
Beispiel: Ein Koeffizient von 2 für X1 bedeutet, dass die Zielvariable um 2 für jede 1-Einheitserhöhung in X1 ansteigt, unter Beibehaltung der anderen Variablen konstant.
2.Abschnitt (intercept_): Stellt den vorhergesagten Wert der Zielvariablen dar, wenn alle Prädiktoren null sind.
3.R-Quadrat: Erklärt den Anteil der Varianz in der Zielvariablen, der durch die Prädiktoren erklärt wird.
Beispiel: Ein R^2 von 0,85 bedeutet, dass 85% der Variabilität in der Zielvariablen durch das Modell erklärt wird.
4.P-Werte (in statsmodels): Beurteilen die statistische Signifikanz der Prädiktoren. Ein p-Wert < 0,05 deutet in der Regel darauf hin, dass ein Prädiktor signifikant ist.
Was ist der Unterschied zwischen einfacher und multipler linearer Regression in Python?
| Feature | Simple Linear Regression | Multiple Linear Regression |
|---|---|---|
| Anzahl unabhängiger Variablen | Eine | Mehr als eine |
| Modellgleichung | y = β0 + β1x + ε | y = β0 + β1×1 + β2×2 + … + βnxn + ε |
| Annahmen | Gleich wie bei multipler linearer Regression, aber mit einer einzelnen unabhängigen Variablen | Gleich wie bei einfacher linearer Regression, aber mit zusätzlichen Annahmen für mehrere unabhängige Variablen |
| Interpretation der Koeffizienten | Die Veränderung der Zielvariablen für eine Einheit Veränderung der unabhängigen Variablen, während alle anderen Variablen konstant gehalten werden (nicht anwendbar in einfacher linearer Regression) | Die Veränderung der Zielvariablen für eine Einheit Veränderung einer unabhängigen Variablen, während alle anderen unabhängigen Variablen konstant gehalten werden |
| Modellkomplexität | Weniger komplex | Mehr komplex |
| Modellflexibilität | Weniger flexibel | Mehr flexibel |
| Überanpassungsrisiko | Niedriger | Höher |
| Interpretierbarkeit | Einfacher zu interpretieren | Schwieriger zu interpretieren |
| Anwendbarkeit | Geeignet für einfache Beziehungen | Geeignet für komplexe Beziehungen mit mehreren Faktoren |
| Beispiel | Vorhersage von Hauspreisen basierend auf der Anzahl der Schlafzimmer | Vorhersage von Hauspreisen basierend auf der Anzahl der Schlafzimmer, Quadratmeterzahl und Standort |
Schlussfolgerung
In diesem umfassenden Tutorial haben Sie gelernt, Multiple Lineare Regression mithilfe des California Housing Dataset umzusetzen. Sie haben wichtige Aspekte wie Multikollinearität, Kreuzvalidierung, Merkmalsauswahl und Regularisierung behandelt und ein gründliches Verständnis jedes Konzepts vermittelt. Sie haben auch gelernt, Visualisierungen einzubeziehen, um Residuen, Merkmalswichtigkeit und die Gesamtmodellleistung zu veranschaulichen. Sie können nun problemlos robuste Regressionsmodelle in Python erstellen und diese Fähigkeiten auf reale Probleme anwenden.
Source:
https://www.digitalocean.com/community/tutorials/multiple-linear-regression-python