













In deze korte artikel zullen we de aanvaarding van lonen verkennen met behulp van verschillende hulpmiddelen en technieken. We zullen beginnen met het analyseren van lonendata en Logistische Regressie toepassen om lonen uitkomsten te voorspellen. Op basis hiervan zullen we BERT integreren voor Natuurlijke Taalverwerking om de voorspellingsnauwkeurigheid te verhogen. Om de voorspellingen te interpreteren, zullen we de verklaringenstructuren SHAP en LIME gebruiken, waarmee we inzicht krijgen in de belangrijkheid van kenmerken en het gedrag van het model. tenslotte zullen we de mogelijkheden van Natuurlijke Taalverwerking via LangChain verkennen om lonen voorspellingen te automatiseren, gebruik makend van de kracht van conversatieve AI.
Het notitiebestand dat in dit artikel wordt gebruikt, is beschikbaar op GitHub.
Inleiding
In dit artikel zullen we diverse technieken voor de aanvaarding van lonen verkennen, met modellen zoals Logistische Regressie en BERT, en SHAP en LIME toepassen voor de uitleg van het model. We zullen ook de mogelijkheden van het gebruik van LangChain voor het automatiseren van lonen voorspellingen met conversatieve AI verkennen.
Maak een SingleStore Cloud account aan
Een vorige artikel toonde de stappen om een gratis SingleStore Cloud account aan te maken. We zullen de Gratis Gedeelde Categorie gebruiken en de standaard namen voor het Werkruimte en Database behouden.
Importeer de Notitie
We zullen het notitiebestand vanaf GitHub下载en (wanneer gelinkt eerder).
Vanuit het linker navigatiepaneel in het SingleStore Cloud portal, selecteerden we DEVELOP > Data Studio.
In de rechterbovenhoek van de webpagina, selecteerden we Nieuw Notitieblok > Importeren uit bestand. We gebruikten de assistent om de notitieblokken die we vanuit GitHub hadden gedownload te vinden en te importeren.
We runnen het Notitieblok
Nadat we hadden gezien dat we met ons SingleStore werkruimte verbonden waren,运行den we de cellen een voor een.
We begonnen door de vereiste bibliotheken te installeren en afhankelijkheden in te importeren, gevolgd door het laden van de creditdata uit een CSV-bestand met bijna 600 rijen. Aangezien sommige rijen gegevens ontbreken, deden we de onvolledige rijen af voor de initiale analyse, waardoor het dataset tot ongeveer 500 rijen werd beperkt.
Vervolgens zullen we de gegevens verder voorbereiden en de kenmerken en doelvariabelen scheiden.
Visualisaties kunnen erg nuttig zijn voor het ontdekken van gegevens, en we zullen beginnen met het maken van een heatmap die de correlatie tussen alleen numerieke kenmerken weergeeft, zoals getoond in Figure 1.
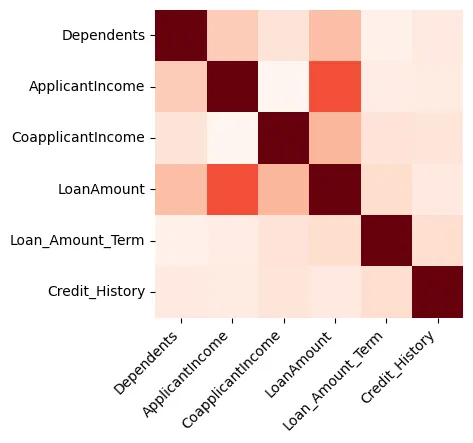
Figure 1: Heatmap
We kunnen zien dat de Creditlimiet en de Inkomsten van de Applicant sterk gerelateerd zijn.
Als we de Creditlimiet tegenover de Inkomsten van de Applicant plotten, zien we dat de meeste data punten naar linksonder zijn op de scatter plot, zoals getoond in Figure 2.
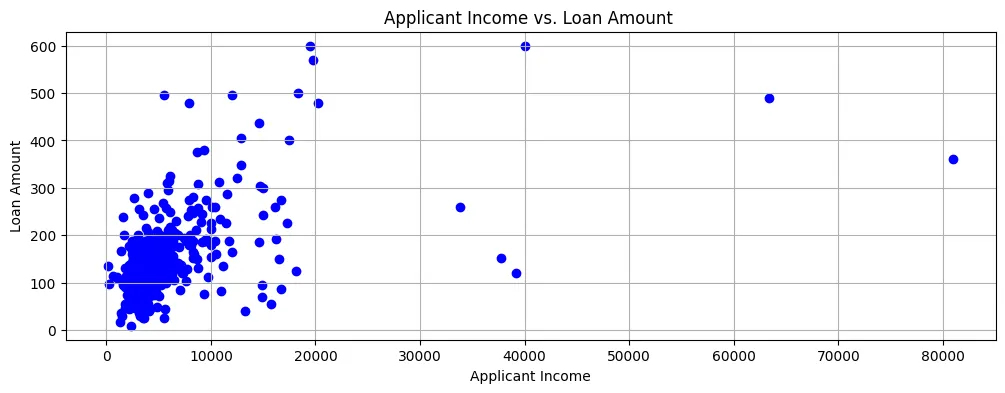
Figure 2: Scatter Plot
Dus hebben de inkomsten meestal een hoogtepunt en de creditaanvragen zijn ook voor relatief kleine bedragen.
We kunnen ook een paarplot maken voor de leningenomstandigheden, de inkomens van de aanvrager en de inkomens van de mede-aanvrager, zoals getoond in Figure 3.
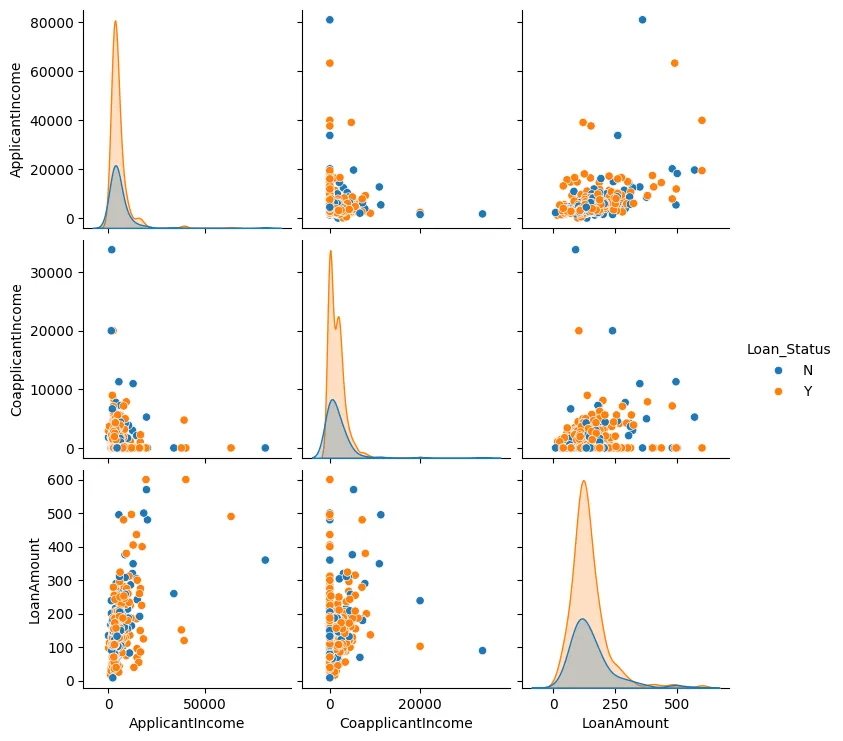
Figure 3: Paarplot
In de meeste gevallen zien we dat de data-punten naar elkaar toe clusterren en zijn er meestal weinig uitvallers.
We zullen nu een paar van de eigenschappen van het model verbeteren. We zullen de categorieën waarden identificeren en deze omzetten in numerieke waarden, en ook one-hot encoding gebruiken waar nodig.
Vervolgens zullen we een model maken met behulp van logistieke regressie omdat er maar twee mogelijke uitkomsten zijn: ofwel wordt de lening goedgekeurd of afgewezen.
Als we de belangrijkheid van de eigenschappen visualiseren, kunnen we enkele interessante observaties doen, zoals getoond in Figure 4.
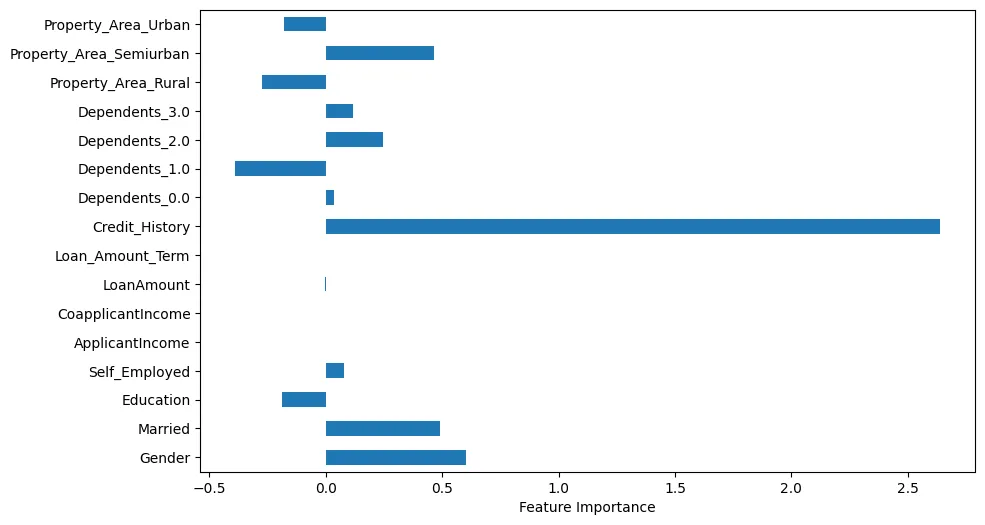
Figure 4: Belangrijkheid van de eigenschappen
Bijvoorbeeld, we kunnen zien dat creditgeschiedenis heel belangrijk is. Echter, huwelijksstatus en geslacht zijn ook van belang.
We zullen nu voorspellingen maken met behulp van één teststuk.
We zullen een overzicht van de leningaanvraag maken met behulp van Bidirectional Encoder Representations from Transformers (BERT) met het teststuk. Voorbeeld van uitvoer:
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
Met behulp van het door BERT gegenereerde overzicht zullen we een woordenbruik-diagram maken zoals getoond in Figure 5.

We kunnen zien dat de naam, inkomen en creditgeschiedenis van de aanvrager groter en meer prominent zijn.
Een andere manier om de gegevens voor ons testmonster te analyseren, is door gebruik te maken van SHapley Additive exPlanations (SHAP). In Figure 6 kunnen we visueel zien welke features belangrijk zijn.

Figure 6: SHAP
Een SHAP krachtplot is een andere manier om de gegevens te analyseren, zoals getoond in Figure 7.
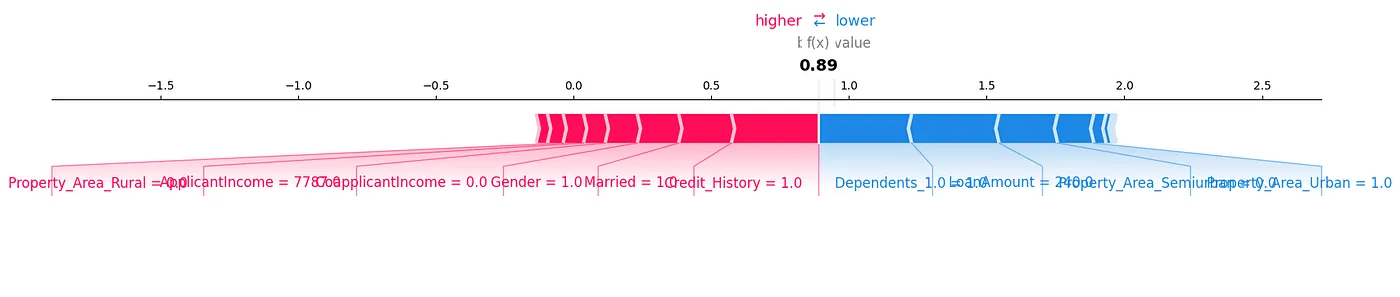
Figure 7: Kracht Plot
We kunnen zien hoe elke feature bijdraagt tot een bepaalde voorspelling voor ons testmonster door de SHAP-waarden in een visuele manier weer te geven.
Een erg nuttige bibliotheek is Local Interpretable Model-Agnostic Explanations (LIME). De resultaten voor dit kunnen worden gegenereerd in het bijbehorende notitieblad bij dit artikel.
Volgend, zullen we een Verwarringstabel (Figure 8) maken voor ons Logistieke Regressie model en een classificatierapport genereren.
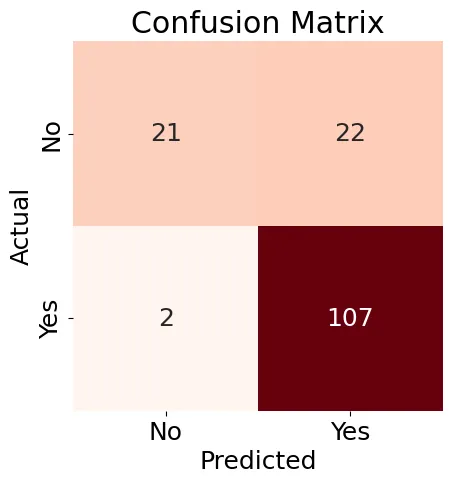
Figure 8: Verwarringstabel
De resultaten die in Figure 8 getoond zijn zijn een beetje gemengd, maar het classificatierapport bevat enkele goede resultaten:
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
Overall, we kunnen zien dat het gebruik van bestaande Machine Learning hulpprogramma’s en technieken ons veel mogelijke manieren biedt om de gegevens te analyseren en interessante relaties te vinden, vooral tot het niveau van een individueel testmonster.
Volgend, laten we LangChain en een LLM gebruiken om te kijken of we ook leningen kunnen voorschrijven.
Zodra we LangChain zijn ingesteld en geconfigureerd, zullen we hem testen met twee voorbeelden, maar toegang tot de hoeveelheid data beperken zodat we de limieten voor tokens en tarieven niet overschrijden. Hier is het eerste voorbeeld:
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
In dit geval werd de aanvraag goedgekeurd in de originele dataset.
Dit is het tweede voorbeeld:
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
In dit geval werd de aanvraag in de originele dataset afgewezen.
Als we deze query’s uitvoeren, kunnen we onconsistente resultaten krijgen. Dat kan komen door het beperken van het aantal data dat kan worden gebruikt. We kunnen ook de uitgebreide modus in LangChain gebruiken om de stappen te zien die worden gebruikt om een creditgoedkeuringsmodel te bouwen, maar er is op dit beginniveau onvoldoende informatie over de detailstappen om dat model te maken.
Er moet meer worden gedaan met conversatieve AI, want veel landen hebben eerlijke hypotheekregels en we zouden een gedetailleerde uitleg nodig hebben over waarom de AI een bepaalde creditaanvraag goed of afkeurde.
Samenvatting
Vandaag de dag bieden veel krachtige toolsen en technieken Machine Learning (ML) aan voor dieper inzicht in gegevens en creditvoorspellingsmodellen. AI, door middel van Grote Taalmodellen (LLMs) en moderne frameworks, biedt groot potentieel om aanvullend of zelfs traditionele ML-benaderingen te vervangen. Echter, voor meer vertrouwen in de AI-aanbevelingen en om te voldoen aan de rechtvaardige hypotheekregels in veel landen, is het crucial om het redeneerproces en de besluitvormingsproces van de AI te begrijpen.
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals