













In de afgelopen jaren zijn er grote vooruitgangen gemaakt in de AI-technologie, vooral dankzij grote taalmodellen (LLMs). LLMs zijn erg goed in staat om tekst te verstandigen en te genereren die menselijker lijkt, en dit heeft geleid tot de creatie van verschillende nieuwe tools, zoals geavanceerde chatbots en AI-schrijvers.
Hoewel LLMs goed zijn in het genereren van menselijke en vloeiende tekst, hebben ze soms problemen met het correcte geven van feiten. Dat kan een grote problematiek zijn wanneer nauwkeurigheid echt belangrijk is
Maar wat is de oplossing voor dit probleem? De antwoord is Retrieval Augmented Generation (RAG).
RAG combineert alle krachtige eigenschappen van modellen zoals GPT en voegt daar ook de mogelijkheid toe om informatie te zoeken uit externe bronnen, zoals eigen databases, artikelen en inhoud. Dit helpt de AI om niet alleen goed geschreven tekst te produceren, maar ook meer feitelijke en contextuele correctheid.
door de mogelijkheid om tekst te genereren te combineren met de kracht om accurate en relevante informatie te vinden en te gebruiken, opent RAG veel nieuwe mogelijkheden. Het helpt de kloof tussen AI die alleen maar tekst schrijft en AI die echte kennis kan gebruiken.
In dit artikel zullen we een kijkje nemen achter RAG, hoe het werkt, waar het wordt gebruikt en hoe het onze toekomstige interacties met AI mogelijk zal veranderen.
Wat is Retrieval Augmented Generation (RAG)?
Laten we beginnen met een formele definitie van RAG:
Het AI-frameork Retrieval Augmented Generation (RAG) verbeterd grote taalmodellen (LLMs) door ze te verbinden met externe kennisbanken. Dit maakt het mogelijk toegang te krijgen tot actuele, nauwkeurige informatie, waardoor de relevantie en de feitelijke nauwkeurigheid van de resultaten verbeterd worden.
Nu zal ik het in eenvoudige taal uitleggen, zodat het gemakkelijk te begrijpen is.
We hebben allemaal de afgelopen 2 jaar AI-chatbots gebruikt, zoals ChatGPT, die onze vragen kunnen beantwoorden. Deze zijn aangedreven door grote taalmodellen (LLMs), die zijn ge trainend en gebouwd op een enorme hoeveelheid internetcontent/gegevens. Ze zijn goed in het produceren van menselijke-achtige tekst over bijna elk onderwerp. Het lijkt alsof ze perfect in staat zijn alle onze vragen te beantwoorden, maar dat is niet altijd zo. Soms delen ze informatie die niet accurate en feitelijk correct is.
Dit is waar RAG komt in beweging. hier is hoe het werkt (op een hoog niveau):
- Je stelt een vraag.
- RAG zoekt een gecurateerde kennisbank van betrouwbare informatie.
- Het haalt relevante informatie op.
- Het stuurt deze informatie door naar de LLM.
- De LLM gebruikt deze nauwkeurige informatie om je te beantwoorden.
Het resultaat van dit proces zijn antwoorden die worden ondersteund door accurate informatie.
Probeer dit met een voorbeeld te verstrijken: denk aan het moment dat je informatie wilt over de bagageregels voor een internationale vlucht. Een traditionele LLM zoals ChatGPT zou misschien zeggen: “Meestal krijg je een gekheckte bagage tot 50 pond en een handbagage. Maar check bij uw luchtvaartmaatschappij voor specifieke details.” Een RAG-versterkte systeem zou zeggen: “Voor luchtvaartmaatschappij X krijgen economy klassen passagiers één gekheckte bagage tot 50 pond en een handbagage van 17 pond. Business class krijgt twee bagages tot 70 pond. Let op speciale regels voor items als sportuitrusting en controleer altijd bij het inchecken.”
merk je de verschillen op? RAG biedt specifieke, meer nauwkeurige informatie die aangepast is aan de werkelijke bagageregels van de luchtvaartmaatschappijen.
Hoe werkt RAG
Nu we een goed idee hebben van wat RAG is, leert ons hoe het werkt. Beginnen we met een eenvoudige architectuurdiagram.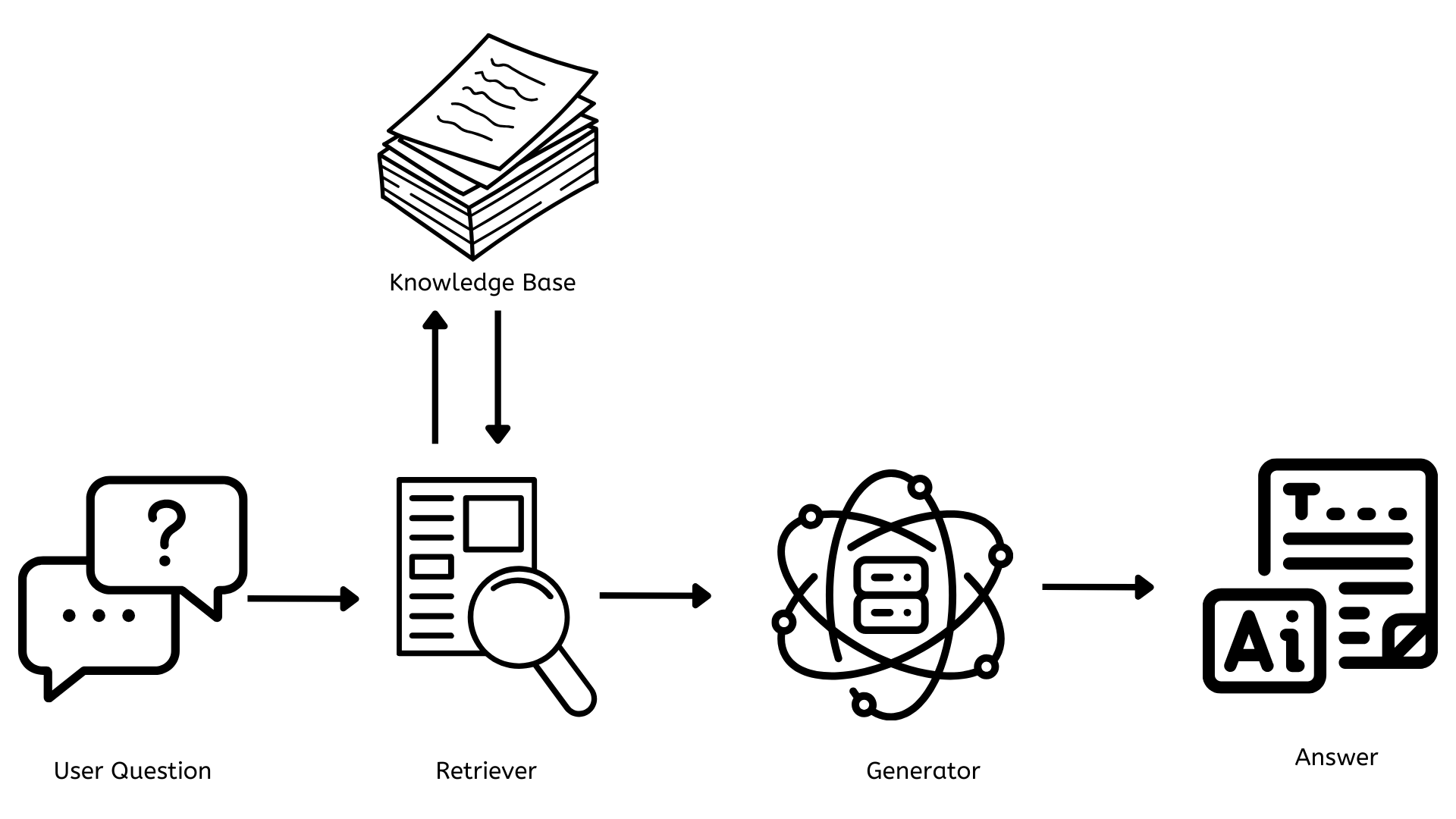
De belangrijkste componenten van RAG
Uit het bovenstaande architectuurdiagram blijkt tussen de vraag van de gebruiker en de uiteindelijke antwoorden op de vraag, dat er drie kritieke componenten zijn die cruciaal zijn voor het functioneren van RAG.
- Knowledge base
- Retriever
- Generator
Nu leert u elk een voor een.
Kennisbasis
Dit is de opslagplaats die alle documenten, artikelen of gegevens bevat die gebruikt kunnen worden om alle vragen te beantwoorden. Dit moet constant worden bijgewerkt met nieuwe en relevante informatie zodat de antwoorden accurate zijn en de gebruikers worden voorzien van de meest relevante en actuele informatie.
Vanuit de technologische kant wordt dit meestal gedaan met vector databases zoals Pinecone, FAISS, enzovoort, om tekst op nummerische weergaven (embeddings) te slaan, waardoor snelle en efficiente zoekopdrachten mogelijk zijn.
Hervinder
Dit is verantwoordelijk voor het vinden van relevante documenten of gegevens die gerelateerd zijn aan de gebruikersvraag. Wanneer een vraag wordt gesteld, zoekt de hervinder snel door de kennisbasis om de meest relevante informatie te vinden.
Vanuit de technologische kant wordt dit vaak gedaan met dichte hervindingsmethodes zoals Dense Passage Retrieval of BM25. Deze methodes converteren de gebruikersvragen in hetzelfde type nummerijke weergaven als in de kennisbasis en matchen ze met relevante informatie.
Generator
Dit is verantwoordelijk voor het genereren van inhoud die coherente en contextueel relevante aan de gebruikersvraag is. Het neemt de informatie van de hervinder en gebruikt die om een antwoord te schrijven die de vraag beantwoordt.
Vanuit een technologisch perspectief werkt dit met een Grote Taal Model (LLM) zoals GPT-4 of open-bron alternatieven zoals LLAMA of BERT. Deze modellen zijn geTraind op grote datasets en kunnen menselijke-achtige tekst genereren op basis van de input die ze ontvangen.
Benefitten en Toepassingen van RAG
Nu we weten wat RAG is en hoe het werkt, laten we ons verdiepen in enkele van de voordelen die het biedt en toepassingen van RAG.
Voordelen van RAG
Bijgewerkte Kennis
Hoeveel traditionele AI-modellen (ChatGPT) zijn beperkt tot hun trainingsdata, RAG-systemen kunnen toegang tot en gebruik maken van de meest actuele informatie beschikbaar in hun kennisbank.
Verbetering van Nauwkeurigheid en Vermindering van Hallucinaties
RAG verbeterd de nauwkeurigheid van antwoorden door middel van factuele, bijgewerkte informatie in de kennisbank te gebruiken. Dit reduceert het probleem van “hallucinaties” voor de meeste deel – gevallen waarin AI meer gelijkzijdige maar onjuiste informatie genereert.
Aanpassing en Specialisatie
Bedrijven kunnen RAG-systemen bouwen die aan hun specifieke behoeften voldoen door gebruik te maken van gespecialiseerde kennisbanken enAI-assistenten te maken die deskundig zijn in specifieke domeinen.
Transparantie en Explicietheid
RAG-systemen kunnen vaak de bronnen van hun informatie opgeven, waardoor het gemakkelijker is voor gebruikers om de bronnen te begrijpen, claims te verifiëren en het redeneren achter de antwoorden te begrijpen.
Scalabiliteit en Efficiëntie
RAG maakt het efficient gebruik van computatiestoffen mogelijk. In plaats van constante herbouw van grote modellen of het bouwen van nieuwe ones, kunnen organisaties hun kennisbases bijwerken, waardoor het gemakkelijker is om schaalbaarheid en onderhoud van AI-systemen mogelijk te maken.
Toepassingen van RAG
Klantenservice
RAG maakt klantenservicechatbots slimmere en nuttigere. Deze chatbots kunnen de meest actuele informatie uit de kennisbase raadplegen en precieze en contextuele antwoorden geven.
Personaliseerbare Assistenten
Bedrijven kunnen aangepaste AI-assistenten maken die kunnen profiteren uit hun unieke en eigenpropriëtaire gegevens. door middel van het gebruik van binnenhuisdocumenten over beleid, procedures en andere gegevens, kunnen deze assistenten vragen van werknemers snel en effectief beantwoorden.
Klantgerichte Inzichten
Organisaties kunnen RAG gebruiken om te analyseren en actievere inzichten te behalen uit een breed scala aan kanaalen voor klantfeedback. Dit laat ze inzichten krijgen in de ervaringen, sentimenten en behoeften van hun klanten, zodat ze snel kritieke problemen kunnen identificeren en aanpakken, beslissingen kunnen nemen op basis van gegevens en kunnen verbeteren aan hun producten op basis van een volledig beeld van klantfeedback over alle aanrakingpunten.
De Toekomst van RAG
RAG is uitgegroeid tot een revolutionaire technologie op het gebied van kunstmatige intelligentie, door de kracht van grote taalmodellen samen te voegen met dynamische informatie-ophalingsmogelijkheden. Veel organisaties gebruiken deze mogelijkheden al en bouwen aangepaste oplossingen aan voor hun specifieke behoeften.
Als we naar de toekomst kijken, zal RAG het verloop van onze interactie met informatie en onze besluitvorming veranderen. Toekomstige RAG-systemen zullen:
- Een betere contextuele verstandhouding en verhoogde personalisering bezitten
- Multimodaal zijn door niet alleen te werken met tekst, maar ook door beelden, audio/video toe te voegen
- Actuele updates van een kennisbase aanvaarden
- Een doorlopende integratie met veel werk流程 om productiviteit te verbeteren en samenwerking te versterken
Conclusie
In conclusie zal RAG de manier waarop we interactie houden met AI en informatie revolutioneren. Door het kleinere verschil tussen AI-gegenereerde inhoud en haar feitelijke nauwkeurigheid te sluiten, zal RAG de voorgrond bezetten voor intelligentie AI-systemen die niet alleen beter zijn, maar ook nauwkeuriger en vertrouwelijker. Met deze ontwikkeling zal onze benadering van informatie effectiever en nauwkeuriger worden dan ooit tevoren.
Source:
https://dzone.com/articles/rag-enhancing-ai-language-models