













In den letzten Jahren hat sich die KI stark weiterentwickelt, was hauptsächlich auf große Sprachmodelle (LLM) zurückzuführen ist. LLM sind sehr gut in der Verständigung und Generierung menschlicher Textähnlichem ausgezeichnet und haben zur Schaffung verschiedener neuartiger Tools wie fortschrittlicher Chatbots und AI-Autoren geführt.
Obwohl LLM hervorragend in der Generierung fließender und menschlicher Text sind, haben sie manchmal mit der Korrektheit von Fakten zu kämpfen. Dies kann ein riesiges Problem sein, wenn Genauigkeit wirklich wichtig ist
Aber wie kann man das Problem lösen? Die Antwort lautet Retrieval Augmented Generation (RAG).
RAG integriert alle mächtigen Features von Modellen wie GPT und fügt auch die Fähigkeit hinzu, Informationen aus außerhalb der Modelle zu suchen, wie z.B. von eigenen Datenbanken, Artikeln und Inhalten. Dies hilft der AI, Text nicht nur gut geschrieben zu produzieren, sondern auch vermehrt faktisch und konztextbezogen korrekt.
Durch die Kombination der Fähigkeit, Text zu generieren, und die Macht, exakte und relevante Informationen zu finden und zu verwenden, öffnet RAG viel neue Möglichkeiten. Es hilft, den Abstand zwischen AI, die nur Text schreibt, und AI, die tatsächliche Kenntnisse verwenden kann, zu überbrücken.
In diesem Beitrag werden wir uns einmal RAG näher anschauen, wie es funktioniert, wo es verwendet wird und wie es die Interaktionen mit AI in der Zukunft verändern könnte.
Was ist Retrieval Augmented Generation (RAG)?
Lassen Sie uns mit einer formellen Definition von RAG beginnen:
RAG (Retrieval Augmented Generation) ist ein AI-Framework, das große Sprachmodelle (LLMs) verbessert, indem sie mit externen Wissensbasen verbunden werden. Dies ermöglicht den Zugriff auf aktuelle, exakte Informationen, was die Relevanz und die faktische Genauigkeit ihrer Ergebnisse verbessert.
Nun lassen Sie uns diese technischen Fakten in einfacheren Sprache translate, um besser verständlich zu sein.
Jeder von uns hat in den letzten 2 Jahren mit AI-Chatbots wie ChatGPT gearbeitet, die unsere Fragen beantworten können. Diese werden von Großen Sprachmodellen (LLMs) getrieben, die auf einem riesigen Datenpool von Internetinhalten/Daten trainiert und erstellt wurden. Sie sind super gut in der Produktion menschlicher Textähnlicher auf fast jedem Thema. Es scheint, als könnten sie perfekt alle unsere Fragen beantworten, aber das ist nicht immer der Fall. Manchmal verbreiten sie Informationen, die nicht korrekt oder faktisch korrekt sind.
Das ist wo RAG eingreift. Hier ist auf einfache Weise, wie es funktioniert (auf sehr hohem Niveau):
- Du stellst eine Frage.
- RAG durchsucht eine aufbereitete Wissensbasis von vertrauenswürdigen Informationen.
- Es findet relevante Informationen.
- Es gibt diese Informationen an das LLM weiter.
- Das LLM nutzt diese exakten Informationen, um auf deine Frage zu antworten.
Das Ergebnis dieses Prozesses sind Antworten, die auf exakten Informationen basieren.
Lassen Sie uns mit einem Beispiel verstehen: Stellen Sie sich vor, Sie möchten sich über die Gepäckbegrenzung für einen internationalen Flug informieren. Ein traditioneller LLM wie ChatGPT könnte sagen: „Im Regelfall erhalten Sie ein gepacktes Gepäck bis zu 50 Pfund und ein Handgepäck. Prüfen Sie jedoch mit Ihrer Fluggesellschaft für Details.“ Ein RAG-verstärkter System würde sagen: „Für die X-Fluggesellschaft erhalten die Wirtschaftskunden ein Gepäck bis zu 50 Pfund und ein Handgepäck bis zu 17 Pfund. Im Business Class erhalten Sie zwei Gepäck bis zu 70 Pfund. Beachten Sie besondere Regeln für Gegenstände wie Sportgeräte und prüfen Sie immer beim Einchecken.“
haben Sie die Differenz bemerkt? RAG liefert spezifische, genauere Informationen, die auf die tatsächlichen Fluggesellschaftspolitiken zugeschnitten sind. Im Zusammenfassung, RAG macht diese Systeme zuverlässiger und glaubwürdiger. Es ist sehr wichtig, wenn Sie AI-Systeme entwickeln, die für reale Anwendungen zuverlässiger sind.
Wie arbeitet RAG?
Nun, da wir uns eine gute Vorstellung von dem was RAG ist haben, lassen Sie uns verstehen, wie es funktioniert. Zuerst, beginnen wir mit einem einfachen Architekturdiagramm.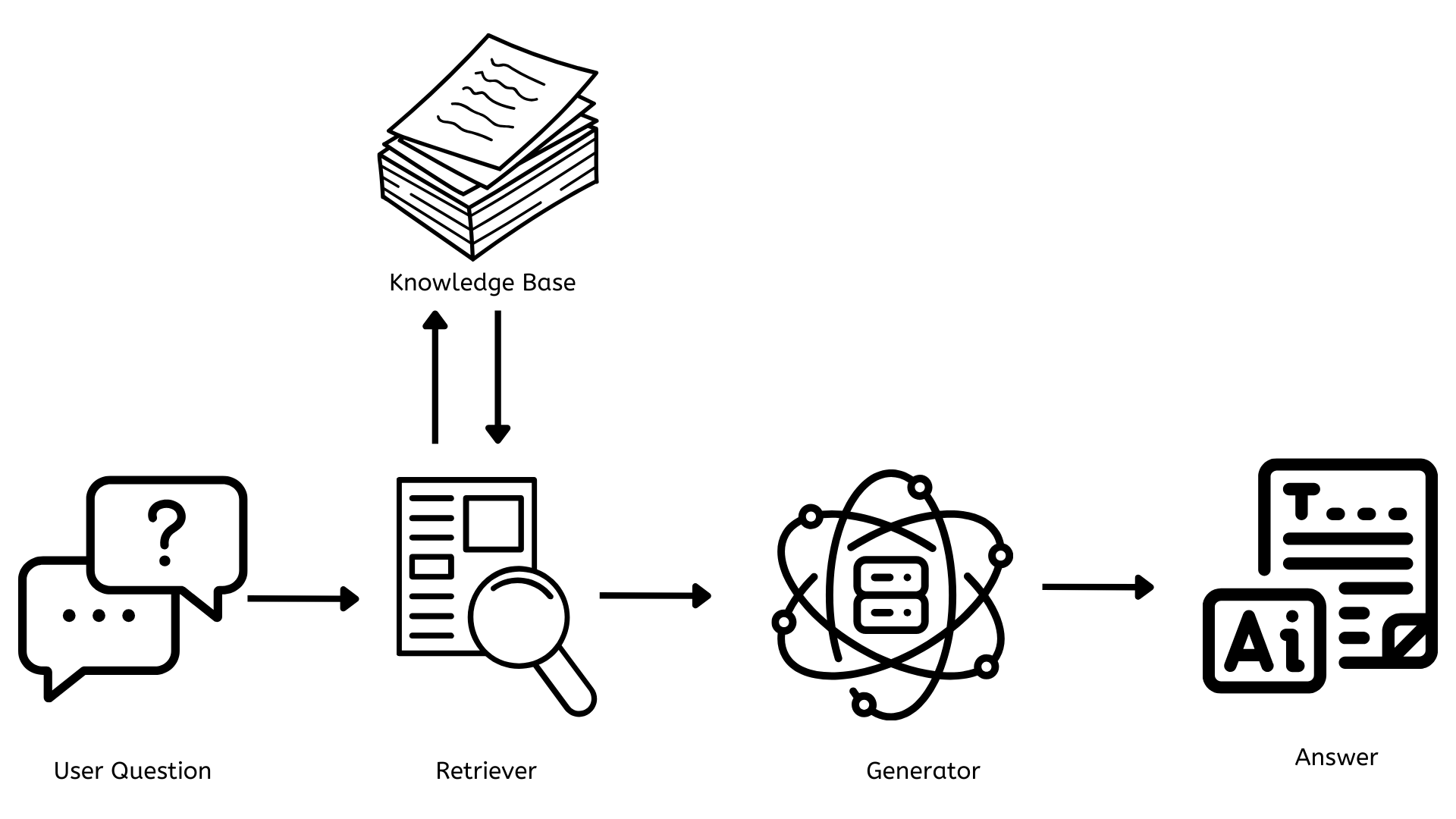
Die Schlüsselkomponenten von RAG
Aus dem oben genannten Architekturdiagramm, zwischen der Frage des Benutzers und der letzten Antwort auf die Frage, gibt es 3 Schlüsselkomponenten, die für das Funktionieren von RAG dabei sind.
- Wissensbasis
- Retriever
- Generator
Nun lassen Sie uns jeden einzelnen verstehen.
Wissensbasis
Das ist das Archiv, das alle Dokumente, Artikel oder Daten enthält, die referenziert werden können, um alle Fragen zu beantworten. Dies muss kontinuierlich mit neuen und relevanten Informationen aktualisiert werden, um die Antworten genau zu halten und den Benutzern die relevantesten und aktuellsten Informationen bereitzustellen.
Aus technischer Sicht verwendet dies normalerweise Vektordatenbanken wie Pinecone, FAISS usw., um Text als numerische Repräsentationen (Embeddings) zu speichern, was eine schnelle und effiziente Suche ermöglicht.
Der Retriever
Er ist verantwortlich für die Findung von relevanten Dokumenten oder Daten, die mit der Benutzerfrage in Verbindung stehen. Wenn eine Frage gestellt wird, sucht der Retriever schnell durch die Wissensbasis, um die relevantesten Informationen zu finden.
Aus technischer Sicht verwendet dies oft dichte Retrievalverfahren wie Dense Passage Retrieval oder BM25. Diese Methoden wandeln die Benutzerfragen in die gleiche Art numerische Repräsentation um, die in der Wissensbasis verwendet wird, und ordnen sie mit relevanten Informationen ab.
Der Generator
Er ist verantwortlich für die Generierung von Inhalten, die koherent und kontextuell für die Benutzerfrage relevant sind. Er nimmt die Informationen vom Retriever und nutzt sie, um eine Antwort zu schaffen, die die Frage beantwortet.
Von einer technischen Standpunkt her, wird dies durch eine Großsprachmodell (LLM) wie z.B. GPT-4 oder Open-Source-Alternativen wie LLAMA oder BERT angetrieben. Diese Modelle werden auf umfangreichen Datensets trainiert und können anhand der empfangenen Eingaben menschenähnlichen Text erzeugen.
Vorteile und Anwendungen von RAG
Nun, da wir wissen, was RAG ist und wie es funktioniert, lassen Sie uns einige der Vorteile untersuchen, die es zu bieten hat, sowie Anwendungen von RAG.
Vorteile von RAG
Auf dem neuesten Stand der Wissenschaft
Im Gegensatz zu traditionellen AI-Modellen (ChatGPT), die auf ihre Trainingsdaten begrenzt sind, können RAG-Systeme auf und nutzen die aktuellsten Informationen in ihrer Wissensbasis zugreifen.
Verbesserte Genauigkeit und verringerte Halluzinationen
RAG verbessert die Genauigkeit von Antworten, indem es tatsächliche, aktuelle Informationen in der Wissensbasis verwendet. Dies reduziert das Problem der „Halluzinationen“ weitgehend – Fälle, in denen AI plausible, aber falsche Informationen generiert.
Anpassung und Spezialisierung
Unternehmen können RAG-Systeme an ihren spezifischen Bedürfnissen aufbauen, indem sie spezielle Wissensbasen verwenden und AI-Assistenten schaffen, die Experten in bestimmten Bereichen sind.
Transparenz und Erklärbarkeit
RAG-Systeme können oft die Quellen ihrer Informationen angeben, was es für Nutzer einfacher macht, die Quellen zu verstehen, Behauptungen zu überprüfen und die Gründe hinter den Antworten zu verstehen.
Skalierbarkeit und Effizienz
RAG ermöglicht die effiziente Nutzung von Rechenressourcen. Statt ständig große Modelle neu zu trainieren oder neue zu bauen, können Organisationen ihre Wissensbasen aktualisieren, was die Skalierung und Wartung von AI-Systemen einfacher macht.
Anwendungen von RAG
Kundenservice
RAG macht Kundenbetreuungschatbots kluger und hilfreich. Diese Chatbots können auf die aktuellste Information aus der Wissensbasis zugreifen und präzise und Kontextrelevante Antworten liefern.
Personalisierte Assistenten
Unternehmen können personalisierte AI-Assistenten erstellen, die auf ihr eigenes und vertrauliches Daten zugreifen können. Indem sie die internen Dokumente der Organisation über Politiken, Verfahren und andere Daten nutzen, können diese Assistenten Mitarbeiteranfragen schnell und effizient beantworten.
Kundenstimme
Organisationen können RAG verwenden, um eine breite Palette von Kundenfeedback Kanälen zu analysieren und daraus handlungsfähige Insights zu extrahieren, was eine umfassende Verstehen der Kunden Erfahrungen, Emotionen und Bedürfnisse ermöglicht. Dies ermöglicht ihnen, kritische Probleme schnell zu erkennen und zu lösen, datengesteuerte Entscheidungen zu treffen und ihre Produkte kontinuierlich basierend auf einem vollständigen Bild der Kundenfeedback über alle Kontaktzonen zu verbessern.
Die Zukunft von RAG
RAG hat sich als eine bahnbrechende Technologie im Bereich der künstlichen Intelligenz etabliert, indem sie die Kraft großer Sprachmodelle mit dynamischer Informationen-Retrieval-Funktion kombiniert. Viele Organisationen nutzen dies bereits aus und bauen maßgeschneiderte Lösungen für ihre Bedürfnisse auf.
Als wir in die Zukunft blicken, wird RAG die Art und Weise verändern, wie wir mit Informationen interagieren und Entscheidungen treffen. Zukünftige RAG-Systeme werden:
- Ein größeres Kontextverständnis und eine verbesserte Personalisierung haben
- Mehrmodalitätig sein, indem sie nicht nur Text, sondern auch Bilder, Audio/Video integrieren
- Eine echtzeitige Aktualisierung der Wissensbasis ermöglichen
- Eine nahtlose Integration in viele Arbeitsabläufe bieten, um Produktivität zu verbessern und Zusammenarbeit zu verstärken
Fazit
Zum Schluss wird RAG die Interaktion mit AI und Information revolutionieren. Durch die Reduzierung des Abstands zwischen AI-generiertem Inhalt und seiner faktischen Genauigkeit legt RAG die Grundlage für intelligente AI-Systeme, die nicht nur erfolgreicher, sondern auch genauer und Vertrauenswürdiger sind. Angesichts dieser Entwicklung werden unsere Interaktion mit Informationen effizienter und präziser denn je sein.
Source:
https://dzone.com/articles/rag-enhancing-ai-language-models