













近年、AIは大きな飛躍を成し遂げています。これは主に大きな言語モデル(LLM)のおかげです。LLMは人間のようなテキストを理解し、生成するのが非常に擅長で、先进のチャットボットやAI書き手など新しいツールの開発につながりました。
LLMは流暢で人間のようなテキストを生成するのに非常に适していますが、時々事実を正しく把握するのが困難になります。正確さが非常に重要な場合、これは大きな問題になる可能性があります。
この問題の解決策とは何でしょうか?答えは取り出し補強型生成(RAG)です。
RAGはGPTなどのモデルの強力な機能を統合し、独自データベースや記事、コンテンツなどの外部情報源から情報を探す能力も追加します。これにより、AIはのちらとした文章だけでなく、より正確で文脈的に正しい文章を生成することができます。
テキストを生成する能力を組み合わせ、正確で関連性のある情報を探す力を持っているため、RAGは新たな可能性を開辟します。これは、単にテキストを生成するAIと、実際の知識を使うことができるAIとの間のギャップを橋渡るのに役立ちます。
この記事では、RAGの仕組み、どのように機能し、どこで使用されているか、将来、私たちとAIの交流をどのように変えるかを詳細に見ていきます。
Retrieval Augmented Generation (RAG)は何か?
まず、RAGの正式な定義から始めます。
RAG(Retrieval Augmented Generation)は、大きな言語モデル(LLM)を外部の知識ベースと結合させることで、それらを強化するAIフレームワーク。これにより、最新の、正確な情報にアクセスでき、結果の関連性と事実の正確性を向上させます。
今、簡単な言語で説明して、理解しやすくする。
過去2年間、私たちはChatGPTなどのAIチャットボットを使ったことがあるでしょう。これらは、巨大な言語モデル(LLM)で作動し、海量のインターネットコンテンツ/データを训练して構築されています。ほとんどのトピックについて人間のようなテキストを生成することができ、私たちの質問に完璧に回答することが思われますが、それは全く真実ではありません。彼らは、時々正確でない情報を共有することがあります。
ここにRAGが登場します。これがどのように機能するか(非常に高层次で)以下のようになります。
- 質問をします。
- RAGは信頼できる情報のカurationされた知識ベースを探索します。
- 関連性のある情報を取得します。
- LLMに渡します。
- LLMはこの正確な情報を使ってあなたに回答します。
このプロセスの結果は、正確な情報に基づく回答です。
従来のLLMは、「通常、あなたは1つの50ポンドのチェックされた荷物と1つの17ポンドの持ち出して行くことができます。しかし、あなたの航空会社に具体例を确认してください。」と答えるかもしれません。RAGによる改善されたシステムは、「X航空会社では、経済舱の乗客は1つの50ポンドのチェックされた荷物と1つの17ポンドの持ち出して行くことができます。ビジネスクラスの乗客は2つの70ポンドの荷物を取ることができます。スポーツ用品などのアイテムについては特別ルールがあり、チェックイン時に確認する必要があります。いつも確認してください。」と答えます。
それで、
RAGの機能
RAGは、これらのシステムをより信頼性の高く、より信頼できるものにするために、特定の、より正確な情報を提供しています。実際の航空会社のポリシーに合わせて定制された情報です。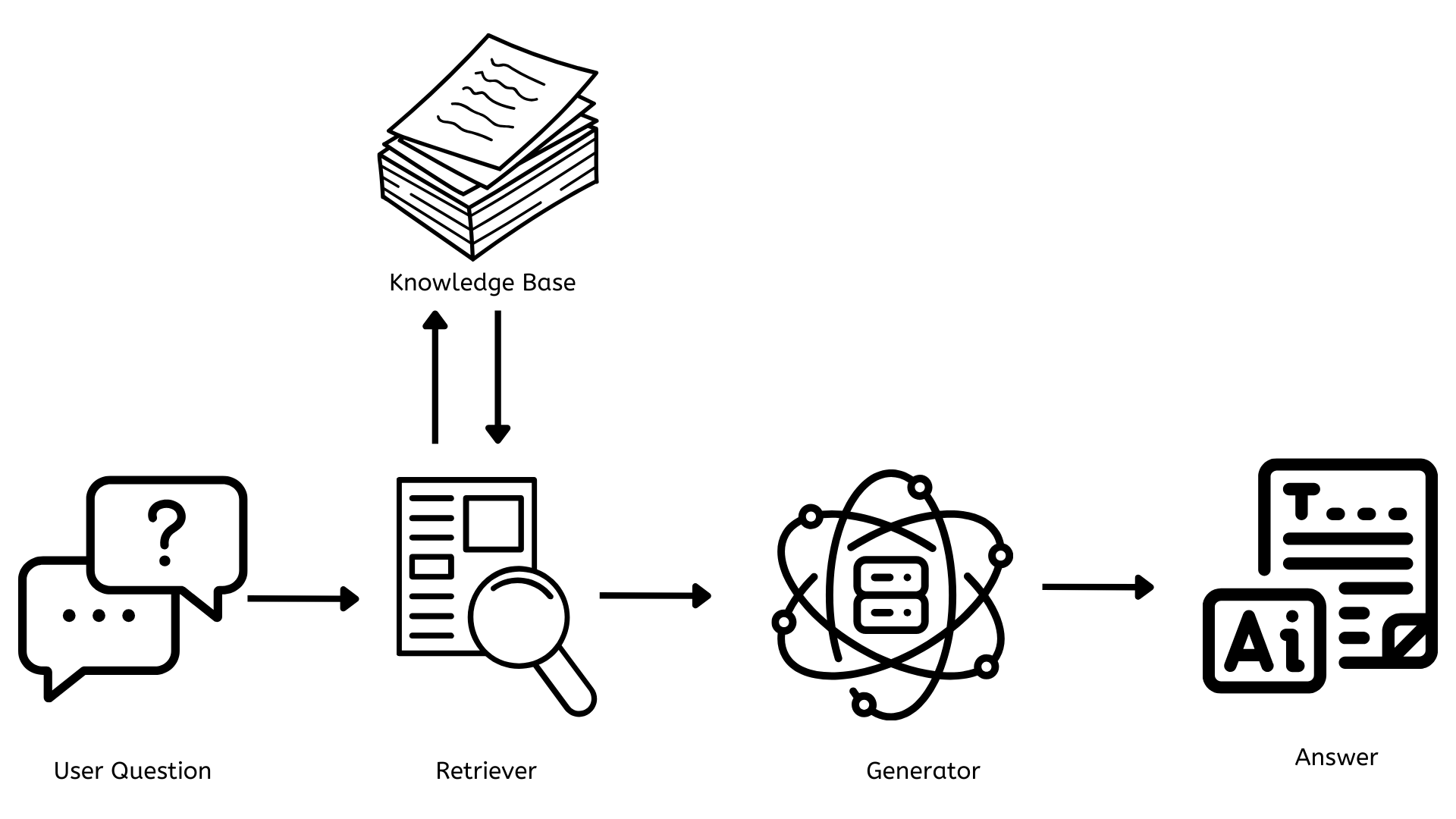
RAGのアーキテクチャ
RAGの仕組みを理解するために、簡単なアーキテクチャの図を見てみましょう。
- 知識ベース
- 取り出し機
- 生成機
これらの構成部分についての詳細を次に解説します。
知識ベース
これは、すべての文書、記事、またはデータを含んだ存储庫で、質問に答えるために参照できます。これは常に新しいと相关性のある情報に更新される必要があり、回答が正確で、ユーザーが最も相关性のある最新の情報を提供されるようにする必要があります。
技術的には、これは通常、ベクターデータベースを使用しています。例えばPinecone、FAISSなど、テキストを数値表現(エンベディング)として格納し、それにより素早く効率的な探索ができます。
レトリエバ
これは、ユーザーの質問に関連するレッテルを探し出す責任があります。質問がある場合、レトリエバは知識ベースを迅速に探し出し、最も関連性のある情報を見つけます。
技術的には、これは通常、デンス・パススルービューションやBM25などの密な復帰方法を使用します。これらの方法は、ユーザーの質問を知識ベースで使用される同じ種類の数値表現に変換し、関連する情報とマッチングします。
ジェネレータ
これは、ユーザーの質問に対する一貫性のあるコンテキストに関連したコンテンツを生成する責任があります。これはレトリエバからの情報を取り入れ、質問に答えるように応用として作成されます。
技術的な見方から、これはGPT-4などの大規模な言語モデル(LLM)やLLAMAやBERTのようなオープンソースの代替品に基づいています。これらのモデルは大規模なデータセットでトレーニングされ、受信した入力に基づいて人間のようなテキストを生成することができます。
RAGの利点と適用
RAGが何であり、どのように機能するかを理解したので、それに提供される利点やRAGの適用について探りましょう。
RAGの利点
最新の知識
tradition AI models(ChatGPT)とは異なり、RAGシステムは学習データに限定されず、知識ベースに存在する最新の情報をアクセス・利用することができます。
精度の向上と幻视の軽減
RAGは、知識ベースにある正確で最新の情報を使用して、返信の精度を向上させます。これにより、AIがもっと信的なものでない情報を生成する「幻视」問題を大いに軽減します。
カスタマイズと特殊化
会社は、専門的な知識ベースを使用して、RAGシステムを自社の特定のニーズに合わせて構築することができます。また、特定の分野の専門家であるAIアシスタントを作成することもできます。
透明性と説明可能性
RAGシステムは、情報の源を Frequently 提供することができるため、使用者が情報の源を理解し、主張を確認し、反応の根拠を理解することがより簡単になります。
スケールと効率
RAGは、コンピューターリソースの効率的な使用を可能にします。常に大きなモデルを再トレーニングすることを避けるか、新しいものを構築する代わりに、組織は知識ベースを更新することができます。これにより、AIシステムのスケールと維持が容易になります。
RAGの応用
顧客サービス
RAGは、顧客サポートのチャットボットをより賢明く、便利にすることができます。これらのチャットボットは、知識ベースから最新の情報にアクセスし、正確でコンテキストに合わせた回答を提供することができます。
個人化アシスタント
会社は、独自の proprietary data を参照するカスタマイズされたAIアシスタントを作成することができます。組織の内部文書を引用として、政策、手続き、その他のデータを参照して、これらのアシスタントは、従業員の質問に迅速かつ効率的に答えることができます。
顧客の声
組織は、RAGを使用して、幅広い顧客フィードバックチャネルから分析し、行動の基になる洞察を抽出することができます。これにより、顧客の体験、感情、需要についての完全な理解を作成することができます。これにより、重要な問題を迅速に特定し、解決することができ、データに基づく決定をすることができ、すべての接触点での顧客フィードバックの完全なパターンを基に製品を持続的に改善することができます。
RAGの未来
RAGは人工知能分野で、大規模な言語モデルの力を動的な情報取得に结合した划期の技術として台頭しています。多くの組織が既にこれを利用して、自分たちのニーズに合わせたカスタムソリューションを構築しています。
将来を見渡すと、RAGは私たちが情報とのやり取りや、决策をする方法を革新することになります。将来的なRAGシステムは以下のような特徴を持つでしょう。
- より深い文脈理解能力と个性的な要提高
- テキストだけでなく、画像、音声/ビデオを含んだ多モーダルです
- 実時間で知識ベースを更新することができます
- 生産性を向上させ、協力を強化するために、多くのワークフローと無缝に統合します
結論
結論として、RAGは人工知能と情報とのやり取りにおいて革命的な変革をもたらすことになります。AI生成されたコンテンツとその事実の正確性とのギャップを埋めることで、RAGは知的なAIシステムがより有効で、正確で信頼性が高いシステムを舞台を设けることになります。これが進化し続けるにつれて、私たちが情報とのやり取りは今までにないように効果的で正確なものになるでしょう。
Source:
https://dzone.com/articles/rag-enhancing-ai-language-models