













في السنوات الأخيرة، قام الذكاء الاصطناعي بتقدمات كبيرة، وذلك بسبب نماذج اللغات الكبيرة (LLMs). تتميز النماذج الكبيرة بإمكانيات جيدة في فهم وتوليد النصوص التي تشبه النصوص البشرية، وقادت إلى إنشاء عدد من الأدوات الجديدة مثل البوتات الحديثة وكتابو الذكاء الاصطناعي.
بينما تكون النماذج الكبيرة جيدة في توليد النصوص السليمة والتي تشبه البشر، فإنها أحياناً تواجه صعوبات في توصيل الحقائق بشكل صحيح. هذا يمكن أن يكون مشكلة كبيرة عندما يكون الدقة مهمة جداً
لذلك، ما هو الحل لهذا؟ الجواب هو التوليد المعزز بالإسترجاع (RAG).
RAG تدمج جميع الميزات القوية للنماذج مثل GPT وتضيف أيضًا القدرة على البحث في مصادر خارجية، كالقواعد البيانات الخاصة، والمقالات، والمحتوى. هذا يساعد الذكاء الاصطناعي على إنتاج نصوص ليست فقط مكتوبة جيداً لكن أيضًا تكون حقيقة ومتناسقة بشكل أكبر.
بمجموعة القدرة على توليد النصوص بقوة العثور واستخدام المعلومات الصحيحة والمتناسبة، تفتح RAG فرص جديدة كثيرة. يساعدها في تعويض الفجوة بين الذكاء الاصطناعي الذي يكتب النصوص والذكاء الاصطناعي الذي يستخدم المعرفة الفعلية.
في هذه المقالة، سنلقي نظرة قريبة على RAG، وكيفية عملها، وأين تستخدم، وكيف قد تغير تفاعلاتنا مع الذكاء الاصطناعي في المستقبل.
ما هو التوليد المعزز بالإسترجاع (RAG)؟
لنبدأ بتعريف رسمي لـ RAG:
توفير الاستنتاج المساعدة على التوليد (RAG) هو إطار تقنية علم المعلومات التي تحسين نماذج النظم الكبيرة لللغة (LLMs) بتواصلها مع قواعد المعلومات الخارجية. هذا يسمح لهم بالوصول إلى معلومات متقدمة ودقيقة، مما يحسن توافر ودقة النتائج المحتوية على المعلومات.
الآن، دعونا نكسر هذا الموضوع إلى لغة بسيطة ليكون سهلة الفهم.
لقد استخدمنا جميعاً نظم المحادثات التي تدفع بـ ChatGPT خلال العامين الماضيين والتي يمكنها أخبارنا بالإجابات. تم تحميلها بواسطة نماذج النظم الكبيرة لللغة (LLMs) التي تم تدريبها وبناءها على المعلومات الكبيرة من المحتويات/البيانات التي تتضمن الإنترنت. إنها جيدة جداً في إنتاج النصوص التي تشبه الإنسان عن كل موضوع. ويبدو أنها تستطيع إجابة جميع أسئلتنا، ولكن هذا ليس بالضبط صحيحاً في كل الأحيان. فهي تشارك أحياناً معلومات لا تمثل بالدقة والصحة الاعتبارية.
وهنا حيث يأتي RAG. هذا كيف يعمل (على مستوى عالٍ):
- تسأل سؤالًا.
- يبحث RAG في قاعدة موارد المعلومات الموثوقة.
- يجد معلومات متعلقة.
- يتم تخزين هذه المعلومات للنموذج الكبير لللغة.
- يستخدم النموذج الكبير لللغة هذه المعلومات الدقيقة لإجابتك.
نتيجة هذه العملية هي الإجابات التي تحمل دعم من المعلومات الدقيقة.
لنفهم هذا مع مثال: تخيل أنك تريد معرفة حول الحدود المسموحة لرحلة دولية. سيقول محاور تقنية المتحدث التقنية التقليدية مثل ChatGPT: “عادةً، يمكنك أن تحصل على حقيبة مرتدية واحدة تزيد إلى 50 بوندات وحقيبة محمولة واحدة. ولكن استكمل بمراجعة شركة الطيران للتفاصيل.” سيقول نظام معدل التعامل المحفوظ بـ RAG: “لشركة X الطيران، يسمح للمسافرين الاقتصاديين بحقيبة مرتدية واحدة تزيد إلى 50 بوند وحقيبة محمولة تزيد إلى 17 بوند. وللطيران الأعلى تسمح بجهاز من الحقيبات الثنائي يزيد إلى 70 بوند. تحمل إياه قوانين خاصة على أشياء مثل المعدات الرياضية، وتحديداً تحقق في المراجعة في التسجيل.”
ألم تلاحظوا الفرق ؟ يوفر RAG معلومات واضحة ودقيقة ومتخصصة لسياسات الشركة الحقيقية.
كيف تعمل RAG
حالياً أن نكون متأكدين بشكل جيد ما هو RAG، دعونا نفهم كيف يعمل. أولاً، دعونا نبدأ برسم شكل بسيط للهيكل التقني.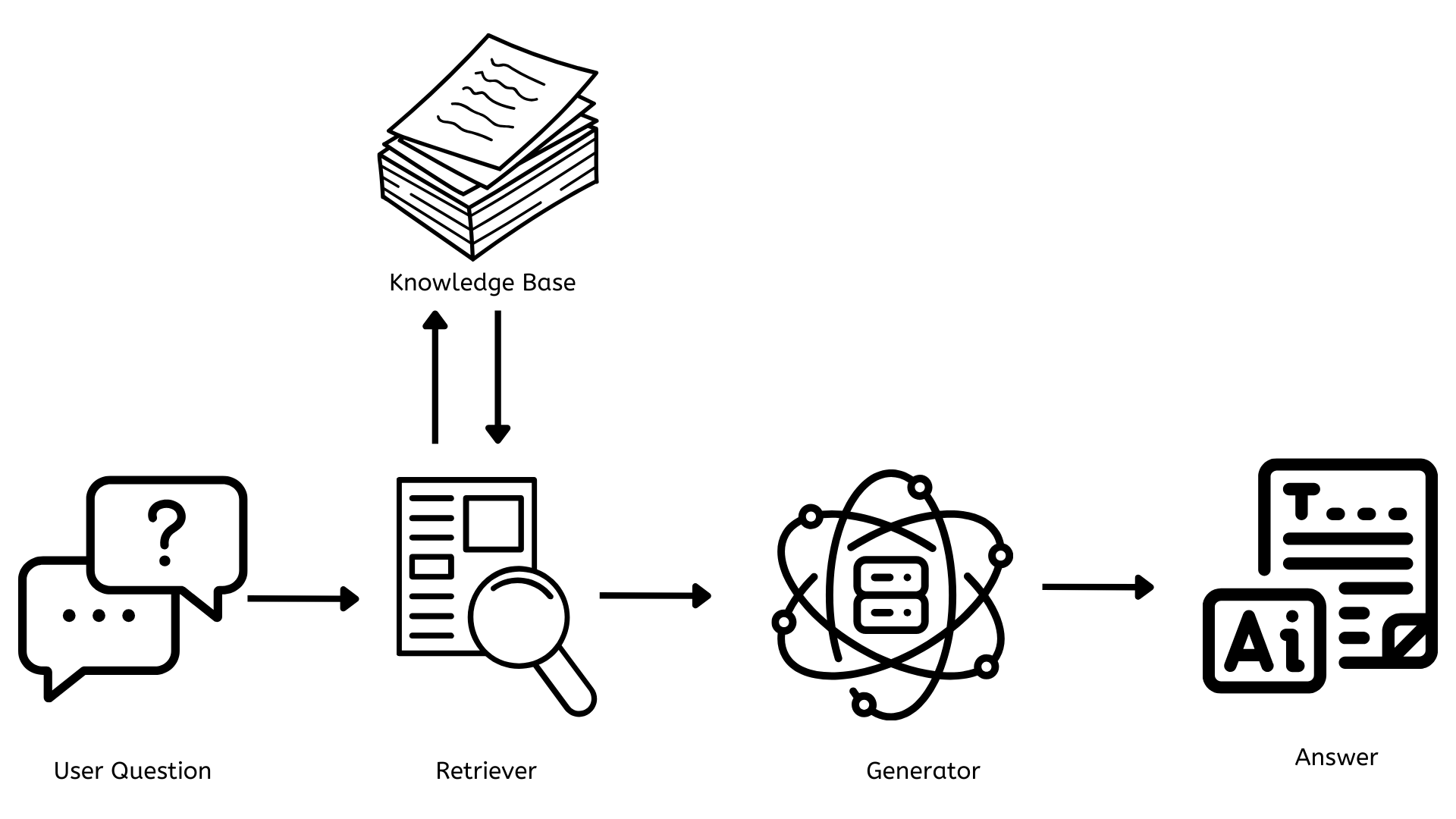
مكونات رئيسية RAG
من خلال رسم هيكل التقنية من أعلاه، بين سؤال المستخدم والإجابة النهائية للسؤال ، هناك 3 مكونات رئيسية تعتمد عليها RAG للعمل.
- قاعدة المعرفة
- المحاول الإحصائي
- المولد الناتج
حالياً، دعونا نفهم كل واحد من
قاعدة المعلومات
هذه هي المخزون الذي يحتوي على جميع المستندات، المقالات، أو البيانات التي يمكن الاشتراك فيها لإجابة جميع الأسئلة. يتوجب عليه تحديث مستمر بالمعلومات الجديدة والمرتبطة لكي تكون الإجابات دقيقة ويتم توفير المعلومات التي تتم الاتصال بها من قبل المستخدمين بالمعلومات التي تتطابق مع أسئلتهم والتي تكون مناسبة ومتابعة.
من المنظور التكنولوجي، يستخدم عامًا قواعد الأبعاد الرسمية مثل Pinecone، FAISS وما إلى ذلك لتخزين النصوص كما تمثل في التعاملات الرقمية (التعاملات الرقمية),يمكن بذلك أن يتم بسهولة وبالكامل بالبحث.
المحرك التنقلي
هذا مسؤول عن إيجاد المستندات المتعلقة أو البيانات المتعلقة بالأسئلة المتعلقة بالمستخدم. عندما يتم طرح سؤال، يبحث المحرك بسرعة عن المعلومات المتعلقة في القاعدة المعلوماتية.
من المنظور التكنولوجي، يستخدم غالبًا طرق إسترجاع كثيفة مثل Dense Passage Retrieval أو BM25. تحويل هذه الطرق الأسئلة المتعلقة بنفس النوع الرقمي من التعاملات التي يستخدمها القاعدة المعلوماتية وتوفير المعلومات المتعلقة.
المولد
هذا مسؤول عن إنشاء المحتوى المتكامل والمتعلق بالسؤال المتعلق بالمستخدم. يأخذ المعلومات من المحرك ويستخدمها لتنشيط رد يجيب على السؤال.
من وجهة نظر التكنولوجيا، هذا يتم تحفيزه بنموذج كبير للنموذج اللغوي (LLM) مثل GPT-4 أو بديلات مفتوحة المصدر مثل LLAMA أو BERT. تم تدريب تلك النماذج على أعدادات ضخمة ويمكنها توليد نصوص تشبه البشرية بناءاً على الإدخال الذي يتلقى منها.
المنافع والتطبيقات ل RAG
حسنًا وعندما نعرف ما هو RAG وكيف يعمل، دعونا نستكشف بعض المنافع التي توفرها إضافة إلى تطبيقات RAG.
المنافع ل RAG
المعرفة المتقدمة
بخلاف النماذج التقنية التقليدية (ChatGPT) التي محدودة بمعلوماتها التدريبية، يمكن للأنظمة RAG الوصول إلى وإستخدام المعلومات الأحدث المتاحة في قاعدتهم المعرفية.
تحسين الدقة وخفض الهلوسات
يحسن RAG دقة الإجابات باستخدام معلومات حقيقية ومتقدمة في قاعدة المعرف، مما يخفض بشكل كبير مشكلة “الهلوسات” بما فيها حالات التوليد الخاطئ للمعلومات الممكنة لكن غير صحيحة.
التخصيص والتخصص
يمكن للشركات بناء أنظمة RAG لاحتياجاتها خاصة باستخدام قواعد المعرف تخصصية وتخليق مستشارين التكنولوجيا يكونون خبراء في مجالات تحديدية.
الشفافية وقابلية التفسير
أنظمة RAG يمكن أن توفر مصادر معلوماتها بشكل كثير، مما يسهل للمستخدمين فهم المصادر وتحقيق الاقتراحات وفهم السببية وراء الردود.
القابلية للتدرج والكفاءة
تسمح RAG بإستخدام كاف لموارد الحوسبة. بدلاً من تعيين نماذج كبيرة بشكل مستمر أو بناء نماذج جديدة، يمكن للمنظمات تحديث قواعد المعرفة، مما يسهل التدرج وصيانة أنظمة الذكاء الاصطناعي.
تطبيقات RAG
خدمة العملاء
تجعل RAG البوتات الحوارية لخدمة العملاء أذكى وأكثر مساعدة. يمكن لهذه البوتات الحوارية الوصول إلى أحدث المعلومات من قاعدة المعرفة وتوفير إجابات دقيقة وسياقية.
المساعدون الشخصيون
يمكن للشركات إنشاء مساعدون ذكاء إصطناعي مخصصين يستطيعون الوصول إلى بياناتهم الفريدة والمملوكة. وباستخدام الوثائق الداخلية للمنظمة في سياسات وإجراءات وبيانات أخرى، يمكن لهؤلاء المساعدون أن يجيبوا على استفسارات الموظفين بسرعة وكفاءة.
صوت العميل
يمكن للمنظمات استخدام RAG لتحليل وإستنباط معارف عملية من قنوات واسعة للتعليقات من العملاء التي تسمح بخلق فهم شامل لتجارب العملاء وشعوراتهم واحتياجاتهم. هذا يسمح لهم بتحديد وتصحيح القضايا الحرجة بسرعة، واتخاذ قرارات مبنية على البيانات، وتحسين منتجاتهم بناءً على الصورة الكاملة لتعليقات العملاء عبر جميع نقاط التواصل.
مستقبل RAG
تعتبر تقنية RAG تغيير أساسي في مجال التصميم الاصطناعي، مزيد من تحويل قوة نماذج اللغة الكبيرة مع استخراج المعلومات الديناميكية. ويستخدم العديد من المنظمات بالفعل هذه التقنية وتقوم ببناء حلول مختلفة لتلبية احتياجاتها.
وأنت نحن ننظر الى المستقبل، ستحول RAG الطريقة التي نتفاعل بها مع المعلومات والقرارات. سيكون أنظمة RAG المستقبلية:
- تمتلك فهمًا تعقيدًا أكثر وتشكيلًا شخصيًا ممكنًا أكثر
- ستكون متعددة الأوامر بتخطي أبعاد النص وتضمان صور وملفات صوتية/فيديو
- ستتم تحديثات دائمة للمعلومات الرئيسية
- ستكون متكاملة بالعديد من الأدوار لتحسين الإنتاجية والتعاون
ختام
في الختام، ستحول RAG الطريقة التي نتفاعل بها مع التصميم الاصطناعي والمعلومات. بإغلاق الفجوة بين المحتوى المنشور من قبل التصميم الاصطناعي ودقة الحقائق التي يمكن إنجازها، ستوضع RAG خطوة أولى لأنظمة التصميم الذكية التي لا تكون فقط أكثر قدرة ولكن أيضًا أكثر دقة وموثوقية. وأيضًا تتطور هذا ، سيكون تواصلنا مع المعلومات فعالًا ودقيقًا من قبل.
Source:
https://dzone.com/articles/rag-enhancing-ai-language-models