













오늘날의 대규모 가상 인프라는 많은 양의 데이터를 생성합니다. 이로 인해 백업 데이터 양과 백업 저장 인프라에 지출이 증가하게 되는데, 이는 저장용 기기 및 그 유지보수를 포함합니다. 이러한 이유로 네트워크 관리자들은 중요한 기계 및 응용 프로그램의 빈번한 백업을 만들 때 저장 공간을 절약하는 방법을 찾습니다.
백업 중복 제거는 널리 사용되는 기술 중 하나입니다. 이 블로그 게시물에서는 데이터 중복 제거의 의미, 중복 제거 유형 및 백업에 초점을 맞춘 사용 사례에 대해 다룹니다.
중복 제거란 무엇인가?
데이터 중복 제거는 저장 용량 최적화 기술입니다. 데이터 중복 제거는 소스 데이터 및 이미 저장된 데이터를 읽어서 고유한 데이터 블록만 전송하거나 저장합니다. 중복 데이터에 대한 참조가 유지됩니다. 이 기술을 사용하여 볼륨에서 중복을 피하면 디스크 공간을 절약하고 저장 오버헤드를 줄일 수 있습니다.
데이터 중복 제거의 기원
데이터 중복 제거의 전신은 각각 1977년과 1978년에 소개된 LZ77 및 LZ78 압축 알고리즘입니다. 이들은 반복되는 데이터 시퀀스를 원본에 대한 참조로 대체하는 것을 포함합니다.
이 개념은 다른 인기 있는 압축 방법에 영향을 미쳤습니다. 이 중에서도 가장 잘 알려진 것은 DEFLATE로, PNG 이미지 및 ZIP 파일 형식에서 사용됩니다. 이제 백업 중복 제거가 가상 머신 백업에서 어떻게 작동하며 정확히 어떻게 저장 공간을 절약하고 인프라에 지출되는 비용을 줄이는 데 도움이 되는지 살펴보겠습니다.
백업에서 중복 제거란 무엇인가?
백업 중에 데이터 중복 제거는 원본 스토리지와 대상 백업 리포지토리 사이에서 동일한 데이터 블록을 확인합니다. 중복 데이터는 복사되지 않고 대상 백업 스토리지의 기존 데이터 블록에 대한 참조 또는 포인터가 생성됩니다.
데이터 중복 제거로 얼마나 많은 공간을 절약할 수 있습니까?
중복 제거로 얼마나 많은 저장 공간을 확보할 수 있는지 이해하기 위해 예를 들어 보겠습니다. Windows Server 2016을 설치하기 위한 최소 시스템 요구 사항은 적어도 32GB의 여유 디스크 공간입니다. 이 OS를 실행하는 10개의 VM이 있다면 백업은 적어도 320GB가 되며, 이는 어떤 애플리케이션이나 데이터베이스도 포함되지 않은 깨끗한 운영 체제입니다.
동일한 시스템으로 두 개 이상의 가상 머신(VM)을 배포해야 한다면 템플릿을 사용할 가능성이 크며, 이는 처음에 10개의 동일한 머신이 있을 것이라는 뜻입니다. 또한 이는 중복 데이터 블록 10세트를 얻게 된다는 것을 의미합니다. 이 예에서는 10:1의 저장 공간 절약 비율을 얻게 됩니다. 일반적으로 절약 범위가 5:1에서 10:1인 것은 좋다고 여겨집니다.
데이터 중복 제거 비율
데이터 중복 제거 비율은 중복 부분이 제거된 후의 데이터 크기 대비 원본 데이터 크기를 측정하는 지표입니다. 이 지표를 사용하면 데이터 중복 제거 프로세스의 효과를 평가할 수 있습니다. 이 값을 계산하려면 중복 제거 전 데이터 양을 중복 제거 후 해당 데이터가 소비하는 저장 공간으로 나누어야 합니다.
예를 들어, 5:1 중복 제거 비율은 중복 제거 없이 동일한 데이터를 저장하는 데 필요한 저장 공간보다 백업 저장소에 다섯 배 더 많은 데이터를 저장할 수 있다는 것을 의미합니다.
당신은 중복 제거 비율과 저장 공간 축소을 결정해야 합니다. 이 두 매개변수는 때로 혼동될 수 있습니다. 중복 제거 비율은 일정 지점을 넘어서면 점차적인 수익 감소의 법칙이 작용하기 때문에 데이터 축소 혜택에 비례하여 변하지 않습니다. 아래 그래프를 참조하십시오.
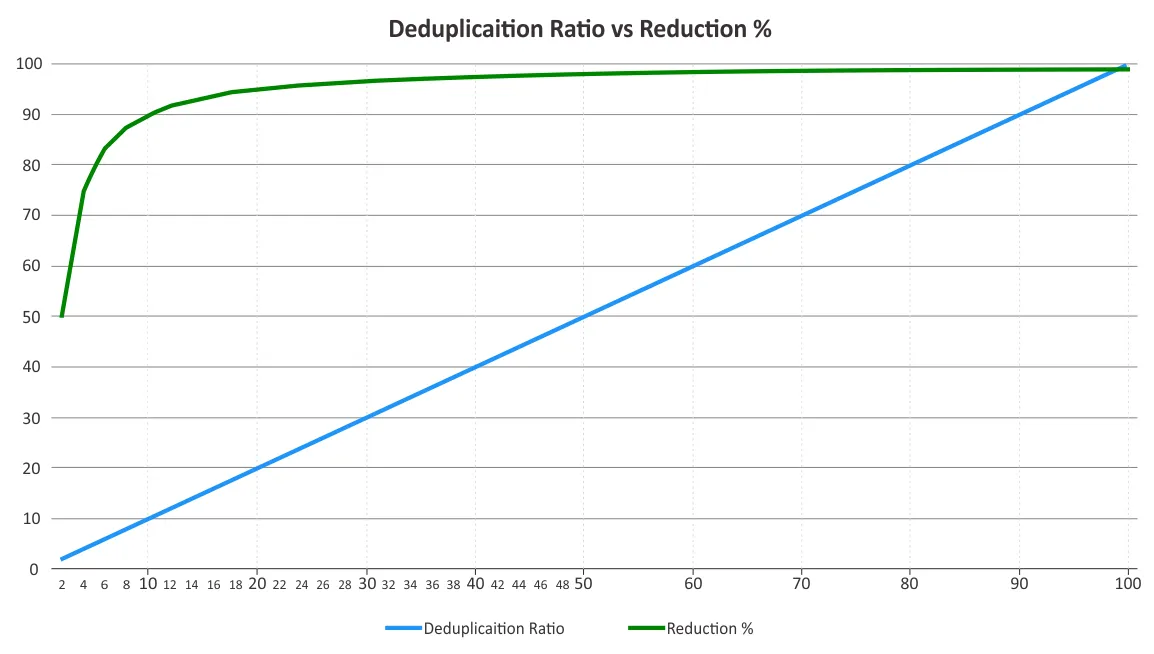
이는 낮은 비율이 높은 비율보다 더 많은 절감을 가져올 수 있다는 것을 의미합니다. 예를 들어, 50:1 중복 제거 비율이 10:1 비율보다 다섯 배 더 좋은 것은 아닙니다. 10:1 비율은 소비된 저장 공간을 90% 줄이는 반면, 50:1 비율은 대부분의 중복이 이미 제거되었기 때문에 이 값을 98%로 높입니다. 이러한 백분율이 어떻게 계산되는지 자세한 내용은 데이터 중복 제거에 대한 스토리지 네트워킹 산업 협회(SNIA) 문서를 참조하십시오.
데이터 중복 제거 효율에 영향을 미치는 요소들
데이터가 실제로 중복 제거되기 전까지 데이터 감소 효율을 예측하기 어려운 이유는 여러 가지 요인들 때문이다. 중복 제거를 사용할 때 데이터 감소에 영향을 미치는 몇 가지 요인은 다음과 같다:
- 데이터 백업 유형 및 정책. 전체 백업의 경우 중복 제거가 증분 또는 차등 백업보다 더 효과적이다.
- 변경률. 백업할 데이터 변경 사항이 많을수록 중복 제거 비율이 낮아진다.
- 유지 설정. 데이터 백업을 백업 저장소에 오래 보관할수록 해당 저장소의 데이터 중복 제거가 더 효과적일 수 있다.
- 데이터 유형. 이미 압축된 데이터가 있는 파일(JPG, PNG, MPG, AVI, MP4, ZIP, RAR 등)의 경우 중복 제거가 효과적이지 않다. 메타데이터가 풍부하거나 암호화된 데이터에도 동일한 원칙이 적용된다. 반복적인 부분을 포함하는 데이터 유형이 중복 제거에 더 적합하다.
- 데이터 범위. 데이터 중복 제거는 데이터 범위가 클수록 더 효과적이다. 글로벌 중복 제거는 로컬 중복 제거보다 더 많은 저장 공간을 절약할 수 있다.
참고: 로컬 중복 제거는 단일 노드/디스크 장치에서 작동합니다. 글로벌 중복 제거는 모든 노드/디스크 장치의 전체 데이터 세트를 분석하여 데이터 중복을 제거합니다. 각각 로컬 중복 제거가 활성화된 여러 노드가 있는 경우, 그들에 대해 글로벌 중복 제거가 활성화된 것만큼 효율적이지 않을 수 있습니다.
- 소프트웨어 및 하드웨어. 소프트웨어 솔루션과 중복 제거 하드웨어를 결합하면 소프트웨어만으로는 제공할 수 없는 더 나은 중복 제거 비율을 제공할 수 있습니다. 예를 들어, NAKIVO의 백업 솔루션은 HP StoreOnce, Dell EMC Data Domain 및 NEC HYDRAstor 중복 제거 장치와 통합하여 최대 17:1의 중복 제거 비율을 제공합니다.
백업 중복 제거 기술
백업 중복 제거 기술은 다음을 기반으로 분류할 수 있습니다:
- 데이터 중복 제거가 수행되는 위치
- 중복 제거가 수행되는 시기
- 중복 제거가 수행되는 방법
데이터 중복 제거가 수행되는 위치
백업 중복 제거는 소스 측이나 대상 측에서 수행할 수 있으며, 해당 기술은 각각 소스 측 중복 제거와 대상 측 중복 제거라고 합니다.
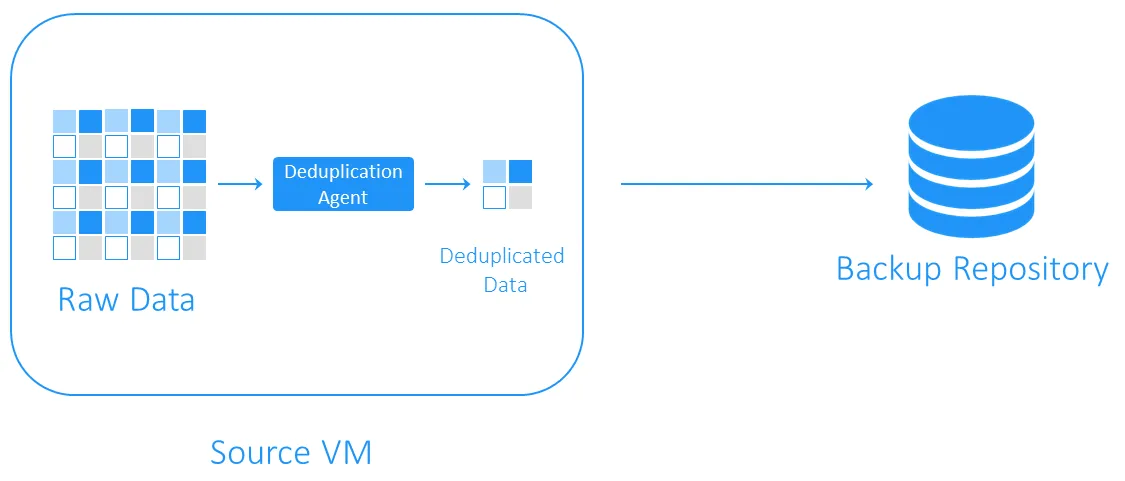
소스 측 중복 제거
원본 측 중복 제거는 백업 중 데이터 전송량이 감소하여 네트워크 부하가 줄어듭니다. 그러나 각 VM 또는 각 호스트에 중복 제거 에이전트를 설치해야 합니다. 다른 단점은 중복 제거가 소스 측에서 이루어질 경우 중복 데이터 블록 식별을 위해 필요한 계산으로 인해 VM의 성능이 느려질 수 있다.
대상 측 중복 제거
대상 측 중복 제거는 먼저 데이터를 백업 저장소로 전송한 다음 중복 제거를 수행합니다. 중복 제거를 담당하는 소프트웨어가 무거운 계산 작업을 수행합니다.
데이터 중복 제거가 완료되면
백업 중복 제거는 인라인 또는 후 처리 방식일 수 있습니다.
- 인라인 중복 제거는 백업 저장소에 기록되기 전에 데이터 중복을 확인합니다. 이 기술은 백업 데이터 스트림에서 중복을 제거하여 백업 저장소에서 더 적은 저장 공간을 필요로 하지만, 백업 작업 중에 인라인 중복 제거가 발생하기 때문에 백업 시간이 더 오래 걸립니다.
- 후 처리 중복 제거는 데이터를 백업 저장소에 기록한 후에 처리합니다. 이 방식은 명백히 저장소에 더 많은 여유 공간이 필요하지만, 백업이 더 빨리 실행되며 필요한 모든 작업이 이후에 수행됩니다. 후 처리 중복 제거는 비동기 중복 제거로도 불립니다.
데이터 중복 제거 방법
중복을 식별하는 가장 일반적인 방법은 해시 기반 및 수정된 해시 기반 방법입니다.
- 해시 기반 방법을 사용하면 중복 제거 소프트웨어는 데이터를 고정 또는 가변 길이의 블록으로 나누고 MD5, SHA-1 또는 SHA-256과 같은 암호화 알고리즘을 사용하여 각각에 대한 해시를 계산합니다. 이러한 방법 각각은 데이터 블록의 고유한 지문을 생성하므로 유사한 해시를 가진 블록은 동일하다고 간주됩니다. 이 방법의 단점은 대규모 백업의 경우에는 상당한 컴퓨팅 자원이 필요할 수 있다는 것입니다.
- 수정된 해시 기반 방법은 CRC와 같은 간단한 해시 생성 알고리즘을 사용하며 이러한 알고리즘은 SHA-256의 256비트 대신 16비트의 해시만 생성합니다. 그런 다음 블록이 유사한 경우 바이트 단위로 비교됩니다. 블록이 완전히 동일하면 해당 블록은 동일하다고 간주됩니다. 이 방법은 해시 기반 방법보다 느리지만 더 적은 컴퓨팅 자원이 필요합니다.
백업 중복 제거 소프트웨어 선택
백업 중복 제거는 중복 제거의 가장 인기 있는 사용 사례 중 하나입니다. 그러나 이 데이터 축소 기술을 구현하려면 적절한 소프트웨어 솔루션과 저장용 하드웨어가 필요합니다.
NAKIVO Backup & Replication은 수정된 해시 기반 중복 탐지를 사용하는 글로벌 대상 후 처리 중복 제거를 지원하는 백업 솔루션입니다. 또한 NAKIVO 솔루션과 통합하여 DELL EMC Data Domain with DD Boost, NEC HYDRAstor 및 Catalyst 지원을 갖춘 중복 제거 애플라이언스와 같은 소스 측 중복 제거를 활용할 수 있습니다.
Source:
https://www.nakivo.com/blog/backup-deduplication-explained/