













실시간 데이터 시대에 있어 스트리밍 정보를 처리하고 분석하는 능력은 기업에게 중요해졌습니다. 강력한 분산 이벤트 스트리밍 플랫폼인 아파치 카프카는 종종 이러한 실시간 파이프라인의 핵심 역할을 합니다. 그러나 데이터의 원시 스트림을 다루는 것은 복잡할 수 있습니다. 이것이 스트리밍 SQL이 필요한 이유입니다: 그것은 사용자가 SQL의 간편함으로 카프카 토픽을 쿼리하고 변환할 수 있게 합니다.
스트리밍 SQL이란 무엇인가?
스트리밍 SQL은 데이터를 처리하고 분석하기 위해 구조화된 쿼리 언어 (SQL)을 적용하는 것을 말합니다. 전통적인 SQL은 데이터베이스의 정적 데이터셋을 쿼리하는 반면, 스트리밍 SQL은 데이터가 시스템을 흐르는 동안 지속적으로 처리합니다. 실시간으로 필터링, 집계, 조인, 윈도잉과 같은 작업을 지원합니다.
실시간 데이터 파이프라인의 중심에 카프카를 두고 있는 경우, 스트리밍 SQL을 사용하면 사용자가 복잡한 코드를 작성하지 않고도 카프카 토픽을 직접 쿼리할 수 있어 데이터를 분석하고 대응하기 쉬워집니다.
카프카에서의 스트리밍 SQL의 주요 구성 요소
1. 아파치 카프카
카프카는 토픽을 통해 실시간 이벤트를 저장하고 스트림으로 전송합니다. 프로듀서가 데이터를 토픽에 쓰고, 컨슈머가 해당 데이터를 처리하거나 분석하기 위해 구독합니다. 카프카의 내구성, 확장성, 장애 허용성은 스트리밍 데이터에 이상적입니다.
2. 카프카 커넥트
Kafka Connect는 데이터베이스, 객체 저장소 또는 기타 스트리밍 플랫폼과의 통합을 용이하게 합니다. Kafka 토픽으로부터 데이터의 매끄러운 수집 또는 내보내기를 가능하게 합니다.
3. 스트리밍 SQL 엔진
여러 도구가 Kafka에서 스트리밍 SQL을 가능하게 합니다. 이 도구들로는 다음이 포함됩니다:
- ksqlDB: Kafka 네이티브 스트리밍 SQL 엔진으로 Kafka Streams에 기반을 둡니다.
- Apache Flink SQL: 고급 SQL 기능을 갖춘 다목적 스트림 처리 프레임워크입니다.
- Apache Beam: 다양한 실행기와 호환되는 배치 및 스트림 처리용 SQL을 제공합니다.
- Spark Structured Streaming: 실시간 및 배치 데이터 처리를 위한 SQL을 지원합니다.
스트리밍 SQL이 작동하는 방법
스트리밍 SQL 엔진은 Kafka에 연결하여 토픽에서 데이터를 읽고, 실시간으로 처리하며 결과를 다른 토픽, 데이터베이스 또는 외부 시스템에 출력합니다. 일반적으로 다음 단계를 포함합니다:
- 데이터 스트림 정의: 사용자는 Kafka 토픽을 소스로 지정하여 스트림 또는 테이블을 정의합니다.
- 쿼리 실행: 필터링, 집계 및 스트림 결합과 같은 작업을 수행하기 위해 SQL 쿼리가 실행됩니다.
- 결과 출력: 결과는 Kafka 토픽이나 데이터베이스 또는 대시보드와 같은 외부 싱크에 다시 쓸 수 있습니다.
흐름 다이어그램
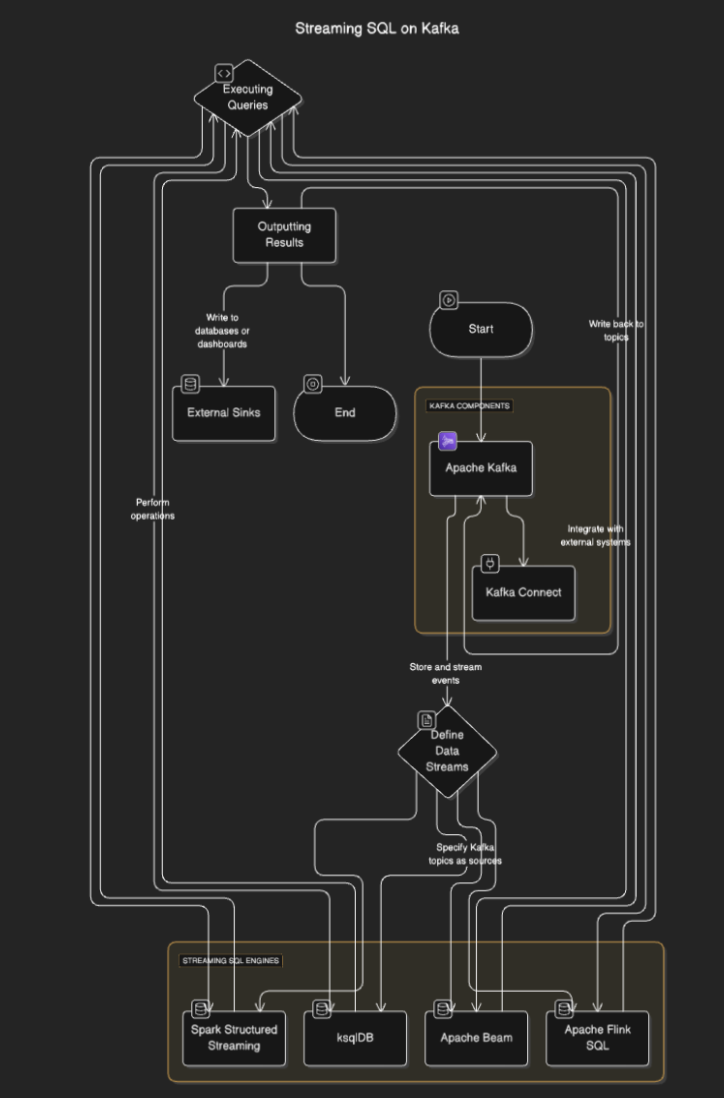
Kafka를 위한 스트리밍 SQL 도구
ksqlDB
ksqlDB는 Kafka를 위해 특별히 설계되었으며 Kafka 토픽을 처리하기 위한 SQL 인터페이스를 제공합니다. 메시지 필터링, 스트림 조인 및 데이터 집계와 같은 작업을 간소화합니다. 주요 기능은 다음과 같습니다:
- 선언적 SQL 쿼리: 코딩 없이 실시간 변환을 정의합니다.
- 물리화된 뷰: 빠른 조회를 위해 쿼리 결과를 지속화합니다.
- Kafka 네이티브: 저지연 처리에 최적화되어 있습니다.
예시:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink는 배치 및 스트리밍 데이터 모두를 위한 SQL 기능을 제공하는 강력한 스트림 처리 프레임워크입니다. 이벤트 시간 처리 및 고급 윈도잉과 같은 복잡한 작업을 지원합니다.
예시:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark 구조화된 스트리밍
스파크 구조적 스트리밍은 SQL 기반의 스트림 처리를 가능하게 하며 다른 스파크 구성 요소와 잘 통합됩니다. 배치 및 스트림 처리를 결합한 복잡한 데이터 파이프라인에 이상적입니다.
예시:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
카프카에서 스트리밍 SQL의 사용 사례
- 실시간 분석. 사용자 활동, 판매 또는 IoT 센서 데이터를 실시간 대시보드로 모니터링합니다.
- 데이터 변환. 카프카 주제를 통해 흐르는 데이터를 정제하고, 필터링하며, 풍부하게 합니다.
- 사기 탐지. 실시간으로 의심스러운 거래나 패턴을 식별합니다.
- 동적 경고. 특정 임계값이나 조건이 충족되면 경고를 발생시킵니다.
- 데이터 파이프라인 강화. 외부 데이터 세트와 스트림을 조인하여 풍부한 데이터 출력을 생성합니다.
카프카에서 스트리밍 SQL의 이점
- 개발 간소화. SQL은 많은 개발자에게 익숙하므로 학습 곡선을 줄여줍니다.
- 실시간 처리. 스트리밍 데이터에 대한 즉각적인 통찰력과 행동을 가능하게 합니다.
- 확장성. 카프카의 분산 아키텍처를 활용하여 확장성을 보장합니다.
- 통합. 기존 카프카 기반 파이프라인과 쉽게 통합됩니다.
도전 과제 및 고려사항
- 상태 관리. 복잡한 쿼리는 대규모 상태를 관리해야 할 수 있으며 성능에 영향을 줄 수 있습니다.
- 쿼리 최적화. 고효율의 쿼리를 보장하여 고처리량 스트림을 처리할 수 있도록 합니다.
- 도구 선택. 요구 사항에 따라 적절한 SQL 엔진을 선택합니다(예: 대기 시간, 복잡성).
- 장애 허용성. 스트리밍 SQL 엔진은 노드 장애를 처리하고 데이터 일관성을 보장해야 합니다.
결론
Kafka에서의 스트리밍 SQL은 SQL의 간편함으로 실시간 데이터를 활용할 수 있는 비즈니스에 강력한 도구입니다. ksqlDB, Apache Flink 및 Spark Structured Streaming과 같은 도구를 사용하면 깊은 프로그래밍 전문 지식 없이도 견고하고 확장 가능하며 저지연 데이터 파이프라인을 구축할 수 있습니다.
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka