













문제 陈述
이 AI 솔루션의 “왜” 문제는 다양한 분야에서 중요하고 널리 распространен합니다.
다양한 扫描 PDF 문서가 있다고 상상하세요:
- 고객이 일부 수동 선택을 하고, 서명/날짜/고객 정보를 추가합니다.
- scanning 과정에서 생성된 다양한 страницы의 쓴 문서를 scanning 하고, 이러한 문서から 텍스트를 추출하는 솔루션을 찾고 있습니다.
또는
- 구조화된 형식이 없는 문서에 대해 질문하는 Interactive Mechanism을 제공하는 AI-based 수단을 찾고 있습니다.
scanning / mixed / unstructured documents를 처리하는 것은 어려울 수 있으며, 중요한 정보를 이러한 문서에서 추출하는 것은 수동적이고, 오류가 발생하고, 시행착오가 많습니다.
下記の 솔루션은 OCR(Optical character recognition)의 능력과 LLM(Large Language Models)를 사용하여 이러한 문서から 텍스트를 추출하고, 이를 통해 구조화된 신뢰성 정보를 얻을 수 있도록 Query를 수행합니다.
高层次 建筑设计
사용자 인터페이스
- 사용자 인터페이스는 PDF/스캔된 문서를 업로드할 수 있도록 하며 (추후 다른 문서 유형으로도 확장될 수 있습니다).
- Streamlit가 사용자 인터페이스에 활용되고 있습니다:
- 이는 오픈 소스 파이썬 프레임워크로 사용이 매우 간편합니다.
- 변경이 이루어지면 실행 중인 앱에 반영되어 빠른 테스트 메커니즘이 됩니다.
- Streamlit에 대한 커뮤니티 지원은 상당히 강력하고 성장하고 있습니다.
- 대화 체인:
- 이는 후속 질문에 답변하고 채팅 기록을 제공할 수 있는 챗봇을 통합하는 데 필수적입니다.
- 우리는 사용하는 AI 모델과 인터페이스하기 위해 LangChain을 활용합니다; 이 프로젝트의 목적을 위해 OpenAI와 Mistral AI로 테스트했습니다.
back-end 서비스
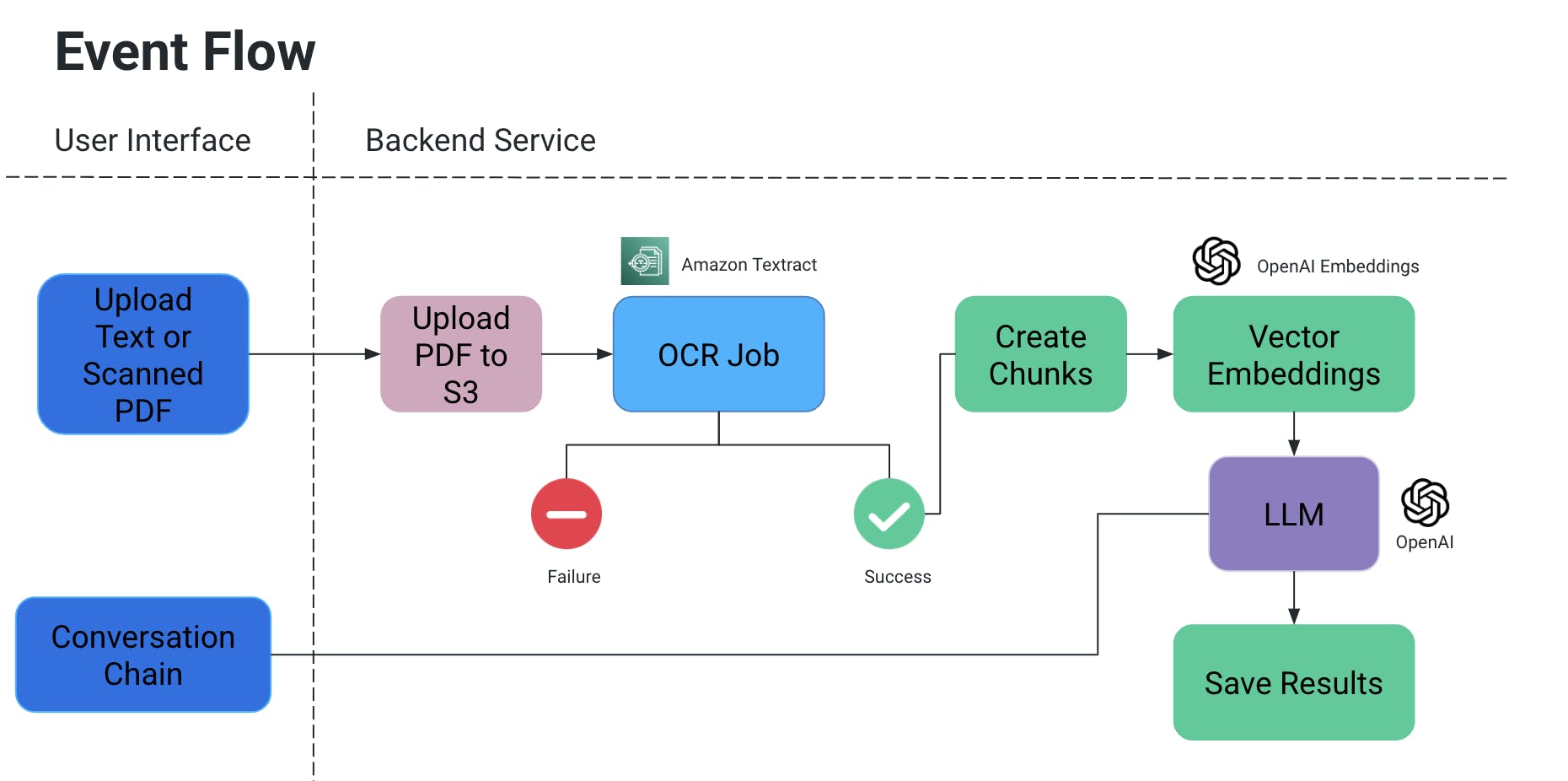
이벤트 흐름
- 사용자가 PDF/스캔 문서를 업로드하면 S3 버킷에 업로드 됩니다.
- OCR 서비스는 S3 버킷에서 이 문서를 가져와 텍스트를 추출하는 작업을 실시합니다.
- 위의 결과로부터 텍스트 块이 생성되며, 그들에 대응하는 vecotr embedding이 생성됩니다.
- 이것이 매우 중요하다는 것을 이해하세요, 텍스트 块이 분할되는 것을 防ぐ purposes: 문장 중간에 분할되어 있을 수 있으며, 某些 punctuations이 없어 의미가 끊어지는 등이 있습니다.
- 따라서, 겹쳐진 块을 생성하여 이러한 문제를 해결합니다.
- 我们使用的这个大型语言模型将这些嵌入作为输入,并且具有两个功能:
- 生成特定输出:
- 如果我们有一种特定的信息需要从文件中提取,我们可以在AI模型中提供代码查询,获取数据,并以结构化格式存储它。
- 通过显式添加具有条件的代码查询来避免AI虚构,这样就不会编造特定的值,只使用文件的上下文。
- 我们可以将其作为S3/本地文件存储,或者写入数据库。
- 聊天
- 在这里,我们提供了最终用户与AI进行聊天以在文件上下文中获取特定信息的途径。
- 生成特定输出:
OCR Job
- Amazon Textract를 이용하여 이러한 문서에 대한 optical recognition을 실시합니다.
- 表格/양식 등이 있는 문서에서도 좋은 result를 얻을 수 있습니다.
- POC에서 작업하는 경우, 이 서비스를 免费的 tier로 이용하십시오.
Vector Embeddings
- vektor 嵌入(embedment)을 이해하는 간단한 방법은 단어나 문장을 숫자로 옮기는 것입니다. 이 숫자는 현재 上下文(context)의 의미와 관계를 CAPTCHA
- “ring”라는 어휘를 생각해봅시다. 이 어휘가 가장 가까운 어휘로는 “sing”이 나오ます. 그러나 어휘의 의미에 따라서는 “jewelry”(宝石), “finger”(손가락), “gemstones”(宝石)과 같은 것과 일치하고 싶을 것입니다. 또한 “hoop”(鞍馬), “circle”(원)과 같은 어휘로 일치하는 것이 좋을 것입니다.
- 따라서 “ring”의 vektor 嵌入(embedment)을 만들 때, 그의 의미와 관계에 대한 많은 정보를 담기 때문입니다.
- 이러한 정보는 문서에 있는 다른 어휘/ 陈述(statement)의 vektor 嵌入(embedment)과 함께 있으면, 어휘 “ring”의 현재 上下文(context)에서 correct meaning을 추정할 수 있습니다.
- 우리는 OpenAIEmbeddings을 사용하여 vektor 嵌入(embedment)을 생성했습니다.
LLM
- 우리의 현상에 적용할 수 있는 다양한 대형 언어 모델이 存在합니다.
- 이 프로젝트 범위 내에서는 OpenAI와 Mistral AI를 사용한 테스트가 이뤄졌습니다.
- OpenAI의 API 키 相关信息은 here에서 더 많이 보실 수 있습니다.
- Mistral AI 대신에 HuggingFace를 활용했습니다.
사용 사례와 테스트
다음과 같은 테스트를 실시했습니다:
- 서명과 手写の 日付/텍스트를 OCR를 사용하여 읽었습니다.
- 문서의 手動 선택 옵션
- 문서上에 디지털 선택을 하였습니다.
- 불STRUKTURIERTES 데이터를 해석하여 탭ular 내용을 얻었습니다.(텍스트 파일 / DB 등에 추가하기, 등)
향후 Scope는 다음과 같습니다.
上記 프로젝트의 用途을 更进一步的に 확장할 수 있습니다. 이미지를 integrate하고, Confluence/Drive과 같은 文档存储을 통해 特定 主题相关的信息를 多种 sources에서 拉取, 두 문서之间进行 比较分析的 更强的途径 추가하는 것을 포함합니다.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data