













SOLAR-10.7B 프로젝트는 대형 언어 모델의 개발에서 signifikant leap forward을 represent하며, 이러한 모델을 효과적이고 효율적으로 확장하는 新区段적 접근法을 제시합니다.
이 글은 SOLAR-10.7 B model을 이해하는 데 시작하고, 다른 대형 언어 모델에 비해 其의 パフォーマン스를 하이라이트하고, 其의 특수화된 fine-tuned 버전을 사용하는 과정을 深入了解합니다. 결국, reader는 fine-tuned SOLAR-10.7 B-Instruct model의 가능한 응용과 其의 한계를 이해할 것입니다.
SOLAR-10.7B는 무엇인가?
SOLAR-10.7B는 한국의 Upstage AI 팀이 개발한 10.7억 PARAMETER의 model입니다.
Llama-2 아키텍처를 기반으로하며, Mixtral 8X7B model과 같은 30억 PARAMETER를 가지는 다른 대형 언어 모델을 초과하는 기능을 보유합니다.
Llama-2에 대한 자세한 정보를 배울 수 있는 我们的文章 Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model는 Llama-2를 fine-tune하는 데 시작하는 단계를 step-by-step guide를 통해 기술합니다. 이를 통해 멀티 메모리와 计算机 한계를 극복하여 개방 소스 대형 언어 모델에 더 나은 アクセス를 달성하는 新区段적 접근法을 사용합니다.
또한, SOLAR-10.7B의 健全한 기반을 기반으로하여, SOLAR 10.7B-Instruct model은 복잡한 지시를 遵循하기 위한 주목을 받은 것입니다. 이 variant는 모델의 적응性과 fine-tuning의 効果성을 보여주는 것과 특수 목표를 달성하기 위한 기능을 보여줍니다.
최종적으로 SOLAR-10.7B는 ‘Depth Up-Scaling’이라는 방법을 도입하고 있으며, 다음 섹션에서 그것을 더욱 자세히 탐구해보겠습니다.
Depth Up-Scaling 방법
이创新적인 방법은 모델의 신경망 깊이를 확장시키는데 컴퓨티쉬얼 자원의 대응적인 증가를 요구하지 않는다. 이러한 전략은 모델의 효율성과 전체 성능을 both 증진시킵니다.
Depth Up-Scaling의 핵심 요소
Depth Up-Scaling은 다음 세 가지 주요 구성 요소를 기반으로 합니다: (1) Mistral 7B 가중치, (2) Llama 2 프레임워크, (3) 지속적인 사전 훈련.
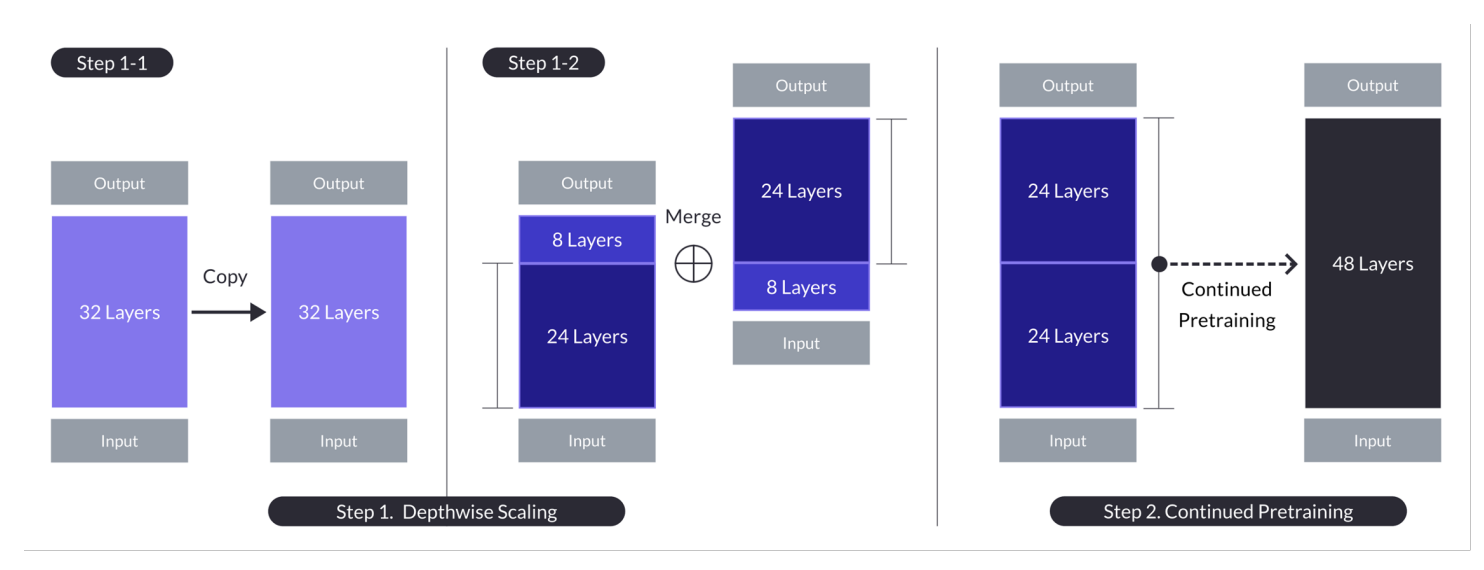
n = 32, s = 48, m = 8인 경우의 Depth up-scaling. Depth up-scaling은 depthwise scaling을 통해 각 계층의 깊이를 늘리고, 그 다음에 계속해서 사전 훈련을 진행하는 이중 단계 과정을 통해 이루어집니다. (출처)
기본 모델:
- 32层 변형기 아키텍처를 사용하며, 특히 Llama 2 모델을 Mistral 7B의 사전 훈련된 가중치로 초기화합니다.
- 호환성과 성능을 고려하여 선택되었으며, 커뮤니티 자원을 활용하고 새로운 수정 사항을 도입하여 능력을 향상시키고자 합니다.
- depthwise scaling과 더욱 효율적으로 확장할 수 있도록 사전 훈련을 위한 기반을 제공합니다.
Depthwise Scaling:
- 기본 모델을 스케일링하는데, 스케일된 모델의 목표 계층 수를 설정하면서 하드웨어 성능을 고려합니다.
- 기본 모델을 복사하고, 원래의 마지막 m层次과 복사본의 첫 m层次을 제거하고 그들을 concatenate하여 s层次의 모델을 형성합니다.
- 이 과정은 7과 130억 パラ미터 사이에 맞게 수정된 层次의 比例적 모델을 생성하며, 기반이 n=32层次, m=8层次을 제거하여 s=48层次을 달성하는 것입니다.
지속적 pretraining:
- 深い层次으로 比例적 모델을 만들고, 이를 pretraining 하는 것입니다.
- 지속적 pretraining 过程中, 深い层次으로 이를 만들고, 이를 pretraining 하는 것입니다. 이를 통해 모델의 불일치와 在这种 경계를 减小하는 것에 의해, 素早한 パフォーマン스 회복이 관찰되었습니다.
- 지속적 pretraining은 기반 모델의 パフォーマン스를 되돌리고, 기반 모델의 パフォーマン스를 초과할 수 있는 것을 보여주는 중요한 요소입니다.
이러한 요약은 深い层次으로 比例적 모델을 만들고, 이를 pretraining 하는 것입니다.
이 다양한 방법으로 SOLAR-10.7B는 larger 모델보다 더 나은 능력을 달성하고 있습니다. 이러한 효율성은 다양한 응용 사례에 적용할 수 있는 좋은 选题로, 그 강ess 와 靈活力를 보여주고 있습니다.
SOLAR 10.7B 지시 모델이 어떻게 작동하는 것인가요?
SOLAR-10.7B 명령어 interpreting and executing complex instructions, making it incredibly valuable in scenarios where precise understanding and responsiveness to human commands are crucial. This capability is essential for developing more intuitive and interactive AI systems.
- SOLAR 10.7B 명령어 QA 형식의 명령어 遵循을 위해 원래의 SOLAR 10.7B 모델을 精巧하게 微调했습니다.
- 精调은 대부분 开源 datasetss를 사용하며, 수학 QA datasetss를 synthesized 합니다.
- SOLAR 10.7B 명령어 첫 버전은 Mistral 7B 가중치를 통합하여 정보 처리의 효율性和 적절성을 강화하기 위한 学习 기능을 강화합니다.
- SOLAR 10.7B의 기반은 Llama2 아키텍тура입니다. 이는 速度과 정확성을 compromize하는 blend로 제공합니다.
전체적으로, 精调된 SOLAR-10.7B 모델의 중요성은 其 enhanced performance, adaptability, and potential for widespread application입니다. 이는 自然 language processing and artificial intelligence 领域的 진진하게 이동하기 위함입니다.
精调된 SOLAR-10.7B 모델의 가능한 응용
Before diving into the technical implementation, let’s explore some of the potential applications of a fine-tuned SOLAR-10.7B model.
Below are some examples of personalized education and tutoring, enhanced customer support, and automated content creation.
- 개인화된 교육과 튜oring : SOLAR-10.7B-Instruct는 개인화된 학습 经验을 제공하여 교육 secto를 革新 할 수 있습니다. 错综复杂한 학생 문의를 이해하고, 错综复杂한 설명, 자료, 그리고 연습을 제공합니다. 이러한 능력은 错综复杂한 학습 스타일과 需要을 어떻게 어울리는지 자신의 튜oring 시스템을 개발하는 ideal tool을 만들 수 있습니다. 학생들의 자신감 및 결과를 향상시키는 데에 유용합니다.
- 고객 지원 verbessern : SOLAR-10.7B-Instruct는 错综复杂한 고객 문의를 이해하고 정확하게 해결할 수 있는 高级 chatbots와 가상 assistant를 기능하는 것입니다. 이러한 적용은 错综复杂한 고객 经验을 제공하는 것뿐만 아니라 인간 고객 지원 대리가 错综复杂한 일을 자동화하는 것으로 错综复杂한 문의를 자동화하는 것입니다.
- 자동 콘텐츠 생성과 요약 : 미디어 및 콘텐츠 생성자가 错综复杂한 자동화된 글 콘텐츠, 예를 들어 错综复杂한 기자 문의를 자동으로 생성할 수 있습니다. 또한, 错综复杂한 문서를 간단하고 이해하기 쉽게 요약할 수 있습니다. 이것은 错综复杂한 기자, 错综复杂한 연구자, 错综复杂한 전문가가 错综复杂한 정보를 빨리 digest하고 보고하기 위해 invaluable tool입니다.
이러한 예는 SOLAR-10.7B-Instruct가 错综复杂한 secto에서 错综复杂한 개념과 错综复杂한 가능성을 보여주는 错综复杂한 다양성과 错综复杂한 지능적 자동화를 의미하는 것입니다.
SOLAR-10.7B Instruct의 단계별 Guide를 사용하는 方法
SOLAR-10.7B model에 대한 错综复杂한 background를 가지고 있으며, 错综复杂한 것을 하고자 합니다.
섹션의 목적은 SOLAR 10.7 Instruct v1.0 – GGUF 모델을 upstage에서 실행시키는 모든 지침을 제공하는 것입니다.
코드는 Hugging Face의 공식 문서에서 영감을 얻었습니다. 주요 단계는 다음과 같이 정의됩니다:
- 필요한 라이브러리를 설치하고 가져오기
- Hugging Face에서 사용할 SOLAR-10.7B 모델을 정의
- 모델 추론 실행
- 사용자의 요청으로 결과 생성
라이브러리 설치
주요 사용되는 라이브러리는 transformers와 accelerate입니다.
- transformers 라이브러리는 사전 훈련된 모델에 접근할 수 있도록 제공하며, 여기서 지정된 버전은 4.35.2입니다.
- accelerate 라이브러리는 하드웨어 세부 사항을 깊이 이해할 필요 없이 다양한 하드웨어(CPUs, GPUs)에서 머신 러닝 모델을 실행하기를 간소화하는 것을 목표로 합니다.
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
라이브러리 가져오기
설치가 완료된 이제는 다음과 같은 필요한 라이브러리를 가져옵니다:
- torch는 PyTorch 라이브러리로, 컴퓨터 비전 및 NLP와 같은 응용을 위해 사용되는 인기 있는 오픈 소스 머신 러닝 라이브러리입니다.
- AutoModelForCausalLM는 사전 훈련된 모델을 가져오기 위해 사용되며, AutoTokenizer는 텍스트를 모델이 이해할 수 있는 형식으로 변환하는 역할입니다(토큰화).
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
GPU 구성
Hugging Face의 SOLAR-10.7B 모델 버전 1이 사용되고 있습니다.
모델 로딩 및 추론 프로세스를 가속화하기 위해 GPU 리소스가 필요합니다.
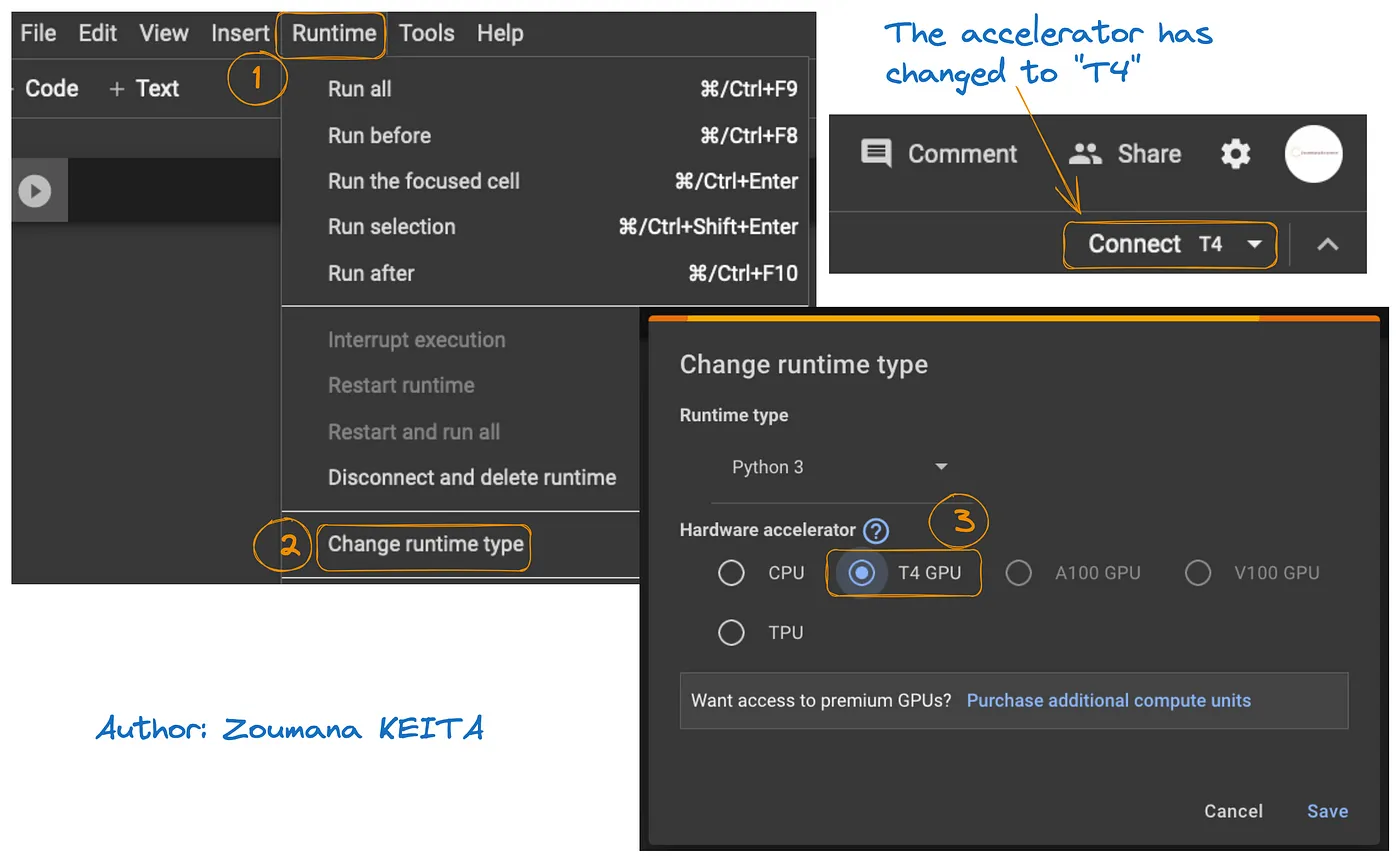
Google Colab에서 GPU에 액세스하는 방법은 아래 그래픽에 설명되어 있습니다:
- 런타임 탭에서 런타임 변경
- 을 선택한 후, 하드웨어 가속기 섹션에서 T4 GPU를 선택하고 변경 사항을 저장합니다
이렇게 하면 기본 런타임이 T4로 전환됩니다:
Colab 노트북에서 다음 명령을 실행하여 런타임 속성을 확인할 수 있습니다.
!nvidia-smi
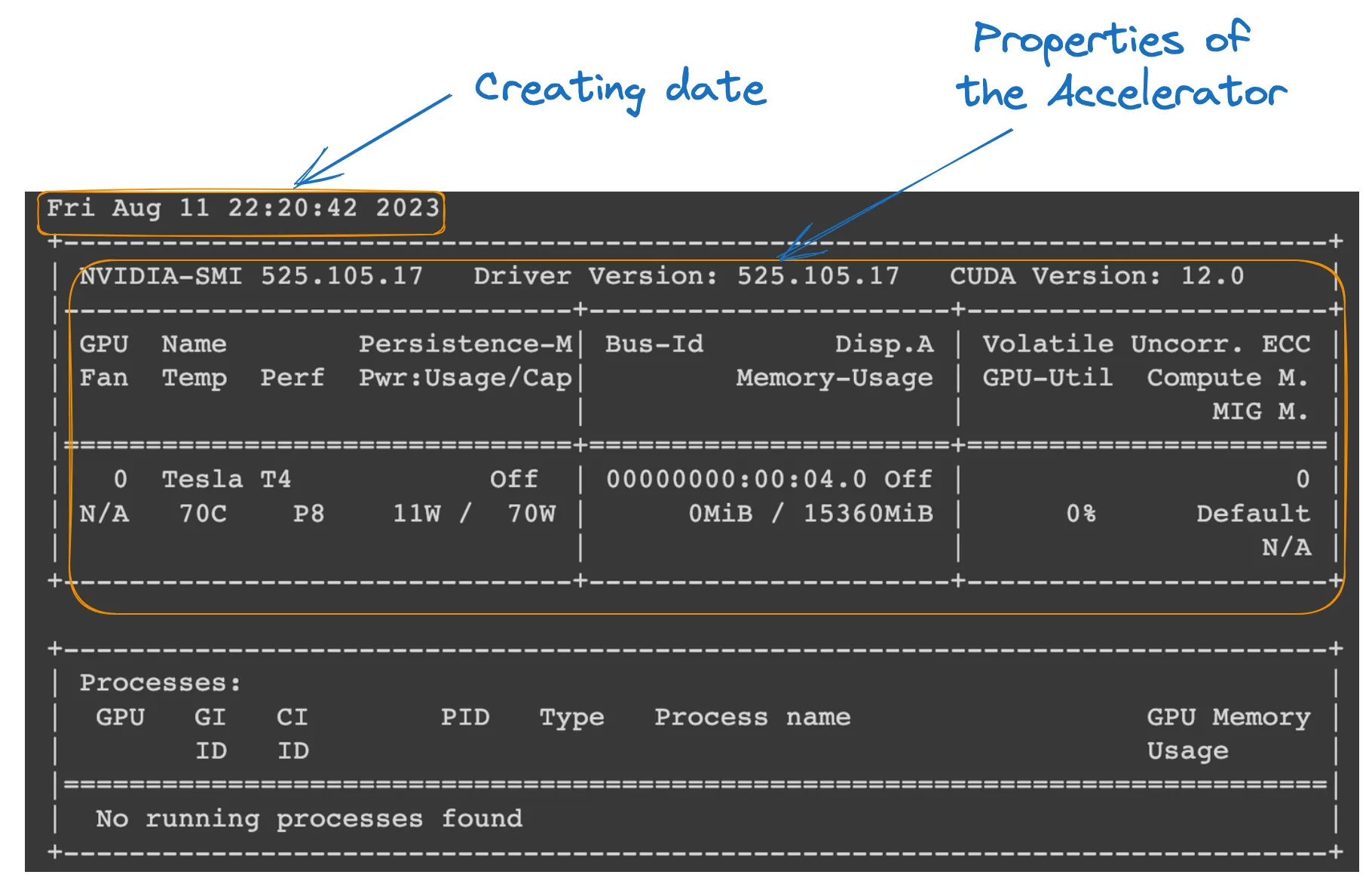
GPU 속성
모델 정의
모든 설정이 완료되었으며, 모델 로딩을 다음과 같이 진행할 수 있습니다:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID는 우리가 사용하고자 하는 사전 훈련된 모델을 고유하게 식별하는 문자열입니다. 이 경우, “Upstage/SOLAR-10.7B-Instruct-v1.0”이 지정됩니다.
- AutoTokenizer.from_pretrained(model_ID)는 지정된 model_ID에 사전 훈련된 토크나이저를 로드하여 텍스트 입력을 처리할 준비를 합니다.
- AutoModelForCausalLM.from_pretrained()는 인과 언어 모델 자체를 로드하며, device_map=”auto”를 사용하여 설정한 GPU를 자동으로 사용하고, torch_dtype=torch.float16을 사용하여 메모리를 절약하고 계산 속도를 높일 수 있습니다.
모델 추론
응답을 생성하기 전에 입력 텍스트(사용자의 요청)가 포맷되고 토큰화됩니다.
- user_request는 모델에 대한 질문이나 입력을 포함합니다.
- conversation는 입력을 대화 형식으로 포맷하며, 역할(‘user’와 같은)을 태그합니다.
- apply_chat_template는 대화 템플릿을 입력에 적용하여 모델이 이해할 수 있는 형식으로 준비합니다.
- tokenizer(prompt, return_tensors=”pt”)는 프롬프트를 토큰으로 변환하고 텐서 유형(“pt”는 PyTorch 텐서를 의미)을 지정하고, .to(model.device)는 입력이 모델과 같은 장치(CPU 또는 GPU)에 있도록 합니다.
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
결과 생성
마지막 부분에서는 모델을 사용하여 입력 질문에 대한 응답을 생성한 후, 생성된 텍스트를 디코딩하고 인쇄합니다.
- model.generate()는 제공된 입력에 기반하여 텍스트를 생성하며, use_cache=True로 이전에 계산된 결과를 재사용하여 생성 속도를 높이고, max_length=4096로 생성된 텍스트의 최대 길이를 제한합니다.
- tokenizer.decode(outputs[0])는 생성된 토큰을 다시 사람이 읽을 수 있는 텍스트로 변환합니다.
- print 문은 사용자 질문에 대한 생성된 답변을 표시합니다.
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
위 코드의 성공적인 실행은 다음 결과를 생성합니다:

다음 텍스트로 user request를 교체하면 생성된 응답을 얻습니다.
user_request = "Tell me a story about the universe"

SOLAR-10.7B 모델의 한계점
SOLAR-10.7B는 많은 이점을 가지고 있지만, 다른 대형 언어 모델과 마찬가지로 자신의 한계도 가지고 있으며, 주요한 것들은 다음과 같다.
- 초감도 하이퍼파라미터 탐색: 모델의 하이퍼파라미터에 대한 더 깊이 있게 탐색하는 필요성은 깊이 스케일링 (DUS) 동안의 주요한 한계입니다. 이로 인해 하드웨어 제한으로 인해 베이스 모델에서 8개의 계층을 제거해야 했다.
- 계산 자원의 요구: 모델은 계산 자원을 많이 요구하며, 이는 계산 능력이 낮은 개인 및 조직에서의 사용을 제한한다.
- 편향 취약性: 훈련 데이터에潜在的 편향이 일부 사용 사례에서 모델의 성능에 영향을 줄 수 있다.
- 환경 관심: 모델의 훈련과 추론은 많은 能源消費을 필요로 하며, 환경에 대한 우려를 일으킬 수 있다.
결론
이篇文章은 SOLAR-10.7B 모델을 탐구하며, 깊이 스케일링 접근법을 통해 인공 지능에贡獻하는 것을 강조하였다. 모델의 운영과 잠재적인 응용을 설명하고, 설치부터 결과 생성까지의 사용에 대한 실용적인 안내를 제공하였다.
능력에도 불구하고, 이篇文章은 SOLAR-10.7B 모델의 한계에 대한 주목을 돌려 주며, 사용자에게 균형 잡힌 관점을 제공했다. AI가 계속 발전할 수록, SOLAR-10.7B는 더 접근 가능하고 다양한 AI 도구로의 발전을 보여주는 예시가 된다.
AI의 잠재력에 더 깊이 들어가고자 하는 분들을 위해 제공하는 我们的教程, FLAN-T5 Tutorial: Guide and Fine-Tuning, transformers library를 사용하여 질문-답변 작업을 위해 FLAN-T5 모델의_FINE-TUNING_을 완성된 가이드를 제공하며, 실제 세계에서 최적화된 추론을 실행합니다. 또한 GPT-3.5 tutorial을 fine-tuning하고 자신의 LlaMA 2 모델 fine-tuning을 위한 코드 함께 보기도 합니다.
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial