













SOLAR-10.7Bプロジェクトは、大規模言語モデルの開発において重要な進歩を示しており、これらのモデルを効果的かつ効率的にスケールアップする新しいアプローチを導入しています。
この記事では、SOLAR-10.7Bモデルとは何かを説明した後、他の大規模言語モデルとの性能比較を行い、その特化した微調整バージョンの使用プロセスに深く掘り下げます。最後に、微調整されたSOLAR-10.7B-Instructモデルの潜在的な応用とその限界を理解します。
SOLAR-10.7Bとは何ですか?
SOLAR-10.7Bは、韓国のUpstage AIによって開発された107億パラメータを持つモデルです。
Llama-2アーキテクチャに基づいており、このモデルはMixtral 8X7Bモデルを含む最大300億パラメータの他の大規模言語モデルを凌駕しています。
Llama-2について詳しく知りたい場合は、「LLaMA 2の微調整: 大規模言語モデルをカスタマイズするためのステップバイステップガイド」が、メモリと計算の制限を克服し、オープンソースの大規模言語モデルへのアクセスを改善するための新しいアプローチを使用して、Llama-2を微調整するステップバイステップガイドを提供します。
さらに、SOLAR-10.7Bの堅固な基盤に基づいて、SOLAR 10.7B-Instructモデルは複雑な指示に従うことを重視して微調整されています。このバリアントは、モデルの適応性と特化した目的を達成するための微調整の効果を示す強化された性能を発揮します。
最終的に、SOLAR-10.7Bは「Depth Up-Scaling」と呼ばれる手法を導入し、以下のセクションでさらにそれについて説明を展开します。
Depth Up-Scaling手法
この革新的な手法は、モデルのニューロンネットワークの深さを拡張することができ、計算資源の対応的な増加を必要としません。この戦略は、モデルの効率と全体の性能を両方とも向上させます。
Depth Up-Scalingの重要要素
Depth Up-Scalingは、以下の3つの主要コンポーネントに基づいています:(1) Mistral 7Bの重み、(2) Llama 2のフレームワーク、(3) 継続的なプレトレーニング。
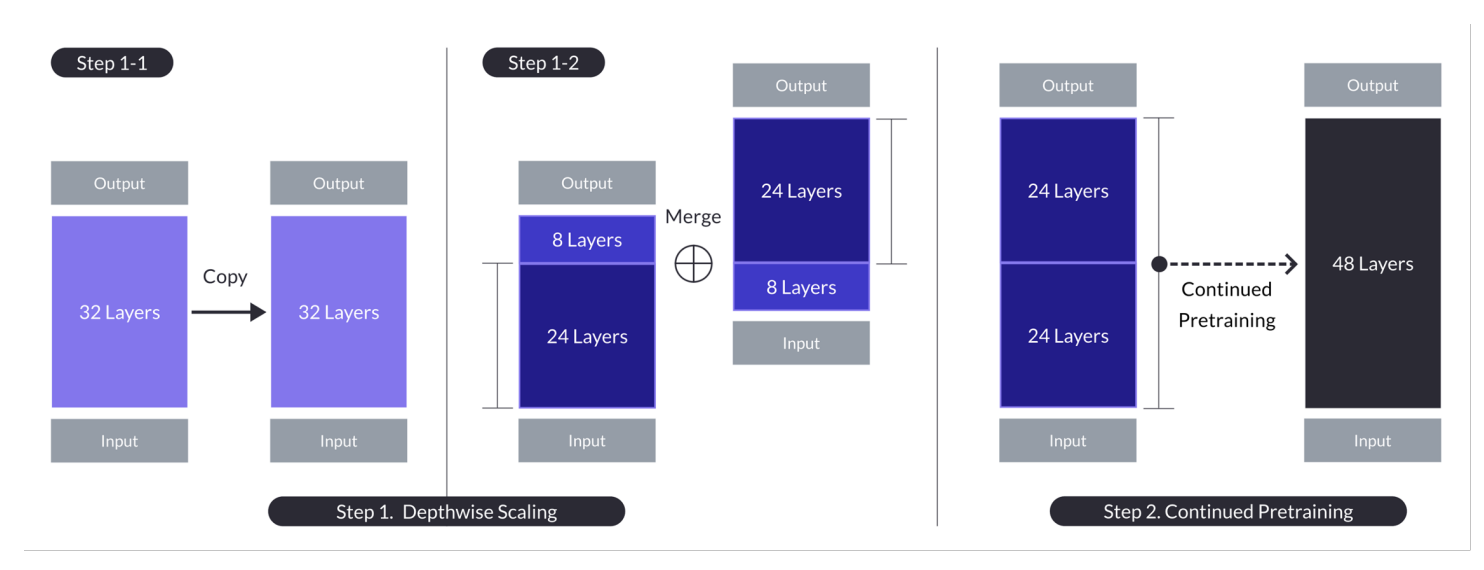
n=32、s=48、m=8のケースにおけるDepth up-scaling。Depth up-scalingは、デプスワイズスケーリングを経由した二段階のプロセスによって達成され、それに続いて継続的なプレトレーニングが行われます。(<diy8>出典
基本モデル:
- 32層のトランスフォーマерアーキテクチャを使用し、特にLlama 2モデルをMistral 7Bのプレトレーンド重みで初期化します。
- 互換性とパフォーマンスのために選択され、コミュニティの資源を活用し、新しい改変を導入して能力を強化します。
- デプスワイズスケーリングとさらなるプレトレーニングによる効率的な拡張の基盤となります。
デプスワイズスケーリング:
- 基本モデルを拡張するために、拡張モデルの目標レイヤーコウントを設定し、ハードウェアの能力を考慮します。
- 基本的モデルを複製し、元のモデルの最終m層と複製されたモデルの最初のm層を除去し、それらを結合してs層のモデルを形成する。
- このプロセスは、基数n=32層を基に、m=8層を除去してs=48層に調整された層数のスケールされたモデルを作成し、70億から130億のパラメーターを介して調整するスケールされたモデルを作成する。
继续学習:
- 深さ調整後の初期パフォーマンス低下を改善するために、スケールされたモデルを继续的に事前学習する。
- 继续学習の間、層の多様性とモデル間の不一致を减少することによって、パフォーマンスの急速な回復が観察されました。
- 继续学習は、深さ調整されたモデルのアーキテクチャを効果的な学習に利用して、基底モデルのパフォーマンスを取り戻し、および潜在的には上回すことが重要である。
これらの要約は、Depth Up-Scaling手法の主要な戦略と結果を示しており、既存のモデルを活用し、深さ調整を通じてスケールを上げ、继续学習を通じてパフォーマンスを改善することに焦点を置く。
この多面性の手法でSOLAR-10.7Bは、より大きなモデルの能力を達成し、多くの場合はそれを越えます。この効率性は、特定の应用に最適な选择であり、その強さと柔軟性を示しています。
SOLAR 10.7B指導モデルはどのように機能しますか?
SOLAR-10.7Bインストールは、複雑な命令を解釈し実行することができ、人的な命令に正確に理解し迅速に反応するシーンでは非常に価値がある。この機能は、より直感的で対話式的なAIシステムを開発するためには不可欠だ。
- SOLAR 10.7Bインストールは、元のSOLAR 10.7BモデルをQA形式での指示に従うように微調整された結果である。
- 微調整は主にオープンソースのデータセットと合成した数学QAデータセットを使用して、モデルの数学的能力を強化する。
- SOLAR 10.7Bインストールの最初のバージョンは、Mistral 7Bの重みを統合して、情報処理の効果的かつ効率的な学習能力を強化したものである。
- SOLAR 10.7Bのバックボーンは、スピードと精度を提供するLlama2アーキテクチャである。
総じて、微調整されたSOLAR-10.7Bモデルの重要性は、そのパフォーマンスの向上、適応性、そして広範囲の応用可能性にある。これは、自然言語処理と人工知能の分野を前進させる。
微調整されたSOLAR-10.7Bモデルの潜在的な応用
技術的な実装に入る前に、微調整されたSOLAR-10.7Bモデルのいくつかの潜在的な応用を探ることにしましょう。
以下は、個人化された教育と指導、顧客サポートの強化、自動化されたコンテンツ創作の例です。
- 個人化された教育と個人指導:
- 優れたカスタマーサポート: SOLAR-10.7B-Instructは、個人化された学習体験を提供することで教育分野を革新することができます。複雑な生徒の質問を理解し、適合された説明、リソース、そして練習を提供することができます。この機能は、個人の学習スタイルやニーズに合わせて適応する知的なトレーニングシステムを開発するのに理想的なツールです。生徒の関与と成果を向上させます。
- 自動化されたコンテンツ作成と要約:メディアやコンテンツ創作者にとって、SOLAR-10.7B-Instructは、新聞記事、報告書、創作書きなどの書かれたコンテンツの自動生成を可能にし、また、広範囲の文書を簡潔で理解しやすい形式に要約することができます。これは、ジャーナリスト、研究者、大量の情報を迅速に消化し報告する必要がある専門家にとって非常に貴重な働きです。
これらの例は、SOLAR-10.7B-Instructの多様性と可能性を示しており、幅広い業界にわたって効率性、アクセシビリティ、ユーザーエクスペリエンスを改善する影響を与えることができます。
SOLAR -10.7B Instructの使用方法のステップバイステップガイド
SOLAR-10.7Bモデルに関する背景情報は十分であり、手を汚す時が来ました。
この節は、SOLAR 10.7 Instruct v1.0 – GGUFモデルをステージの上から実行するためのすべての指示を提供することを目的としています。
コードは、Hugging Faceの公式文書に基づいています。主な手順は以下の通りです。
- 必要なライブラリをインストールし、インポートする。
- Hugging Faceから利用するSOLAR-10.7Bモデルを定義する。
- モデル推断を実行する。
- ユーザーの要求から結果を生成する。
ライブラリのインストール
使用される主要なライブラリはtransformersとaccelerateです。
- transformersライブラリは、前訓練されたモデルにアクセスを提供し、ここで指定したバージョンは4.35.2です。
- accelerateライブラリは、ハードウェアの詳細を深く理解することなく、さまざまなハードウェア(CPU、GPU)で machine learning モデルを実行することを簡素化するために設計されています。
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
インポートしたライブラリ
インストールが完了した後、以下の必要なライブラリをインポートします。
- torchは、计算机ビジョンやNLPなどのアプリケーションに使用される人気の開源の machine learning ライブラリであるPyTorchを表します。
- AutoModelForCausalLMは、原因的言語モデリング用の前訓練されたモデルを読み込むために使用され、AutoTokenizerは、テキストをモデルが理解できる形式(トークン化)に変換する責任があります。
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
GPU設定
使用されているモデルは、Hugging FaceからのSOLAR-10.7Bモデルのバージョン1です。
GPUリソースは、モデルの読み込みと推論プロセスを高速化するために必要です。
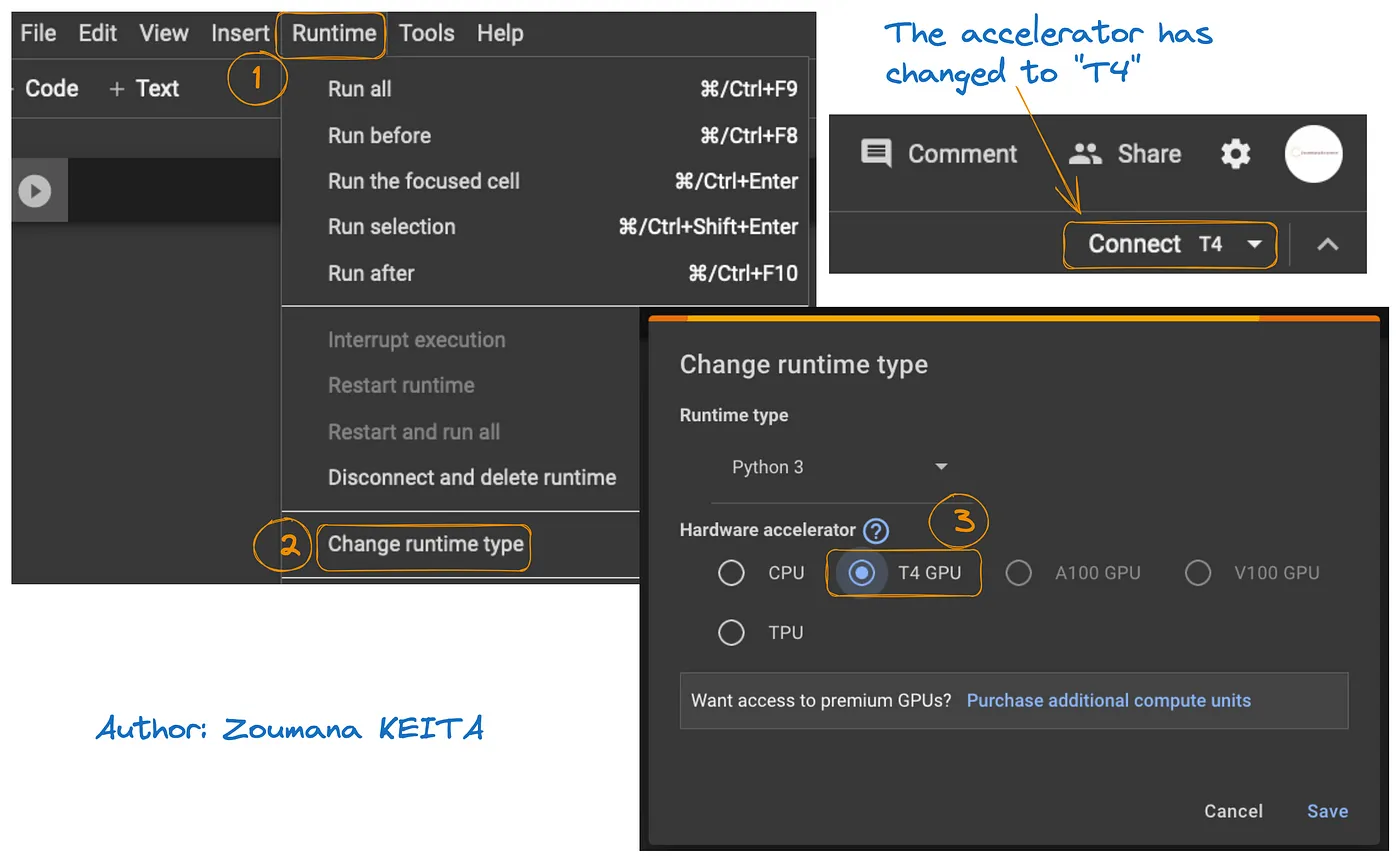
Google ColabでGPUへのアクセスは以下の図で説明します。
- 以下のRuntimeタブからChange runtimeを選択します。
- そして、T4 GPUをハードウェアアクセラレーターのセクションから選択し、Saveをクリックして変更を保存します。
これにより、デフォルトの runtimeをT4に切り替えます。
以下のコマンドをColabノートブックから実行して、 runtimeの特性を確認することができます。
!nvidia-smi
GPU properties
Model definition
設定が完了していますので、以下のようにモデルの読み込みを進めることができます。
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_IDは、使用したい事前トレーニングされたモデルを唯一識別する文字列です。この場合、“Upstage/SOLAR-10.7B-Instruct-v1.0”が指定されています。
- AutoTokenizer.from_pretrained(model_ID)は、model_IDに事前トレーニングされたトークン変換器を読み込み、テキスト入力の処理準備を行います。
- AutoModelForCausalLM.from_pretrained()は、デバイスマップを”auto”に設定して最も良い hardware (私たちが設定したGPU)を自動的に使用し、torch_dtype=torch.float16を使用して16ビットの浮動小数点数を使用してメモリを節約し、計算を可能にします。
Model inference
入力テキスト(ユーザーの要求)の整形とトークン化を行ってから、応答を生成する前にformattingとtokenizationを行います。
- user_requestは、モデルに対する質問や入力を含みます。
- conversationは、入力を会話の一部として整形し、役割(例えば「user」)をタグとして识別します。
- apply_chat_templateは、会話テンプレートを入力に適用し、モデルに理解できる形式に準備します。
- tokenizer(prompt, return_tensors=”pt”)は、プロンプトをトークンに変換し、テンサータイプ(“pt”を使用してPyTorchのテンサーを指定し)、.to(model.device)は、入力をモデルと同じデバイス(CPUまたはGPU)に持ってくることを保証します。
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
結果生成
最終のセクションで、モデルを使用して入力質問に対する応答を生成し、生成したテキストを解码して表示します。
- model.generate()は、provided inputsに基づいてテキストを生成し、use_cache=Trueを使用して以前計算された結果を再利用して生成を速め、max_length=4096を使用して生成されるテキストの最大長を制限します。
- tokenizer.decode(outputs[0])は、生成されたトークンを人間が読むことができるテキストに変換します。
- print ステートメントは、生成された質問に答える。
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
上記のコードの成功実行は、以下のような結果を生成します:

以下のテキストにuser requestを置き換えると、生成された応答を得ます。
user_request = "Tell me a story about the universe"

SOLAR-10.7Bモデルの制約
SOLAR-10.7Bには多くの利点がありますが、他の大規模な言語モデルと同様に独自の限界もあり、主なものは以下に示されています:
- ハイパーパラメータの徹底的な探索: Depth Up-Scaling (DUS)の間にモデルのハイパーパラメータをより徹底的に探索する必要が关键の限界です。これにより、ハードウェアの制限のために基本モデルから8層を削除する必要が生じました。
- 計算資源の要求:このモデルは計算資源に非常に要求が高く、これが計算能力の低い個人や組織にとって使用の限界を設定します。
- 偏向の脆弱性:トレーニングデータに潜在的な偏向があり、それは一部の使用例におけるモデルの性能に影響を与える可能性があります。
- 環境への関心:モデルのトレーニングと推論には相当なエネルギー消費が必要で、環境への関心を引き起こすことがあります。
結論
この記事では、SOLAR-10.7Bモデルを探検し、深さ方向の拡縮アプローチによる人工知能への貢献を強調しました。モデルの運作と潜在的な応用を概説し、インストールから結果生成までの使用方法に関する実践的手引きを提供しました。
その能力にもかかわらず、記事はSOLAR-10.7Bモデルの限界にも言及し、ユーザーに全面的な視点を提供しました。AIが進化し続ける中で、SOLAR-10.7Bはよりアクセスしやすく多用途のAIツールに向けた進歩を示しています。
AIの可能性をより深く探るために、私たちのチュートリアル、FLAN-T5 Tutorial: ガイドとファインチューニングでは、transformers libraryを使用して質問応答タスク用のFLAN-T5モデルのファインチューニング方法や、実際のシナリオにおける最適化された推論の実行方法についての完全なガイドが提供されています。また、GPT-3.5のファインチューニングチュートリアルと、独自のLlaMA 2モデルのファインチューニングについてのコードアロンも見つけることができます。
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial