













يمثل مشروع SOLAR-10.7B قفزة هامة في تطوير نماذج اللغات الكبيرة، وهو يقدم مقاربة جديدة لتوسيع هذه النماذج بشكل فعال وفعالي.
يبدأ هذا المقال بشرح ما هو نموذج SOLAR-10.7 B قبل أن يبرز أداءه مقارنة بالنماذج الأخرى الكبيرة اللغوية والذي يغوص في عملية استخدام نسخة متفتحة خاصة به. أخيرًا سيفهم القارئ تطبيقات نموذج SOLAR-10.7 B-Instruct المُحسَن وقيوده.
ما هو SOLAR-10.7B؟
هو نموذج بـ 10.7 بليون معامل يتطور من قبل فريق في Upstage AI في الكوريا الجنوبية.
يستند على هيكلية Llama-2، وهذا النموذج يتجاوز أخرى الكبيرة اللغوية بحوالي 30 بليون معامل بما في ذلك نموذج Mixtral 8X7B.
لمعرفة المزيد عن Llama-2، يوفر مقالتنا Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model درس خطوة بخطوة لتنقيح Llama-2 وباستخدام مقاربات جديدة لتحجيم الذاكرة والقدرة المعالجية للوصول بأفضل إلى النماذج اللغوية الكبيرة المفتوحة المصدر.
بالإضافة إلى هذا، يقوم نموذج SOLAR-10.7B-Instruct المُحسَن بتنقيحه بالأهمية الإضافية للتتبع للأوامر المعقدة. يبرز هذا النموذج الأداء المحسن، مظهر قابلية النموذج للتأقلم وفاعلية التنقيح في الحصول على الأهداف الخاصة.
بالنهاية، يقدم SOLAR-10.7B طريقة تدعى “تمديد العمق”، ودعونا نستكشف ذلك في القسم التالي.
طريقة تمديد العمق
هذه الطريقة الإبداعية تسمح للتوسعة في عمق شبكة العصب العمودية للنموذج بدون حاجة إلى زيادة متطلبات المعالجة المتعلقة به. هذه الاستراتيجية تحسين الكفاءة والفاعلية العامة للنموذج.
عناصر أساسية لتمديد العمق
تعمل تمديد العمق على ثلاثة مكونات رئيسية: (1) وزنة Mistral 7B، (2) قالب Llama 2، و (3) التدريب المستمر السلسلي.
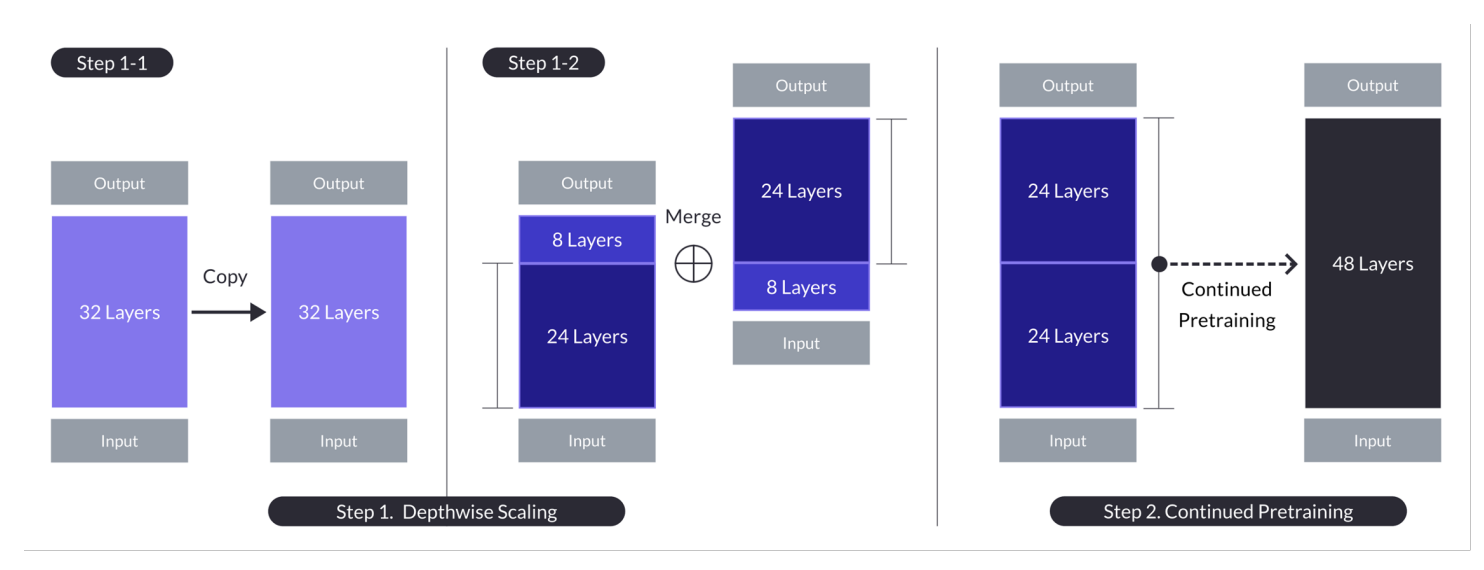
تمديد العمق لحالة ن = 32، s = 48، و m = 8. يحقق التمديد العمق من خلال عملية مزدوجة من التمديد العمودي ومواصلة التدريب السلسلي. (مصدر)
النموذج الأساسي:
- يستخدم هيكل تحويل 32-طبق ، بالتحديد نموذج Llama 2 الذي يبدأ بوزنات مسبق التدريب من Mistral 7B.
- يختار لتوافره وأداءه من التوافر والأداء، وهو يحاول استخدام موارد المجموعة والمدخلات الجديدة للقدرات المستمرة.
- يشكل الأساس للتمديد العمودي والتدريب السلسلي المستمر للتوسعة بالكفاءة.
تمديد العمودي:
- يقوم بتمديد النموذج الأساسي بتحديد عدد الطبقات الهدفي للنموذج المتمدد، باعتبار قدرات ال hardware.
- تتضمن العملية الكرتونية النموذج الأساسي، إزالة الطبقات النهائية m من الأصل والطبقات الأولية m من النموذج المكرر، ومن ثم الصافحة لإنشاء نموذج بـ s طبقات.
- هذه العملية تخلق نموذج مقاس مع عدد منغمس من الطبقات لتناسب ما بين 7 و 13 بليون خاصية، بالتحديد باستخدام أساس n=32 طبقة، إزالة m=8 طبقات لتحقيق s=48 طبقة.
التدريب المستمر:
- يعالج الانخفاض الأولي في الأداء بعد تدرج العمق بمواصلة تدريب النموذج المقاس.
- شهدنا استرداد سريع للأداء أثناء التدريب المستمر، والذي تم إيجازه إلى الحد من التنوع والاختلافات في النموذج.
- التدريب المستمر لا يزال حاسماً لإستعادة وربما تفوق أداء النموذج الأساسي، باستخدام هيكلية النموذج المقاس من حيث العمق للتعلم الفعال.
تبرز هذه الملخصات الاستراتيجيات الرئيسية والنتائج لمنهجية التدرج العمقي، بالتركيز على استفادة من النموذجات الحالية، والتدرج من خلال تعديل العمق، وتعزيز الأداء من خلال التدريب المستمر.
هذه الطريقة المتعددة الوجهات SOLAR-10.7B تحقق وفي كثير من الحالات تتعدى قدرات النموذجات الأكبر بكثير. هذه الكفاءة تجعلها الخيار الأمثل لعدد من التطبيقات الحساسة، مظهراً قوتها ومرونتها.
كيف يعمل نموذج التوجيه SOLAR 10.7B؟
SOLAR-10.7B يمكنه التوجيه والتنفيذ المتقدم في ترجمة وتنفيذ تعلمات معقدة ، مما يجعله قيمة جداً في محتويات التي يتطلب فيها فهم دقيق وتوجيه لأوامر البشر. هذه القدرة ضرورية لتطوير أنظمة AI أكثر تعقيدًا وتفاعلية.
- SOLAR 10.7B ينجز عندما يتم موذجه الأول للتنقيح من النموذج الأصلي SOLAR 10.7B ليتبع الأوامر بالصيغة QA.
- تقوم التنقيح في الغالب باستخدام أحسن البيانات المفتوحة المصدر وباستناد البيانات المحاسبية المصنعة لتعزيز مهارات النموذج الرياضية.
- أول نسخة لSOLAR 10.7B تم إنشاؤها عن طريق تكامل وزنات Mistral 7B لتعزيز قدراتها التعلمية للتعامل بالمعلومات بكفاءة وفعالية.
- أساس SOLAR 10.7B هو الهيكل Llama2 الذي يوفر خلاله مزيجًا من السرعة والدقة.
وبشكل عام يتميز النموذج SOLAR-10.7B منتج التنقيح بأهمية أفضل بإظهار أداء متقدم وقدرة تكيف وإمكانية عمودية للتطبيق، مما يقود قطاعاً من مجالات التحليل اللغوي والذكاء الصناعي.
التطبيقات المحتملة لنموذج SOLAR-10.7B المنتج من التنقيح
قبل الانخراط في تطبيقات التقنية ، دعونا نبحث عن بعض أحدث التطبيقات لنموذج SOLAR-10.7B المنتج من التنقيح.
مثالًا على تعليم الشخصية والدراسة الشخصية مرئية والدعم المتميز للزبائن وإنشاء المحتويات الautomated.
- تعليم شخصي وتدريس تخصصي: SOLAR-10.7B-Instruct يستطيع أن يغير القطاع التعليمي بشكل كبير من خلال توفير تجارب تعلمية شخصية. يستطيع فهم الاستفسارات المعقدة للطلاب، مقدماً تفسيرات ومصادر وتمارين مخصصة. هذه القدرة تجعله يكون أداة مثالية لتطوير أنظمة التدريس الذكية التي تتكيف مع أساليب التعلم واحتياجات الفرد، مما يعزز الانخراط الطالبي والنتائج.
- دعم مستخدمين أفضل: SOLAR-10.7B-Instruct يستطيع تزويد البوتات الحديثة والمساعدي الافتراضيين المستويين بإستطاعة فهم وحل الاستفسارات المعقدة للعملاء بدقة عالية. هذا التطبيق ليس فقط يحسن تجربة العميل بتوفير دعم موسع ومناسب للوقت ولكنه أيضًا يخفض عن بئرة ممثلي الخدمة البشريين من خلال تلقائيّة الاستفسارات الروتينية.
- إنشاء وملخص تلقائي للمحتوى: لصناع الإعلام وخرّغي المحتوى، SOLAR-10.7B-Instruct يقدم القدرة على تلقائيّة إنشاء المحتوى الكتابي، مثل المقالات الصحفية والتقارير والكتابة الإبداعية. بالإضافة إلى ذلك، يستطيع تلخيص الوثائق الطويلة إلى أشكال موجزة وسهلة التفهم، مما يجعله ذا قيمة للصحفيين والباحثين والمهنيين الذين يحتاجون إلى تعجيم وتقديم معلومات كبيرة الحجم بسرعة.
هذه الأمثلة تبرز التنوع والإمكانيات المتمثلة في SOLAR-10.7B-Instruct لتأثيره وتحسين الكفاءة والمتاحية وتجربة المستخدم عبر مجموعة واسعة من القطاعات.
دليل خطوة بخطوة لاستخدام SOLAR -10.7B Instruct
لقد حصلنا على ما يكفي من المعرفة الخلفية حول نموذج SOLAR-10.7B وحان الوقت لإبداع أعمالنا.
هذا القسم يهدف إلى توفير جميع التعليمات لتشغيل نموذج SOLAR 10.7 Instruct v1.0 – GGUF من خلال المسرح.
تلك الأوامر تلهم من التوثيق الرسميعلى Hugging Face. تعريف الخطوات الرئيسية من أدناه:
- تثبيت واستيراد المكتبات المطلوبة
- تعريف نموذج SOLAR-10.7B الذي يتم استخدامه من Hugging Face
- تشغيل تحليل النموذج
- توليد النتائج من طلب المستخدمين
تثبيت المكتبات
المكتبات الرئيسية التي يتم استخدامها هي transformers و accelerate.
- مكتبة transformers توفر وصول إلى النماذج المتمولة مسبقاً، والإصدار المحدد هنا هو 4.35.2.
- مكتبة accelerate تهدف إلى تبسيط تشغيل نماذج المعرفة المتقدمة على أجهزة مختلفة (الCPUs والGPUs) بدون حاجة إلى فهم جديد لتفاصيل الأجهزة.
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
import المكتبات
حالما تم التثبيت، سنقوم بتجهيز توفير المكتبات التالية المطلوبة:
- torch هي مكتبة PyTorch، مكتبة المعرفة المتقدمة المفتوحة المصدرة المستخدمة لتطبيقات مثل الرؤية الحاسوبية والنصوص المتقدمة.
- AutoModelForCausalLM يستخدم لتحميل نموذج مسبقاً موجود للمحاكاة اللغوي السلكي، ويشغل AutoTokenizer مسؤولية تحويل النص إلى تشكيل يمكن الفهم بواسطة النموذج (توكيز).
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
Configure الGPU
يتم استخدام نسخة 1 من نموذج SOLAR-10.7B من Hugging Face.
يحتاج المصادر الGPU لتسريع عملية تحميل النموذج وعملية التخمين.
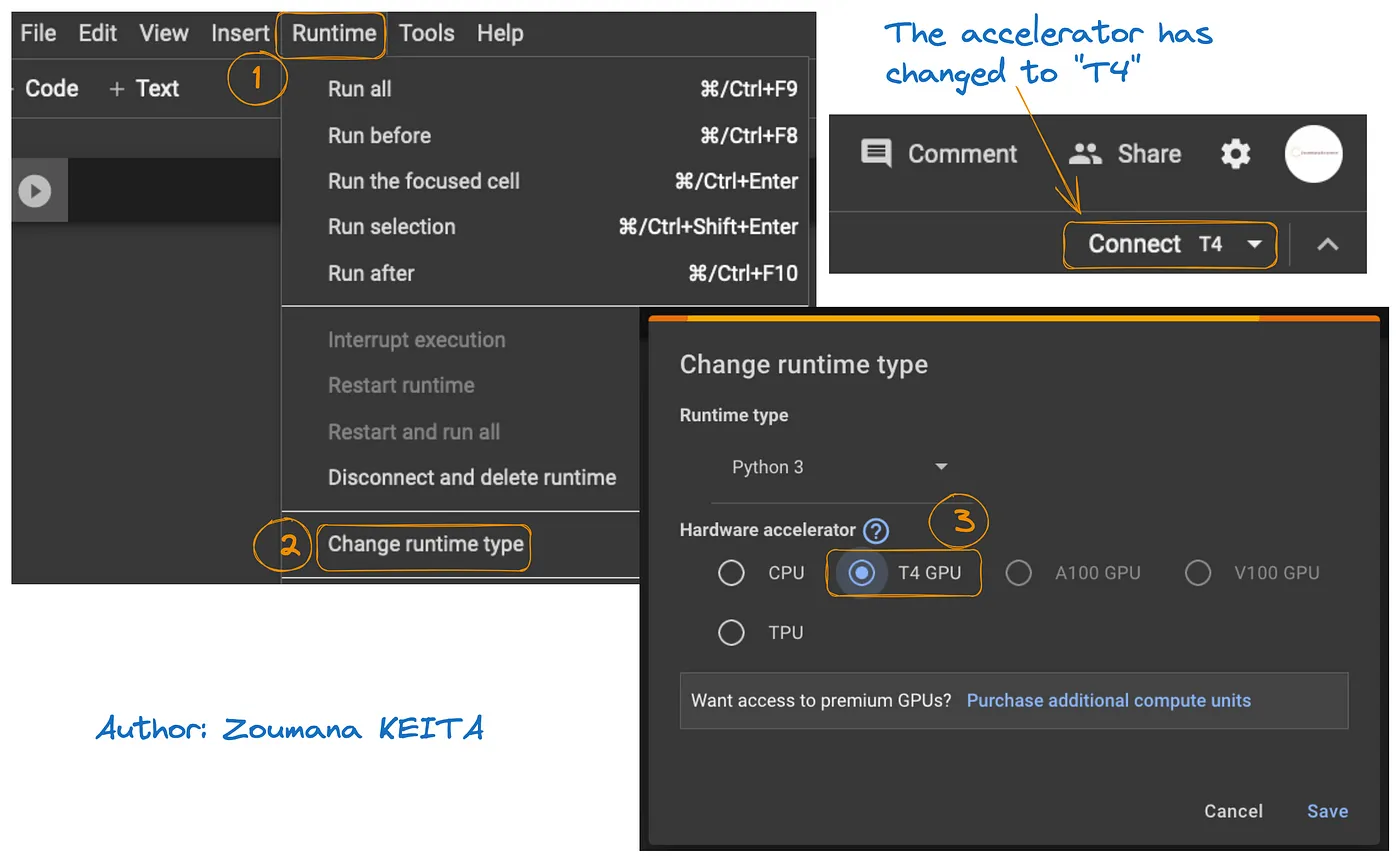
يوضح الوصول إلى المصادر الGPU في Google Colab في الرسم البياني الموجود أسفل:
- من لوحة التشغيل Runtime، حدد Change runtime
- ثم، اختر T4 GPU من قسم محركات ال hardware و Save التغييرات
سيتغير التشغيل الافتراضي الاولي إلى T4:
يمكننا تفقد خصائص التشغيل بتنفيذ أوامر المرور التالية من الدفتر الرسمي للColab.
!nvidia-smi
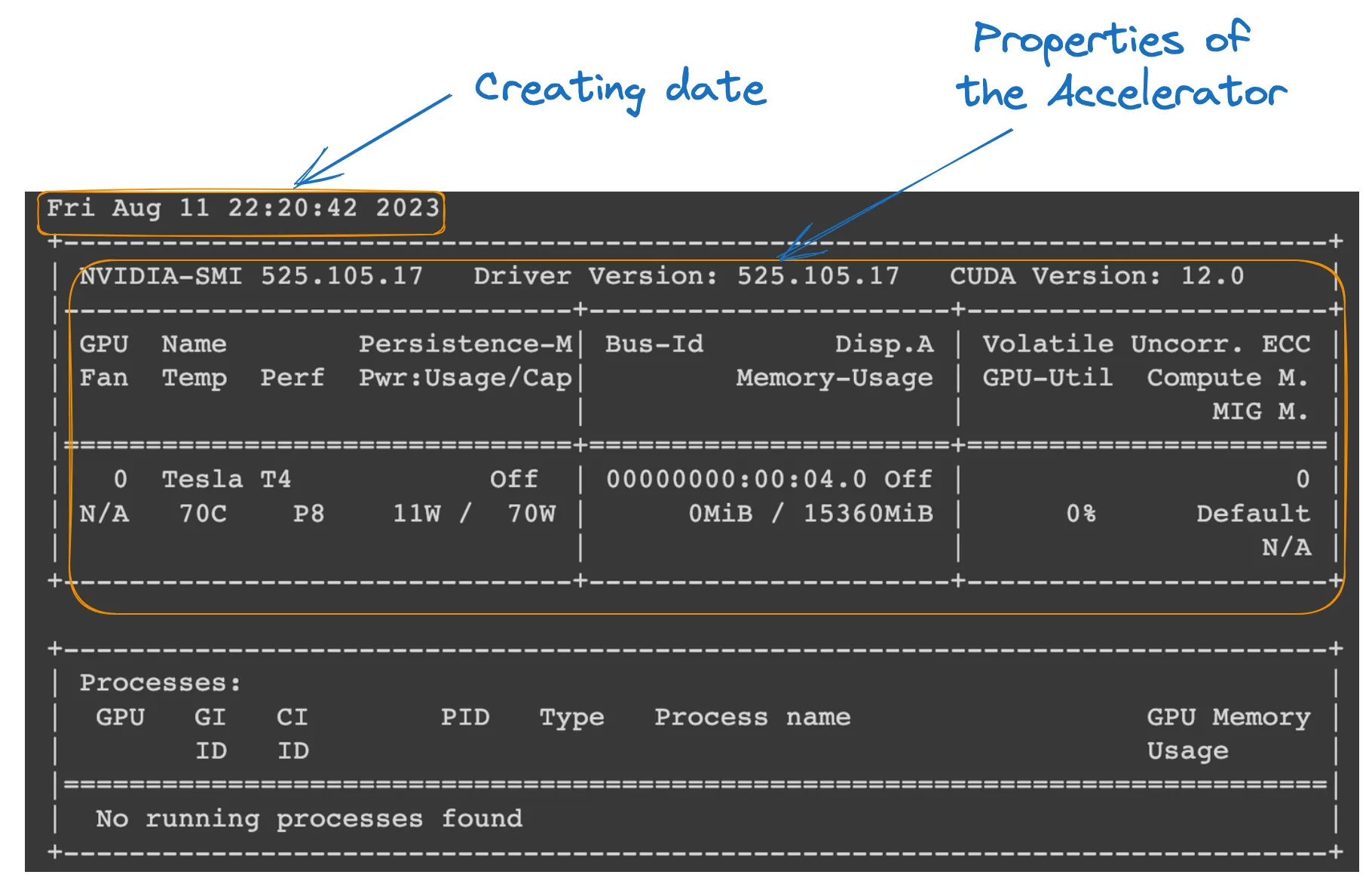
GPU properties
تعريف النموذج
كل شيء موجه؛ يمكننا المتابعة بتحميل النموذج كما يلي:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID هو سلسلة تحديدية للنموذج المسبق التدريبي الذي نريد استخدامه. في هذه الحالة، يتم تحديد “Upstage/SOLAR-10.7B-Instruct-v1.0” .
- AutoTokenizer.from_pretrained(model_ID) يحمل معا التوكيزر المسبق التدريبي على model_ID المحدد، من ثم يتجه لمعالجة إدخال النصوص.
- AutoModelForCausalLM.from_pretrained() يحمل نموذج اللغة التسببي نفسه مع device_map=”auto” لإستخدام المعدات الأفضل المتاحة (الGPU التي قمنا بإعداده)، و torch_dtype=torch.float16 للاستخدام من أرقام النسبة العشرين لتوفير الذاكرة وتسريع ممكن الحوسبة.
التخمين النموذجي
قبل إنشاء رد يتم تشكيل وتو
- user_request يحتوي على السؤال أو المدخل للنموذج.
- conversation ينسق المدخل كجزء من محادثة، ويضع له علامة دور (مثل ‘user’).
- apply_chat_template يطبق قالب محادثة على المدخل، ويجهزه للنموذج بتنسيق يفهمه.
- tokenizer(prompt, return_tensors=”pt”) يحول المدخل إلى رموز ويحدد نوع التنسور (“pt” لتنسورات PyTorch)، و .to(model.device) يضمن أن المدخل على نفس الجهاز (CPU أو GPU) مثل النموذج.
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
توليد النتيجة
القسم النهائي يستخدم النموذج لتوليد استجابة للسؤال المدخل ثم يفك الشفرة ويطبع النص المولد.
- model.generate() يولد نصًا بناءً على المدخلات المقدمة، مع use_cache=True لتسريع التوليد بإعادة استخدام النتائج المحسوبة مسبقًا. max_length=4096 يحدد الحد الأقصى لطول النص المولد.
- tokenizer.decode(outputs[0]) يحول الرموز المولدة إلى نص يمكن قراءته.
- print يعرض البيان الإجابة المولدة على سؤال المستخدم.
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
التنفيذ الناجح للكود أعلاه يولد النتيجة التالية:

عن طريق استبدال طلب المستخدم بالنص التالي، نحصل على الاستجابة المولدة
user_request = "Tell me a story about the universe"

القيود الخاصة بنموذج SOLAR-10.7B
على الرغم من جميع مزايا الـ SOLAR-10.7B، له قيوده الخاصة مثل أي نموذج كبير لللغة الآخر، والأكبر منها توضح الأدنى:
- الاستكشاف الفائق للخصائص الرئيسية: حاجة إلى استكشاف أكثر عمق لخصائص النموذج خلال التكبير العمودي (DUS) هو حد القيود الرئيسي. هذا أدى إلى إزالة 8 طبقات من النموذج الأساسي بسبب قيود ال hardware.
- المتطلبات الحاسوبية الكبيرة: تتطلب النموذج موارد الحاسوب الكبيرة بشكل كبير، وهذا يحدد استخدامه من قبل الأشخاص والمنظمات ذات القدرات الحاسوبية المنخفضة.
- الضعف بجه التحيز: قد يؤثر توافر التحيز في البيانات التي يتم تدريبها على النموذج في بعض الأحوال التي قد تؤثر على أداء النموذج في بعض الأسباب التطبيقية.
- القلق بشأن البيئة: تتطلب التدريب والتحكم في النموذج تأسيس مصادر طاقة كبيرة، وهذا قد يزيد القلق حول البيئة.
الخلاصة
قد استكشفت هذه المقالة النموذج SOLAR-10.7B، وأبرزت مساهمته في الذكاء الصناعي من خلال مقاربة التكبير العمودي. ووضعت تشريح عمل النموذج والتطبيقات المحتملة له، وقدمت دراسة عملية لاستخدامه، من التثبيت إلى توليد النتائج.
وعلى الرغم من قدراته، قد توجهت المقالة أيضًا إلى قيود النموذج SOLAR-10.7B، لضمان وجهة نظر شاملة للمستخدمين. وكما تتطور الت
تحتاج الآن للتعمق أكثر في إمكانيات الذكاء الاصطناعي؟ الدرس التوجيهي الخاص بنا، درس FLAN-T5: الدليل والتحسين التفضيلي، يقدم دليل كامل لتحسين تفضيلي نموذج FLAN-T5 لمهمة إجابة الأسئلة باستخدام مكتبة transformers وتشغيل تحليل تخمين محسن لمشهد حقيقي. يمكنك أيضًا العثور على درس تحسين GPT-3.5 وبرنامجنا التواجدي مع تحسين نموذج LlaMA 2 الخاص بك.
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial