













Het SOLAR-10.7B-project vertegenwoordigt een significante sprong voorwaarts in de ontwikkeling van grote taalmodellen, door een nieuwe benadering te introduceren om deze modellen op een effectieve en efficiënte manier op te schalen.
Dit artikel begint met een uitleg over wat het SOLAR-10.7B-model is, benadrukt vervolgens de prestaties ten opzichte van andere grote taalmodellen en duikt in het proces van het gebruik van de gespecialiseerde fijn-afgestemde versie. Tot slot begrijpt de lezer de potentiële toepassingen van het fijn-afgestemde SOLAR-10.7B-Instruct-model en de beperkingen ervan.
Wat is SOLAR-10.7B?
SOLAR-10.7B is een model met 10,7 miljard parameters, ontwikkeld door een team bij Upstage AI in Zuid-Korea.
Gebaseerd op de Llama-2-architectuur overtreft dit model andere grote taalmodellen met tot wel 30 miljard parameters, inclusief het Mixtral 8X7B-model.
Om meer te leren over Llama-2, biedt ons artikel Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model een stapsgewijze handleiding voor het fijn afstemmen van Llama-2, met nieuwe benaderingen om geheugen- en rekenbeperkingen te overwinnen voor betere toegang tot open-source grote taalmodellen.
Bovendien, voortbouwend op de robuuste basis van SOLAR-10.7B, is het SOLAR 10.7B-Instruct-model fijn afgestemd met de nadruk op het volgen van complexe instructies. Deze variant toont verbeterde prestaties, wat de aanpasbaarheid van het model en de effectiviteit van fijn afstemming in het bereiken van gespecialiseerde doelen aantoont.
In dit deel introduceert SOLAR-10.7B een methode genaamd Depth Up-Scaling, en laten we die verder onderzoeken in het volgende gedeelte.
De Depth Up-Scaling methode
Deze innovatieve methode maakt het mogelijk om de diepte van de neurale netwerk van het model uit te breiden zonder dat er een overeenkomstige toename is in computatieve middelen. Zo’n strategie verbetert zowel de efficiency als de algehele prestaties van het model.
Belangrijke elementen van Depth Up-Scaling
Depth Up-Scaling is gebaseerd op drie belangrijke componenten: (1) Mistral 7B gewicht, (2) Llama 2 framework, en (3) Continu pre-trainen.
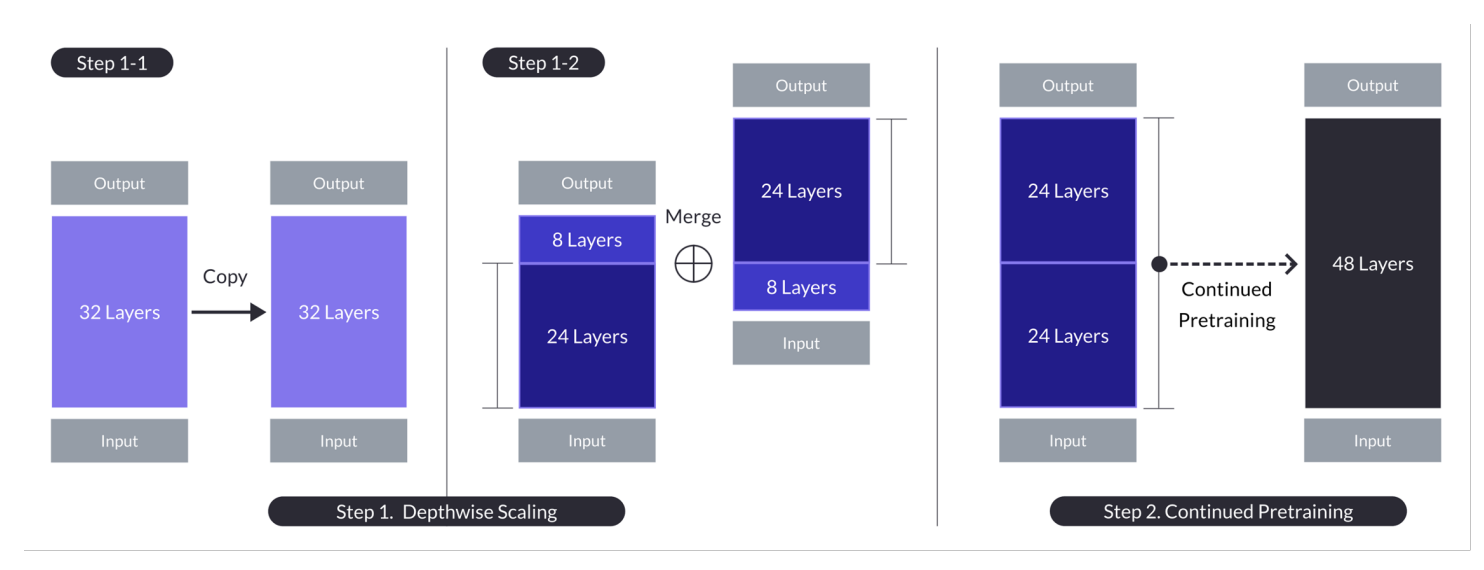
Depth up-scaling voor het geval met n = 32, s = 48, en m = 8. Depth up-scaling wordt bereikt door een dubbele fase van depthwise scaling gevolgd door voortgezet pretraining. (Bron)
Basismodel:
- Gebruikt een 32-lagen transformatie-architectuur, specifiek het Llama 2 model, geïnitialiseerd met pre-getrainde gewichten van Mistral 7B.
- Gekozen vanwege zijn compatibiliteit en prestaties, met als doel gemeenschapsbronnen te gebruiken en nieuwe modificaties te introduceren voor verbeterde mogelijkheden.
- Dient als basis voor depthwise scaling en verdere pretraining om efficient op schaal te gaan.
Depthwise Scaling:
- Stelt het basismodel in op een doel aantal lagen voor het geschaalde model, waarbij rekening wordt gehouden met de hardwaremogelijkheden.
- Het betreft het kopiëren van de basismodel, het verwijderen van de laatste m lagen van het originele en de eerste m lagen van de kopie, en daarna deze samenvoegen om een model met s lagen te vormen.
- Dit proces creëert een schaalbaar model met een aangepaste aantal lagen tussen de 7 en 13 miljard parameter, specifiek door een basis van n=32 lagen te gebruiken, m=8 lagen te verwijderen om s=48 lagen te behalen.
Verdere voorbereiding:
- Dit adresseert de aanvankelijke prestatie daling na de diepte-scaling door verder voor te trainen het gescaleerde model.
- Tijdens de verdere voorbereiding is een snelle prestatie herstel geconstateerd, wat toegeschreven is aan het verminderen van de heterogeeniteit en discrepanties in het model.
- Verdere voorbereiding is crucial voor het herstellen en zelfs overschrijden van de prestaties van het basismodel, door de architectuur van het diepte-gescaleerde model voor effectief leren in te zetten.
Deze samenvattingen laten de sleutelstrategieën en resultaten van de Depth Up-Scaling-methode zien, met focus op het gebruik van bestaande modellen, de schaalbaarheid door diepte-aanpassing en het verbeteren van prestaties door verdere voorbereiding.
Deze multifacette aanpak van SOLAR-10.7B bereikt en, in veel gevallen, overschrijdt de mogelijkheden van veel grotere modellen. Deze efficiëntie maakt het een prima keuze voor een reeks specifieke toepassingen, die haar kracht en flexibiliteit tonen.
Hoe werkt de SOLAR 10.7B instructie-model?
ZON-10.7B instruct is uitstekend in het interpreteren en uitvoeren van complexe instructies, waardoor het uiterst waardevol is in situaties waarin een precieze begrip en reaktie op menselijke commando’s essentieel zijn. Deze capaciteit is essentieel voor het ontwikkelen van meer intuïtieve en interactieve AI-systemen.
- ZON 10.7B instruct resulteert van het fijnafstemmen van de originele ZON 10.7B-model om instructies in QA-formaat te volgen.
- Het fijnafstemmen maakt voornamelijk gebruik van openbron-datasets samen met gesynteeseerde wiskunde QA-datasets om de wiskundige vaardigheden van het model te verbeteren.
- De eerste versie van de ZON 10.7B instruct wordt gemaakt door de Mistral 7B-weights te integreren om zijn leercapaciteiten voor effectieve en efficiente informatieverwerking te versterken.
- De backbone van de ZON 10.7B is de Llama2-architectuur, die een mix van snelheid en nauwkeurigheid biedt.
Algemeen blijft de belangrijkste waarde van het gefinetunede ZON-10.7B-model liggen in zijn verbeterde prestaties, aanpasbaarheid en potentieel voor brede toepassing, die de velden van natuurlijke taalverwerking en kunstmatige intelligentie vooruit duwen.
Potentiele toepassingen van het gefinetunede ZON-10.7B-model
Voordat we in de technische implementatie duiken, laten we eerst enkele potentiële toepassingen van een gefinetunede ZON-10.7B-model bekijken.
Hieronder staan enkele voorbeelden van gepersonaliseerde educatie en tutoring, verbeterde klantenservice en geautomatiseerde contentcreatie.
- Gepersonaliseerde onderwijs en begeleiding: SOLAR-10.7B-Instruct kan de onderwijssector revolutionair maken door het aanbieden van gepersonaliseerde leerervaringen. Het kan complexe studentenvragen begrijpen en biedt aangepaste verklaringen, bronnen en oefeningen. Deze mogelijkheid maakt het een ideale tool voor het ontwikkelen van intelligentes begeleidingssystemen die aanpassen aan individuele leerstijlen en behoeften, waardoor studenten beter gemotiveerd en betere resultaten behalen.
- Beter klantondersteuning: SOLAR-10.7B-Instruct kan geavanceerde chatbots en virtuele assistenten aanzetten die in staat zijn complexe klantvragen met hoge nauwkeurigheid te begrijpen en op te lossen. Deze toepassing verbeterd niet alleen de klantervaring door tijdige en relevante ondersteuning te bieden, maar helpt ook de takenlast op de menselijke klantenservicevertegenwoordigers te verminderen door routinevragen automatisch op te lossen.
- Geautomatiseerde contentproductie en samenvatting: Voor media- en contentcreators biedt SOLAR-10.7B-Instruct de mogelijkheid om de productie van schriftelijke content zoals nieuwsartikelen, rapporten en creatief schrijven automatisch te maken. Bovendien kan het uitgebreide documenten samenvatten in korte, gemakkelijk te begrijpen formaten, waardoor het onontbeerlijk is voor journalisten, onderzoekers en professionals die snel informatie moeten assimileren en rapporteren over grote hoeveelheden informatie.
Deze voorbeelden onderstrepen de versatiliteit en potentie van SOLAR-10.7B-Instruct om impact en efficiëntie, toegankelijkheid en gebruikerservaring te verbeteren over een breed scala van industriën.
Een stap-voor-stap gids voor het gebruik van SOLAR-10.7B Instruct
We hebben genoeg achtergrondinformatie over het SOLAR-10.7B-model en het is nu tijd om onze handen vuil te maken.
Deze sectie biedt alle instructies om het SOLAR 10.7 Instruct v1.0 – GGUF-model vanuit upstage uit te voeren.
De codes zijn geïnspireerd door de officiële documentatie op Hugging Face. De belangrijkste stappen zijn hieronder gedefinieerd:
- Installeer en importeer de noodzakelijke bibliotheken
- Definieer het SOLAR-10.7B-model dat gebruikt moet worden vanaf Hugging Face
- Voer modelinferenties uit
- Genereer het resultaat uit het verzoek van de gebruiker
Installatie van Bibliotheken
De voornaamste bibliotheken die gebruikt worden zijn transformers en accelerate.
- De transformers-bibliotheek biedt toegang tot voorgeïnstalleerde modellen, en de hier gespecificeerde versie is 4.35.2.
- De accelerate-bibliotheek is ontworpen om het uitvoeren van machine learning-modellen op verschillende hardware (CPU’s, GPU’s) te vereenvoudigen zonder diepgaande kennis van de hardware specifics nodig te hebben.
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
Importeer Bibliotheken
Nu de installatie voltooid is, gaan we verder door de volgende noodzakelijke bibliotheken te importeren:
- torch is de PyTorch-bibliotheek, een populaire open-source machine learning-bibliotheek die gebruikt wordt voor toepassingen zoals computervision en NLP.
- AutoModelForCausalLM wordt gebruikt om een voorgeïnstalleerd model voor causal language modeling te laden, en AutoTokenizer is verantwoordelijk voor het converteren van tekst naar een formaat dat het model kan begrijpen (tokenization).
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
GPU-configuratie
De gebruikte versie is versie 1 van het SOLAR-10.7B-model van Hugging Face.
Een GPU-resource is nodig om het laden van het model en het inferentieschema te versnellen.
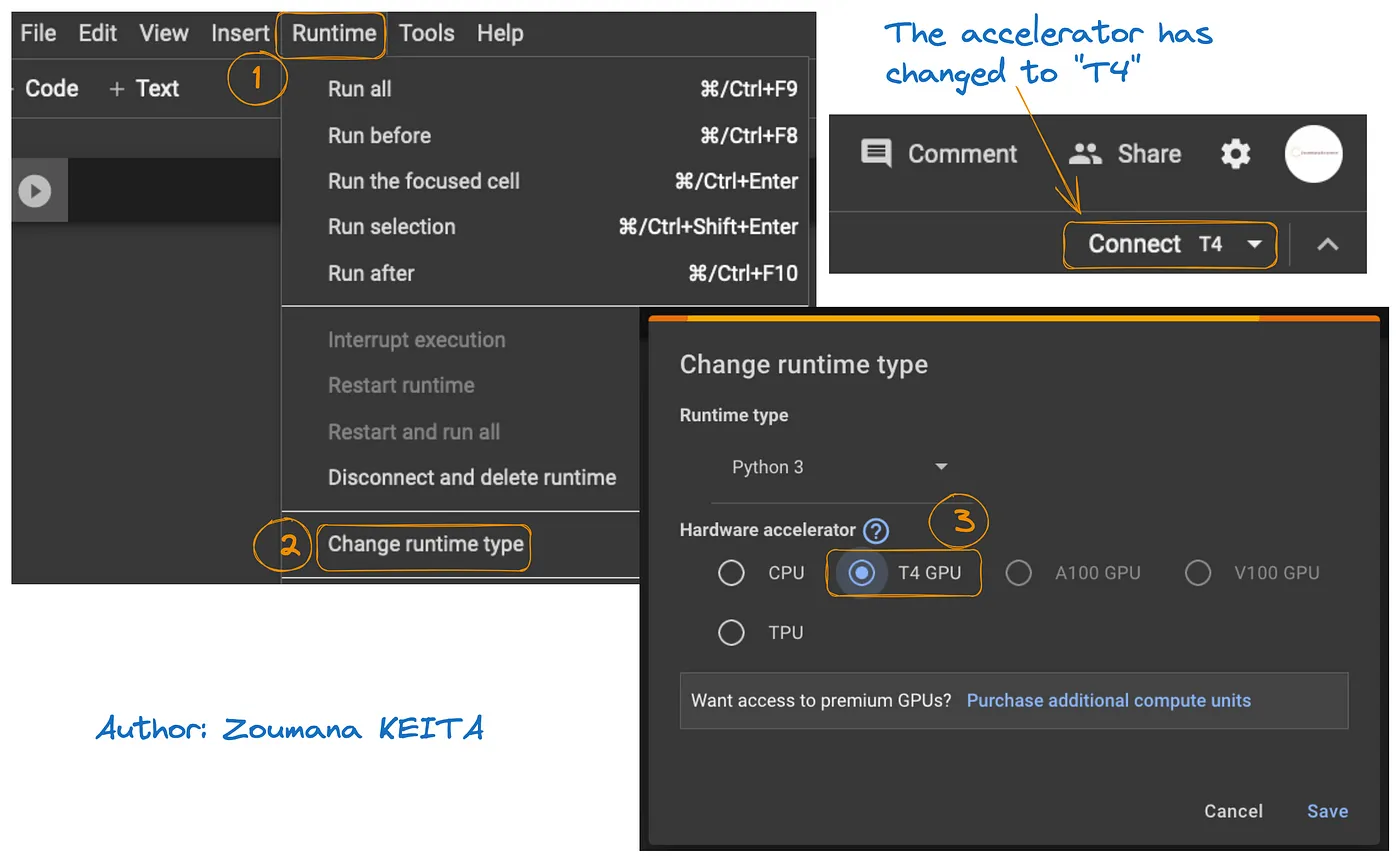
De toegang tot GPU op Google Colab wordt geïllustreerd in de onderstaande grafiek:
- Vanaf het tabblad Runtime, selecteer Runtime wijzigen
- Vervolgens kies je T4 GPU uit de sectie Hardwareversneller en Opslaan van de wijzigingen
Dit zal de standaard runtime wijzigen naar T4:
We kunnen de eigenschappen van de runtime controleren door het volgende commando uit te voeren in het Colab notebook.
!nvidia-smi
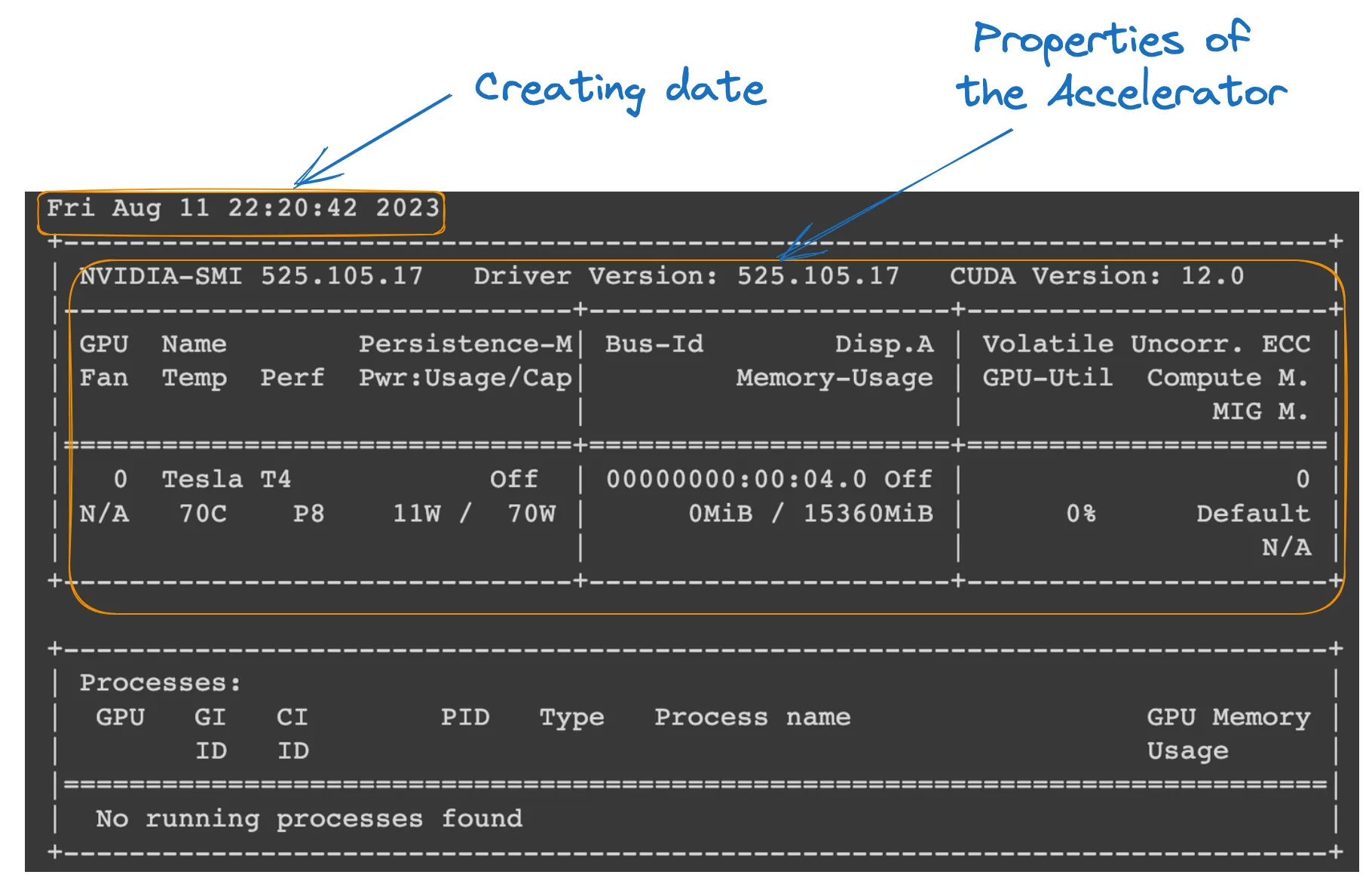
GPU eigenschappen
Modeldefinitie
Alles is ingesteld; we kunnen verder gaan met het laden van het model als volgt:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID is een tekenreeks die het pre-getrainde model uniek identificeert dat we willen gebruiken. In dit geval is “Upstage/SOLAR-10.7B-Instruct-v1.0” gespecificeerd.
- AutoTokenizer.from_pretrained(model_ID) laadt een tokenizer die pre-getraind is op de gespecificeerde model_ID, klaar voor het verwerken van tekstinvoer.
- AutoModelForCausalLM.from_pretrained() laadt het causale taalmodel zelf, met device_map=”auto” om automatisch het beste beschikbare hardware (de GPU die we hebben ingesteld) te gebruiken, en torch_dtype=torch.float16 voor het gebruik van 16-bits drijvende komma-getallen om geheugen te besparen en mogelijk de berekeningen te versnellen.
Modelinferentie
Voordat een antwoord gegenereerd wordt, wordt het invoertext (het verzoek van de gebruiker) geformatteerd en getokeniseerd.
- user_request bevat de vraag of invoer voor het model.
- conversation formateert de invoer als onderdeel van een conversatie, waarbij het wordt getagd met een rol (bijv., ‘user’).
- apply_chat_template past een conversatiesjabloon toe op de invoer, waarbij het voorbereidt in een formaat dat het model begrijpt.
- tokenizer(prompt, return_tensors=”pt”) converteert de prompt naar tokens en specificeert het tensor type (“pt” voor PyTorch-tensors), en .to(model.device) zorgt ervoor dat de invoer op dezelfde apparatuur (CPU of GPU) staat als het model.
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
Resultaatgeneratie
De laatste sectie gebruikt het model om een antwoord op de invoervraag te genereren en decodeert vervolgens het gegenereerde tekst.
- model.generate() genereert tekst op basis van de gegeven invoeren, met use_cache=True om de generatie te versnellen door eerder berekende resultaten te hergebruiken. max_length=4096 limiteert de maximale lengte van de gegenereerde tekst.
- tokenizer.decode(outputs[0]) converteert de gegenereerde tokens terug naar leesbare tekst.
- print statement toont het gegenereerde antwoord op de vraag van de gebruiker.
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
De succesvolle uitvoering van de bovenstaande code genereert het volgende resultaat:

Door de gebruikersaanvraag te vervangen door de volgende tekst, krijgen we de gegenereerde respons
user_request = "Tell me a story about the universe"

Beperkingen van het SOLAR-10.7B model
Ondanks alle voordelen van de SOLAR-10.7B heeft deze net als elke andere grote taalmodel zijn eigen beperkingen, en de belangrijkste worden hieronder gemarkeerd:
- Duurslaaf hyperparameteronderzoek: de behoefte aan een dieper onderzoek van de hyperparameters van het model tijdens de diepte-opwaardering (DUS) is een belangrijke beperking. Dit heeft tot gevolg dat 8 lagen zijn verwijderd uit de basismodel vanwege hardwarebeperkingen.
- Kostbare computationeleisen: het model vereist significante computationele resources, wat zijn gebruik beperkt tot individuen en organisaties met lagere computationele mogelijkheden.
- Verschillende voorkeur voor bias: potentiële bias in de trainingsdata zou de prestaties van het model kunnen beïnvloeden voor sommige toepassingen.
- Milieu- en energiebescherming: de training en inference van het model vereisen significante energieconsumptie, wat milieu- en energiebeschermingsproblemen kan veroorzaken.
Conclusie
Dit artikel heeft de SOLAR-10.7B-model uitgebreid onderzocht en de bijdrage van het model aan de kunstmatige intelligentie door middel van de diepte-opwaardering benaderd. Het heeft de werking en potentiële toepassingen van het model beschreven en een praktische handleiding voor zijn gebruik geleverd, van installatie tot het genereren van resultaten.
Ondanks zijn capaciteiten heeft het artikel ook de beperkingen van het SOLAR-10.7B-model aangepakt, om een rondzien perspectief voor gebruikers te verzekeren. Aangezien AI doorgaat evolueren, is SOLAR-10.7B een voorbeeld van de vooruitgang die is gemaakt naar meer toegankelijke en verschillende AI-hulpmiddelen.
Voor hen die dieper willen delven in de mogelijkheden van AI, biedt ons handleiding FLAN-T5 Handleiding: Gids en Fijnafstemming een volledige gids aan om een FLAN-T5 model voor een vraagbeheersings taak te fijnafstemmen gebruik makende van de transformers bibliotheek en om geoptimaliseerde inferentie uit te voeren op een echte wereld scenario. U kunt ook onze Fijnafstemming GPT-3.5 handleiding en ons code-along over fijnafstemmen van uw eigen LlaMA 2 model vinden.
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial