













El proyecto SOLAR-10.7B representa un avance significativo en el desarrollo de modelos de lenguaje grandes, introduciendo un nuevo enfoque para escalar estos modelos de manera efectiva y eficiente.
Este artículo comienza explicando qué es el modelo SOLAR-10.7B antes de resaltar su rendimiento en comparación con otros modelos de lenguaje grandes y profundizar en el proceso de uso de su versión especializada ajustada. Por último, el lector comprenderá las posibles aplicaciones del modelo ajustado SOLAR-10.7B-Instruct y sus limitaciones.
¿Qué es SOLAR-10.7B?
SOLAR-10.7B es un modelo de 10.7 mil millones de parámetros desarrollado por un equipo de Upstage AI en Corea del Sur.
Basado en la arquitectura Llama-2, este modelo supera a otros modelos de lenguaje grandes con hasta 30 mil millones de parámetros, incluido el modelo Mixtral 8X7B.
Para aprender más sobre Llama-2, nuestro artículo Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model proporciona una guía paso a paso para ajustar Llama-2, utilizando nuevos enfoques para superar las limitaciones de memoria y computación para un mejor acceso a modelos de lenguaje grandes de código abierto.
Además, basándose en la robusta base de SOLAR-10.7B, el modelo SOLAR-10.7B-Instruct está ajustado con énfasis en seguir instrucciones complejas. Esta variante demuestra un rendimiento mejorado, mostrando la adaptabilidad del modelo y la efectividad del ajuste para lograr objetivos especializados.
Finalmente, SOLAR-10.7B introduce un método llamado Escalamiento en Profundidad, y vamos a explorarlo en la siguiente sección.
El método de Escalamiento en Profundidad
Este método innovador permite la expandición de la profundidad de la red neuronal del modelo sin requerir un aumento correspondiente en los recursos computacionales. Esta estrategia mejora tanto la eficiencia como el rendimiento global del modelo.
Elementos esenciales de Escalamiento en Profundidad
El Escalamiento en Profundidad se basa en tres componentes principales: (1) Pesos de Mistral 7B, (2) Marco Llama 2, y (3) Preentrenamiento continuo.
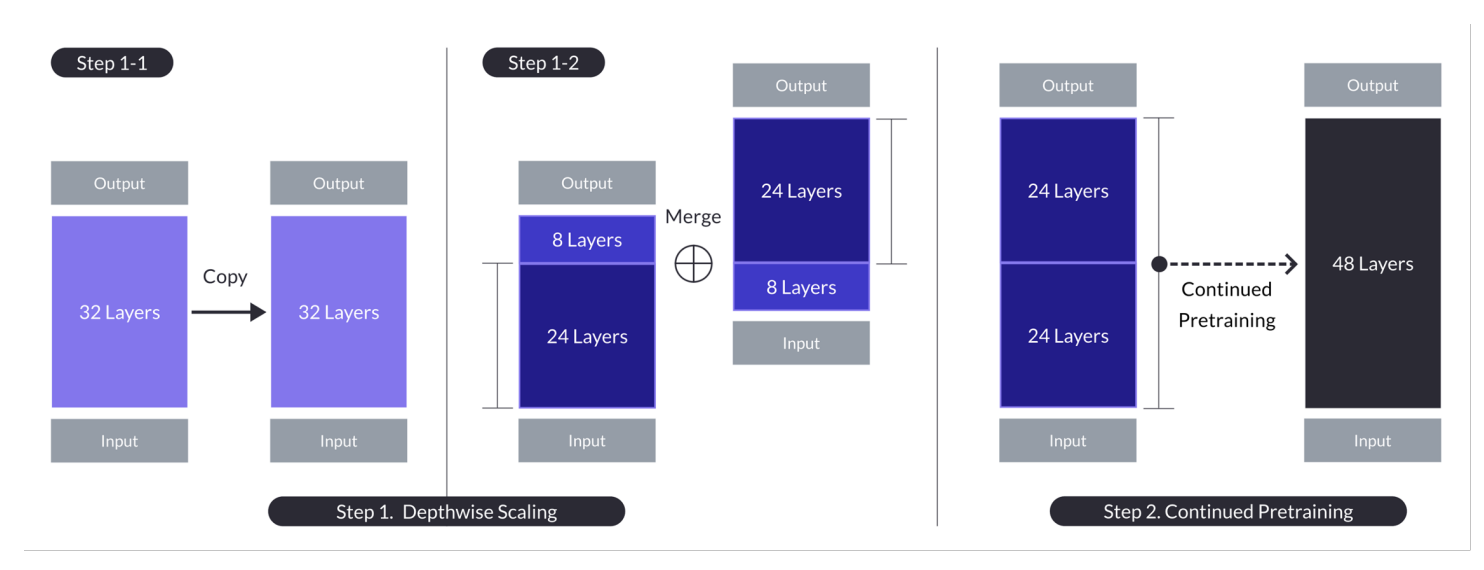
Escala en profundidad para el caso con n = 32, s = 48, y m = 8. La escalada en profundidad se logra a través de un proceso dual de escalado en profundidad seguido de preentrenamiento continuo. (Fuente)
Modelo Base:
- Usa una arquitectura de transformador de 32 capas, específicamente el modelo Llama 2, inicializado con pesos preentrenados de Mistral 7B.
- Elegido por su compatibilidad y rendimiento, con el objetivo de aprovechar los recursos de la comunidad y introducir modificaciones novedosas para capacidades mejoradas.
- Sirve como base para la escalada en profundidad y un adicional preentrenamiento para escalar eficientemente.
Escala en Profundidad:
- Escala el modelo base estableciendo un número de capas objetivo para el modelo escalado, considerando las capacidades del hardware.
- Involucra duplicar la base del modelo, eliminando las capas m finales del original y las capas iniciales m del duplicado, y luego concatenándolas para formar un modelo con s capas.
- Este proceso crea un modelo escalado con un número de capas ajustado para caber entre 7 y 13 mil millones de parámetros, específicamente utilizando una base de n=32 capas, eliminando m=8 capas para lograr s=48 capas.
Pretraining Continuado:
- Aborda la caída inicial en el rendimiento tras la escalada en profundidad eliminando heterogeneidad y discrepancias en el modelo.
- Se observó una rápida recuperación del rendimiento durante el pretraining continuo, lo que se atribuyó a la reducción de la heterogeneidad y las discrepancias en el modelo.
- El pretraining continuo es crucial para recuperar y, potencialmente, superar el rendimiento del modelo base, aprovechando la arquitectura del modelo escalado en profundidad para un aprendizaje efectivo.
Estos resúmenes resaltan las estrategias clave y los resultados del enfoque de Escalado en Profundidad, enfocándose en aprovechar los modelos existentes, la escalada a través de ajustes en profundidad y la mejora del rendimiento a través de pretraining continuo.
Este enfoque multifacético logra el SOLAR-10.7B y, en muchos casos, supera las capacidades de modelos mucho más grandes. Esta eficiencia lo hace una opción primera para una gama de aplicaciones específicas, mostrando su fuerza y flexibilidad.
¿Cómo funciona el modelo de instrucción SOLAR 10.7B?
SOLAR-10.7B instructo destaca en la interpretación y ejecución de instrucciones complejas, lo que lo hace increíblemente valioso en escenarios donde la comprensión precisa y la respuesta a los comandos humanos son cruciales. Esta capacidad es fundamental para el desarrollo de sistemas AI más intuitivos e interactivos.
- SOLAR 10.7B instructo resulta de la afinamiento fino de la original SOLAR 10.7B para seguir instrucciones en formato QA.
- El afinamiento principalmente utiliza conjuntos de datos de código abierto junto con conjuntos de datos de QA de cálculo sintetizados para mejorar las habilidades matemáticas del modelo.
- La primera versión del SOLAR 10.7B instructo se crea integrando los pesos de Mistral 7B para fortalecer sus capacidades de aprendizaje para el procesamiento eficaz y eficiente de información.
- El backbone del SOLAR 10.7B es la arquitectura Llama2, que ofrece una mezcla de velocidad y precisión.
En general, la importancia del modelo afinado SOLAR-10.7B radica en su mejor rendimiento, adaptabilidad y potencial para aplicaciones generalizadas, impulsando los campos del procesamiento de lenguaje natural y la inteligencia artificial.
Aplicaciones potenciales del modelo afinado SOLAR-10.7B
Antes de adentrarnos en la implementación técnica, exploremos algunas de las aplicaciones potenciales de un modelo afinado SOLAR-10.7B.
A continuación encontrarán algunos ejemplos de educación personalizada y tutoría, soporte cliente mejorado y creación de contenido automatizada.
- Educación personalizada y tutoría: SOLAR-10.7B-Instruct puede revolucionar el sector educativo proporcionando experiencias de aprendizaje personalizadas. Puede comprender consultas complejas de estudiantes, ofreciendo explicaciones, recursos y ejercicios adaptados. Esta capacidad lo convierte en una herramienta ideal para desarrollar sistemas de tutoría inteligentes que se adapten a los estilos y necesidades de aprendizaje individuales, mejorando la participación y los resultados de los estudiantes.
- Mejor soporte al cliente: SOLAR-10.7B-Instruct puede impulsar chatbots y asistentes virtuales avanzados capaces de comprender y resolver consultas complejas de los clientes con alta precisión. Esta aplicación no solo mejora la experiencia del cliente proporcionando soporte oportuno y relevante, sino también reduce la carga de trabajo en los representantes de servicio al cliente humanos al automatizar las consultas rutinarias.
- Creación y resumen automático de contenido: Para los medios de comunicación y creadores de contenido, SOLAR-10.7B-Instruct ofrece la capacidad de automatizar la generación de contenido escrito, como artículos de noticias, informes y escritura creativa. Además, puede resumir documentos extensos en formatos concisos y fáciles de entender, lo que lo hace invaluable para periodistas, investigadores y profesionales que necesitan asimilar y reportar rápidamente sobre grandes volúmenes de información.
Estos ejemplos subrayan la versatilidad y el potencial de SOLAR-10.7B-Instruct para impactar y mejorar la eficiencia, accesibilidad y experiencia de usuario en un amplio espectro de industrias.
Una Guía Paso a Paso para Usar SOLAR -10.7B Instruct
Tenemos suficiente información de fondo sobre el modelo SOLAR-10.7B y es hora de ponernos manos a la obra.
Este sector pretende proporcionar todas las instrucciones para ejecutar el modelo SOLAR 10.7 Instruct v1.0 – GGUF desde upstage.
Los códigos están inspirados en la documentación oficial de Hugging Face. Los pasos principales se definen a continuación:
- Instalar e importar las bibliotecas necesarias
- Definir el modelo SOLAR-10.7B para usar desde Hugging Face
- Ejecutar la inferencia del modelo
- Generar el resultado a partir de la solicitud de los usuarios
Instalación de Bibliotecas
Las principales bibliotecas utilizadas son transformers y accelerate.
- La biblioteca transformers ofrece acceso a modelos preentrenados, y la versión especificada aquí es 4.35.2.
- La biblioteca accelerate está diseñada para simplificar la ejecución de modelos de aprendizaje automático en diferentes hardwares (CPUs, GPUs) sin tener que entender profundamente las características específicas del hardware.
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
Importar Bibliotecas
Una vez que la instalación se completa, procedemos a importar las siguientes bibliotecas necesarias:
- torch es la biblioteca PyTorch, una popular biblioteca de código abierto para aprendizaje automático utilizada para aplicaciones como visión por computadora y NLP.
- AutoModelForCausalLM se utiliza para cargar un modelo preentrenado para modelado causal de lenguaje, y AutoTokenizer es responsable de convertir texto en un formato que el modelo pueda entender (tokenización).
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
Configuración de GPU
El modelo que se está utilizando es la versión 1 del modelo SOLAR-10.7B de Hugging Face.
Es necesario un recurso GPU para acelerar el proceso de carga y inferción del modelo.
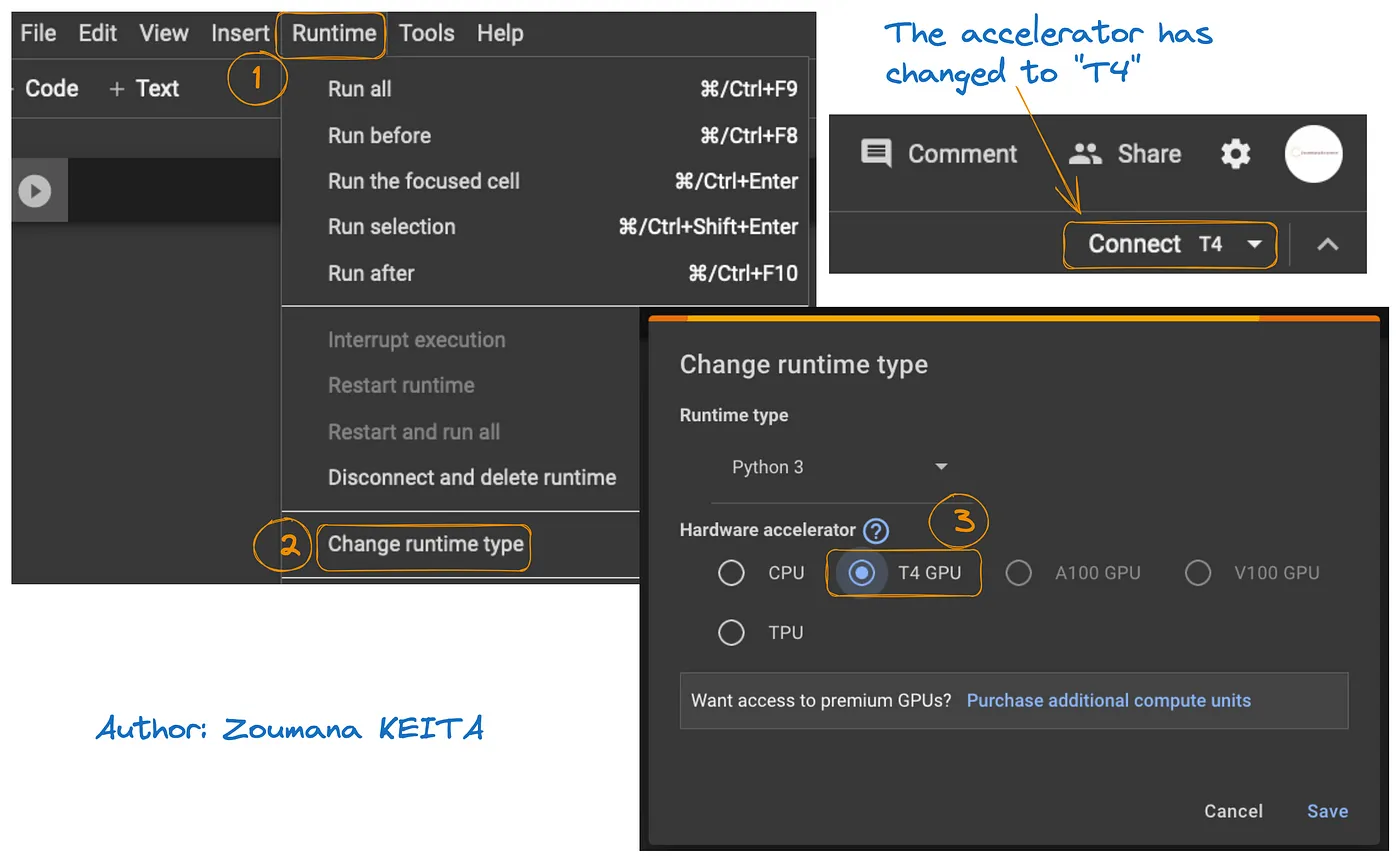
El acceso a GPU en Google Colab se ilustra en la imagen de abajo:
- Desde la pestaña Runtime, seleccione Change runtime
- A continuación, elija T4 GPU de la sección Hardware accelerator y Save los cambios
Esto cambiará el runtime predeterminado a T4:
Podemos ver las propiedades del runtime ejecutando el siguiente comando desde el cuaderno de Colab.
!nvidia-smi
GPU properties
Definición del modelo
Todo está configurado; podemos seguir cargando el modelo como sigue:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID es una cadena de texto que identifica únicamente el modelo preentrenado que queremos utilizar. En este caso, se especifica “Upstage/SOLAR-10.7B-Instruct-v1.0”.
- AutoTokenizer.from_pretrained(model_ID) carga un tokenizer preentrenado en el model_ID especificado, preparándolo para procesar la entrada de texto.
- AutoModelForCausalLM.from_pretrained() carga el modelo de lenguaje casual en sí mismo, con device_map=”auto” para utilizar automáticamente la mejor hardware disponible (el GPU que hemos configurado) y torch_dtype=torch.float16 para utilizar números de punto flotante de 16 bits para ahorrar memoria y potencialmente acelerar computaciones.
Inferencia del modelo
Antes de generar una respuesta, el texto de entrada (solicitud del usuario) se formatea y tokeniza.
- user_request contiene la pregunta o entrada para el modelo.
- conversation formatea la entrada como parte de una conversación, etiquetándola con un rol (por ejemplo, ‘usuario’).
- apply_chat_template aplica una plantilla conversacional a la entrada, preparándola para que el modelo la entienda en un formato que reconozca.
- tokenizer(prompt, return_tensors=”pt”) convierte la solicitud en tokens y especifica el tipo de tensor (“pt” para tensores de PyTorch), y .to(model.device) asegura que la entrada esté en el mismo dispositivo (CPU o GPU) que el modelo.
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
Generación de resultados
La última sección utiliza el modelo para generar una respuesta a la pregunta de entrada y luego decodifica e imprime el texto generado.
- model.generate() genera texto basado en las entradas proporcionadas, con use_cache=True para acelerar la generación reutilizando resultados calculados previamente. max_length=4096 limita la longitud máxima del texto generado.
- tokenizer.decode(outputs[0]) convierte los tokens generados de nuevo en texto legible por humanos.
- print sentencia muestra la respuesta generada a la pregunta del usuario.
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
La ejecución exitosa del código anterior genera el siguiente resultado:

Al reemplazar la solicitud del usuario con el siguiente texto, obtenemos la respuesta generada
user_request = "Tell me a story about the universe"

Limitaciones del modelo SOLAR-10.7B
A pesar de todos los beneficios del SOLAR-10.7B, tiene sus propias limitaciones como cualquier otro modelo de lenguaje grande, y las principales se destacan a continuación:
- Exploración exhaustiva de hiperparámetros: la necesidad de una exploración más exhaustiva de los hiperparámetros del modelo durante el Escalado de Profundidad (DUS) es una limitación clave. Esto provocó la eliminación de 8 capas del modelo base debido a limitaciones de hardware.
- Exigente en recursos computacionales: el modelo es significativamente exigente en recursos de computación, y esto limita su uso por parte de individuos y organizaciones con capacidades computacionales menores.
- Vulnerabilidad al sesgo: el sesgo potencial en los datos de entrenamiento podría afectar el rendimiento del modelo para algunos casos de uso.
- Preocupación ambiental: el entrenamiento e inferencia del modelo requiere un consumo energético significativo, lo que puede generar preocupaciones ambientales.
Conclusión
Este artículo ha explorado el modelo SOLAR-10.7B, destacando su contribución a la inteligencia artificial a través del enfoque de escalado de profundidad. Ha delineado la operación del modelo y sus aplicaciones potenciales, y proporcionado una guía práctica para su uso, desde la instalación hasta la generación de resultados.
A pesar de sus capacidades, el artículo también abordó las limitaciones del modelo SOLAR-10.7B, asegurando una perspectiva bien equilibrada para los usuarios. A medida que la IA continúa evolucionando, SOLAR-10.7B ejemplifica los avances realizados hacia herramientas de IA más accesibles y versátiles.
Para aquellos que buscan profundizar más en el potencial de la IA, nuestro tutorial, Tutorial FLAN-T5: Guía y Ajuste Fino, ofrece una guía completa para ajustar fino un modelo FLAN-T5 para una tarea de respuesta a preguntas utilizando la biblioteca transformers y ejecutar inferencia optimizada en un escenario real del mundo. También puede encontrar nuestro tutorial de Ajuste Fino GPT-3.5 y nuestro código secuencial en ajustar fino tu propio modelo LlaMA 2.
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial