













Das SOLAR-10.7B-Projekt markiert einen bedeutenden Fortschritt in der Entwicklung großer Sprachmodelle, indem es eine neue Herangehensweise an die Skalierung dieser Modelle in eine effiziente und wirksame Weise einführt.
In diesem Artikel wird zunächst erklärt, was das SOLAR-10.7B-Modell ist, bevor auf seine Leistung gegenüber anderen großen Sprachmodellen verglichen wird und in das Verfahren eingeht, um seine spezialfine-tuned Version zu verwenden. Schließlich versteht der Leser die potenziellen Anwendungen des fine-tuned SOLAR-10.7B-Instruct-Modells und seine Grenzen.
Was ist SOLAR-10.7B?
SOLAR-10.7B ist ein 10,7 Milliarden Parameter umfassendes Modell, das von einem Team bei Upstage AI in Südkorea entwickelt wurde.
Basierend auf der Llama-2-Architektur übertrifft dieses Modell andere große Sprachmodelle mit bis zu 30 Milliarden Parametern, einschließlich des Mixtral 8X7B-Modells.
Um mehr über Llama-2 zu erfahren, der Artikel unseres Fine-Tuning LLaMA 2: Ein Schritt-für-Schritt-Leitfaden zur Anpassung des Großen Sprachmodells beschreibt, wie man Llama-2 fine-tune, indem neue Ansätze verwendet werden, um den Gedächtnis- und Rechenbegrenzungen zu begegnen, um besseren Zugriff auf Open-Source-große Sprachmodelle zu erhalten.
Weiterhin baut das SOLAR-10.7B-Instruct-Modell auf die robuste Grundlage von SOLAR-10.7B auf und wird mit einem Schwerpunkt auf die Befolgung komplexer Anweisungen fine-tuned. Diese Variante zeigt eine verbesserte Leistung und demonstriert die Anpassungsfähigkeit des Modells und die Effektivität von Fine-Tuning bei der Erreichung spezialisierter Ziele.
Endlich führt SOLAR-10.7B eine Methode namens Depth Up-Scaling ein, die wir im folgenden Abschnitt weiter erkunden.
Die Depth Up-Scaling Methode
Diese innovative Methode ermöglicht die Erweiterung der Tiefe des neuronalen Netzwerks des Modells, ohne dass ein entsprechender Anstieg der Rechenressourcen erforderlich ist. Eine solche Strategie verbessert sowohl die Effizienz als auch die Gesamtleistung des Modells.
Wesentliche Elemente des Depth Up-Scaling
Das Depth Up-Scaling basiert auf drei Hauptkomponenten: (1) Mistral 7B Gewicht, (2) Llama 2 Framework und (3) Kontinuierliches Pre-Training.
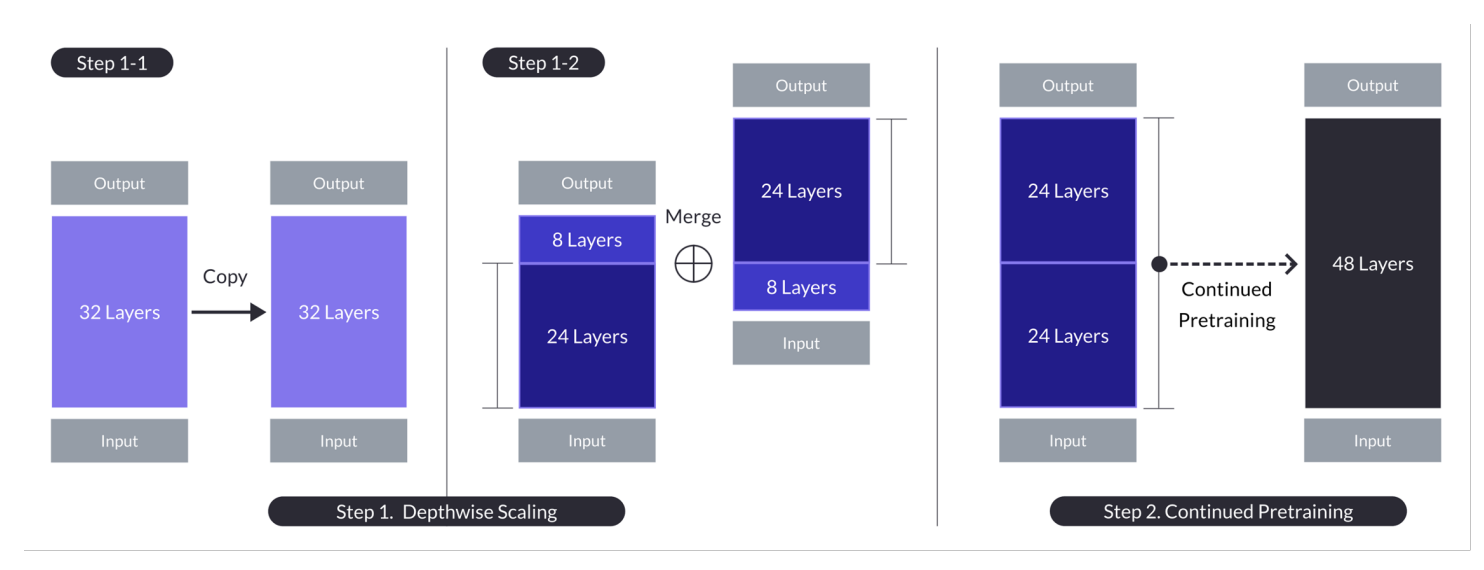
Tiefenskalierung für den Fall mit n = 32, s = 48 und m = 8. Die Tiefenskalierung wird durch einen zweistufigen Prozess der tiefenweisen Skalierung gefolgt von weiterem Pre-Training erreicht. (Quelle)
Basismodell:
- Verwendet eine 32-Schichten-Transformer-Architektur, speziell das Llama 2 Modell, initialisiert mit vortrainierten Gewichten von Mistral 7B.
- Ausgewählt für seine Kompatibilität und Leistung, mit dem Ziel, Gemeinschaftsressourcen zu nutzen und neuartige Modifikationen für verbesserte Fähigkeiten einzuführen.
- Dient als Grundlage für tiefenweise Skalierung und weiteres Pre-Training, um effizient hochzuskalieren.
Tiefenweise Skalierung:
- Skaliert das Basismodell, indem eine Zielschichtenzahl für das skalierte Modell festgelegt wird, unter Berücksichtigung der Hardwarefähigkeiten.
- Das Verfahren beinhaltet die Duplizierung des Basismodells, das Entfernen der letzten m Schichten aus dem Original und der ersten m Schichten aus der Duplikation, um sie dann zu einem Modell mit s Schichten zu concatenieren.
- Dieser Prozess erstellt ein skaliertes Modell mit einer angepassten Anzahl von Schichten, um zwischen 7 und 13 Milliarden Parameter zu passen, wobei speziell eine Basis von n=32 Schichten verwendet wird und m=8 Schichten entfernt werden, um s=48 Schichten zu erreichen.
Fortgesetztes Pretraining:
- Es adressiert den anfänglichen Leistungsabfall nach der Tiefenskala, indem das skalierte Modell weiter vortrainiert wird.
- Schnelle Leistungswiederherstellung wurde während des fortgesetzten Pretrainings beobachtet, was darauf zurückgeführt wurde, dass die Heterogenität und die Unterschiede im Modell reduziert wurden.
- Fortgesetztes Pretraining ist entscheidend, um die Leistung des Basismodells wiederzuerlangen und potenziell zu übertreffen, indem die Architektur des tiefenskalierten Modells für effektives Lernen genutzt wird.
Diese Zusammenfassungen heben die wichtigsten Strategien und Ergebnisse des Depth Up-Scaling-Ansatzes hervor, wobei der Fokus auf der Nutzung bestehender Modelle, der Skalierung durch Tiefenanpassung und der Leistungssteigerung durch fortgesetztes Pretraining liegt.
Dieser facettenreiche Ansatz SOLAR-10.7B erreicht und übertrifft in vielen Fällen die Fähigkeiten viel größerer Modelle. Diese Effizienz macht es zu einer erstklassigen Wahl für eine Reihe spezifischer Anwendungen und zeigt seine Stärke und Flexibilität.
Wie funktioniert das SOLAR 10.7B Instruct-Modell?
SOLAR-10.7B instruct ist hervorragend in der Interpretation und Ausführung komplexer Anweisungen, was es in Situationen, in denen eine präzise Verständnis und Reaktionsfähigkeit auf menschliche Befehle entscheidend ist, unglaublich wertvoll macht. Diese Fähigkeit ist unerlässlich für die Entwicklung von intuitiverren und interaktiveren AI-Systemen.
- SOLAR 10.7B instruct ergibt sich aus der feinen Anpassung des ursprünglichen SOLAR 10.7B-Modells, um Befehle im QA-Format zu befolgen.
- Die feine Anpassung nutzt hauptsächlich Open-Source-Datensets sowie synthetisierte mathematische QA-Datensets, um die mathematischen Fähigkeiten des Modells zu verbessern.
- Die erste Version des SOLAR 10.7B instruct wurde durch die Integration der Mistral 7B-Gewichte zur Stärkung seiner Lernfähigkeiten für effektives und effizientes Informationsverarbeitung geschaffen.
- Der Kern des SOLAR 10.7B ist die Llama2-Architektur, die eine Kombination von Geschwindigkeit und Genauigkeit bietet.
Insgesamt ist der fein abgestimmte SOLAR-10.7B-Model ansichtig in seiner verbesserten Leistung, Anpassung und potenziellen allgemeinen Anwendungen, was die Bereiche der natürlichen Sprachverarbeitung und der künstlichen Intelligenz vorwärts bringt.
Mögliche Anwendungen des fein abgestimmten SOLAR-10.7B-Modells
Bevor wir uns der technischen Implementierung widmen, lassen Sie uns einige möglichen Anwendungen eines fein abgestimmten SOLAR-10.7B-Modells erörtern.
Nachstehend finden Sie Beispiele für personalisierte Ausbildung und Tutoring, verbessertes Kundendienstleistungen und automatisierte Inhaltserstellung.
- Personalisierte Bildung und Tutoring: SOLAR-10.7B-Instruct kann den Bildungssektor revolutionieren, indem es personalisierte Lernerfahrungen bereitstellt. Es kann komplexe Schülerfragen verstehen und bietet massgeschneiderte Erklärungen, Ressourcen und Übungen. Diese Fähigkeit macht es zu einem idealen Tool für die Entwicklung intelligenter Tutoring-Systeme, die auf individuelle Lernstile und Bedürfnisse anpassen und die Schülerbeteiligung und Ergebnisse verbessern.
- Verbesserte Kundensupport: SOLAR-10.7B-Instruct kann fortschrittliche Chatbots und virtuelle Assistenten antreiben, die in der Lage sind, komplexe Kundenanfragen mit hoher Genauigkeit zu verstehen und zu lösen. Diese Anwendung verbessert nicht nur die Kundenerfahrung, indem sie zeitnah und relevante Unterstützung bereitstellt, sondern reduziert auch die Arbeitslast von menschlichen Kundenservicevertretern, indem sie Routineanfragen automatisiert.
- Automatisierte Inhaltserstellung und Zusammenfassung: Für Medien- und Inhaltschaffende bietet SOLAR-10.7B-Instruct die Fähigkeit, die Erstellung von schriftlichen Inhalten automatisch zu verwalten, wie z.B. Nachrichtenartikel, Berichte und kreatives Schreiben. Zusätzlich kann es umfangreiche Dokumente in kurze, leicht verständliche Formate zusammenfassen, was ihn für Journalisten, Forscher und Fachleute unentbehrlich macht, die schnell Informationen verarbeiten und berichten müssen.
Diese Beispiele unterstreichen die Vielseitigkeit und das Potenzial von SOLAR-10.7B-Instruct, Einfluss und Effizienz, Zugänglichkeit und Nutzererfahrung in einer breiten Palette von Branchen zu beeinflussen und zu verbessern.
Ein Schritt-für-Schritt-Leitfaden zur Nutzung von SOLAR-10.7B-Instruct
Wir haben genug Hintergrundwissen über das SOLAR-10.7B-Modell und es ist an der Zeit, die Hände in die Schmutz zu getaucht.
Dieser Abschnitt zielt darauf ab, alle Anweisungen zur Ausführung des SOLAR 10.7 Instruct v1.0 – GGUF-Modells von Upstage bereitzustellen.
Die Code wurden durch die offizielle Dokumentation von Hugging Face inspiriert. Die Haupt Schritte sind unten definiert:
- Installieren und importieren Sie die notwendigen Bibliotheken
- Definieren Sie das SOLAR-10.7B-Modell, das von Hugging Face verwendet werden soll
- Führen Sie die Modellinferenz aus
- Erstellen Sie das Ergebnis auf Basis des Benutzerauftrags
Bibliotheken Installation
Die wichtigsten Bibliotheken, die verwendet werden, sind transformers und accelerate.
- Die transformers Bibliothek bietet Zugriff auf vordefinierte Modelle und die hier festgelegte Version ist 4.35.2.
- Die accelerate Bibliothek ist dafür konzipiert, das Ausführen von maschinellen Lernmodelle auf verschiedene Hardware (CPUs, GPUs) zu vereinfachen, ohne die Details der Hardware tief zu verstehen.
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
Importieren Sie Bibliotheken
Nun, dass die Installation fertiggestellt ist, fahren wir mit dem Importieren der folgenden notwendigen Bibliotheken fort:
- torch ist die PyTorch-Bibliothek, eine populäre open-source maschinelle Lernbibliothek, die für Anwendungen wie Computer Vision und NLP verwendet wird.
- AutoModelForCausalLM wird verwendet, um ein vordefiniertes Modell für kausales Sprachmodellierung zu laden, und AutoTokenizer ist verantwortlich für die Konvertierung von Text in eine Format, das das Modell verstehen kann (Tokenisierung).
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
GPU-Konfiguration
Die verwendete Modelle ist die Version 1 des SOLAR-10.7B-Modells von Hugging Face.
Ein GPU-Resource ist notwendig, um den Modell Laden und die Inferenzprozesse zu beschleunigen.
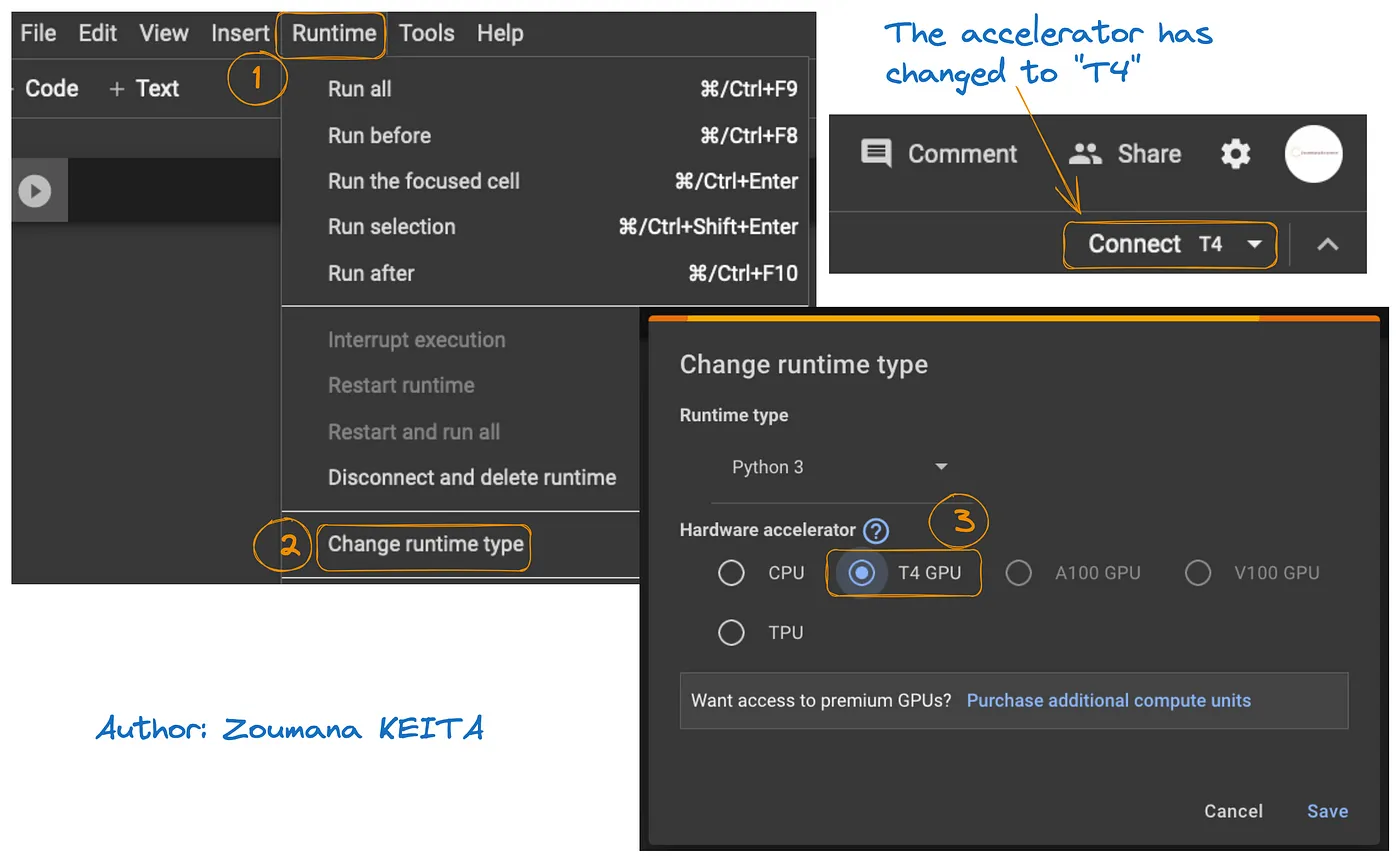
Der Zugriff auf das GPU auf Google Colab ist in dem Diagramm unten dargestellt:
- Wählen Sie von der Registerkarte Runtime aus, Change runtime
- Wählen Sie dann T4 GPU aus dem Hardware-Accelerator- Abschnitt und Save die Änderungen
Dadurch wechselt die Standard-Runtime auf T4:
Wir können die Eigenschaften der Runtime mit dem folgenden Befehl von der Colab-Notebook aus überprüfen.
!nvidia-smi
GPU-Eigenschaften
Modeldefinition
Alles ist eingerichtet; wir können mit dem Laden des Modells fortfahren, wie folgt:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID ist eine Zeichenkette, die einzigartig ein vorbereitetes Modell kennzeichnet, das wir verwenden möchten. In diesem Fall ist „Upstage/SOLAR-10.7B-Instruct-v1.0“ angegeben.
- AutoTokenizer.from_pretrained(model_ID) lädt einen Tokenizer, der auf dem model_ID vorbereitet ist, und bereitet ihn für die Textdatenverarbeitung vor.
- AutoModelForCausalLM.from_pretrained() lädt das kausale Sprachmodell selbst, mit device_map=“auto“, um die beste verfügbare Hardware (die GPU, die wir eingerichtet haben) automatisch zu verwenden, und torch_dtype=torch.float16, um 16-Bit-Fließkommazahlen zu verwenden, um Speicher und möglicherweise Berechnungen zu beschleunigen.
Modellinferenz
Vor der Generierung einer Antwort wird der Eingabetext (Anfrage des Benutzers) formatiert und tokenisiert.
- Benutzeranfrage enthält die Frage oder Eingabe für das Modell.
- Gespräch formatiert die Eingabe als Teil eines Gesprächs und kennzeichnet sie mit einer Rolle (z. B. ‚Benutzer‘).
- Chat-Vorlage anwenden wendet eine Gesprächsvorlage auf die Eingabe an und bereitet sie für das Modell in einem Format vor, das es versteht.
- tokenizer(prompt, return_tensors=“pt“) konvertiert den Prompt in Token und spezifiziert den Tensortyp („pt“ für PyTorch-Tensoren), und .to(model.device) stellt sicher, dass die Eingabe auf dem gleichen Gerät (CPU oder GPU) wie das Modell erfolgt.
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
Ergebnisgenerierung
Der letzte Abschnitt verwendet das Modell, um eine Antwort auf die Eingabe zu generieren, und dekodiert und druckt dann den generierten Text.
- model.generate() generiert Text basierend auf den bereitgestellten Eingaben, wobei use_cache=True verwendet wird, um die Generierung zu beschleunigen, indem zuvor berechnete Ergebnisse wiederverwendet werden. max_length=4096 begrenzt die maximale Länge des generierten Textes.
- tokenizer.decode(outputs[0]) konvertiert die generierten Token zurück in menschenlesbaren Text.
- print Anweisung zeigt die generierte Antwort auf die Frage des Benutzers an.
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
Die erfolgreiche Ausführung des obigen Codes erzeugt das folgende Ergebnis:

Durch Ersetzen der Benutzeranfrage mit dem folgenden Text erhalten wir die generierte Antwort
user_request = "Tell me a story about the universe"

Beschränkungen des SOLAR-10.7B-Modells
Trotz aller Vorteile des SOLAR-10.7B hat es wie jedes andere große Sprachmodell seine eigenen Einschränkungen, und die wichtigsten sind unten hervorgehoben:
- Umfassende Hyperparameter-Erkundung: die Notwendigkeit einer gründlicheren Erkundung der Hyperparameter des Modells während des Tiefen-Hochskalierens (DUS) ist eine wesentliche Einschränkung. Dies führte zur Entfernung von 8 Schichten aus dem Basismodell aufgrund von Hardware-Einschränkungen.
- Hoher Rechenaufwand: das Modell erfordert erheblich viele Rechenressourcen, was seine Nutzung durch Einzelpersonen und Organisationen mit geringeren Rechenkapazitäten einschränkt.
- Anfälligkeit für Bias: potenzielle Voreingenommenheit in den Trainingsdaten könnte die Leistung des Modells für einige Anwendungsfälle beeinträchtigen.
- Umweltbelastung: das Training und die Inferenz des Modells erfordern einen erheblichen Energieverbrauch, was Umweltbedenken hervorrufen kann.
Fazit
Dieser Artikel hat das SOLAR-10.7B-Modell untersucht und seine Beiträge zur künstlichen Intelligenz durch den Tiefen-Hochskalierungsansatz hervorgehoben. Er hat den Betrieb und die potenziellen Anwendungen des Modells beschrieben und eine praktische Anleitung für seine Nutzung, von der Installation bis zur Ergebnisgenerierung, bereitgestellt.
Trotz seiner Fähigkeiten hat der Artikel auch die Einschränkungen des SOLAR-10.7B-Modells angesprochen und so eine ausgewogene Perspektive für die Nutzer sichergestellt. Da sich die KI weiterentwickelt, exemplifiziert SOLAR-10.7B die Fortschritte in Richtung zugänglicherer und vielseitigerer KI-Werkzeuge.
Für diejenigen, die sich tiefer in das Potenzial von KI einarbeiten möchten, bietet unser Tutorial FLAN-T5 Tutorial: Leitfaden und Feintuning einen vollständigen Leitfaden zum Feintuning eines FLAN-T5-Modells für eine Frage-Antwort-Aufgabe anhand der transformers-Bibliothek und der Optimierung von Inferenz in einer realen Welt. Sie können auch unser Feintuning von GPT-3.5 Tutorial und unseren Code-Along zum Feintuning Ihres eigenen LlaMA 2-Modells finden.
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial