













SOLAR-10.7B 項目代表了大型語言模型發展的一個重大飛躍,引入了一種有效且高效的擴展這些模型的新方法。
本文首先解釋了什麼是 SOLAR-10.7B 模型,然後強調其相對於其他大型語言模型的性能,並深入探討使用其專門微調版本的過程。最後,讀者將了解微調後的 SOLAR-10.7B-Instruct 模型的潛在應用及其局限性。
什麼是 SOLAR-10.7B?
SOLAR-10.7B 是由南韓 Upstage AI 團隊開發的一個擁有 107 億參數的模型。
基於 Llama-2 架構,該模型超越了其他擁有高達 300 億參數的大型語言模型,包括 Mixtral 8X7B 模型。
想了解更多關於 Llama-2 的信息,我們的文章 微調 LLaMA 2:定製大型語言模型的逐步指南 提供了一個逐步指南,使用新方法克服記憶體和計算限制,以更好地訪問開源大型語言模型。
此外,基於 SOLAR-10.7B 的堅實基礎,SOLAR-10.7B-Instruct 模型經過專門微調,重點在於遵循複雜指令。這一變體展示了增強的性能,展示了模型的適應性以及微調在實現專業目標方面的有效性。
最後,SOLAR-10.7B 引進了一個稱為「深度擴增」的方法,讓我們在下一節進一步探索。
「深度擴增」方法
這種創新方法讓模型 neural network 的深度可以擴張,而不需要相对增加計算資源。這種策略提高了模型的效率和整體性能。
「深度擴增」的基本元素
「深度擴增量」基於三大元件: (1) Mistral 7B 權重,(2) Llama 2 框架,和 (3) 持續预训练。
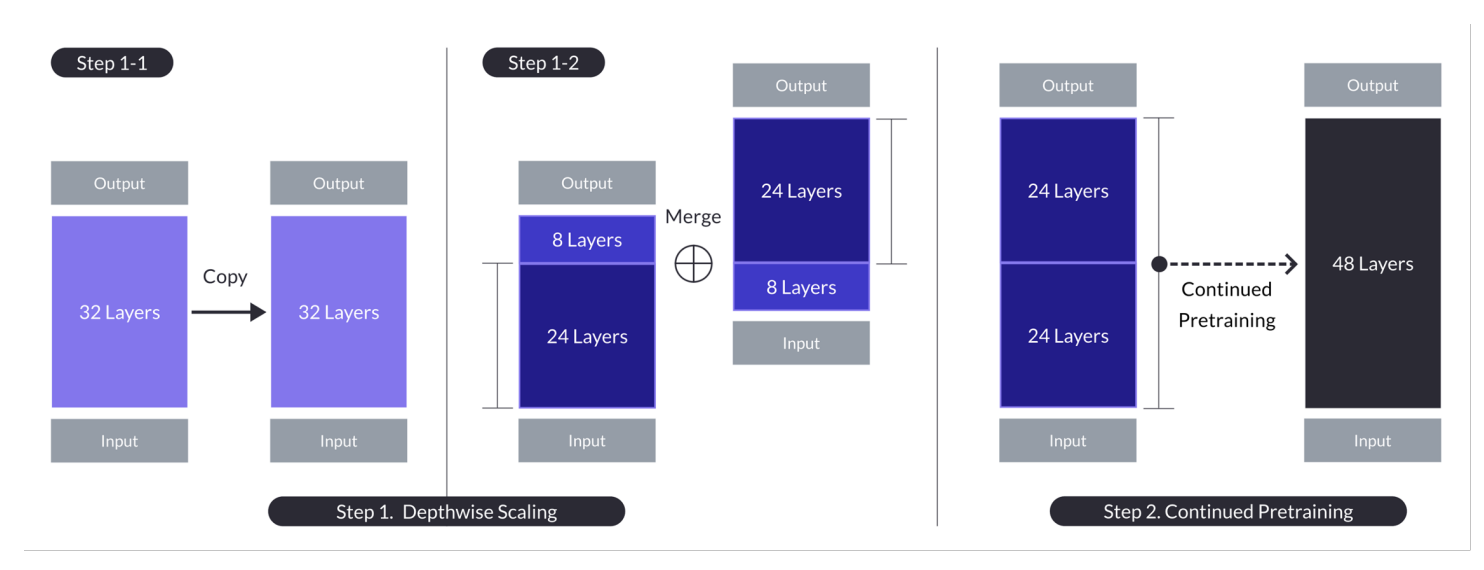
當 n = 32, s = 48, 和 m = 8 時,「深度擴增量」的案例。 「深度擴增量」通過兩個阶段的過程實現:先進行深度擴展,再進行預訓練。 (來源)
基模型:
- 使用 32 層變形器架構,特別是 Llama 2 模型,初始化 Mistral 7B 預訓練權重。
- 選擇它是因为它的兼容性和性能,目的是利用社群資源和引入新奇的修改以獲得增強的能力。
- 作為深度擴展和進一步預訓練的基础以有效擴張。
深度擴展:
- 通過設定擴增量模型的目標層數,考慮硬件能力,來擴張基模型。
- 涉及複製基本模型,從原模型的最後m層和複製模型的最初m層中移除,然後將它們串連起來形成具有s層的模型。
- 這個過程創建了一個可調整層數的縮放模型,層數介於7和130億params之間,具體使用基底n=32層,移除m=8層以達到s=48層。
持續预训练:
- 通過繼續預訓練縮放模型來應對縮放後初次性能下降。
- 在持續預訓練過程中,觀察到性能迅速恢復,這被归因於减少了模型的異質性和差異。
- 持續預訓練對於恢復並可能在基礎模型性能之上有着至关重要的作用,利用深度縮放的模型結構進行有效的學習。
這些摘要突顯了深度擴展方法的關鍵策略和結果,著重於利用既有模型的擴展、通過深度調整來縮放以及透過持續預訓練提高性能。
這種多面向的方法SOLAR-10.7B達到並,在許多情況下,超越了更大模型的功能。這種效率使其成為一系列特定應用的主選,展現了其強度和靈活性。
SOLAR 10.7B指令模型是如何工作的?
SOLAR-10.7B instruct 精於解釋和執行複雜指令,這使其在需要精確理解和響應人類命令的場景中特別有價值。這種能力對於開發更直觀和互動的 AI 系統至關重要。
- SOLAR 10.7B instruct 是通過微調原始的 SOLAR 10.7B 模型以遵循 QA 格式的指令而得來的。
- 微調主要使用開源數據集以及合成的數學 QA 數據集來增強模型的數學技能。
- SOLAR 10.7B instruct 的第一個版本是通過整合 Mistral 7B 權重來加強其學習能力,以實現有效和高效的信息處理。
- SOLAR 10.7B 的主幹是 Llama2 架構,這提供了速度和準確性的平衡。
總體而言,微調後的 SOLAR-10.7B 模型的重要性在於其增強的性能、適應性和廣泛應用的潛力,推動了自然語言處理和人工智能領域的發展。
微調後的 SOLAR-10.7B 模型的潛在應用
在深入研究技術實施之前,讓我們探索一下微調後的 SOLAR-10.7B 模型的一些潛在應用。
以下是一些個性化教育和輔導、增強的客戶支持以及自動化內容創建的例子。
- 個人化教育與家教:SOLAR-10.7B-Instruct可以革新教育界,通過提供個人化學習體驗。它能夠理解複雜的學生問題,提供量身定制的解釋、資源和練習。這種能力使其成為開發適應個體學習風格和需求的聪明家教系統的理想工具,從而提高學生參與度和成效。
- 更好的客戶支援:SOLAR-10.7B-Instruct可以驅動進階聊天机器人與虛擬助手,能夠理解並精準解決複雜的客戶詢問。這種應用不僅通過提供即時且相关的支援改善客戶體驗,也通過自動化例行問題來減少人類客戶服務代表的工作負擔。
- 自動化內容創建與摘要在内:對於媒體與內容創作者,SOLAR-10.7B-Instruct提供了自動化生成文字內容的服务能力,例如新聞文章、報告和創意寫作。此外,它還能夠將冗長的文件摘要在簡潔易懂的格式中,對於记者、研究人员和專業人士來說,這是非常有價值的,因為他們需要快速消化和報告大量信息。
這些例子凸显了SOLAR-10.7B-Instruct的 多功能性與潛在影響,能針對廣泛行業提高效率、可达性與用戶體驗。
使用SOLAR-10.7B Instruct的步驟指南
我們對SOLAR-10.7B模型的認識已經足夠,是时候亲自动手了。
這一節旨在提供從upstage運行SOLAR 10.7 Instruct v1.0 – GGUF模型的全部指示。
這些代碼受到Hugging Face上的官方文件的啟發。主要步驟定義如下:
- 安裝並導入必要的函式庫
- 從Hugging Face定義要使用的SOLAR-10.7B模型
- 運行模型推論
- 從用戶的要求生成結果
函式庫安裝
使用的主要函式庫為transformers和accelerate。
- transformers函式庫提供了訪問預訓練模型的途徑,這裡指定的版本為4.35.2。
- accelerate函式庫旨在簡化在不同硬體(CPU、GPU)上運行機器學習模型的過程,而無需深入了解硬體的具體細節。
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
導入函式庫
安裝完成後,我們繼續導入以下必要的函式庫:
- torch是PyTorch函式庫,這是一個流行的開源機器學習函式庫,用於電腦視覺和自然語言處理等應用。
- AutoModelForCausalLM用於加載預訓練的因果語言建模模型,而AutoTokenizer負責將文字轉換成模型能夠理解的格式(分詞)。
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
GPU配置
所使用的模型是來自 Hugging Face 的 SOLAR-10.7B 模型的版本 1。
需要 GPU 資源來加速模型加載和推理過程。
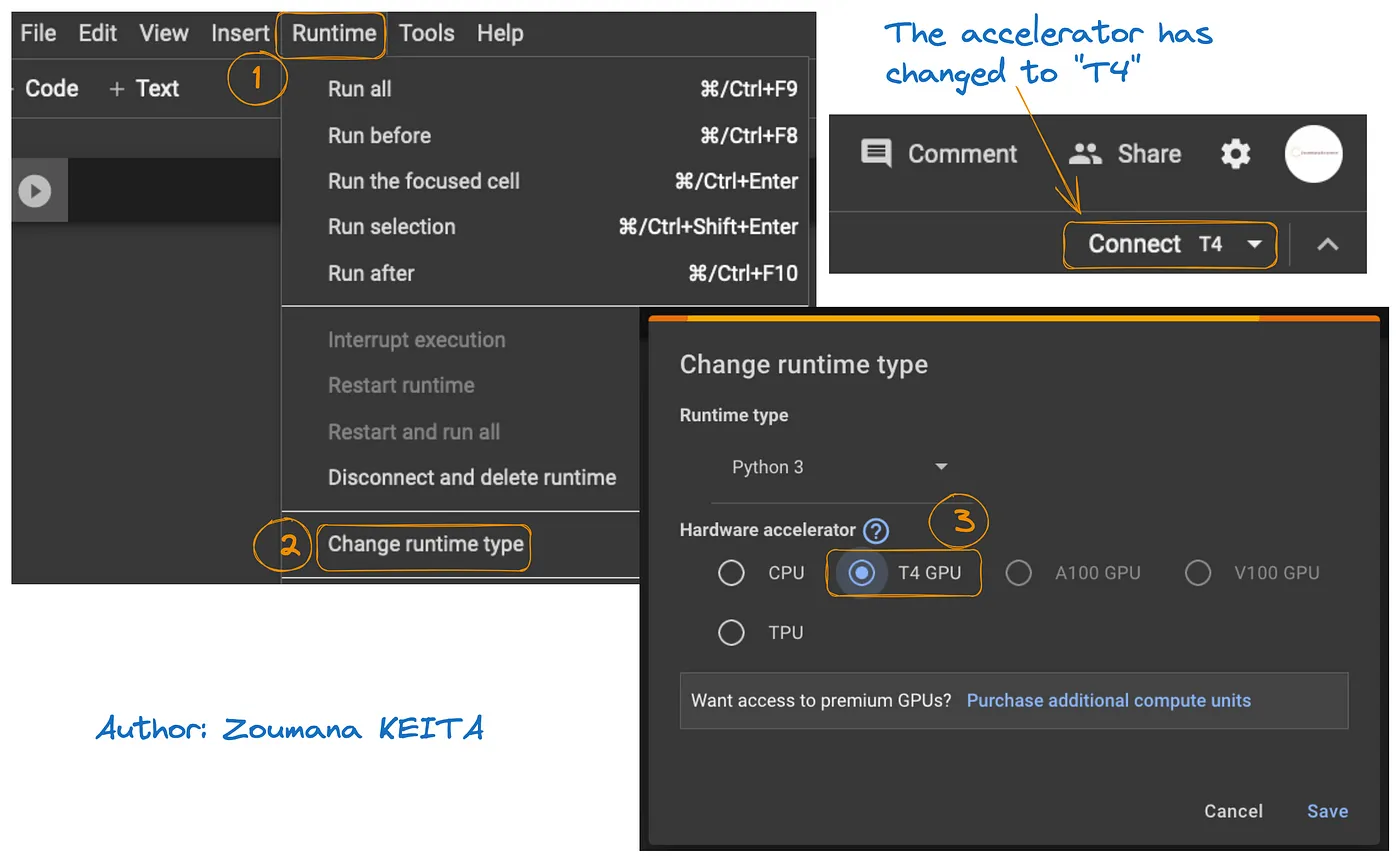
在下圖中說明了如何在 Google Colab 上訪問 GPU:
- 從 Runtime 標籤中,選擇 Change runtime
- 然後,在硬件加速器部分選擇 T4 GPU 並 Save 更改
這將把默認運行時切換到 T4:
我們可以通過在 Colab 筆記本中運行以下命令來檢查運行時的屬性。
!nvidia-smi
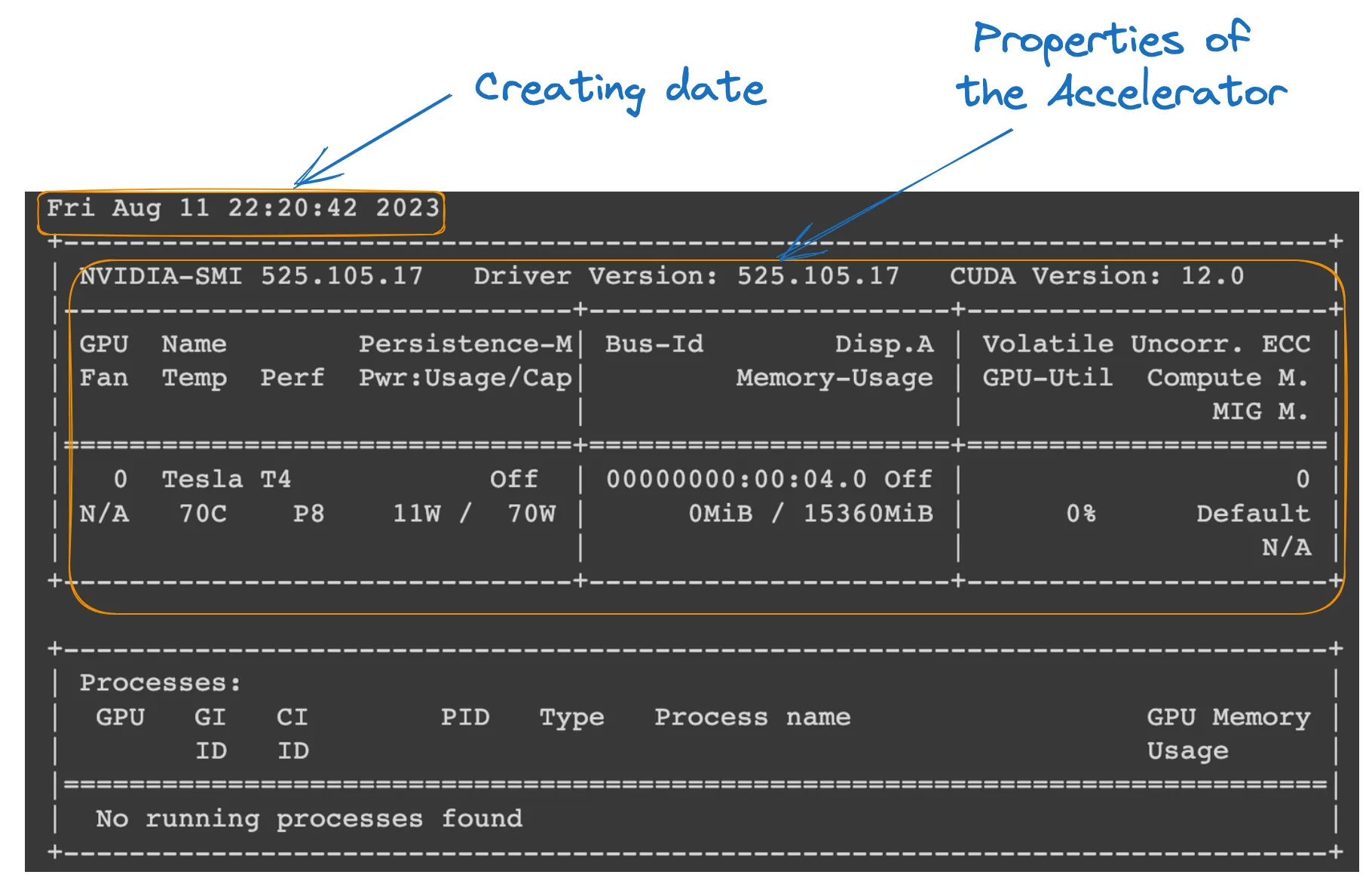
GPU properties
模型定義
一切都已設置;我們可以如下加載模型:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID 是唯一標識我們要使用的預訓練模型的字符串。在這種情況下,指定為 “Upstage/SOLAR-10.7B-Instruct-v1.0”。
- AutoTokenizer.from_pretrained(model_ID) 加載一個在指定 model_ID 上預訓練的 tokenizer,為處理文本輸入做準備。
- AutoModelForCausalLM.from_pretrained() 加載因果語言模型,device_map=”auto” 會自動使用最佳可用硬件(我們已設置的 GPU),並使用 torch_dtype=torch.float16 以 16 位浮點數來節省內存並可能加快計算速度。
模型推理
在生成響應之前,輸入文本(用戶的請求)會被格式化和分詞。
- user_request 包含問題或對模型的輸入。
- conversation 將輸入格式設定為對話的一部分,並使用角色標籤(例如,’user’)。
- apply_chat_template 將對話模板應用於輸入,以模型能夠理解的格式準備它。
- tokenizer(prompt, return_tensors=”pt”) 將提示轉換為令牌並指定張量類型(”pt” 為 PyTorch 張量),而 .to(model.device) 確保輸入與模型的設備(CPU 或 GPU)相同。
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
結果生成
最後一節使用模型對輸入問題生成回應,然後解碼並列印生成的文本。
- model.generate() 根據提供的輸入生成文本,使用 use_cache=True 來通過重用之前計算的結果來加速生成。max_length=4096 將生成的文本的最大長度限制為4096。
- tokenizer.decode(outputs[0]) 將生成的令牌轉換回可讀文本。
- print 語句顯示對用戶問題生成的答案。
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
上述代碼的成功執行產生了以下結果:

通過將用戶請求替換為以下文本,我們獲得了生成的回應
user_request = "Tell me a story about the universe"

SOLAR-10.7B 模型的限制
SOLAR-10.7B雖然具有許多優點,但它和任何其他大型語言模型一樣,也有一些限制,主要如下:
- 深入的超參數探索:模型在深度擴展(DUS)過程中需要更彻底地探索超參數,這是一個主要的限制。這導致由於硬件限制,移除了基本模型中的8層。
- 計算要求高的:模型的計算資源需求非常顯著,這限制了計算能力较低的個人和組織使用該模型的能力。
- 對偏見的脆弱性:訓練數據中可能存在的偏見可能會影響模型的某些使用场景的性能。
- 環境問題:模型的訓練和推理需要大量的能源消耗,這可能會引起環境問題。
結論
本文探讨了SOLAR-10.7B模型,通過深度擴展方法展示它在人工智慧領域的貢獻。它概述了模型的操作和潛在應用,並提供了從安裝到生成結果的實用指南。
儘管它的能力很强,文章也address了SOLAR-10.7B模型的限制,為用戶提供全面的視角。隨著AI的不斷發展,SOLAR-10.7B示例了朝向更易訪問和多才多藝的AI工具所取得的進步。
對那些想要深入探究 AI 潛能的人,我們的教程 FLAN-T5 教程:導航與微調 提供了完整的指導,教您如何使用 transformers 庫對 FLAN-T5 模型進行問題回答任務的微調,並在现实世界的場景中運行優化后的推理。您還可以在我們的 GPT-3.5 微調教程 和我們的 與我们一起微調自己的 LlaMA 2 模型的代码示例 中找到更多相關信息。
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial