













O projeto SOLAR-10.7B representa um avanço significativo no desenvolvimento de modelos de linguagem grande, introduzindo uma nova abordagem para dimensionar esses modelos de forma eficiente e eficaz.
Este artigo começa explicando o que é o modelo SOLAR-10.7B antes de destacar seu desempenho em relação a outros modelos de linguagem grandes e mergulhar no processo de usar sua versão especialmente treinada. Por fim, o leitor entenderá as aplicações potenciais do modelo SOLAR-10.7B-Instruct treinado e suas limitações.
O que é o SOLAR-10.7B?
O SOLAR-10.7B é um modelo com 10,7 biliões de parâmetros desenvolvido por uma equipe na Upstage AI, na Coreia do Sul.
Baseado na arquitetura Llama-2, este modelo ultrapassa outros modelos de linguagem grandes com até 30 biliões de parâmetros, incluindo o modelo Mixtral 8X7B.
Para saber mais sobre o Llama-2, o nosso artigo Fine-Tuning LLaMA 2: Uma Guia Passo a Passo para Personalizar o Modelo de Linguagem Grande fornece uma guia passo a passo para treinar o Llama-2, usando novas abordagens para superar as limitações de memória e computação para melhor acesso a modelos de linguagem grandes de código aberto.
Além disso, com base na robusta fundação do SOLAR-10.7B, o modelo SOLAR 10.7B-Instruct é treinado com ênfase em seguir instruções complexas. Esta variante demonstra um desempenho melhorado, mostrando a adaptabilidade do modelo e a eficácia do treinamento fino em alcançar objetivos especializados.
Finalmente, o SOLAR-10.7B apresenta um método chamado Aumento de Profundidade e vamos explorar isso na seção seguinte.
O método Aumento de Profundidade
Este método inovador permite a expandir a profundidade da rede neural do modelo sem a necessidade de aumentar correspondentemente os recursos computacionais. Esta estratégia melhora tanto a eficiência quanto o desempenho global do modelo.
Elementos essenciais do Aumento de Profundidade
O Aumento de Profundidade se baseia em três componentes principais: (1) Pesos do Mistral 7B, (2) Framework Llama 2 e (3) Pré-treinamento contínuo.
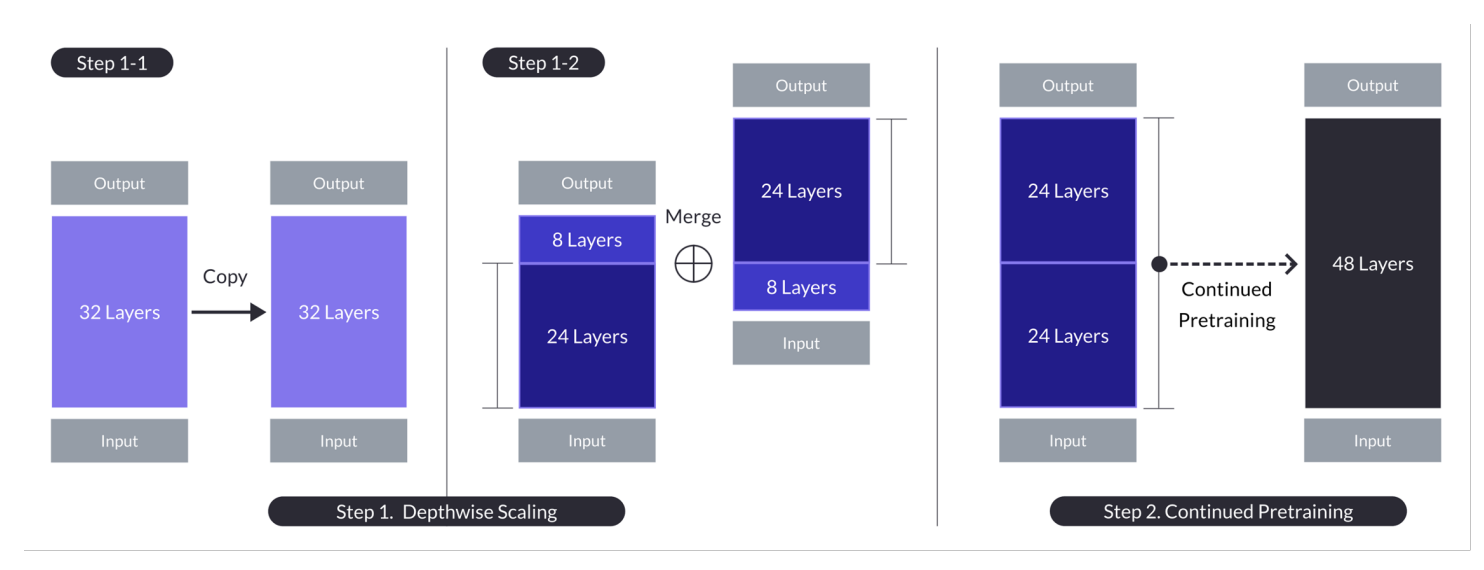
Aumento de profundidade no caso com n = 32, s = 48 e m = 8. O aumento de profundidade é alcançado através de dois processos: ajuste proporcional da profundidade seguido de pré-treinamento contínuo. (Fonte)
Modelo Base:
- Usa uma arquitetura de transformador de 32 camadas, especificamente o modelo Llama 2, inicializado com pesos pré-treinados do Mistral 7B.
- Escolhido por sua compatibilidade e desempenho, visando aproveitar recursos da comunidade e introduzir modificações inovadoras para capacidades aprimoradas.
- Serve de base para o ajuste proporcional da profundidade e para o pré-treinamento adicional para aumentar de forma eficiente.
Ajuste Proporcional de Profundidade:
- Escala o modelo base definindo um número de camadas alvo para o modelo escalado, considerando as capacidades de hardware.
- Involve duplicar o modelo de base, remover as últimas m camadas do original e as primeiras m camadas da duplicata, e então concatená-las para formar um modelo com s camadas.
- Este processo cria um modelo dimensionado com um número ajustado de camadas para se ajustar entre 7 e 13 bilhões de parâmetros, especificamente usando uma base de n=32 camadas, removendo m=8 camadas para alcançar s=48 camadas.
Continuação do Pre-treinamento:
- Aborda a queda inicial no desempenho após a escala depthwise, continuando o pré-treinamento do modelo dimensionado.
- Foi observada uma rápida recuperação de desempenho durante a continuação do pré-treinamento, o que foi atribuído à redução da heterogeneidade e das discrepâncias no modelo.
- A continuação do pré-treinamento é crucial para recuperar e potencialmente superar o desempenho do modelo de base, aproveitando a arquitetura do modelo dimensionado por profundidade para um aprendizado efetivo.
Esses resumos destacam as estratégias chave e resultados do método de Escala de Profundidade, concentrando-se em aproveitar modelos existentes, dimensionar através da ajuste de profundidade e melhorar o desempenho por meio de continuação de pré-treinamento.
Essa abordagem multifacetada SOLAR-10.7B alcança e, na maioria dos casos, supera as capacidades de modelos muito maiores. Essa eficiência o torna uma escolha primária para uma ampla gama de aplicações específicas, destacando sua força e flexibilidade.
Como funciona o modelo de instrução SOLAR 10.7B?
SOLAR-10.7B instrução se destaca na interpretação e execução de instruções complexas, tornando-se incrivelmente valioso em cenários onde compreensão precisa e respostas a comandos humanos são cruciais. Essa capacidade é essencial para o desenvolvimento de sistemas AI mais intuitivos e interativos.
- A instrução SOLAR 10.7B resulta do ajuste fino do modelo original SOLAR 10.7B para seguir instruções no formato QA.
- O ajuste fino utiliza principalmente conjuntos de dados de código aberto, juntamente com conjuntos de dados sintetizados de QA matemática para melhorar as habilidades matemáticas do modelo.
- A primeira versão do SOLAR 10.7B instrução é criada integrando os pesos Mistral 7B para fortalecer suas capacidades de aprendizado para processamento eficaz e eficiente de informações.
- A estrutura de base do SOLAR 10.7B é a arquitetura Llama2, que fornece uma mistura de velocidade e precisão.
No geral, a importância do modelo ajustado SOLAR-10.7B reside em seu desempenho aprimorado, adaptabilidade e potencial para uma ampla aplicação, levando adiante os campos de processamento de linguagem natural e inteligência artificial.
Aplicações Potenciais do Modelo Fine-Tuned SOLAR-10.7B
Antes de mergulhar na implementação técnica, vamos explorar algumas das aplicações potenciais de um modelo ajustado SOLAR-10.7B.
Abaixo estão alguns exemplos de educação personalizada e tutoriais, suporte ao cliente aprimorado e criação automática de conteúdo.
- Educação personalizada e tutoria: O SOLAR-10.7B-Instruct pode revolucionar o setor educacional oferecendo experiências de aprendizagem personalizadas. Ele pode compreender consultas complexas de alunos, oferecendo explicações, recursos e exercícios personalizados. Essa capacidade torna-o numa ferramenta ideal para o desenvolvimento de sistemas de tutoria inteligentes que se adaptam aos estilos e necessidades de aprendizagem individuais, melhorando o engajamento e os resultados dos alunos.
- Melhor suporte ao cliente: O SOLAR-10.7B-Instruct pode impulsionar chatbots avançados e assistentes virtuais capazes de compreender e resolver inquéritos complexos de clientes com alta precisão. Essa aplicação não apenas melhora a experiência do cliente oferecendo suporte oportuno e relevante, mas também reduz a carga de trabalho nos representantes de serviço ao cliente humanos ao automatizar consultas rotineiras.
- Criação e resumo de conteúdo automatizados: Para os meios de comunicação e criadores de conteúdo, o SOLAR-10.7B-Instruct oferece a capacidade de automatizar a geração de conteúdo escrito, como artigos de notícias, relatórios e escrita criativa. Além disso, ele pode resumir documentos extensos em formatos concisos e fáceis de entender, tornando-se valioso para jornalistas, pesquisadores e profissionais que precisam Assimilar e relatar rapidamente grandes volumes de informação.
Esses exemplos destacam a versatilidade e o potencial do SOLAR-10.7B-Instruct para impactar e melhorar a eficiência, acessibilidade e experiência do usuário em uma ampla gama de indústrias.
Uma Guia Passo a Passo para Usar o SOLAR -10.7B Instruct
Nós temos o suficiente de fundo sobre o modelo SOLAR-10.7B e é hora de colocar as mãos na massa.
Esta seção visa fornecer todas as instruções para executar o modelo SOLAR 10.7 Instruct v1.0 – GGUF a partir de upstage.
Os códigos são inspirados pela documentação oficial de Hugging Face. Os passos principais são definidos abaixo:
- Instalar e importar as bibliotecas necessárias
- Definir o modelo SOLAR-10.7B para uso de Hugging Face
- Executar a inferência do modelo
- Gerar o resultado a partir da solicitação do usuário
Instalação de Bibliotecas
As principais bibliotecas usadas são transformers e accelerate.
- A biblioteca transformers fornece acesso a modelos pré-treinados e a versão especificada aqui é 4.35.2.
- A biblioteca accelerate está projetada para simplificar a execução de modelos de aprendizado de máquina em diferentes hardware (CPUs, GPUs) sem precisar entender detalhes específicos do hardware.
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
Importar Bibliotecas
Agora que a instalação está concluída, procedemos importando as seguintes bibliotecas necessárias:
- torch é a biblioteca PyTorch, uma biblioteca de aprendizado de máquina aberta e popular usada para aplicações como visão computacional e NLP.
- AutoModelForCausalLM é usado para carregar um modelo pré-treinado para modelagem de linguagem causal, e AutoTokenizer é responsável por converter o texto em um formato que o modelo pode entender (tokenização).
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
Configuração da GPU
O modelo sendo utilizado é a versão 1 do modelo SOLAR-10.7B da Hugging Face.
Uma resource de GPU é necessária para acelerar o processo de carregamento e inferência do modelo.
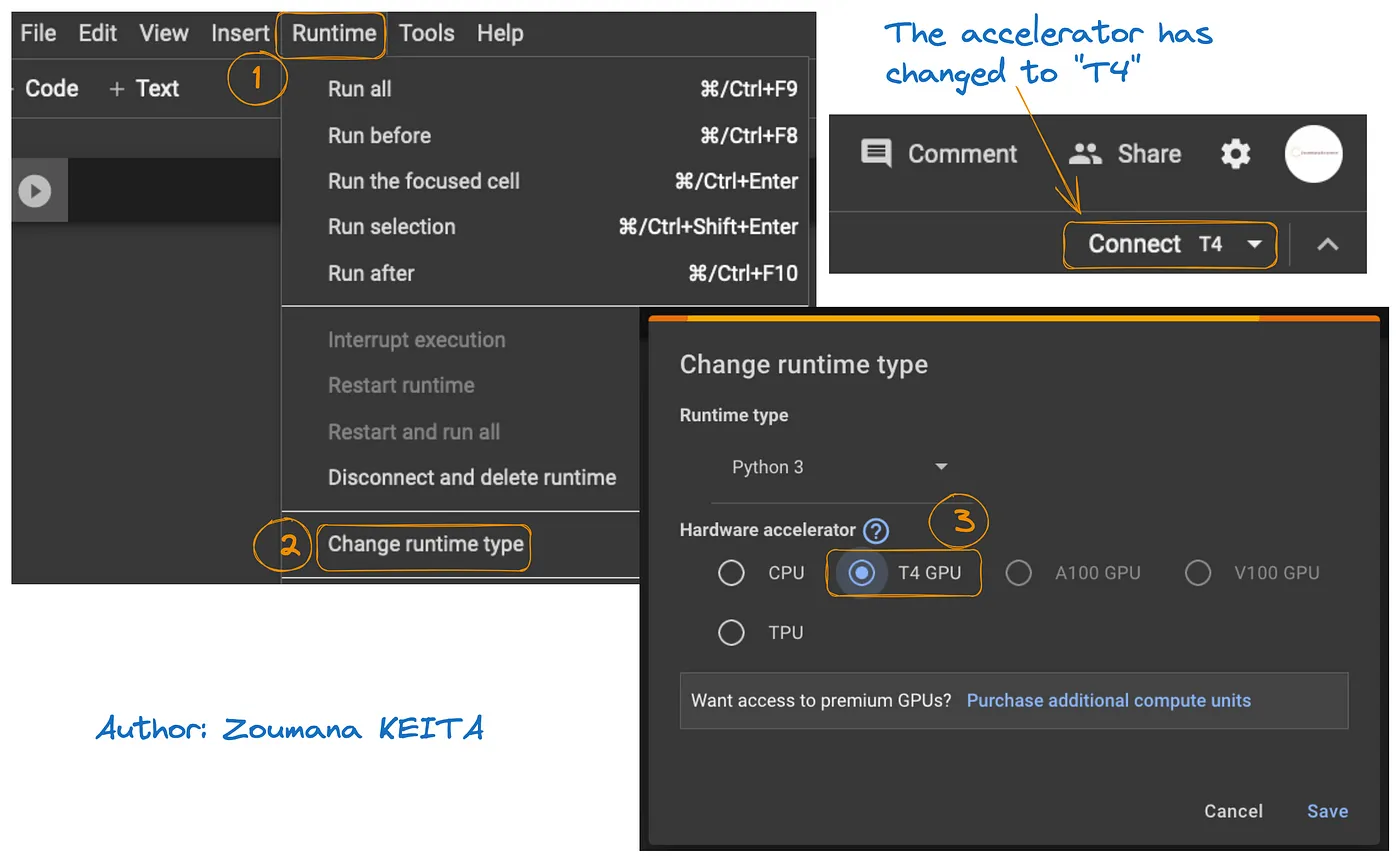
O acesso à GPU no Google Colab é ilustrado no gráfico abaixo:
- Na guia Runtime, selecione Change runtime
- Em seguida, escolha T4 GPU na seção de acelerador de hardware e Save as alterações
Isso irá trocar o runtime padrão para T4:
Podemos verificar as propriedades do runtime executando o seguinte comando no notebook do Colab.
!nvidia-smi
Propriedades da GPU
Definição do modelo
Tudo está configurado; podemos prosseguir com o carregamento do modelo da seguinte forma:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID é uma string que identifica exclusivamente o modelo pré-treinado que desejamos usar. Neste caso, “Upstage/SOLAR-10.7B-Instruct-v1.0” é especificado.
- AutoTokenizer.from_pretrained(model_ID) carrega um tokenizador pré-treinado no model_ID especificado, preparando-o para processar a entrada de texto.
- AutoModelForCausalLM.from_pretrained() carrega o próprio modelo de linguagem causal, com device_map=”auto” para usar automaticamente o melhor hardware disponível (a GPU que configuramos), e torch_dtype=torch.float16 para usar números de ponto flutuante de 16 bits para economizar memória e potencialmente acelerar os cálculos.
Inferência do modelo
Antes de gerar uma resposta, o texto de entrada (pedido do usuário) é formatado e tokenizado.
- user_request contém a pergunta ou entrada para o modelo.
- conversation formata a entrada como parte de uma conversa, marcando-a com uma função (por exemplo, ‘user’).
- apply_chat_template aplica um modelo de conversação à entrada, preparando-a no formato compreendido pelo modelo.
- tokenizer(prompt, return_tensors=”pt”) converte a entrada em tokens e especifica o tipo de tensor (“pt” para tensores do PyTorch), e .to(model.device) garante que a entrada esteja no mesmo dispositivo (CPU ou GPU) que o modelo.
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
Gereração de resultados
A seção final usa o modelo para gerar uma resposta à pergunta de entrada e então decodifica e imprime o texto gerado.
- model.generate() gera texto com base nas entradas fornecidas, com use_cache=True para acelerar a geração reutilizando resultados computados anteriormente. max_length=4096 limita a comprimento máximo do texto gerado.
- tokenizer.decode(outputs[0]) converte os tokens gerados de volta em texto legível por humanos.
- print instrução exibe a resposta gerada à pergunta do usuário.
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
A execução bem-sucedida do código acima gera o seguinte resultado:

Ao substituir a solicitação do usuário pelo seguinte texto, obtemos a resposta gerada
user_request = "Tell me a story about the universe"

Limitações do modelo SOLAR-10.7B
Apesar de todos os benefícios do SOLAR-10.7B, ele tem suas próprias limitações, como qualquer outro grande modelo de linguagem, e as principais são destacadas abaixo:
- Exploração detalhada de hipérparametros: a necessidade de uma exploração mais detalhada de hipérparametros do modelo durante a Escalação na Profundidade (DUS) é uma limitação chave. Isso resultou na remoção de 8 camadas do modelo básico devido a limitações de hardware.
- Demanda computacional significativa: o modelo é significativamente exigente em recursos computacionais, limitando seu uso por indivíduos e organizações com capacidades computacionais inferiores.
- Vulnerabilidade à biências: potenciais biases no conjunto de treinamento podem afetar o desempenho do modelo em algumas aplicações.
- Preocupação ambiental: o treinamento e a inferência do modelo requerem significativa consomção de energia, o que pode originar preocupações ambientais.
Conclusão
Este artigo explorou o modelo SOLAR-10.7B, destacando sua contribuição à inteligência artificial através da abordagem de escalação na profundidade. Ele descreveu o funcionamento do modelo e suas aplicações potenciais e forneceu um guia prático para seu uso, desde a instalação até a geração de resultados.
Apesar de suas capacidades, o artigo também abordou as limitações do modelo SOLAR-10.7B, garantindo uma perspectiva bem-rounded para os usuários. Com a evolução da IA, o SOLAR-10.7B exemplifica os passos dados em direção a ferramentas AI mais acessíveis e versáteis.
Tutorial FLAN-T5: Guia e Ajuste Fino, para aqueles que desejam mergulhar mais fundo no potencial da AI, oferece um guia completo para o ajuste fino de um modelo FLAN-T5 para uma tarefa de resposta a perguntas usando a biblioteca transformers e executando inferência otimizada em um cenário real-world. Você também pode encontrar nosso tutorial Ajuste Fino do GPT-3.5 e nosso código acompanhado em ajustar seu próprio modelo LlaMA 2.
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial