













ユーザーが重要なデータにアクセスする数が非常に多い大規模な組織は、細かいアクセス管理に多くの課題に直面しなければなりません。
IAM、Lake Formation、およびS3 ACLなどのさまざまなAWSサービスは、細かいアクセス制御に役立ちます。ただし、単一のエンティティにグローバルデータが含まれ、システム全体で複数のユーザーグループが制限付きのアクセスでアクセスする必要があるシナリオもあります。また、グローバルなプレゼンスを持つ組織は異なる環境で作業し、異なるツールセットを使用している可能性があるため、データの移動とカタログ作成が非常に手間がかかります。
たとえば、ユーザーが分析目的でテーブルから売上データにアクセスしたいが、オーストラリア地域関連の売上データにのみアクセスすることが制限されるべきです。他のデータは彼には表示されてはいけません。また、異なるクラウドプラットフォームからデータにアクセスし、複数のDML操作を行いたい場合があります。そのため、データを取り込んで処理のためにツールのネイティブフォーマットに変換する必要があり、遅延が発生します。
このようなシナリオでは、属性レベルでのデータ制御と、ネイティブツールセットフォーマットをサポートし、迅速なアクセスを実現するために、異なる環境間でのデータが必要です。
これらの課題に対処し、Apache IcebergテーブルでのデータガバナンスにLake Formationを活用したクラウド変換ソリューションを提供するために一歩前進しました。これにより、AWS S3自体でクエリおよびカタログ化され、さまざまなプラットフォームやクラウドでアクセスできるようになりました。
Lake Formationのデータフィルターオプションを使用することで、列レベルのセキュリティ、行レベルのセキュリティ、セルレベルのセキュリティを確保できます。
Icebergテーブルフォーマットとは?
Icebergは、以下の利点を持つオープンソースのテーブルフォーマットです:
- Icebergは柔軟なSQLコマンドを完全にサポートしており、データの更新、マージ、削除が可能です。 Icebergはデータファイルを再構成して読み取りパフォーマンスを向上させるために使用でき、削除デルタを使用して更新のペースを速めることができます。
- Icebergは完全なスキーマ進化をサポートしています。 Icebergテーブルのスキーマ更新はメタデータのみを変更し、データファイル自体には影響を与えません。スキーマ進化の変更には、追加、削除、名前変更、並べ替え、型昇格が含まれます。
- データレイクやデータメッシュアーキテクチャに格納されたデータは、組織全体で複数の独立したアプリケーションから同時に利用できます。
- Icebergは巨大な解析データセットに使用するために設計されています。高速なクエリ処理速度と効率を向上させるために、高速スキャンプランニング、不要なメタデータファイルの削減、および一致データを含まないデータファイルをフィルタリングする機能など、複数の機能を提供しています。
ソリューション概要
提案されているソリューションは、ユーザーにアクセス権を付与できるデータフィルターを作成するためにLake Formationサービスを使用することです。ソリューションの中心にはIcebergテーブル形式の使用があり、それがカタログ化され、アクセスを管理するためにフィルター条件が追加されます。

データフロー
- DMSまたはGlueを使用して、ソースシステムリポジトリからデータを取得し、指定されたS3バケットに保存します。
- イベントベースのアーキテクチャは、S3がプッシュするとイベントをトリガーし、対応するLambda関数を呼び出してETLプロセスを開始します。
- データはIcebergテーブル形式で保存され、カタログ化されます。
- Glueを使用してデータを処理および変換し、GenAIの既製モデルを活用できます。
- 処理されたデータはRedshiftに保存され、消費されます。
- カタログ化されたIcebergテーブルにはタグ列(タグ値がユーザーグループにマッピングされています)が追加されます。
以下の画像はサンプルデータフィルターとその表示方法を示しています。データフィルターを使用して列の数を制限することもできます。
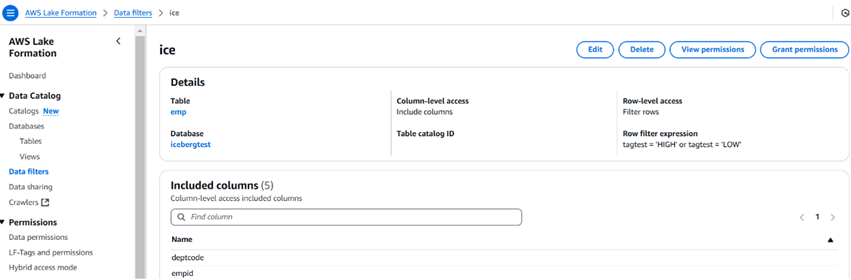
フィルターを作成したら、権限をユーザー、ロール、グループ、およびアカウントに付与するために権限付与オプションを使用できます。ユーザーはAthenaを使用してデータをクエリできます。
私たちのソリューションのさまざまな機能は次のとおりです:
- データへのアクセスの微細な制御を効果的に管理する機能。
- データフィルターの再利用が複数のユーザーグループに対応しています。
- 列レベルのセキュリティ、行レベルのセキュリティ、およびセルレベルのセキュリティを実現できます。
- Apache Icebergテーブル形式の機能を効果的に活用し、データとそのアクセスをシームレスに制御します。
- データ準備の効率性と効果を実現します。
- レイクフォーメーションを使用した中央集中型のアクセス管理とガバナンス。
- 完全に統合されたソリューションにおける手作業の介入の削減。
- クラウドに依存しないソリューションとサーバーレスコンポーネントを使用したエンドツーエンドのデータ配信により、拡張性とコスト効率を提供します。
利点
- 運用効率。サーバーレスコンポーネントの使用により、運用およびメンテナンスにかかるオーバーヘッドが削減されます。
- 作業の最適化。GenAIモデルを使用して標準化され効率的なETLスクリプトを生成することで、作業量を20〜30%削減できます。
- ガバナンスとコンプライアンスの利点。レイクフォーメーションでの属性ベースの制御は、標準規制を遵守し、監査とログ記録の機能を提供します。
産業利用
Apache Icebergテーブルを使用した属性レベルのガバナンスは、銀行や保険会社などの金融部門で非常にシームレスに実装でき、顧客がデータに制限されたアクセス権を持ち、データの信頼性とセキュリティを確保できます。医療部門では、データの感度を確保し、迅速な方法で患者の電子健康記録を生成および共有するために使用でき、これにより適時な治療と薬物療法が可能になります。
結論
したがって、全体的なソリューションは、Apache Icebergテーブル形式を使用してスケールで属性レベルのガバナンスを提供し、最適なコストと無制限のスケーラビリティを提供するAmazon Cloudサービスを活用してソリューションを実装することで、データの準備を迅速に行う必要があります。
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables