













紹介
読者の皆様、これはPyTorchについてのシリーズの別の記事です。この記事は、PyTorchの基本を熟悉しているユーザーに向けて、 intermediate levelに移行したいと考えている人の為のものです。以前の記事では、基本的な分類器の実装方法を説明しましたが、この記事では、PyTorchを用いたより複雑な deep learning機能の実装方法について話します。この記事の目的は、以下の点について理解することです。
-
PyTorchのクラスとしての
nn.Module、nn.Functional、nn.Parameterの違いと、どのようにして使用するか。 -
トレーニングオプションのカスタマイズ方法、层ごとに異なる学習率、異なる学習率スケジュールの使用。
-
重みの初期化のカスタマイズ。
では、始めましょう。
nn.Moduleとnn.Functionalの違い
これは、オープンソースコードを読んでいる际によく出てくることです。PyTorchでは、層はよくtorch.nn.Moduleオブジェクトのように実装されますが、torch.nn.Functional関数としても実装できます。どちらを使用するのか?どちらがより良いのか?
第2節で触れたように、torch.nn.Moduleは基本的にPyTorchの基石です。これは、まずnn.Moduleオブジェクトを定義し、次にそれのforwardメソッドを呼び出して実行する方法で機能します。これはオブジェクト指向の方法です。
他方で、nn.functionalは、オブジェクトを定義する代わりに入力に直接呼び出される関数形式のレイヤー/アクティベーションを提供します。たとえば、画像テンソルを再スケールするためには、画像テンソルにtorch.nn.functional.interpolateを呼び出す必要があります。
では、何を使用すべきかということはどうしますか?レイヤー/アクティベーション/損失が損失を持つ場合。
状態保持の理解
通常、どのレイヤーも関数として考えることができます。たとえば、畳み込み操作は単に乗法と加法操作の一連です。したがって、関数として実装することは合理的ですが、まあ待て、レイヤーは重みを持ち、学習中に保持と更新する必要があります。したがって、プログラマー的な観点から、レイヤーは関数以上のものであり、学習していくネットワークによって変化するデータを保持する必要があります。
今、畳み込み層が保持するデータが変化するという点に強調してほしいです。つまり、層にはトレーニング中に変化する状態があります。畳み込み演算を行う関数を実装するためには、関数自体から重みを別々に保持するデータ構造を定義する必要があります。そして、この外部データ構造を関数の入力にします。
手間を省くために、データ構造を保持するクラスを定義し、畳み込み演算をメンバー関数として実装することもできます。これにより、関数の外に状態変数が存在することを心配する必要がありません。このような場合には、層の挙動を定義する重みや他の状態がある場合には、nn.Moduleオブジェクトを使用することを好みます。たとえば、ドロップアウト/バッチ正規化層は、トレーニングと推論中で異なる動作をします。
一方で、状態や重みが必要ない場合には、nn.functionalを使用できます。例えば、リサイズ(nn.functional.interpolate)、平均プーリング(nn.functional.AvgPool2d)などがあります。
上記の理由にもかかわらず、ほとんどのnn.Moduleクラスには、それに対応するnn.functionalが存在します。ただし、実践的な作業中には上記の理論に敬意を払う必要があります。
nn.Parameter
PyTorchの重要なクラスの1つは、nn.Parameterクラスです。驚いたことに、PyTorchの入門的な文書においてはほとんど取り上げられていません。以下のようなケースを考えてみましょう。
各nn.Moduleにはparameters()関数があり、これは、よく知られているように、学習可能なパラメータを返します。私たちはこれらのパラメータを隐して定義する必要があります。nn.Conv2dの定義で、PyTorchの作者はそのレイヤーの重みと偏差をパラメータとして定義しました。しかし、注意してください、netを定義する際に、nn.Conv2dのparametersをnetのparametersに追加する必要はありません。nn.Conv2dオブジェクトをnetオブジェクトのメンバーとして設定することで、implicitlyに行われます。
これは内部にnn.Parameterクラスによってサポートされています。nn.Moduleオブジェクトのparameters()関数を呼び出すと、それのすべてのメンバーがnn.Parameterオブジェクトであることを返します。
事実、nn.Moduleクラスのすべての学習重みはnn.Parameterオブジェクトとして実装されています。どこからでもnn.Module(私たちの場合はnn.Conv2d)が他のnn.Moduleのメンバーとして割り当てられると、割り当てられる対象の「パラメータ」(つまりnn.Conv2dの重み)も「netオブジェクトのパラメータ」に加わります。これは「nn.Moduleのパラメータ」を登録することと呼ばれます。
nn.Moduleにテンサーを割り当てようとすると、parameters()にはnn.Parameterとして定義されていない限り表示されません。これは、RNNの場合に前の出力をキャッシュする必要があるなど、非微分可能なテンサーをキャッシュする必要があるシーンをサポートするために行われています。
nn.ModuleListとnn.ParameterList()
PyTorchでYOLO v3を実装した際にはnn.ModuleListを使用しました。構造を含むテキストファイルを解析してネットワークを作成する必要がありました。すべてのnn.ModuleオブジェクトをPythonのリストに保存し、そのリストをネットワークを表すnn.Moduleオブジェクトのメンバーにしました。
簡単に言うと、このようなものです。
個々のモジュールを登録する代わりに、Pythonのリストを割り当てると、リスト内のモジュールのパラメーターを登録しないことに注意してください。これを修正するために、私たちはnn.ModuleListクラスでリストを包み、それをネットワーククラスのメンバーとして割り当てます。
同様に、nn.ParameterListクラスに包まれたリスト内のテンサーを登録することもできます。
重み初期化
重み初期化は、学習の結果に影響を与える可能性があります。さらに、さまざまな種類のレイヤーに适した異なる重み初期化方法を必要とする場合があるかもしれません。これはmodulesとapply機能を使用できます。modulesはnn.Moduleクラスのメンバー関数であり、nn.Module関数のすべてのnn.Moduleメンバーを含むイテレータを返します。そして、各nn.Moduleにapply機能を呼び出して、初期化を設定することができます。
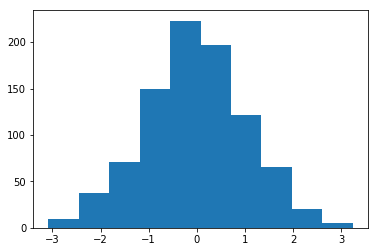
平均値=1、標準偏差=1で初期化された重みのヒストグラム
torch..nn.initモジュールには、さまざまなinplace初期化関数が見つかります。
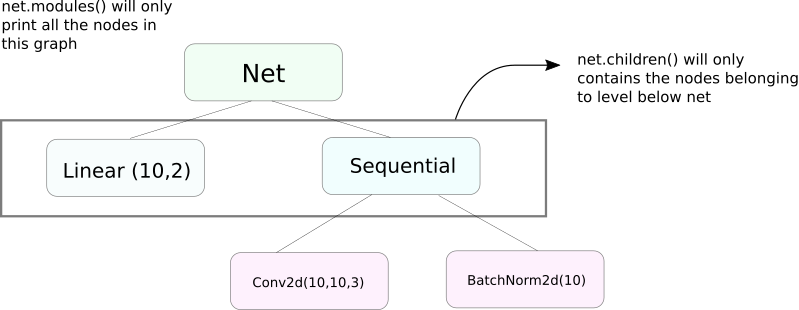
modules() vs children()
modulesとchildrenとは非常に似た機能ですが、微妙な差があります。私たちはnn.Moduleオブジェクトには他のnn.Moduleオブジェクトがデータメンバーとして含まれることがあることを知っています。
children()は、childrenが呼び出されているオブジェクトのデータメンバーとしてのnn.Moduleオブジェクトのリストを返します。
その一方、nn.Modulesは各nn.Moduleオブジェクトに深入りし、それぞれのnn.Moduleオブジェクトのリストを作成します。これはnn.moduleオブジェクトが残っていないまで続きます。modules()はまた、呼び出されたnn.Moduleをリストの一部として返します。
上記の声明は、nn.Moduleクラスをサブクラス化したすべてのオブジェクト/クラスにも適用されます。
なので、重みを初期化する際にはmodules()関数を使用したい場合があります。なぜなら、nn.Sequentialオブジェクトの内部に入り込んで重みを初期化することができないからです。
ネットワークに関する情報の印刷
ネットワークに関する情報を印刷する必要があるかもしれません。印刷する情報がユーザー用であれ、デバッグ目的であれ、PyTorchはnamed_*関数を使用して、ネットワークに関する多くの情報を取得する非常に便利な方法を提供しています。これらの関数は4つあります。
named_parameters関数は、イテレータを返し、パラメーターの名前(例えばself.conv1に畳み込み層が割り当てられている場合、それのパラメーターはconv1.weightとconv1.bias)と、nn.Parameterの__repr__関数の返り値を与えることができます。
2. named_modules関数は、同じですが、イテレータはmodules()関数のようにモジュールを返します。
3. named_children関数は、同じですが、イテレータはchildren()関数のようにモジュールを返します。
4. named_buffers関数は、例えばBatch Norm層のrunning meanなどのバッファテンソルを返します。
層ごとに異なる学習率
この節では、異なる学習率を異なる層に使用する方法を学びます。一般的には、異なる学習率を異なる層に使用すること、またはBIASと重みに異なる学習率を使用することをカバーします。
このような実装のアイデアは相当にシンプルです。先日の投稿で、CIFAR分类器を実装しましたが、そこでは、ネットワークのすべてのパラメータを Optimizer オブジェクトに一度に渡しました。
しかし、`torch.optim` クラスは、学習率が異なる複数のパラメーター集合を辞書形式で与えることができます。
上記のシーンでは、`fc1`のパラメーターは学習率0.01、モーメントum0.99を使用しています。パラメーターのグループに対するハイパーパラメータが指定されていない場合(如く`fc2`)、それらはOptimizer関数に与えられた入力引数で与えられたハイパーパラメータのデフォルト値を使用します。分层ごとのパラメーターリストを作成するか、パラメーターが重みかバイアスかによって、先ほど述べた`named_parameters()`関数を使用してください。
学習率スケジューリング
学習率をスケジュールすることは、調整する必要がある主要なハイパーパラメータです。PyTorchは、学習率のスケジュールをサポートしており、これには様々な学習率スケジュールが含まれています。以下の例は、そのような例の一つを示しています。
上記のスケジューラは、milestonesリストに含まれるエポックに到达するたびに、学習率をgamma倍します。私たちの場合、学習率は第10エポックと第20エポックに0.1倍されます。学習率の更新を行うために、scheduler.stepを自己破壊的なコードのepochに対するループに書く必要があります。
一般的に、トレーニングループは2つの内包したループからなされており、1つのループはepochを回し、内包したもう1つのループはそのepochのbatchを回します。epochの開始時にscheduler.stepを呼び出してください、そうすると学習率が更新されます。batchのループに書かないでください、そうすると学習率が第10batchではなく第10epochで更新されるからです。
また、scheduler.stepはoptim.stepの代わりにはならないことを忘れないでくださいが、バックプロップ後にoptim.stepを呼び出す必要があります。(これは”batch”ループである)。
モデルの保存
後で推論に使用するか、トレーニングチェックポイントを作成したい場合には、モデルを保存したいことがあるかもしれません。PyTorchでモデルを保存する際には2つの選択肢があります。
第1の選択肢はtorch.saveを使用することです。これはnn.ModuleオブジェクトをPickleを使用して序列化すると同等です。これにより、整个なモデルをディスクに保存します。このモデルを後でメモリに読み込むことができます。torch.loadを使用します。
上記は、重みとアーキテクチャを含んだ全てのモデルを保存します。もし、ただ重みだけを保存したい場合は、全てのモデルを保存する代わりに、モデルのstate_dictだけを保存することができます。state_dictは、基本的には、ネットワークのnn.Parameterオブジェクトをその値に対応する辞書です。
上記のように示されるように、既存のstate_dictをnn.Moduleオブジェクトに読み込むことができます。注意してください、これはモデル全体の保存ではなく、ただのパラメーターだけを保存しています。state dictを読み込む前に、層のあるネットワークを作成する必要があります。保存したstate_dictを持ったネットワークのアーキテクチャが正確に同じでない場合、PyTorchはエラーを投げます。
torch.optimからの最適化オブジェクトには、最適化アルゴリズムのハイパーパラメーターを保存するstate_dictオブジェクトもあります。これも、上記のように、最適化オブジェクトにload_state_dictを呼び出すことで、同様に保存したり読み込んだりすることができます。
結論
これで、PyTorchのより高度な機能についての讨论は終了しました。この記事で読んだことが、皆さんが考え出した複雑なディープラーニングアイデアを実装する上で役立つことを期待しています。もしより詳細な情報を探すことが興味があれば、以下のリンクをご参照ください。
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced