













Come discusso nel mio articolo precedente sull’architetture dei dati che enfatizzano le tendenze emergenti, il trattamento dei dati è uno dei componenti chiave nella moderna architettura dei dati. Questo articolo discute varie alternative alla libreria Pandas per ottenere migliori prestazioni nella tua architettura dei dati.
Il trattamento dei dati e l’analisi dei dati sono compiti cruciali nel campo della scienza e dell’ingegneria dei dati. Con l’aumentare delle dimensioni e della complessità dei set di dati, strumenti tradizionali come pandas possono avere difficoltà con le prestazioni e la scalabilità. Questo ha portato allo sviluppo di diverse librerie alternative, ognuna progettata per affrontare sfide specifiche nella manipolazione e nell’analisi dei dati.
Introduzione
Le seguenti librerie sono emerse come strumenti potenti per il trattamento dei dati:
- Pandas – Il tradizionale cavallo di battaglia per la manipolazione dei dati in Python
- Dask – Estende pandas per il trattamento dei dati su larga scala e distribuiti
- DuckDB – Un database analitico in-process per query SQL veloci
- Modin – Un sostituto diretto per pandas con prestazioni migliorate
- Polars – Una libreria DataFrame ad alte prestazioni costruita su Rust
- FireDucks – Un’alternativa accelerata da compilatore a pandas
- Datatable – Una libreria ad alte prestazioni per la manipolazione dei dati
Ogni una di queste librerie offre funzionalità uniche e vantaggi, adattandosi a diversi casi d’uso e requisiti di prestazioni. Esploriamo ognuna nel dettaglio:
Pandas
Pandas è una libreria versatile e consolidata nella comunità della scienza dei dati. Offre robuste strutture dati (DataFrame e Series) e strumenti completi per la pulizia e la trasformazione dei dati. Pandas eccelle nell’esplorazione e visualizzazione dei dati, con una documentazione estesa e un supporto della comunità.
Tuttavia, affronta problemi di prestazioni con grandi set di dati, è limitato a operazioni single-threaded e può avere un alto utilizzo della memoria per grandi set di dati. Pandas è ideale per set di dati di dimensioni piccole o medie (fino a qualche GB) e quando sono richieste manipolazioni e analisi estese dei dati.
Dask
Dask estende pandas per l’elaborazione di dati su larga scala, offrendo il calcolo parallelo su più core CPU o cluster e la computazione out-of-core per dataset più grandi della RAM disponibile. Scala le operazioni di pandas ai big data e si integra bene nell’ecosistema PyData.
Tuttavia, Dask supporta solo una parte dell’API di pandas e può essere complesso da configurare e ottimizzare per il calcolo distribuito. È più adatto per l’elaborazione di dataset estremamente grandi che non rientrano in memoria o richiedono risorse di calcolo distribuito.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
Per una migliore performance, carica i dati con Dask usando
dd.from_dict(data, npartitions=4al posto del dataframe di Pandasdd.from_pandas(df_pandas, npartitions=4)
Output
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB è un database analitico in-process che offre query analitiche veloci utilizzando un motore di query vettorializzato per colonne. Supporta SQL con funzionalità aggiuntive e non ha dipendenze esterne, rendendo la configurazione semplice. DuckDB fornisce prestazioni eccezionali per le query analitiche e si integra facilmente con Python e altri linguaggi.
Tuttavia, non è adatto per carichi di lavoro transazionali ad alto volume e ha opzioni di concorrenza limitate. DuckDB eccelle nei carichi di lavoro analitici, specialmente quando le query SQL sono preferite.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
Output
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin mira a essere un sostituto diretto di pandas, utilizzando più core CPU per un’esecuzione più veloce e scalando le operazioni di pandas su sistemi distribuiti. Richiede modifiche minime al codice per essere adottato e offre il potenziale per miglioramenti significativi della velocità su sistemi multi-core.
Tuttavia, Modin potrebbe avere miglioramenti delle prestazioni limitati in alcuni scenari ed è ancora in fase di sviluppo attivo. È ideale per gli utenti che cercano di accelerare i flussi di lavoro esistenti di pandas senza grandi modifiche al codice.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
Output
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars è una libreria DataFrame ad alte prestazioni costruita su Rust, caratterizzata da un layout di memoria colonnare efficiente e un’API di valutazione pigra per una pianificazione delle query ottimizzata. Offre una velocità eccezionale per le attività di elaborazione dei dati e scalabilità per gestire grandi dataset.
Tuttavia, Polars ha un’API diversa da pandas, richiedendo un certo apprendimento, e potrebbe avere difficoltà con dataset estremamente grandi (oltre 100 GB). È ideale per data scientist e ingegneri che lavorano con dataset di medie e grandi dimensioni che danno priorità alle prestazioni.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
Output
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks offre piena compatibilità con l’API di pandas, esecuzione multi-threaded e esecuzione pigra per un’ottimizzazione efficiente del flusso di dati. Dispone di un compilatore runtime che ottimizza l’esecuzione del codice, fornendo miglioramenti significativi delle prestazioni rispetto a pandas. FireDucks consente un’adozione facile grazie alla sua compatibilità con l’API di pandas e all’ottimizzazione automatica delle operazioni sui dati.
Tuttavia, è relativamente nuovo e potrebbe avere meno supporto della comunità e una documentazione limitata rispetto a librerie più consolidate.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
Output
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Datatable
Datatable è una libreria ad alte prestazioni per la manipolazione dei dati, caratterizzata da un’archiviazione dei dati orientata alle colonne, un’implementazione in C nativa per tutti i tipi di dati e un’elaborazione dei dati multi-thread. Offre una velocità eccezionale per i compiti di elaborazione dei dati, un uso efficiente della memoria ed è progettata per gestire grandi set di dati (fino a 100 GB). L’API di Datatable è simile a quella di data.table di R.
Tuttavia, ha una documentazione meno completa rispetto a pandas, meno funzionalità e non è compatibile con Windows. Datatable è ideale per l’elaborazione di grandi set di dati su una singola macchina, particolarmente quando la velocità è cruciale.
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
Output
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
Confronto delle prestazioni
- Caricamento dati: 34 volte più veloce di pandas per un set di dati di 5,7 GB
- Ordinamento dati: 36 volte più veloce di pandas
- Operazioni di raggruppamento: 2 volte più veloci di pandas
Datatable si distingue in scenari che coinvolgono l’elaborazione di dati su larga scala, offrendo significativi miglioramenti delle prestazioni rispetto a pandas per operazioni come ordinamento, raggruppamento e caricamento dei dati. Le sue capacità di elaborazione multi-thread lo rendono particolarmente efficace per sfruttare i moderni processori multi-core
Conclusione
In conclusione, la scelta della libreria dipende da fattori come le dimensioni dell’insieme di dati, i requisiti di prestazioni e casi d’uso specifici. Mentre pandas rimane versatile per insiemi di dati più piccoli, alternative come Dask e FireDucks offrono soluzioni efficaci per l’elaborazione di dati su larga scala. DuckDB eccelle nelle query analitiche, Polars garantisce alte prestazioni per insiemi di dati di dimensioni medie e Modin mira a scalare le operazioni di pandas con modifiche minime al codice.
Il diagramma a barre qui sotto mostra le prestazioni delle librerie, utilizzando il DataFrame per il confronto. I dati sono normalizzati per mostrare le percentuali.
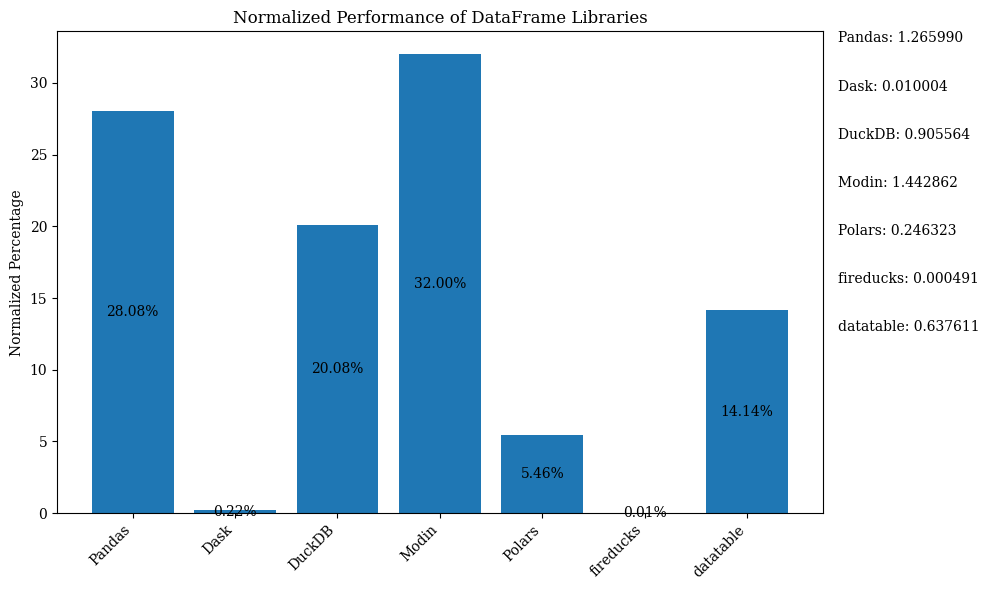
Per il codice Python che mostra il grafico a barre sopra con dati normalizzati, fare riferimento al Jupyter Notebook. Utilizzare Google Colab poiché FireDucks è disponibile solo su Linux
Tabella di Confronto
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | Moderato | Basso | N/D (Originale) | Insiemi di dati piccoli e medi, esplorazione dati | Versatilità, ecosistema ricco | Lento con insiemi di dati grandi, single-threaded |
| Dask | Alto | Molto Alto | Alto | Insiemi di dati grandi, elaborazione distribuita | Scala le operazioni di pandas, elaborazione distribuita | Configurazione complessa, supporto parziale all’API di pandas |
| DuckDB | Molto Alto | Moderato | Basso | Query analitiche, analisi basata su SQL | Query SQL veloci, facile integrazione | Non adatto per carichi di lavoro transazionali, concorrenza limitata |
| Modin | Alto | Alto | Molto alto | Accelerare i flussi di lavoro esistenti di pandas | Facile adozione, utilizzo multi-core | Miglioramenti limitati in alcuni scenari |
| Polars | Molto alto | Alto | Moderato | Set di dati medio-grandi, critici per le prestazioni | Velocità eccezionale, API moderna | Curva di apprendimento, problemi con dati molto grandi |
| FireDucks | Molto alto | Alto | Molto alto | Set di dati grandi, API simile a pandas con prestazioni | ottimizzazione automatica, compatibilità pandas | Libreria più recente, meno supporto della community |
| Datatable | Molto alto | Alto | Moderato | Set di dati grandi su singola macchina | Elaborazione veloce, uso efficiente della memoria | Funzionalità limitate, nessun supporto per Windows |
Questa tabella fornisce una rapida panoramica dei punti di forza, delle limitazioni e dei migliori casi d’uso di ciascuna libreria, consentendo un confronto facile tra diversi aspetti come prestazioni, scalabilità e similarità dell’API rispetto a pandas.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas