













Negli ultimi anni, i trasformatori hanno trasformato il NLP nel campo del machine learning. Modelli come GPT e BERT hanno stabilito nuovi standard nella comprensione e generazione del linguaggio umano. Ora lo stesso principio viene applicato al dominio della visione artificiale.
Un recente sviluppo nel campo della visione artificiale sono i vision transformers o ViTs. Come dettagliato nel documento “Un’immagine vale 16×16 parole: Trasformatori per il riconoscimento delle immagini su larga scala”, i ViTs e i modelli basati su trasformatori sono progettati per sostituire le reti neurali convoluzionali (CNN).
I Vision Transformers sono un nuovo approccio per risolvere problemi nella visione artificiale. Invece di fare affidamento sulle tradizionali reti neurali convoluzionali (CNN), che sono state il pilastro dei compiti legati alle immagini per decenni, i ViTs utilizzano l’architettura dei trasformatori per elaborare le immagini. Trattano i patch delle immagini come parole in una frase, permettendo al modello di apprendere le relazioni tra questi patch, proprio come apprende il contesto in un paragrafo di testo.
A differenza delle CNN, i ViT dividono le immagini di input in patch, le serializzano in vettori e ne riducono la dimensionalità utilizzando la moltiplicazione matriciale. Un codificatore transformer elabora quindi questi vettori come embedding di token. In questo articolo, esploreremo i vision transformers e le loro principali differenze rispetto alle reti neurali convoluzionali. Ciò che li rende particolarmente interessanti è la loro capacità di comprendere modelli globali in un’immagine, cosa con cui le CNN possono avere difficoltà.
Prerequisiti
- Fondamenti delle Reti Neurali: Comprensione di come le reti neurali elaborano i dati.
- Reti Neurali Convoluzionali (CNN): Familiarità con le CNN e il loro ruolo nella visione artificiale.
- Architettura Transformer: Conoscenza dei transformer, in particolare del loro utilizzo nell’NLP.
- Elaborazione delle Immagini: Comprensione di concetti di base come la rappresentazione delle immagini, i canali e le matrici di pixel.
- Mechanismo di Attenzione: Comprensione dell’autoattenzione e della sua capacità di modellare le relazioni tra gli input.
Cosa sono i vision transformers?
I trasformatori visivi utilizzano il concetto di attenzione e trasformatori per elaborare le immagini, simile ai trasformatori nel contesto dell’elaborazione del linguaggio naturale (NLP). Tuttavia, invece di utilizzare token, l’immagine viene suddivisa in patch e fornita come una sequenza di embedding lineari. Queste patch vengono trattate allo stesso modo in cui i token o le parole vengono trattati nell’NLP.
Invece di osservare l’intera immagine simultaneamente, un ViT taglia l’immagine in piccoli pezzi, come un puzzle. Ogni pezzo viene trasformato in un elenco di numeri (un vettore) che descrive le sue caratteristiche, e poi il modello esamina tutti i pezzi e determina come si relazionano tra loro utilizzando un meccanismo di trasformatori.
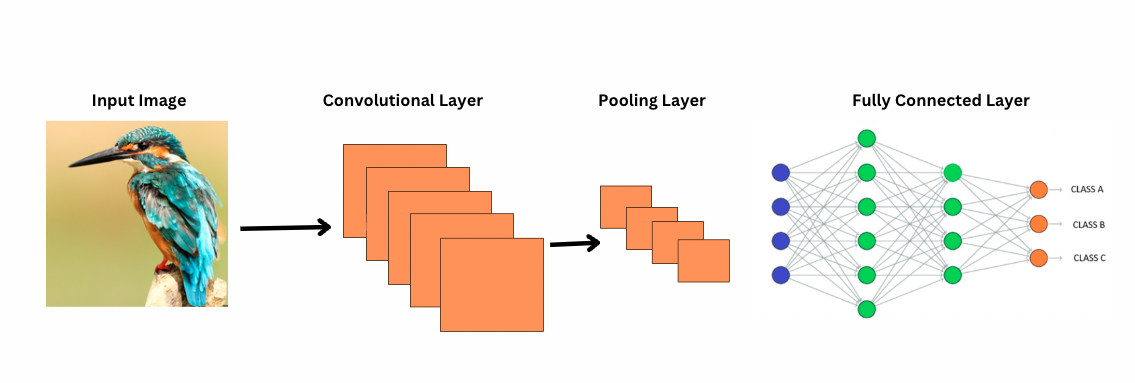
A differenza delle CNN, i ViT funzionano applicando filtri o kernel specifici su un’immagine per rilevare caratteristiche specifiche, come i modelli dei bordi. Questo è il processo di convoluzione, molto simile a una stampante che scansiona un’immagine. Questi filtri scorrono su tutta l’immagine e evidenziano caratteristiche significative. La rete quindi impila più strati di questi filtri, identificando gradualmente modelli più complessi.
Con le CNN, gli strati di pooling riducono la dimensione delle mappe delle caratteristiche. Questi strati analizzano le caratteristiche estratte per fare previsioni utili per il riconoscimento delle immagini, il rilevamento degli oggetti, ecc. Tuttavia, le CNN hanno un campo ricettivo fisso, limitando così la capacità di modellare dipendenze a lungo raggio.
Come vedono le immagini le CNN?
ViTs, nonostante abbiano più parametri, utilizzano meccanismi di auto-attenzione per una migliore rappresentazione delle caratteristiche e per ridurre la necessità di strati più profondi. Le CNN richiedono un’architettura significativamente più profonda per ottenere una potenza rappresentativa simile, il che porta a un aumento del costo computazionale.
Inoltre, le CNN non possono catturare modelli di immagine a livello globale perché i loro filtri si concentrano su regioni locali di un’immagine. Per comprendere l’intera immagine o le relazioni distanti, le CNN si basano sulla sovrapposizione di molti strati e sul pooling, espandendo il campo visivo. Tuttavia, questo processo può perdere informazioni globali poiché aggrega i dettagli passo dopo passo.
ViTs, d’altra parte, dividono l’immagine in patch che vengono trattate come token di input individuali. Utilizzando l’auto-attenzione, le ViTs confrontano tutte le patch simultaneamente e imparano come sono correlate. Ciò consente loro di catturare modelli e dipendenze sull’intera immagine senza costruirli strato per strato.
Cosa si intende per Bias Induttivo?
Prima di procedere, è importante comprendere il concetto di bias induttivo. Il bias induttivo si riferisce all’assunzione che un modello fa sulla struttura dei dati; durante l’addestramento, questo aiuta il modello a essere più generalizzato e a ridurre il bias. Nelle CNN, i bias induttivi includono:
- Località: Le caratteristiche nelle immagini (come i bordi o le texture) sono localizzate all’interno di piccole regioni.
- Struttura di vicinato bidimensionale: I pixel vicini sono più probabili di essere correlati, quindi i filtri operano su regioni spazialmente adiacenti.
- Equivarianza alla traduzione: Le caratteristiche rilevate in una parte dell’immagine, come un bordo, mantengono lo stesso significato se compaiono in un’altra parte.
Questi bias rendono le CNN altamente efficienti per i compiti legati alle immagini, in quanto sono progettate in modo intrinseco per sfruttare le proprietà spaziali e strutturali delle immagini.
I Vision Transformers (ViTs) hanno significativamente meno bias induttivi specifici per le immagini rispetto alle CNN. Nei ViTs:
- Elaborazione globale: I livelli di auto-attenzione operano sull’intera immagine, consentendo al modello di catturare relazioni globali e dipendenze senza essere vincolato da regioni locali.
- Struttura 2D minima: La struttura 2D dell’immagine è utilizzata solo all’inizio (quando l’immagine è divisa in patch) e durante il raffinamento (per regolare i posizionamenti delle incrustazioni per diverse risoluzioni). A differenza delle CNN, i ViTs non presuppongono che i pixel vicini siano necessariamente correlati.
- Relazioni spaziali apprese: Le incrustazioni posizionali nei ViTs non codificano relazioni spaziali 2D specifiche all’inizializzazione. Invece, il modello apprende tutte le relazioni spaziali dai dati durante l’addestramento.
Come funzionano i Vision Transformers
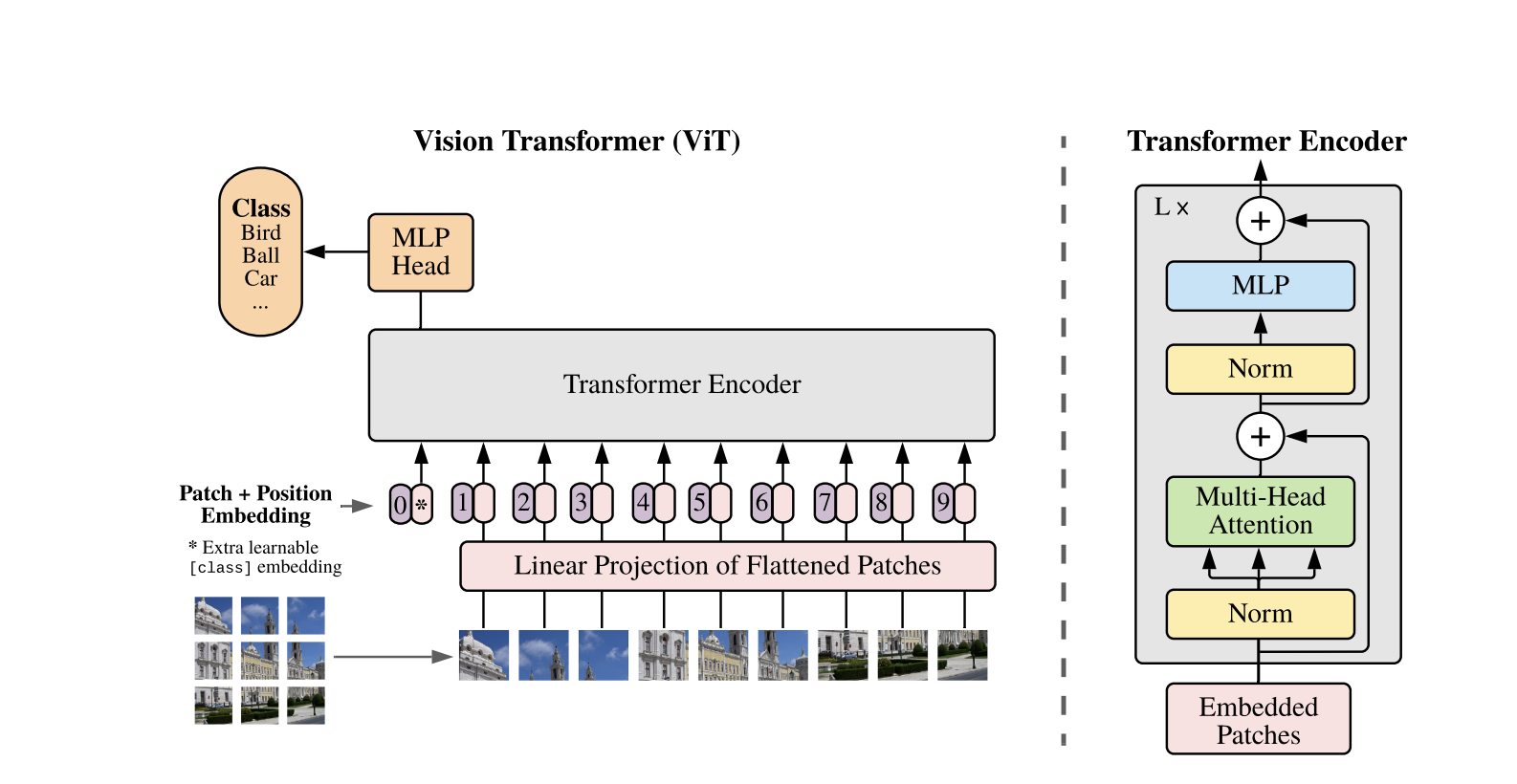
I Vision Transformers utilizzano l’architettura standard del Transformer sviluppata per sequenze di testo 1D. Per elaborare le immagini 2D, queste vengono suddivise in patch più piccole di dimensioni fisse, come ad esempio P P pixel, che vengono appiattite in vettori. Se l’immagine ha dimensioni H W con C canali, il numero totale di patch è N = H W / P P la lunghezza effettiva della sequenza di input per il Transformer. Queste patch appiattite vengono quindi proiettate linearmente in uno spazio dimensionale fisso D, chiamato gli incorporamenti delle patch.
Un token apprendibile speciale, simile al token [CLS] in BERT, viene preposto alla sequenza di incorporamenti delle patch. Questo token apprende una rappresentazione globale dell’immagine che viene successivamente utilizzata per la classificazione. Inoltre, agli incorporamenti delle patch vengono aggiunti gli incorporamenti posizionali per codificare le informazioni posizionali, aiutando il modello a comprendere la struttura spaziale dell’immagine.
La sequenza di embedding viene passata attraverso l’encoder Transformer, che alterna tra due operazioni principali: Self-Attention Multi-Head (MSA) e un network neurale feedforward, anche chiamato blocco MLP. Ogni strato include Normalizzazione di Strato (LN) applicata prima di queste operazioni e connessioni residue aggiunte successivamente per stabilizzare l’addestramento. L’output dell’encoder Transformer, nello specifico lo stato del token [CLS], viene utilizzato come rappresentazione dell’immagine.
Al token [CLS] finale viene aggiunto un semplice head per compiti di classificazione. Durante la preformazione, questo head è un piccolo perceptron multi-strato (MLP), mentre nel fine-tuning, è tipicamente uno strato lineare singolo. Questa architettura permette ai ViT di modellare efficacemente le relazioni globali tra le patch e utilizzare pienamente il potere dell’autorappresentazione per la comprensione delle immagini.
In un modello ibrido Vision Transformer, invece di dividere direttamente le immagini grezze in patch, la sequenza di input è derivata dalle mappe di caratteristiche generate da una CNN. La CNN elabora prima l’immagine, estraendo significative caratteristiche spaziali, che vengono poi utilizzate per creare le patch. Queste patch vengono appiattite e proiettate in uno spazio dimensionale fisso utilizzando la stessa proiezione lineare addestrabile dei Vision Transformers standard. Un caso speciale di questo approccio è l’utilizzo di patch di dimensioni 1×1, dove ciascuna patch corrisponde a una singola posizione spaziale nella mappa di caratteristiche della CNN.
In questo caso, le dimensioni spaziali della mappa delle caratteristiche vengono appiattite e la sequenza risultante viene proiettata nella dimensione di input del Transformer. Come per il ViT standard, un token di classificazione e degli embeddings posizionali vengono aggiunti per mantenere informazioni sulla posizione e consentire una comprensione globale dell’immagine. Questo approccio ibrido sfrutta i punti di forza dell’estrazione delle caratteristiche locali delle reti neurali convoluzionali, combinandoli con le capacità di modellazione globale dei Transformer.
Dimostrazione del Codice
Ecco il blocco di codice su come utilizzare i vision transformers sulle immagini.
Il modello ViT elabora l’immagine. Comprende un codificatore simile a BERT e un’unità di classificazione lineare posizionata sulla parte superiore dello stato nascosto finale del token [CLS].
Ecco un’implementazione di base del Vision Transformer (ViT) utilizzando PyTorch. Questo codice include i componenti principali: l’incorporamento dei patch, la codifica posizionale e l’encoder Transformer. Questo può essere utilizzato per semplici compiti di classificazione.
Componenti chiave:
- Incorporamento del patch: Le immagini vengono divise in patch più piccoli, appiattite e trasformate linearmente in incorporamenti.
- Codifica posizionale: Le informazioni posizionali vengono aggiunte agli incorporamenti dei patch, poiché i Trasformatori sono posizione-agnostici.
- Codificatore del trasformatore: Applica autoattenzione e livelli di feed-forward per apprendere le relazioni tra i patch.
- Testa di Classificazione: Restituisce le probabilità di classe utilizzando il token CLS.
È possibile allenare questo modello su qualsiasi dataset di immagini utilizzando un ottimizzatore come Adam e una funzione di perdita come l’entropia incrociata. Per prestazioni migliori, considera il preallenamento su un dataset ampio prima del raffinamento.
Lavori di Seguito Popolari
-
DeiT (Trasformatori di Immagini Efficienti nei Dati) di Facebook AI: Si tratta di trasformatori di visione allenati in modo efficiente con distillazione di conoscenza. DeiT offre quattro varianti: deit-tiny, deit-small, e due modelli deit-base. Usa
DeiTImageProcessorper preparare le immagini. -
BEiT (Pre-training di BERT di Image Transformers) di Microsoft Research: Ispirato da BERT, BEiT utilizza un modello di immagine mascherata auto-supervisionato e supera i ViTs supervisionati. Si basa su VQ-VAE per l’addestramento.
-
DINO (Addestramento di Vision Transformer auto-supervisionato) di Facebook AI: I ViTs addestrati con DINO possono segmentare gli oggetti senza addestramento esplicito. I checkpoint sono disponibili online.
-
MAE (Masked Autoencoders) di Facebook pre-addestrano ViTs ricostruendo patch mascherate (75%). Quando vengono ottimizzati, questo semplice metodo supera il pre-addestramento supervisionato.
Conclusioni
In conclusione, i ViTs sono un’ottima alternativa alle CNN poiché applicano trasformatori al riconoscimento delle immagini, minimizzano il bias induttivo e trattano le immagini come sequenze di patch. Questo approccio semplice ma scalabile ha dimostrato prestazioni all’avanguardia su molti benchmark di classificazione delle immagini, specialmente quando abbinato al pre-addestramento su grandi set di dati. Tuttavia, rimangono sfide potenziali, tra cui estendere i ViTs a compiti come il rilevamento oggetti e la segmentazione, migliorare ulteriormente i metodi di pre-addestramento auto-supervisionati ed esplorare il potenziale di scalare i ViTs per prestazioni ancora migliori.
Risorse aggiuntive
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision