













במהלך השנים האחרונות, הטרנספורמרים שינו את תחומי NLP בלמידת מכונה. מודלים כמו GPT ו־BERT הציבו סטנדרטים חדשים בהבנת ויצירת שפה אנושית. כעת העקרון הזה מיושם בתחום ראייה ממוחשבת.
פיתוח אחרון בתחום ראיית מחשב הם טרנספורמרי ראייה או ViTs. כפי שמפורט במאמר "תמונה שווה 16×16 מילים: טרנספורמרים לזיהוי תמונה בקנה מידה", ViTs ומודלים מבוססי טרנספורמר עוצבו על מנת להחליף רשתות עצבים קונבולוציונליות (CNNs).
טרנספורמרי ראייה הם גישה חדשה לפתרון בעיות בתחום ראיית מחשב. במקום לסמוך על רשתות עצבים קונבולוציונליות טרדיציונליות (CNNs), שהיו העמוד המרכזי של משימות הקשורות לתמונות מאז עשורים, ViTs משתמשים בארכיטקטורת הטרנספורמר כדי לעבד תמונות. הם מתייחסים לחתיכות תמונה כמילים במשפט, מאפשרים למודל ללמוד את היחסים בין החתיכות הללו, בדיוק כמו שהוא לומד את ההקשר בפסקה של טקסט.
בניגוד לרשתות נוירונים קונבולוציונליות, ViTs מחלקים תמונות קלט לחלקים, מסדרים אותם לוקטורים, ומפחיתים את ממדיהם באמצעות כפל מטריצות. לאחר מכן, מפעיל מעצב טרנספורמר את הוקטורים האלה כמוטבעות טוקנים. במאמר זה, נחקור טרנספורמרים חזוניים וההבדלים העיקריים שלהם מרשתות נוירונים קונבולוציונליות. מה שהופך אותם למעניינים במיוחד היא היכולת שלהם להבין תבניות גלובליות בתמונה, משהו שרשתות נוירונים קונבולוציונליות יכולות להתמודד איתן.
דרישות מוקדמות
- יסודות של רשתות נוירונים: הבנת כיצד רשתות נוירונים מעבדות נתונים.
- רשתות נוירונים קונבולוציונליות (CNNs): היכרות עם CNNs ותפקידם בראיה ממוחשבת.
- ארכיטקטורת טרנספורמר: ידע על טרנספורמרים, בעיקר השימוש שלהם בעיבוד שפה טבעית.
- עיבוד תמונה: הבנת מושגים בסיסיים כמו ייצוג תמונה, ערוצים, ומערכי פיקסלים.
- מנגנון תשומת לב: הבנת תשומת לב עצמית ויכולתה למודל יחסים בין קלטים.
מהם טרנספורמרים חזוניים?
טרנספורמרים של ויז'ן (ViT) משתמשים בקונספט של תשומת לב וטרנספורמרים כדי לעבד תמונות – זה דומה לטרנספורמרים בהקשר של עיבוד שפה טבעית (NLP). עם זאת, במקום להשתמש בטוקנים, התמונה מחולקת לפאצ'ים ומסופקת כרצף של הטמעות ליניאריות. פאצ'ים אלו מטופלים באותו אופן שבו מטופלים טוקנים או מילים ב-NLP.
במקום להסתכל על התמונה כולה בו זמנית, ViT חותך את התמונה לחתיכות קטנות כמו פאזל. כל חתיכה הופכת לרשימת מספרים (וקטור) שמתארת את המאפיינים שלה, ולאחר מכן המודל מסתכל על כל החתיכות ומבין כיצד הן קשורות זו לזו באמצעות מנגנון טרנספורמר.
בניגוד ל-CNNs, ViTs פועלים על ידי החלת מסננים או קרנלים ספציפיים על תמונה כדי לגלות מאפיינים ספציפיים, כמו דפוסי קצה. זהו תהליך הקונולוציה שהוא מאוד דומה לסורק מדפסת שמסרק תמונה. המסננים הללו מחליקים על פני כל התמונה ומדגישים מאפיינים משמעותיים. לאחר מכן, הרשת מצטברת שכבות רבות של מסננים אלו, ומזהה בהדרגה דפוסים מורכבים יותר.
עם CNNs, שכבות פולינג מצמצמות את גודל מפות המאפיינים. שכבות אלו מנתחות את המאפיינים המופקים כדי לבצע תחזיות שימושיות לזיהוי תמונה, גילוי אובייקטים וכדומה. עם זאת, ל-CNNs יש שדה קליטה קבוע, מה שמגביל את היכולת למודל תלותיות לטווח ארוך.
איך CNN רואה תמונות?
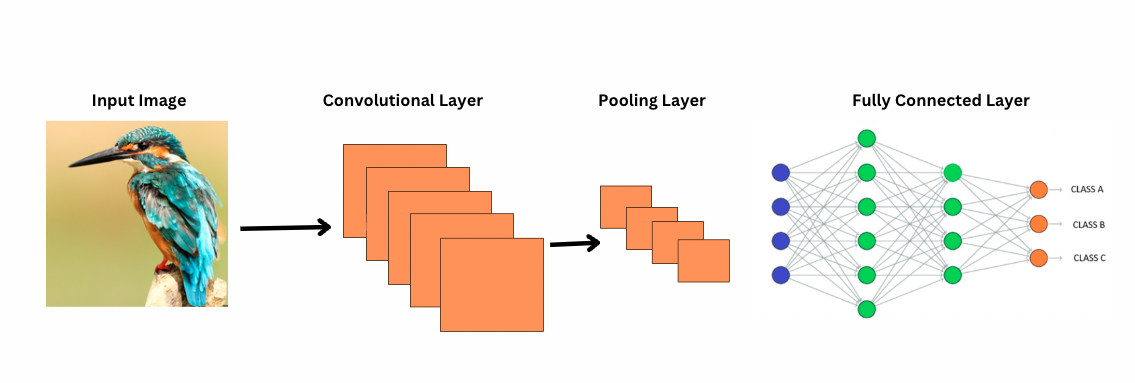
ViTs, למרות שיש להם יותר פרמטרים, משתמשים במנגנון העצמי-התייחסות לייצוג מאפיינים טוב יותר ולהפחית את הצורך בשכבות עמוקות. רשתות CNN מחייבות ארכיטקטורה עמוקה בהרבה על מנת להשיג כוח ייצוג דומה, מה שמביא לעליית עלות חישובית.
בנוסף, רשתות CNN לא יכולות ללכוד תבניות גלובליות בתמונה מכיוון שהמסננים שלהן מתמקדים באזורים מקומיים בתמונה. כדי להבין את התמונה כולה או קשרים מרוחקים, רשתות CNN תלויות בשילוב של שכבות רבות ופולינג להרחבת תחום הראייה. אך, תהליך זה עשוי לאבד מידע גלובלי בגישות שלב אחר שלב.
ViTs, מצד שני, מחלקות את התמונה לפסים שמטופלים כאקראי כניסה יחידה. באמצעות העצמי-התייחסות, ViTs משווים את כל הפסים בו זמנית ולומדים כיצד הם קשורים. זה מאפשר להם ללכוד תבניות ותלותים בכל התמונה מבלי לבנות אותם שכבה אחר שכבה.
מהו הנחה אינדוקטיבית?
לפני שממשיכים, חשוב להבין את המושג של הנחה אינדוקטיבית. הנחה אינדוקטיבית מתייחסת להנחה שדגם מבצע על מבנה הנתונים; במהלך האימון, זה עוזר לדגם להיות כללי יותר ולהפחית את הסינוי. ב- CNNs, הנחות אינדוקטיביות כוללות:
- מקומיות: תכונות בתמונות (כמו קצוות או טקסטורות) מוקצות באזורים קטנים.
- מבנה שכונתי דו-ממדי: פיקסלים סמוכים יותר קשורים זה לזה, כך שסננים פועלים על אזורים הסמוכים מרחבית.
- שקיפות לתרגום: תכונות שנזהרות בחלק מהתמונה, כמו קצה, שומרות על אותו משמעות אם הן מופיעות בחלק אחר.
הפגיעות האלו הופכות את CNNs ליעילים ביותר עבור משימות תמונה, מאחר והן עוצבו באופן תואם למאפיינים המרחביים והמבנתיים של תמונות.
Transformers חזון (ViTs) מכילים פחות פגיעות ספציפיות לתמונה ביחס ל-CNNs. ב-ViTs:
- עיבוד גלובלי: שכבות התשומת הלב פועלות על כל התמונה, מאפשרות למודל ללכוד יחסים גלובליים ותלותיות מבלי להיות מוגבלות על ידי אזורים מקומיים.
- מבנה 2D מינימלי: מבנה ה-2D של התמונה משמש רק בהתחלה (כאשר התמונה מחולקת לקטעים) ובמהלך הכיוונון הדק (להתאמת הטבעות תפקידיות לרזולוציות שונות). להבדל מ-CNNs, ViTs אינן מניחות שפיקסלים סמוכים קשורים בהכרח.
- יחסים מרחביים שנלמדים: הטבעות תפקידיות ב-ViTs לא מקודדות יחסים מרחביים ספציפיים באיתחול. במקום זאת, המודל לומד את כל היחסים המרחביים מהנתונים במהלך האימון.
כיצד פעלו Transformers חזון
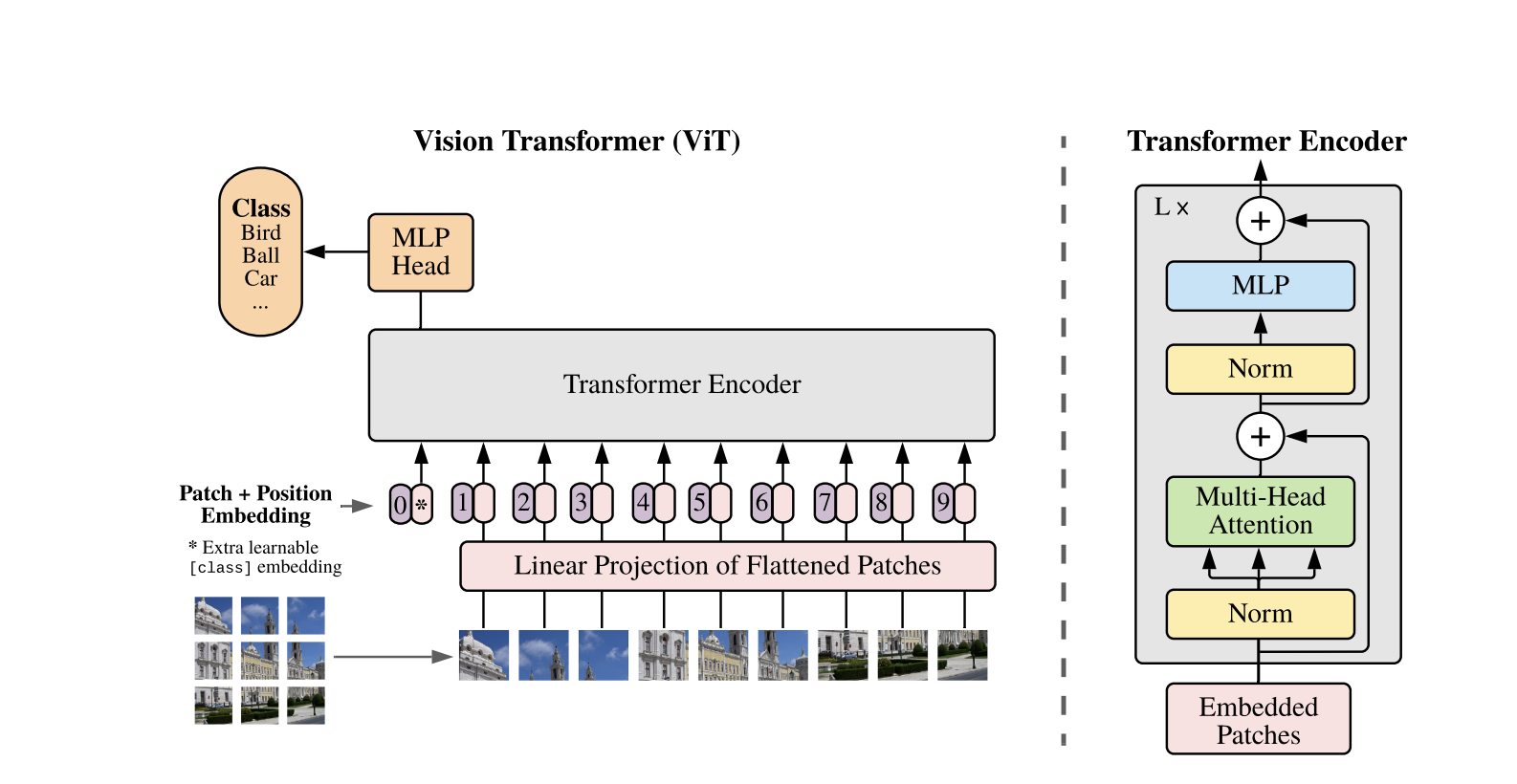
הראיון של Transformer משתמש בארכיטקטורת Transformer התקן שפותחה לרצפי טקסט חד-מימדיים. כדי לעבד את התמונות דו-מימדיות, הן מחולקות לחלקי פצל קטנים בגודל קבוע, כגון P P פיקסלים, שמושפעים לווקטורים. אם לתמונה יש ממדים H W עם ערוצים C, מספר החלקים הכולל הוא N = H W / P P אורך הקלט היעיל ל-Transformer. החלקים שמאושרעים מוטבעים למרחב קבוע ממד D, שנקרא קידודי חלק.
אסימון לימודי מיוחד, דומה לאסימון [CLS] ב-BERT, מתווסף לקדימה לרצף הקידודים. אסימון זה לומד ייצוג תמונה גלובלי שישמש מאוחר יותר לצורך סיווג. בנוסף, יישומים מיקומיים מתווספים לקידודי חלק כדי לקודד מידע מיקומי, עוזרים למודל להבין את מבנה המרחבי של התמונה.
הרצף של הטמעות עובר דרך הקידוד Transformer, שמשלב בין שני פעולות עיקריות: ביניים בראש מרובע עצמי (MSA) ורשת עצבים משמעתית, הנקראת גם בלוק MLP. כל שכבה כוללת הפחתת שכבה (LN) שמופעלת לפני הפעולות אלו וחיבורים שומרים נותרים מוספים לאחר מכן כדי לקבוע את האימונים. הפלט של הקידוד Transformer, בדיוק מצב האקראי של האסימון [CLS], משמש כייצוג התמונה.
ראש פשוט מתווסף לאסימון [CLS] הסופי עבור משימות סיווג. במהלך ההקדמה, ראש זה הוא רשת פרספטרון רב-שכבתית (MLP) קטנה, בעוד בכוונון מדויק, זהו בדרך כלל שכבה ליניארית יחידה. ארכיטקטורה זו מאפשרת ל-ViTs לדמות ביעילות יחסים גלובליים בין פסילות ולהשתמש בכוחה המלא של הפעילות העצמית להבנת תמונה.
בדגם טרנספורמר חיברי, במקום לחלק ישירות תמונות גולמיות לפסילות, הרצף הקלט מגיע ממפות תכונות שנוצרו על ידי CNN. ה-CNN מעבדת את התמונה תחילה, מוציאה תכונות מרחביות משמעותיות, שנמצאות לאחר מכן ליצירת פסילות. הפסילות הללו מופשטות ומוקפצות למרחב קבוע-מימדי באמצעות ההקרנה הליניארית המאומן כאשר בטרנספורמרים חזוניים סטנדרטיים. מקרה מיוחד של הגישה הזו הוא שימוש בפסילות בגודל 1×1, שכל פסילה מתאימה למיקום מרחבי יחיד במפת התכונות של ה-CNN.
במקרה זה, מימדי המרחב של מפת התכונות מתשטחים, והרצף התוצאה מוקצה לממד הקלט של ה-Transformer. כמו עם ViT התקני, נוסף טוקן שיווק והטבעות מיקום כדי לשמור על מידע מיקומי וכדי לאפשר הבנת תמונה גלובלית. גישה היברידית זו משתמשת בעוצמת החילוץ של תכונות מקומיות של CNNs ומשלבת אותן עם יכולות המיפוי הגלובלי של Transformers.
הדגמת קוד
כאן קטע הקוד על איך להשתמש במרתונים חזותיים על תמונות.
המודל ViT מעבד את התמונה. הוא כולל מפענח בעל דמות כמו BERT וראש לינארי לסיווג הממוקם בראש המצב המוסתר הסופי של הטוקן [CLS].
כאן נמצא יישום בסיסי של מרתון חזותי (ViT) באמצעות PyTorch. הקוד הזה כולל את הרכיבים היסודיים: הטביעת חתך, הקידוד המיקומי, ומפעיל הTransformer. ניתן להשתמש בזה למשימות סיווג פשוטות.
מרכיבים מרכזיים:
- הכנסת רצפים: תמונות מחולקות לרצפים קטנים, שטוחים, ומועברות ליניארית לייצוגים.
- קידוד מיקוד: מידע מיקום נוסף לייצוגי הרצפים, מכיוון שטרנספורמרים אינם תופסים מיקום.
- מקודד טרנספורמר: מבצע תשומת לב עצמית ושכבות הזנה קדימה כדי ללמוד מערכות יחסים בין רצפים.
- כותרת סיווג: מייצא את ההסתברויות של המחלקה באמצעות טוקן CLS.
ניתן לאמן מודל זה על כל קובץ תמונה באמצעות מקסימיזצית כמו Adam ופונקציית ההפסד כמו cross-entropy. לשיפור ביצועים, שקול שימוש בטכניקת הרצה מראש על קובץ נתונים גדול לפני הכוונון.
עבודה נוספת פופולרית
-
DeiT (מרכיבי תמונות יעילים מבחינת נתונים) מאת Facebook AI: אלה הם מרכיבי תמונה מבחינת ראייה שנאמנו באופן יעיל עם הכנסת ידע. DeiT מציע ארבעה גרסאות: deit-tiny, deit-small, ושניים deit-base. השתמש ב־
DeiTImageProcessorכדי להכין תמונות. -
BEiT (BERT הכשרה מוקדמת של טרנספורמרים לדימויים) על ידי מחקר מיקרוסופט: בהשראת BERT, BEiT משתמש במידול דימויים מוסתרים עצמאי ומביס את ה-ViTs המפוקחים. הוא מתבסס על VQ-VAE לצורך הכשרה.
-
DINO (הכשרת טרנספורמרים לדימויים עם פיקוח עצמי) על ידי AI של פייסבוק: ViTs שהוכשרו באמצעות DINO יכולים לסSegment אובייקטים ללא הכשרה מפורשת. נקודות ביקורת זמינות באינטרנט.
-
MAE (Masked Autoencoders) על ידי פייסבוק מאמצה לשכפל את ViTs על ידי שיקום תחביר של חתכי תמונה מסומנים (75%). כאשר מבוצע כיוונון סופי, שיטה זו פשוטה עולה על הכשרה מודרכת.
מסקנה
לסיכום, נמצא כי ViTs הם אלטרנטיבה מצוינת ל־CNNs מאחר שהן משתמשות ב־transformers לזיהוי תמונות, ממזערות דעת עצמית ומתייחסות לתמונות כחתיכות רצפים. שיטה זו פשוטה ונפתחה מראש, והיא הראתה ביצועים מובילים בתחרויות רבות לסיווג תמונות, במיוחד כאשר משויכים אותה עם שיקופים קדמיים על מערכות נתונים גדולות. אף על פי כן, ישנן אתגרים פוטנציאליים שנשארים, כולל הרחבת ViTs למשימות כמו זיהוי אובייקטים וסיגמנטציה, שיפור נוסף של שיטות שכפול עצמי מודרכות, וחקירת הפוטנציאל של התגלוגה של ViTs לשיפור ביצועים.
משאבים נוספים
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision