













הקדמה
רגרסיה ליניארית מרובת משתנים היא טכניקה סטטיסטית בסיסית המשמשת ליצירת דגמים ליחס בין משתנה תלותי אחד לבין מספר משתנים תלותים. ב-Python, כלים כמו scikit-learn ו־statsmodels מספקים יישומים איכותיים לניתוח רגרסיה. במדריך זה תלמד כיצד ליישם, לפרש ולהעריך דגמי רגרסיה ליניארית מרובת משתנים בעזרת Python.
דרישות מוקדמות
לפני שתתעמק ביישום, וודא שיש לך את התנאים הבאים:
- הבנה בסיסית של Python. ניתן להתייעץ ב-מדריך Python למתחילים.
- ידיעה ב־scikit-learn למשימות למידת מכונה. ניתן להתייעץ ב-מדריך Python scikit-learn.
- comprehension של עקרונות ויזואליזציה של נתונים ב-Python. ניתן להפנות ל-איך לערוך נתונים ב-Python 3 באמצעות matplotlib ו-ניתוח וויזואליזציה עם pandas ו-Jupyter Notebook ב-Python 3.
- Python 3.x מותקן עם הספריות הבאות
numpy,pandas,matplotlib,seaborn,scikit-learn, ו-statsmodelsמותקנות.
מהו התאמה ליניארית מרובה?
התאמה ליניארית מרובה (MLR) היא שיטת סטטיסטית שמבצעת מודלים עבור הקשר בין משתנה תלוי ושני או יותר משתנים תלויים. זו הרחבה של התאמה לינארית פשוטה, שמבצעת מודלים עבור הקשר בין משתנה תלוי ומשתנה תלוי יחיד. ב-MLR, הקשר מודלה באמצעות הנוסחה:
.png)
איפה:
.png)
דוגמה: חיזוי מחיר בית על סמך גודלו, מספר החדרים והמיקום שלו. במקרה זה, קיימים שלושה משתנים תלויים, כלומר, גודל, מספר החדרים והמיקום, ומשתנה תלוי אחד, כלומר, המחיר, שהוא הערך שיש לחזות.
ניחושים של רגרסיה לינארית מרובתית
לפני הטפל ברגרסיה לינארית מרובתית, חשוב לוודא כי הנחיות אלו יתקיימו:
-
לינאריות: הקשר בין משתנה התלות והמשתנים התלותים הוא לינארי.
-
אי-תלות בשגיאות: שאריות (שגיאות) הן אינן תלויות זו בזו. נפיק זאת בדרך כלל באמצעות מבחן דרבין-ווטסון.
-
הומוסקדסיות: וריאנס שאריות היא קבועה בכל רמות המשתנים התלותים. גרף שאריות יכול לעזור לוודא זאת.
-
אין רב-התאמה: משתנים תלויים אינם מופתעים בצורה גבוהה. גורם ניפוח השונות (VIF) בשימוש נרחב לזיהוי רב-התאמה.
-
נורמליות של השאריות: השאריות צריכות לעקוף התפלגות נורמלית. ניתן לבדוק זאת באמצעות גרף Q-Q.
-
השפעת חריגים: חריגים או נקודות עקיפה גבוהות לא צריכות להשפיע בצורה לא פרופורציונלית על המודל.
ההנחיות הללו מבטיחות כי המודל הרגרסי תקף והתוצאות אמינות. כשל בעמיתות בהנחיות אלו עשוי להביא לתוצאות משוחזרות או מטעות.
עיבוד קדם של הנתונים
במקטע זה, תלמד כיצד להשתמש במודל הרגרסיה לינארית מרובתית בפייתון כדי לחזות מחירי בתים על סמך תכונות ממערך הנתונים של סט נתוני הדיור של קליפורניה. תלמד כיצד לעבד את הנתונים, להתאים מודל רגרסיה, ולהעריך את ביצועיו בזמן שמתמודדים עם אתגרים נפוצים כמו ריבוי שיתופים, עצמים חריפים, ובחירת תכונות
שלב 1 – טעינת המערך הנתונים
תשתמש במערך הנתונים של סט נתוני הדיור של קליפורניה, מערך נתונים פופולרי למשימות רגרסיה. מערך הנתונים מכיל 13 תכונות על בתים בכפרים בבוסטון ואת מחיר הבית הממוצע המתאים להם
ראשית, נתקין את החבילות הדרושות:
כדאי לשים לב לפלט של הקובץ:
כאן ניתן לראות מה משמעות כל אחת מהתכונות:
| Variable | Description |
|---|---|
| MedInc | הכנסה ממוצעת ברחוב |
| HouseAge | גיל בינוני של בתים ברחוב |
| AveRooms | מספר החדרים הממוצע |
| AveBedrms | מספר החדרי שינה הממוצע |
| אוכלוסייה | אוכלוסיית הרחוב |
| AveOccup | ממוצע ביתי של תושבים |
| Latitude | קו רוחב של הרחוב |
| Longitude | קו אורך של הרחוב |
שלב 2 – עיבוד מראש של הנתונים
בדיקת ערכים חסרים
מבצע בדיקה כדי לוודא שאין ערכים חסרים בקבוצת הנתונים שעשויים להשפיע על הניתוח.
פלט:
בחירת תכונות
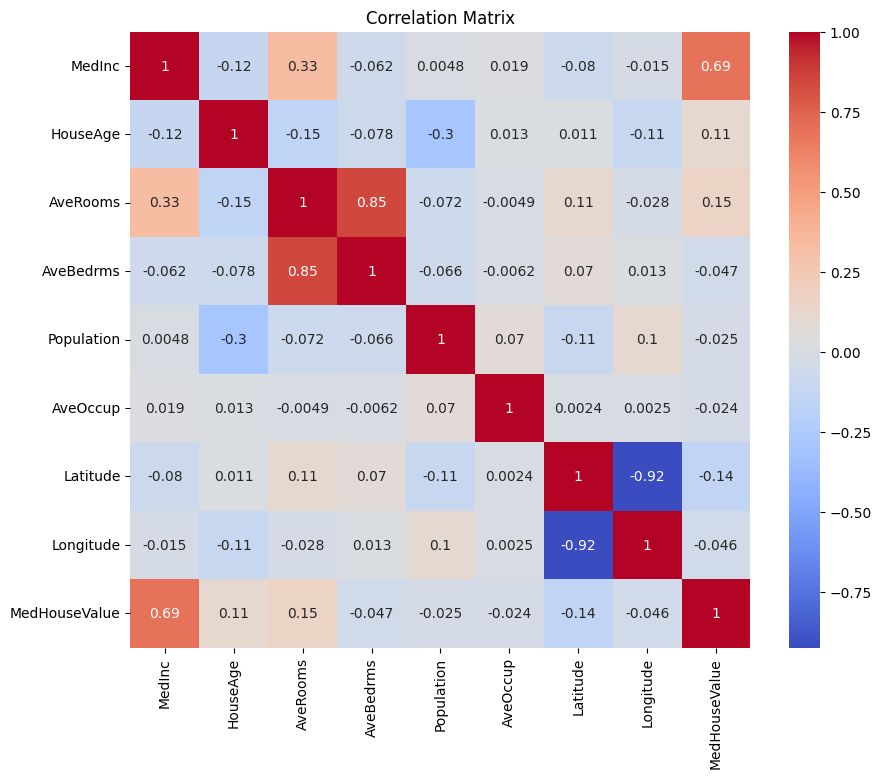
נתחיל ביצירת מטריצת קורלציה כדי להבין את התלות בין המשתנים.
פלט:
ניתן לנתח את מטריצת הקורלציה למעלה כדי לבחור בין המשתנים התלויים והאינדפנדנטיים עבור המודל הרגרסיוני שלנו. מטריצת הקורלציה מספקת תובנות ליחסים בין כל זוג משתנים בקבוצת הנתונים.
במטריצת הקורלציה הנתונה, MedHouseValue הוא המשתנה התלוי, מכיוון שזהו המשתנה שאנו מנסים לנבא. המשתנים האינדפנדנטיים מציגים קורלציה משמעותית עם MedHouseValue.
בהתבסס על מטריצת הקורלציה, ניתן לזהות את המשתנים האינדפנדנטיים הבאים שיש להם קורלציה משמעותית עם MedHouseValue:
MedInc: משתנה זה מציג קורלציה חיובית חזקה (0.688075) עםMedHouseValue, מראה כי ככל שההכנסה הממוצעת עולה, ערך הבית הממוצע גם עשוי לעלות.AveRooms: משתנה זה מציג קורלציה חיובית בינונית (0.151948) עםMedHouseValue, מרמז על כך שככל שממוצע מספר החדרים לבית עולה, ערך הבית הממוצע גם עשוי לעלות.AveOccup: משתנה זה מציג קורלציה שלילית חלשה (-0.023737) עםMedHouseValue, המציינת כי ככל שהתעופה הממוצע לבית מתגורר עולה, ערך בית הממוצע מטבע לרדת, אף על פי שההשפעה נחותה יחסית.
על ידי בחירת משתנים אלו המתלקים, ניתן לבנות מודל רגרסיה שמכסה את הקשרים בין המשתנים הללו ואת MedHouseValue, מאפשר לנו לבצע חיזויים על ערך בית הממוצע בהתבסס על הכנסה ממוצעת, מספר חדרים ממוצע, ותעופה ממוצעת.
ניתן גם לעשות דיוקן של מטריצת הקורלציה בפייתון באמצעות הקוד הבא:
תתמקד במאפיינים מרכזיים מסוימים לפשטות בהתבסס על דברים שנאמרו לעיל, כגון MedInc (הכנסה ממוצעת), AveRooms (מספר חדרים ממוצע לבית), ו־AveOccup (תעופה ממוצעת לבית מתגורר).
הבלוק הקודד לעיל בוחר תכונות מסוימות ממסגרת הנתונים housing_df לצורך ניתוח. התכונות שנבחרות הן MedInc, AveRooms, ו־AveOccup, המאוחסנות ברשימת selected_features.
מסגרת הנתונים housing_df מוחלקת לתת-קבוצה הכוללת רק את התכונות שנבחרו והתוצאה מאוחסנת ברשימת X.
המשתנה המטרה MedHouseValue מופק מתוך housing_df ומאוחסן ברשימת y.
סיווג התכונות
תשתמש בתהליך התקנה כדי לוודא שכל התכונות נמצאות על אותו סולם, משפרת ביצועים של המודל והשוואה.
התקנה היא טכניקת עיבוד מוקדמת שמקנה לתכונות מספריות להצטיין בערך ממוצע של 0 ובסטיית תקן של 1. תהליך זה מבטיח שכל התכונות נמצאות על אותו סולם, שהוא חיוני למודלים למידת מכונה הרגישים לסולמות הקלט של התכונות. על ידי התקנת התכונות, ניתן לשפר את ביצועי המודל והשוואה על ידי הפחתת ההשפעה של תכונות עם טווחים גדולים ששולטים במודל.
פלט:
הפלט מייצג את הערכים שנקודת הנתונים הראשונה, הערכים של MedInc, AveRooms, ו-AveOccup לאחר החישובים של StandardScaler. הערכים כעת ממוקדים סביב 0 עם סטיית תקן של 1, מבטיחים שכל התכונות נמצאות על אותו סולם.
השורה הראשונה [ 2.34476576 0.62855945 -0.04959654] מציינת שעבור נקודת הנתונים הראשונה, הערך של MedInc מוקדם ב־2.34476576, AveRooms הוא 0.62855945, ו-AveOccup הוא -0.04959654. באופן דומה, השורה השנייה [ 2.33223796 0.32704136 -0.09251223] מייצגת את הערכים הממוקדים עבור נקודת הנתונים השנייה, וכן הלאה.
הערכים שנסקלו נמצאים בטווח של כ -1.14259331 עד 2.34476576, רומזים כי התכונות נורמליזו וניתן להשוות ביניהן. זה חיוני עבור מודלי למידת מכונה שרגישים לגודל התכונות הקלטיות, שכן זה מונע מתכונות עם טווחים גדולים מלשלוט במודל.
יישום רגרסיה ליניארית מרובית
עכשיו שסיימת עם עיבוד הנתונים בוא ניישם רגרסיה ליניארית מרובית בפייתון.
הפונקציה train_test_split משמשת לחלוקת הנתונים לסטים של אימון ובדיקה. כאן, 80% מהנתונים משמשים לאימון ו-20% לבדיקה.
המודל מוערך באמצעות שגיאת הריבועים הממוצעת ו-R-squared. שגיאת הריבועים הממוצעת (MSE) מודדת את הממוצע של ריבועי השגיאות או הפערים.
R-squared (R2) הוא מדיד סטטיסטי שמייצג את האחוז של השונות של משתנה תלותי שמוסבר על ידי משתנה תלותי או משתנים במודל רגרסיה.
פלט:
הפלט מספק שני מדדים עיקריים להערכת ביצועי המודל של רגרסיה ליניארית מרובית:
שגיאת הריבוע הממוצע (MSE): 0.7006855912225249
MSE מודד את ההבדל בריבוע בממוצע בין הערכים המיוחסים לערכים האמיתיים של משתנה המטרה. ערך MSE נמוך מציין ביצועים טובים יותר של המודל, משום שזה אומר שהמודל עושה יותר תחזיות מדויקות. במקרה זה, ערך ה-MSE הוא 0.7006855912225249, מה שמציין שהמודל אינו מושלם אך יש לו רמה סבירה של דיוק. ערכי ה-MSE כללית צריכים להיות קרובים יותר ל-0, עם ערכים נמוכים מציינים ביצועים טובים יותר.
R-squared (R2): 0.4652924370503557
R-squared מודד את היחס של השונות במשתנה התלוי שניתן לחזות מהמשתנים האינפנדנטיים. המדד נע בין 0 ל-1, כאשר 1 הוא תחזית מושלמת ו-0 מציין אין קשר לינארי. במקרה זה, ערך ה-R-squared הוא 0.4652924370503557, מה שמציין שכ-46.53% מהשונות במשתנה המטרה ניתן להסביר על ידי המשתנים האינפנדנטים שהשתמשו במודל. זה מרמז על כך שהמודל מסוגל לתפוס חלק ניכר מהקשרים בין המשתנים אך לא את כולם.
בואו נבדוק כמה גרפים חשובים:

.png)
שימוש ב־statsmodels
ספריית Statsmodels בפייתון היא כלי עוצמתי לניתוח סטטיסטי. היא מספקת מגוון רחב של מודלים סטטיסטיים ובדיקות, כולל רגרסיה לינארית, ניתוח שורת זמן ושיטות לא פרמטריות.
בהקשר של רגרסיה לינארית מרובה, ניתן להשתמש ב־statsmodels כדי להתאים מודל לינארי לנתונים, ולאחר מכן לבצע מגוון בדיקות סטטיסטיות וניתוחים על המודל. זה יכול להיות מועיל במיוחד להבנת הקשרים בין המשתנים התלויים והלא תלויים, ולביצוע חיזויים מבוססים על המודל.
פלט:
כאן תמצא את סיכום הטבלה לעיל:
סיכום מודל
המודל הוא מודל התאמה של Ordinary Least Squares, שהוא סוג של מודל התאמה לינארית. המשתנה התלותי הוא MedHouseValue, ויש במודל ערך R-squared של 0.485, שמציין כי כ-48.5% מהשינוי ב־MedHouseValue ניתן להסביר באמצעות המשתנים האינפנדנטיים. ערך R-squared מתוקן הוא 0.484, שהוא גרסה מתוקנת של R-squared שמעניקה דוחס למודל עבור כל הכלים האינפנדנטיים הנוספים.
התאמת המודל
המודל נתאם באמצעות שיטת ה־Least Squares, והסטטיסטיקת ה־F היא 5173, שמציינת כי המודל הוא התאמה טובה. על פי הנחת ההיתכנות, הסיכוי לראות סטטיסטיקת F שכזו או יותר קיצונית מהנצפה הוא בערך 0. מה שמעיד על המודל כמקביל.
מקדפי המודל
המקדפים של המודל הם:
- המונח הקבוע הוא 2.0679, שמציין כי כאשר כל המשתנים האינפנדנטיים הם 0, הערך המשוער של
MedHouseValueהוא בערך 2.0679. - המקדף של
x1(במקרה זהMedInc) הוא 0.8300, שמציין כי עבור כל עליה ביחידה ב־MedInc, הערך המשוער שלMedHouseValueעולה בכ-0.83 יחידות, בהנחה שכל המשתנים האינפנדנטיים האחרים נמצאים קבועים. - המקדם עבור
x2(במקרה זהAveRooms) הוא -0.1000, מה שמציין כי עבור כל יחידה הגדלה ב-x2, ערך ה-MedHouseValueהמנובא יורד בכ-0.10 יחידות, בהנחה שכל המשתנים התלויים האחרים נשמרים קבועים. - המקדם עבור
x3(במקרה זהAveOccup) הוא -0.0397, מה שמציין כי עבור כל יחידה הגדלה ב-x3, ערך ה-MedHouseValueהמנובא יורד בכ-0.04 יחידות, בהנחה שכל המשתנים התלויים האחרים נשמרים קבועים.
אבחון המודל
אבחון המודל הוא כדלקמן:
- הסטטיסטיקת בדיקת אומניבוס היא 3981.290, מה שמציין שהשאריות אינן מיוצגות בהתפלגות תקנית.
- הסטטיסטיקת דרבין-ווטסון היא 1.983, מה שמציין שאין אוטוקורלציה סינפנטית בשאריות.
- הסטטיסטיקת ג'רקי-ברה היא 11583.284, מה שמציין שהשאריות אינן מיוצגות בהתפלגות תקנית.
- השחלת השפלות של השאריות היא 1.260, מה שמציין שהשאריות מוטהות לימין.
- הקורטוזה של השאריות היא 6.239, מה שמציין שהשאריות הן לפי סוגם לפיק גבוה וזנבות כבדים יותר מהתפלגות תקנית.
- מספר התנאים הוא 1.42, מה שמציין שהמודל אינו רגיש לשינויים קטנים בנתונים.
.png)
טיפול ברב-קולינאריות
רב-קולינאריות היא בעיה נפוצה ברגרסיה ליניארית מרובתית, כאשר שני או יותר משתנים תלותיים קורלטים בצורה גבוהה זה עם זה. זה עשוי להוביל להערכות לא יציבות ובלתי אמינות של מקדמי הרגרסיה.
כדי לזהות ולטפל ברב-קולינאריות, ניתן להשתמש ב-גורם הנפיחות של שטח השגיאה. גורם הנפיחות של שטח השגיאה מודד כמה השקפת השגיאה המשוערת מתרחבת אם החזאים שלך קורלטים. ערך של VIF של 1 אומר שאין קורלציה בין חזאי נתון לחזאים האחרים. ערכי VIF שחורגים מ-5 או 10 מציינים כמות של רב-קולינאריות בעייתית.
בבלוק הקוד למטה, בואו נחשב את ערך ה-VIF עבור כל משתנה תלותי במודל שלנו. אם ערך VIF כלשהו עובר על 5, עליך לשקול להסיר את המשתנה מהמודל.
פלט:
ערכי VIF עבור כל תכונה הם כדלקמן:
MedInc: ערך ה-VIF הוא 1.120166, מציין קורלציה נמוכה מאוד עם משתנים תלותיים אחרים. זה מרמז על כך ש-MedIncאינו קורלט גבוהה עם משתנים תלותיים אחרים במודל.AveRooms: ערך ה-VIF הוא 1.119797, מציין קורלציה נמוכה מאוד עם משתנים תלותיים אחרים. זה מרמז על כך ש-AveRoomsאינו קורלט גבוהה עם משתנים תלותיים אחרים במודל.AveOccup: ערך ה-VIF הוא 1.000488, המציין אי קיום קורלציה עם משתנים תלויים אחרים. זה מרמז על כך ש־AveOccupלא מקורלת עם משתנים תלויים אחרים במודל.
בכלל, ערכי ה-VIF האלה נמצאים מתחת ל־5, מה שמציין על עדיפות לא קיום מולטי־קולינאריות חשובה בין המשתנים התלויים במודל. זה מרמז על כך שהמודל יציב ואמין, וכי קואפיציינטים של המשתנים התלויים לא מושפעים באופן משמעותי ממולטי־קולינאריות.
.png)
טכניקות אימות חוצי
אימות חוצי הוא טכניקה המשמשת להערכת ביצועי המודל של למידת מכונה. זו פרוצדורה של דיגום שמשמשת להערכת מודל אם יש לנו דגימת נתונים מוגבלת. הפרוצדורה כוללת פרמטר יחיד בשם k שמפנה למספר הקבוצות שבהן יש לחלק את דגימת הנתונים הנתונה. כתוצאה מכך, הפרוצדורה לעתים קרות נקראת k-fold cross-validation.
פלט:
ציוני האימות החוצי מציינים כיצד המודל מבצע על נתונים שלא נראו מראש. הציונים נעים בין 0.31191043 ל־0.51269138, המרמזים על כך שביצועי המודל משתנים בין הפיתיחות השונות. ציון גבוה מציין ביצוע טוב יותר.
התוצאה הממוצעת של ציון CV R^2 היא 0.41864482644003276, ומרמזת על כך שבממוצע המודל מסביר כ-41.86% מהשונות במשתנה היעד. זאת רמת הסבר בינונית, המעידה על כך שהמודל יחסית יעיל בחיזוי המשתנה היעד אך עשוי להרוויח משיפור או מהדרכה נוספת.
ניתן להשתמש בתוצאות אלו על מנת להעריך את יכולת ההתפשטות של המודל ולזהות אזורים פוטנציאליים לשיפור.
.png)
שיטות בחירת תכונות
השיטה של הסרת תכונות רקורסיבית היא טכניקת בחירת תכונות שמסירה באופן רקורסיבי את התכונות הפחות חשובות עד שמתקבל מספר מסוים של תכונות. שיטה זו שימושית במיוחד כאשר ישנן כמות גדולה של תכונות והמטרה היא לבחור תת קבוצת תכונות המכילה את התכונות המידעניות ביותר.
בקוד המסופק, תחילה יש לייבא את המחלקה RFE מתוך sklearn.feature_selection. לאחר מכן ליצור אינסטנס של RFE עם מוערך מסוים (במקרה זה, LinearRegression) ולהגדיר n_features_to_select כ-2, מה שמציין כי אנו רוצים לבחור את שתי התכונות העליונות.
לְבַדִּיקָה, אנו מתאימים את אובייקט ה־RFE למאפיינים שנסודרו שלנו X_scaled ולמשתנה המטרה y. המאפיין support_ של אובייקט ה־RFE מחזיר מסכה בוליאנית המציינת אילו מאפיינים נבחרו.
כדי לחזות את דירוג המאפיינים, יש ליצור DataFrame עם שמות המאפיינים והדירוגים המתאימים להם. המאפיין ranking_ של אובייקט ה־RFE מחזיר את הדירוג של כל מאפיין, עם ערכים נמוכים מציינים מאפיינים חשובים יותר. לאחר מכן יש לערוך תרשים עמודות של דירוגי המאפיינים, ממוינים לפי ערכי הדירוג שלהם. תרשים זה עוזר לנו להבין את החשיבות היחסית של כל מאפיין במודל.
פלט:
.png)
בהתבסס על התרשים לעיל, המאפיינים המתאימים ביותר הם MedInc ו־AveRooms. ניתן גם לאמת זאת על ידי הפלט של המודל לעיל כמשתנה תלוי MedHouseValue, הוא תלוי ברובו ב־MedInc ו־AveRooms.
שאלות נפוצות
איך ליישם רגרסיה לינארית מרובתית בפייתון?
כדי ליישם רגרסיה ליניארית מרובתית בפייתון, ניתן להשתמש בספריות כמו statsmodels או scikit-learn. הנה סקירה מהירה באמצעות scikit-learn:
זה מדגים איך להתאים את המודל, לקבל את הקואפיציינטים וליצור תחזיות.
מהן השערות הנדרשות של רגרסיה ליניארית מרובתית בפייתון?
רגרסיה ליניארית מרובתית מתבססת על מספר שערות כדי להבטיח תוצאות תקפות:
- לינאריות: הקשר בין משתני התחזית והמשתנה המטרה הוא לינארי.
- אינדפנדנטיות: התצפיות הן תלויות זו בזו.
- הומוסקדסיות: שונות השאריות (שגיאות) קבועה בכל רמות המשתנים התלויים.
- נורמליות של השאריות: השאריות מתפלגות באופן נורמלי.
- אין מולטי-קולינאריות: משתנים תלויים אינם מתואמים בצורה גבוהה זה עם זה.
ניתן לבדוק את ההנחיות הללו באמצעות כלים כמו גרפים שאריים, פקטור פליטות בריאותי (VIF), או בדיקות סטטיסטיות.
כיצד לפרש תוצאות רגרסיה מרובים בפייתון?
מדדים מרכזיים מתוצאות הרגרסיה כוללים:
- קואפיציינטים (coef_): מציינים את השינוי במשתנה היעד לכל שינוי יחיד במשקל המתאים, תוך שמירה על שאר המשתנים קבועים.
דוגמה: קואפיציינט של 2 עבור X1 אומר שהמשתנה היעד מתעלה ב-2 לכל עליה של 1 יחידה ב-X1, תוך שמירה על שאר המשתנים קבועים.
2.חיתוך (intercept_): מייצג את הערך המנובא של המשתנה היעד כאשר כל המכנים שווים לאפס.
3.R-ריבוע: מסביר את היחס של השונות במשתנה היעד המוסבר על ידי המכנים.
דוגמה: R^2 של 0.85 אומר ש-85% מהשנויות במשתנה היעד מוסברות על ידי המודל.
4.ערכי P (ב־statsmodels): מעריכים את המשמעות הסטטיסטית של המכנים. ערך P < 0.05 בדרך כלל מעיד על כך שהמכנה הוא משמעותי.
מה ההבדל בין התאמה ליניארית פשוטה ומרובתית בפייתון?
| Feature | Simple Linear Regression | Multiple Linear Regression |
|---|---|---|
| מספר המשתנים התלותיים | אחד | יותר מאחד |
| משוואת המודל | y = β0 + β1x + ε | y = β0 + β1×1 + β2×2 + … + βnxn + ε |
| הנחיות | זהות להתאמה ליניארית מרובתית, אך עם משתנה תלות יחיד | זהה להתאמה ליניארית פשוטה, אך עם הנחות נוספות עבור מספר משתנים תלותיים |
| פרשנות של מקדמים | השינוי במשתנה היעד לשינוי ביחידה במשתנה התלותי, בתנאי שכל המשתנים האחרים נשמרים קבועים (לא רלוונטי בהתאמה ליניארית פשוטה) | השינוי במשתנה היעד לשינוי ביחידה באחד מהמשתנים התלותיים, בתנאי שכל המשתנים התלותיים האחרים נשמרים קבועים |
| מורכבות המודל | פחות מורכב | מורכב יותר |
| גמישות המודל | פחות גמיש | יותר גמיש |
| סיכון לעקיפה | נמוך | גבוה |
| ניתוח נתונים | קל לפרש | קשה יותר לפרש |
| יישומיות | מתאים לקשרים פשוטים | מתאים לקשרים מורכבים עם מספר גורמים |
| דוגמה | חיזוי מחירי בתים על סמך מספר חדרי שינה | חיזוי מחירי בתים על סמך מספר חדרי שינה, מ"ר, ומיקום |
מסקנה
במדריך המקיף הזה, למדת ליישם רגרסיה לינארית מרובית באמצעות קובץ הנתונים הגורם לדיור בקליפורניה. עיסקת בנושאים קריטיים כמו רב-קולינאריות, אימות מרובה, בחירת תכונות, ורגולריזציה, מעניק לך הבנה מעמיקה של כל עקרון. גם למדת לשלב ויזואליזציות כדי להמחיש נשאריות, חשיבות תכונות, וביצועים כלליים של המודל. עכשיו אתה יכול לבנות מודלי רגרסיה חזקים בפייתון ולהחיל את היכולות הללו על בעיות בעולם האמיתי.
Source:
https://www.digitalocean.com/community/tutorials/multiple-linear-regression-python