













מדעני נתונים מתחילים בלמידה על SQL מוקדם. זה מובן, בהתבסס על הנרחבות והיעילות גבוהה של מידע טבלי. עם זאת, יש דברים אחרים שהם מצויינים באופן המאגרים המסוגים שלהם, כמו מאגרי גרף, בהם ניתן לאחסן מידע מחובר שאינו מתאים למאגר רלאונציום SQL. במדריך הלמידה הזה, נלמד על Neo4j, מערכת ניהול מאגרי גרף פופולרית שניתן להשתמש בה כדי ליצור, לנהל ולבדוק מאגרי גרף בעזרת Python.
מהים מאגרי גרף?
לפני שיחת על Neo4j, בואו נקח דקה כדי להבין טוב יותר את מאגרי הגרף. יש לנו מאמר מלא שמסביר מהים מאגרי גרף, אז אנחנו נסכם את הנקודות העיקריות כאן.
מסדי נתונים גרפיים הם סוג של מסד נתונים NoSQL (הם לא משתמשים בSQL). הם מעוצבים עבור ניהול מידע מחובר. בניגוד למסדי היחסים הרלוונציאליים המשתמשים בשורות ושורות, מסדי הגרפים משתמשים במבנים גרפיים המערבבים מ:
- נקודות (יישומים) כמו אנשים, מקומות, תפיסות
- קצוות (יחסים) שמחברים את הנקודות השונות האלה, כמו אדם חי במקום, או שחקן פוטבול העשה תרומה במשחק.
- מאפיינים (תכונות לאנקדות/חסים)כמו גיל של אדם, או מתי במATCH היה הועמד היעד.
המבנה הזה גורם למאגרי הגרפים להיות מועדים למען טיפול במידע מחובר בתחומים ויישומים כמו רשתות חברתיות, המצעדים, זיהוי הונאה, ועוד, לרוב מועילים יותר מבני נתונים רלוונציאליים במונחים של יעילות השאלות. הנה המבנה של מאגר גרף דוגמה לנתונים כדוגמה של כדורגל:
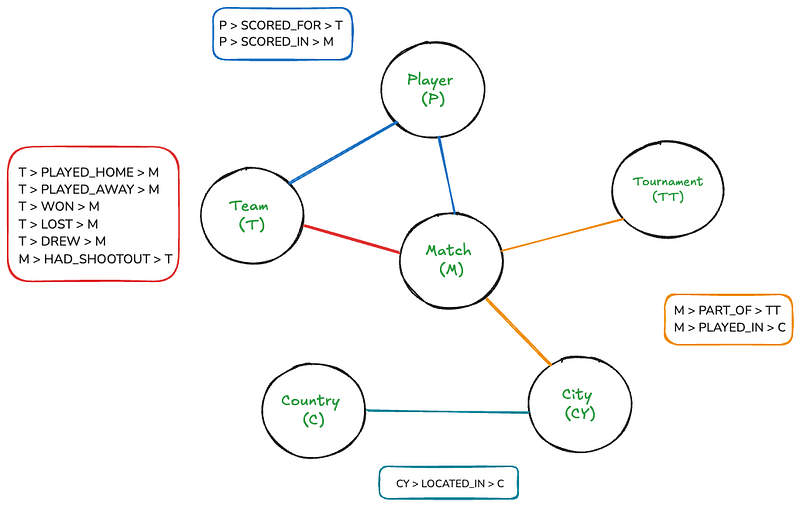
למרות שהגרף הזה מייצג משהו די יודע לבני אדם, הוא יכול להיות די מסובך אם נמחק על הכלי 'canvas'. אבל עם Neo4j, התייעצות בגרף זה תהיה כל כך פשוטה שתהיה כמו כתיבת SQL joins פשוטים.שילובים SQL.
יש לגרף שש נקודות: מאתגר, צוות, מירוץ, שחקן, מדינה ועיר. המלבנים מציגים את היחסים שקיימים בין הנקודות. יש גם מספר תכונות לנקודות וליחסים:
- התאמה: תאריך, תוצר הבית, תוצר המחזיר
- מועדון: שם
- שחקן: שם
- מירבית: שם
- עיר: שם
- מדינה: שם
- רוב_הצעד, רוב_בתוך: דקה, גלידה, פנלי
- היתה_מילה: זוכה, מועמד_ראשון
תבנית זו מאפשרת לנו לייצג:
- כל המאמץ עם התוצאות, התאריכים והמיקומים
- הצוותים שמשתתפים במאמץ כל אחד (בית וחוץ)
- השחקנים שמונחים מולגול, כולל פרטים כמו הדקה, גולים של המקבלים ופנלים
- המירוצים שהמאמצים חלק ממנה
- הערים והמדינות בהן מנוצחים
- מידע על משחק הירים, כולל זוכים ומושתלי הירים הראשונים (במקרה שלם)
השEMA מאפשר את טבע היררכיה של המיקומים (עיר בתוך מדינה) ואת היחסים השונים בין היישומים (לדוגמא, צוותים שמשחקים מאץ, שחקנים שמתרחשים לצוותים במאצים).
המבנה מאפשר בעליל בדיקות, כמו למצוא את כל המאצים בין שתי צוותים, כל המטרים שניצחו על ידי שחקן אחד, או כל המאצים במישהו מהמפגשים או במקום מסויים.
אך בואו לא נתקדם יותר מדי. להתחיל, מה הן Neo4j ולמה להשתמש בהם?
מה הם Neo4j?
Neo4j, השם המוביל בעולם הניהול של בסיס נתונים גרף, ידוע בפעילויות חזקות וגיוון.
בלבודה של נאו-4ג', משמש אובייקטים מאחסנים גרף מקוריים שמותוכנזים בעזרת תהליכים גרף בצורה מאוד יעילה. היעילות שלו בעיקרון מתמחת בעיבוד יחסים מורכבים מעוררת בעלי יכולת לעבוד טובה יותר מבases המסורתיות עבור מידע מחובר
אחד האסקט המרכזיים בנאו-4ג' הוא הבריאות המידע. היא מובטחת את ההתאמה לרשימת ACID (Atomicity, Consistency, Isolation, Durability), שמעניקה בעלי הביצועים אמינות וקיימות
כשמדברים על העסקאות, שפת השאילתת המעורבת בעיקרון של הגרף, Cypher, מציעה סינתקסיס מאוד יותרי הגיון ודירבני, מעוצב עבור תבניות גרף. לכן לסינתקסיס שלו נתנה שם משמעותי של "אסקיי ארט". Cypher לא יהיה בעיה ללמוד, בעיקר אם מוכרחים עם SQL.
אתם יכולים להוסיף עכשיו עצמים, יחסים או תכונות חדשים בקלות בעזרת Cypher ללא דאגה להרס שאלות קיימות או מבנה. הוא אפשרי לשינויים המהדהדים בדרישות הפיתוח המודרני.
לNeo4j יש תמיכה רבת תחום במערכת החיים שלה. יש לו מאמרים מורחבים, כלים מוחשיים להצגת גרפים, קהילה פעילה ושילובים עם שפות תכנות אחרות כמו Python, Java וJavaScript.
הגדרת Neo4j וסביבת Python
לפני שאנחנו נתקע בעבודה עם Neo4j, אנחנו צריכים להגדיר את הסביבה שלנו. הקטע הזה ידוע אתכם בעיצוב מיקום חלון על-מנוע בכדי לאחסן בסיס נEO4j, בהגדרת סביבת Python וביציאה קשר ביניהם.
לא התקנת Neo4j
אם ברצונך לעבוד עם בסיס נתונים מקומיים בניוזוג, אתה יש צורך ב הורדת והתקנת זה באופן מקומי, ביחד עם התלויים שלו כמו ג' אווה. אך במקרים רבים, תוכל להתמודד עם בסיס נתונים Neo4j חי רחוק בסביבת כל מיני ספקים של ענן.
למעשה, לא נהיה מתקנים Neo4j על המערכת שלנו. במקום זאת, ניצור מקום מסוג בסיס נתונים חופשי על Aura, שירות ה云 המנוהל לחלוטין של Neo4j. אחר כך, נשתמש בneo4j ספקטר הליבה הפתוחה לפינגווין כדי להתחבר לבסיס הנתונים הזה ולספק אותו בנתונים.
יצירת מקום בסיס נתונים Neo4j Aura
כדי לאתר בסיס נתונים גרף חינמי על Aura DB, ביקורת דף המוצר שלהם ולחץ "התחל בחינמה."
לאחר ההרשמה שלך, יהיו לך אפשרויות אפשריות, וצריך לבחור את האפשרות החינמית. אחר כך ייתן לך מיניסיין חדש עם שם משתמש וסיסמה כדי להתחבר אליו:
העתק את הסיסמה שלך, שם המשתמש שלך וה-URI הקישור למיניסיין.
אז, יצירה של תיבת עבודה חדשה ושל .env קובץ כדי לאחסן את המידע הפרטי:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
הדבקת תוכן באותה הקובץ:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
הגדרת הסביבה הפיתוחית של הפיתוח
עכשיו, אנחנו ניתן את ספקת הלוגינג neo4j לספקת הלוגינג הפיתוחית הפינגוויניסטית:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # כדי להוסיף את הסביבה לJupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
הפקטים גם מו Installsipykernel ספרייה ומשתמשים בה כדי להוסיף את הסביבה Conda החדשות ב Jupyter כגרעין. אחר כך, אנחנו מו Installsneo4j לקוח ה-Python עבור אינטראקצים עם מסדי ניוז 'ורג' וpython-dotenv כדי לנהל את הפרטים הסיסמיים שלנו ב-Neo4j באופן בטיחה.
מייצאים את האינסטANCE AuraDB עם מידע על כדורגל
לקחת נתונים לתוך מסד נתונים גרף היא תהליך מסובך שדורש ידע בסיסי בסייפר. כיום עדיין לא למדנו על היסודות של סייפר, ולכן תשתמשו בתסריט פייתון שהכנתי לכתבה הזו שיבזיז אוטומטית נתוני פוטבול היסטוריים אמיתיים. התסריט ישתמש באישורים שאיחסנתם כדי להתחבר למופע הAuraDB שלכם.
המידע על הכדורגל מקורו ב מאגר הנתונים הזה על משחקי כדורגל הבינלאומיים שהתקיימו בין 1872 ל2024. המידע זמין בפורמט קומاסקסV (CSV), אז הסקripט מפרק אותו וממיר אותו לצורה גרף בעזרת Cypher וNeo4j. בשלב האחרון של המאמר, כשנהיה רגישים מספיק בטכנולוגיות האלה, נעבור על הסקripט שורה בשורה כך שתוכלו להבין איך להמיר מידע טבלאי לצורה גרף.
אלה הפקודות להפעלה (ודא שהגדרת את מופע AuraDB ושמרת את האישורים שלך בקובץ .env בספריית העבודה שלך):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
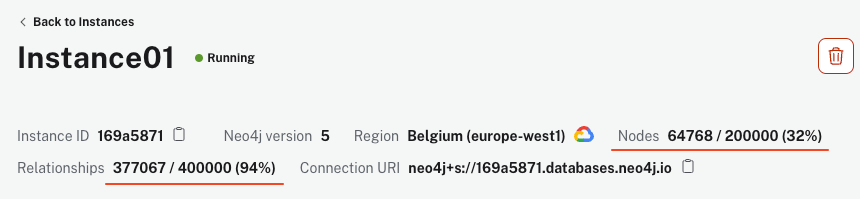
הסקריפט עשוי לקחת מספר דקות לרוץ, תלוי במכונה ובחיבור האינטרנט שלך. עם זאת, ברגע שהוא מסתיים, מופע AuraDB שלך אמור להראות מעל 64k צמתים ו-340k קשרים.
חיבור ל-Neo4j מפייתון
עכשיו, אנחנו מוכנים להתחבר למיקום Aura DB שלנו. קודם כל, אנחנו נקרא את המידע הנתונים שלנו מה.env תוך שימוש בdotenv:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
עכשיו, בואו ניצור קישור:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
היצאה:
Connection successful!
הנה ההסבר לקוד:
- אנחנו מיmport
GraphDatabaseמneo4jכדי לתקשר עם Neo4j. - אנחנו משתמשים במשתנים הסביבה הקודמים כדי להגדיר את החיבור שלנו (
uri,username,password). - אנחנו יוצרים אובייקט נהג בעזרת
GraphDatabase.driver(), בעזרת ההגדרות הזו, אנחנו מקבלים חיבור אל בסיס ניוז 4ג' - מתחת ל
withחלק, אנחנו משתמשים בverify_connectivity()פעולה כדי לבדוק אם קישור מוכתב. בהגדרה ברירוץ,verify_connectivity()לא מחזיר שום דבר אם הקישור הוצלח.
אחרי שההדרכה מסתיימת, קראdriver.close()כדי לסגור את החיבור ולשחרר את המשאבים. אובייקטים של הדריאקטור יקרים ליצירה, לכן צריך ליצור רק אובייקט אחד עבור היישומך.
מה שיש לשאול בשפת Cypher
השיבוט של Cypher מעוצב כך שיהיה אינטuitiביל וייצג בצורה מראית את מבני הגרף. הוא מסתמך על סינטגיית האסיי ארט הבאה:
(nodes)-[:CONNECT_TO]->(other_nodes)
בואו נפרס את הרכיבים העיקריים של דפוס השאילת הכללי:
1. נקודות
בשאלה Cypher, מילה מופיעה בתוך פתחים מסמלת שם לאחד מהתאים. לדוגמה, (שחקן) מתאים את כל התאים Player. במקרה כמעט בולט, שמות תאים מזוהים באליזים כדי להפוך השאלות ליותר קריאות, קלות יותר לכתיבה וצפופות. אתה יכול להוסיף אליז לשם של תא על-ידי שימוש בסימן צד לפניו: (m:מatch).
בתוך הפתחים, אתה יכול ל指定 אחד או יותר תכונות לתא עבור התאמה מדויקת בעזרת סינTAX דיקסיקני. לדוגמה:
// כל התאים tournament שהם FIFA World Cup (t:Tournament {name: "FIFA World Cup"})
מאפייני הנודעים נכתבים כרגעים, בעוד שהערך שאתה רוצה שיהיה להם חייב להיות שטרם.
2. יחסים
יחסים מחברים נודעים אחד לשני, והם מוצפפים בסוג של סימן קווץ וחץ:
// התאמה לנודעים שהם חלק ממירן מסויים (m:Match)-[PART_OF]->(t:Tournament)
ניתן להוסיף סינונים ומאפיינים ליחסים באותו אופן:
// התאמה שברזיל שיצא למשחק קפיצות הערך והיתה המועמדת הראשונה (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
יחסים מוצפים בחץ עצמות-[יחסים]->. שוב, אתה יכול לכלול תכונות השמה בתוך חתיכות. לדוגמה:
// כל השחקנים שעשו משעבר (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. מקלים
אותו הדברCOUNT(*) FROM table_nameלא יחזיר דבר בלי פרט לSELECT בעזרת SQL,(node) - [RELATIONSHIP] -> (node)לא ישליך שום תוצאות. אז, בדומה לSQL, Cypher מצויין בפרטים שונים כדי למצב את ההגיון של השאילתך בעזרת SQL:
- מתאים: התאמת דפוס בגרף
- איפה: סינון של התוצאות
- חזור: קביעת מה לכלול בקבוצת התוצאות
- צור: יצירת נקודות חדשות או יחסים
MERGE: יצירת עצמים ייחודיים או יחסיםDELETE: הסרת עצמים, יחסים או תכונותSET: עדכון תגיות ותכונות
הנה שאלה דוגמה שמדגימה את התפיסות האלה:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
השאלה הזו מוצאת את כל השחקנים שעידכנו בעצמם מטבחים במשחקים של העולם כאשר עומדים אחרי הדקה ה-80. זה קורה כמעט כמו SQL, אך התואם הSQL שלו מוצע לפחות אחד שלב של JOIN.
שימוש בנתב הפינגווין הניוצ'ור עבור ניתוח בסיס נתונים גרפי
בעיצוב שאלות עם execute_query
הנתב הפינגווין הניוצ'ור המקורי הוא הספרייה הרשמית שמתחברת למיקום של Neo4j דרך יישומים Python. הוא מאשר ומתקשר עם שאלות Cypher בעצם כמותות Python עם שרת Neo4j ומשלוח את התוצאות בתבנית אחידה.
כל זה מתחיל ביצירת אובייקט נהג עם הGraphDatabase מעבר לכך, אנחנו יכולים להתחיל לשלוח שאילות בעזרת הexecute_query שיטה.
עבור השאילת הראשונה שלנו, בואו נשאל שאלה מעניינת: איזה קבוצה זכתה במירב המשחקים באולימפיאדה העולמית?
# הוא יחזיר את הקבוצה שזכתה במירב המשחקים באולימפיאדה העולמית query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
ראשית, בואו נפרוש את השאילה:
- ה
התאמההקרובה מגדירה את התבנית שאנחנו רוצים: צוות -> ניצח -> משחק -> חלק מ -> מירבית RETURNהוא האותו כמות SQL,SELECTהביטוי, שבו אנחנו יכולים לשחזר את התכונות של העמודות והיחסים החוזרים. בביטוי הזה, אתה יכול גם להשתמש בכל פונקציית אסטרגגציה נתמכת בקיפה. למעלה, אנחנו משתמשים בCOUNT.ORDER BYפסקת פעולה פועלת באותה דרך כמו בSQL.LIMITמשמש לבקר את אורך השירותים החוזרים.
אחרי שאנחנו מגדירים את השאלה בתור מספר שורות של טקסט, אנחנו מעבירים אותה לשימוש בexecute_query() השיטה של האובייקט הנושא לנהג ומציעים את שמו הבסיסי של הבסיס הנתונים (הבסיסי בלבד הואneo4j). הפלט תמיד מכיל שלושה אובייקטים:
records: רשימה של אובייקטים Record, כל אחד מהם מייצג שורה באות האותם. כל רשימה היא אובייקט דומה לטופל שמקורי שם שבו ניתן לגשת לשדות באופן על-שמותי או במדדים.תקציב: מאפיין תוצאות שכולל מידע על ההוצאה לביצוע של השאלה, כמו סטטיסטיקות שאלה ומידע על זמנים.מפתחות: רשימה של תווים שמייצגים את שמות העמודות בתוצאות.
נדון באובייקט summary מאוחר יותר כי אנחנו בעיקר מתעניינים בrecords, שמכילים אובייקטי Record. ניתן לשלוף את המידע שלהם על ידי קריאה לשיטת data():
for record in records: print(record.data())
תוצאה:
{'Team': 'Brazil', 'MatchesWon': 76}
התוצאה מציגה בצורה נכונה שברזיל ניצחה בעיקר את המשחקים בקומפוזיון העולם.
העברת פרמטרים של השאלה
השאלה האחרונה שלנו אינה ניתנת לשימוש מחדש, בגלל שהיא רק מוצאת את הצוות המצליח ביותר בהיסטוריית הקומפוזיון העולמי. מה אם אנחנו רוצים למצוא את הצוות המצליח ביותר בהיסטוריית האירופה?
זה המקום בו מופיעים הפרמטרים של השאלה:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
בגירסה הזו של השאלה, אנחנו מציגים שתי פרמטרים בעזרת הסימן $:
tournamentlimit
כדי להעביר ערכים לפרמטרים של השאלה, אנחנו משתמשים באגודלים תועלתיים בתוך execute_query:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
תוצאה:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
תמיד מומלץ להשתמש בפרמטרים של שאלה ברגע שאתה מתחיל לחשוב על הכנסת ערכים משתנים לתוך השאלות שלך. המנהג הטוב ביותר מגינה על השאלות שלך מהזלזול של Cypher ומאפשרת לNeo4j להאסיף אותן.
כתיבת לדabases בעזרת פסקאות CREATE ו MERGE.
כתיבת מידע חדש במאגר קיים באותה דרך של execute_query אך על-ידי שימוש ב CREATE בעוגן בשאלה. לדוגמה, בואו ניצור פונקציה שתוסף סוג חדש של נקודה – מאמני צוות:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
הפונקציה add_new_coach לוקחת חמש פרמטרים:
- נהג: האובייקט של הניוקרט המשמש להתחברות לבסיס המידע.
שם_מועץ: שם המועץ החדש שיוסף למעשה.שם_המועדון: שם המועדון שבו המועץ יתחבר.start_date: התאריך בו המאמן מתחיל למעבד את הצוות.end_date: התאריך בו המשך המעבדת המאמן עם הצוות מסתיים.
השאלה Cypher בפונקציה עושה את הבאה:
- מתאים עם עצם צוות קיים עם שם הצוות נתנה.
- יוצר עצם מאמן חדש עם שם המאמן שנתנה.
- יוצר יחסים בין המאמן לבין הצוות
- מערךים את
start_dateוend_dateעל היחסיםCOACHES.
השאלה נבצעת בעזרת הexecute_query של השיטה, שלוקחת את מחרוזת השאלה ומידע של הפרמטרים בצורה מינורמלית.
אחרי הבצע, הפונקציה מדפיסה:
- מסר אישור בו מופיעים שמות המאמן והצוות ותאריך ההתחלה.
- מספר העמודים הנוצרים (אמור להיות 1 עבור העמוד החדש של המאמן).
- מספר היחסים הנוצרים (אמור להיות 1 עבור היחס
COACHESהחדש).
בואו נפעיל את זה עבור אחד המאמנים המצליחים ביותר בהיסטוריה הפוטבול הבינלאומית, ליאונל סקלוני, שניצח בשלושה תחרויות בינלאומיות רצופות (כוס העולם ושתי קופה אמריקה):
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
בפריט הקטן הזה, אנחנו משתמשים בDateTime ממשק מהמודולneo4j.time כדי להעביר תאריך בצורה נכונה לשאלה Cypher שלנו. ה מודול מכיל מספר מיני מבני מידע טימל שיכולים להיות שימושיים לך.
מעבר לCREATE, יש גם אחר פסולתMERGE שמשתמש בו ליצירת עצמים חדשים וקשרים. ההבדל העיקרי בינם הוא:
CREATEתמיד יוצר עצמים/קשרים חדשים, שיכולים להוביל למותגורמות.MERGEמייצרת רק נקודות/יחסים אם הם לא קיימים כבר.
לדוגמה, בסript של דיבור המידע שלנו, כפי שתראו מאוחר יותר:
- השתמשנו ב
MERGEעבור צוותים ושחקנים כדי להימנע מהדוגמות. - השתמשנו ב
CREATEעבורSCORED_FORוSCORED_INמערכות יחסים בגלל ששחקן יכול להרוב מספר פעמים במשחק אחד. - אלה אינם דומים ממשיים, בגלל שיש להם תכונות שונות (לדוגמה, דקה המשך של המטבע).
הגישה הזו מאפשרת יומרציות באותו זמן של מידע בעל יחסים דומים אך מבודדים.
בעלית העסקאות שלך
כשאתה מבצע execute_query, הנהג יוצר עסקאות ברקע. עסקאות הן יחידות עבודה שעושות את כל אותם פעולות במלואן או שמוחזרות ככשלון. זה אומר שכשאתה יוצר אלפים של נקודות או יחסים בעסקאות אחת בלבד (זה אפשרי) ונמצאת בדרך בשגיאה, כל העסקה נכשלת ללא כתיבה של מידע חדש לגרף.
כדי לקבל שליטה יותר חדה על כל עסקה, צריך ליצור אובייקטים של סשן. לדוגמה, בואו ניצור פונקציה למציאת מספר התוצאות הגבוהות ביותר של נקודות בתחרות נתונה בעזרת אובייקט של סשן:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
ראשית, אנחנו יוצרים את הפונקציה top_goal_scorers שמקבלת שלושה פרמטרים, החשוב ביותר הוא האובייקט של העסקה tx שיש להשיג באמצעות אובייקט של סשן.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
פלט:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
אז, מתחת למנהל ההקשר שנוצר בעזרת הsession() שיטה, אנו משתמשים בexecute_read(), ומעבירים את הtop_goal_scorers() פונקצייה, ביחד עם כל הפרמטרים הדרושים לשאילתה.
היציאה שלexecute_readהיא רשימה של אובייקטים סוג רשומה שמראים באופן נכון את שחיית ה5 מועדף בהיסטוריית הגולד העולמי, כוללה שמות כמו מירוסלב קלוז, רונאלדו נזאריו, וליונל מסי.
העתיף שלexecute_read()לטעינת מידע הואexecute_write().
ועם זאת מספרת, בואו נביט עכשיו בסקripט האכילה שהשתמשנו בו קודם כדי להבין איך עובדת אכילת הנתונים עם הנעה הפיתוחי הפונטגני של Neo4j על ידי Python.
אכילת נתונים בעזרת נעה פיתוחי פונטגני Neo4j על ידי Python
ה סקripט הנושא הזה מתחיל עם הצטרפות הערכים ולודאי הקובעים לקבלת הקובעים הנחוצים:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging # מסלולי קבצי CSV results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" # הגדרת רשת העדכונים logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") # טעינת מידע results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
אזור הקוד הזה גם מעצב רשת העדכונים. השורות הבאות בקוד קוראות את פרטי המשתמש שלי בNeo4j בעזרת dotenv ויוצרים אובייקט של מנהג (Driver).
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
בגלל שיש יותר מ-48k התאמות במאגר המידע שלנו, אנחנו מגדירים פרמטר BATCH_SIZE כדי להטעין מידע בדגימות קטנות יותר.
אז, אנחנו מגדירים פונקציה בשם create_indexes שמקבלת אבן-שיח של ההפעלה:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
מבני האינדקסים של Cypher הם מבנים בסיסיים בבסיס נתונים שמשפרים את ביצועי השאילתות בNeo4j. הם מאיצים את תהליך מציאת הノード או קשרים בהתבסס על תכונות מסויימות. אנחנו צריכים אותם עבור:
- ביצועי השאילתות מהרים
- ביצועי קריאה מורבדים על מידע גדול
- התאמה יעילה לתבניות
- אימוץ מגבלות ייחודיות
- סקלציות טובה יותר בגלל הגידול של הבסיס הנתונים
במקרה שלנו, רשימות מפתח על שמות צוותים, מזהמים מatch ושמות שחקנים יעזרו לשאילות שלנו להיות מהירות יותר בזמן חיפוש ייחודים או ביצוע שילובים מעבר לסוגים שונים של הנקודות. זו מנהג טוב ליצור רשימות מפתח כאלה בבסיס הנתונים שלך.
בהמשך, יש לנו את הingest_matches פונקציית.היא גדולה, אז בואו נפרק אותה בבלוקים:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
הדבר הראשון שתשימו לב הוא לUNWIND מילה המשמשת לעיבד מקבץ של מידע. היא לוקחת את$batch הפרמטר (שיהיה שורות ה DataFrame שלנו) ומשקיפה על כל שורה, מאפשרת לנו ליצור או לעדכן מספר נקודות ויחסים בעסקה אחת. הגישה הזו יותר יעילה מאשר לעיבד כל שורה בנפרד, בעיקר עבור מאגרי מידע גדולים.
החלק השני של השאלה מוכר מפני שהוא משתמש במספרMERGE כל פעמים. אחר כך, אנחנו מגיעים לWITH כל פעמים, שמשתמש בFOREACH בניינים עםIN CASE הצעות. הם משמשים ליצירת יחסים בהתאמה לתוצאה של המוחא. אם הצבעת המקומית ניצחת, זה יוצר יחס 'נצח' עבור הצבעת המקומית ויחס 'הפסידה' עבור הצבעת המוזרה, והפך. במקרה של צירוף, שני הצבעות מקבלים יחס 'חצץ' עם המאבק.
השאר מהפעלה מחלקת את הדף המוכן למתחמקים ובונה את הנתונים שינסיעו אל ה$batch פרמטר השאלה:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals ו ingest_shootouts פונקציות משתמשות בהבניות דומות. אך ל ingest_goals יש טיפול נוסף בשגיאות ובערך חסר.
בסוף הסקript, יש לנו את הmain() פונקציית הביצוע של כל הפונקציות האינגסציוניות שלנו בעזרת אובייקט ההפעלה:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
סיכום והשלבים הבאים
עברנו על היבטים מפתחים של עבודה עם בסיסים גרף Neo4j בעזרת Python:
- תפיסות ומבנה של בסיסים גרף
- הגדרת Neo4j AuraDB
- בסיסים לשפת Cypher
- שימוש במנוע הפייתון של Neo4j
- אספת נתונים ושיפור שאילתות
להמשך המסע שלך בNeo4j, בדוגל במשאבים אלו:
- תיעוד Neo4j
- ספריית מדעי הגרפים של Neo4j
- מדריך הניוזון של Neo4j Cypher
- מדריך לנוירופין הפיתוחים ב Python
- הסמכות בתעשיית הנתונים
- קצת על NoSQL
- מדריך מקיף לא-רשמי בשימוש ב MongoDB
הזכרו, הכוח של בases הגרפים נמצא בייצוג ובבחינה של יחסים מורכבים. המשיכו לנסות במודלים מסוגים שונים ולחקור תכונות מתקדמות של Cypher.