













Introduction
L’apprentissage automatique est une sous-domaine de l’intelligence artificielle (IA). L’objectif de l’apprentissage automatique est généralement de comprendre la structure des données et de les ajuster dans des modèles pouvant être compris et utilisés par les personnes.
Bien que l’apprentissage automatique soit un domaine de l’informatique, il diffère des approches computationnelles traditionnelles. Dans l’informatique traditionnelle, les algorithmes sont des ensembles d’instructions explicitement programmées utilisées par les ordinateurs pour effectuer des calculs ou résoudre des problèmes. Les algorithmes d’apprentissage automatique permettent plutôt aux ordinateurs de s’entraîner sur des entrées de données et d’utiliser des analyses statistiques pour produire des valeurs qui se situent dans une plage spécifique. De ce fait, l’apprentissage automatique permet aux ordinateurs de construire des modèles à partir de données d’échantillons afin d’automatiser les processus de prise de décision basés sur les entrées de données.
Tout utilisateur de technologie aujourd’hui a bénéficié de l’apprentissage automatique. La technologie de reconnaissance faciale permet aux plateformes de médias sociaux d’aider les utilisateurs à identifier et partager des photos d’amis. La technologie de reconnaissance optique de caractères (OCR) convertit les images de texte en caractères mobiles. Les moteurs de recommandation, alimentés par l’apprentissage automatique, suggèrent quels films ou émissions de télévision regarder ensuite en fonction des préférences des utilisateurs. Les voitures autonomes qui dépendent de l’apprentissage automatique pour naviguer pourraient bientôt être disponibles pour les consommateurs.
L’apprentissage automatique est un domaine en constante évolution. En raison de cela, il y a quelques considérations à garder à l’esprit lorsque vous travaillez avec des méthodologies d’apprentissage automatique, ou que vous analysez l’impact des processus d’apprentissage automatique.
Dans ce tutoriel, nous examinerons les méthodes d’apprentissage automatique courantes de l’apprentissage supervisé et non supervisé, ainsi que les approches algorithmiques courantes en apprentissage automatique, y compris l’algorithme des k plus proches voisins, l’apprentissage par arbre de décision et l’apprentissage profond. Nous explorerons quelles langues de programmation sont les plus utilisées en apprentissage automatique, en vous fournissant certains des attributs positifs et négatifs de chacune. De plus, nous discuterons des biais perpétués par les algorithmes d’apprentissage automatique, et envisagerons ce qui peut être gardé à l’esprit pour prévenir ces biais lors de la construction d’algorithmes.
Méthodes d’apprentissage automatique
En apprentissage automatique, les tâches sont généralement classées en grandes catégories. Ces catégories sont basées sur la manière dont l’apprentissage est reçu ou sur la manière dont les rétroactions sur l’apprentissage sont données au système développé.
Deux des méthodes d’apprentissage automatique les plus largement adoptées sont l’apprentissage supervisé, qui entraîne des algorithmes sur la base de données d’entrée et de sortie d’exemple étiquetées par des humains, et l’apprentissage non supervisé, qui fournit à l’algorithme des données non étiquetées afin de lui permettre de trouver une structure dans ses données d’entrée. Explorons ces méthodes plus en détail.
Apprentissage supervisé
Dans l’apprentissage supervisé, l’ordinateur est fourni avec des entrées d’exemple qui sont étiquetées avec leurs sorties désirées. Le but de cette méthode est que l’algorithme puisse « apprendre » en comparant sa sortie réelle avec les sorties « enseignées » pour trouver des erreurs et modifier le modèle en conséquence. L’apprentissage supervisé utilise donc des motifs pour prédire les valeurs d’étiquette sur des données supplémentaires non étiquetées.
Par exemple, avec l’apprentissage supervisé, un algorithme peut être alimenté avec des données d’images de requins étiquetées comme poisson et des images d’océans étiquetées comme eau. En étant formé sur ces données, l’algorithme d’apprentissage supervisé devrait être capable d’identifier ultérieurement les images de requins non étiquetées comme poisson et les images d’océans non étiquetées comme eau.
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
Apprentissage non supervisé
Dans l’apprentissage non supervisé, les données ne sont pas étiquetées, donc l’algorithme d’apprentissage est laissé à lui-même pour trouver des similitudes parmi ses données d’entrée. Comme les données non étiquetées sont plus abondantes que les données étiquetées, les méthodes d’apprentissage automatique qui facilitent l’apprentissage non supervisé sont particulièrement précieuses.
L’objectif de l’apprentissage non supervisé peut être aussi simple que de découvrir des motifs cachés dans un ensemble de données, mais il peut également viser à l’apprentissage des caractéristiques, ce qui permet à la machine informatique de découvrir automatiquement les représentations nécessaires pour classifier les données brutes.
L’apprentissage non supervisé est couramment utilisé pour les données transactionnelles. Vous pouvez disposer d’un grand ensemble de données sur les clients et leurs achats, mais en tant qu’humain, vous ne pourrez probablement pas comprendre quelles caractéristiques similaires peuvent être tirées des profils des clients et de leurs types d’achats. Avec ces données alimentées dans un algorithme d’apprentissage non supervisé, il peut être déterminé que les femmes d’une certaine tranche d’âge qui achètent des savons non parfumés sont susceptibles d’être enceintes, et donc une campagne marketing liée à la grossesse et aux produits pour bébés peut être ciblée vers ce public afin d’augmenter leur nombre d’achats.
Sans qu’une réponse « correcte » ne soit donnée, les méthodes d’apprentissage non supervisé peuvent examiner des données complexes qui sont plus étendues et apparemment non liées afin de les organiser de manière potentiellement significative. L’apprentissage non supervisé est souvent utilisé pour la détection d’anomalies, y compris pour les achats frauduleux par carte de crédit, et les systèmes de recommandation qui recommandent quels produits acheter ensuite. Dans l’apprentissage non supervisé, des photos de chiens non étiquetées peuvent être utilisées comme données d’entrée pour que l’algorithme trouve des ressemblances et classe ensemble les photos de chiens.
Approches
En tant que domaine, l’apprentissage automatique est étroitement lié à la statistique computationnelle, il est donc utile d’avoir des connaissances de base en statistique pour comprendre et exploiter les algorithmes d’apprentissage automatique.
Pour ceux qui n’ont peut-être pas étudié la statistique, il peut être utile de commencer par définir la corrélation et la régression, car ce sont des techniques couramment utilisées pour étudier la relation entre des variables quantitatives. La corrélation est une mesure d’association entre deux variables qui ne sont pas désignées comme dépendantes ou indépendantes. La régression au niveau de base est utilisée pour examiner la relation entre une variable dépendante et une variable indépendante. Parce que les statistiques de régression peuvent être utilisées pour anticiper la variable dépendante lorsque la variable indépendante est connue, la régression permet des capacités de prédiction.
Les approches de l’apprentissage automatique sont continuellement développées. Pour nos besoins, nous passerons en revue quelques-unes des approches populaires qui sont utilisées dans l’apprentissage automatique au moment de l’écriture.
k-nearest neighbor
L’algorithme des k plus proches voisins est un modèle de reconnaissance de motifs qui peut être utilisé à la fois pour la classification et pour la régression. Souvent abrégé en k-NN, le k dans k plus proches voisins est un entier positif, qui est généralement petit. Dans le cas de la classification ou de la régression, l’entrée consistera en les k exemples d’entraînement les plus proches dans un espace.
Nous nous concentrerons sur la classification k-NN. Dans cette méthode, la sortie est l’appartenance à une classe. Cela attribuera un nouvel objet à la classe la plus courante parmi ses k plus proches voisins. Dans le cas où k = 1, l’objet est attribué à la classe du seul voisin le plus proche.
Jetons un coup d’œil à un exemple de k plus proches voisins. Dans le diagramme ci-dessous, il y a des objets en forme de diamant bleu et des objets en forme d’étoile orange. Ceux-ci appartiennent à deux classes distinctes : la classe des diamants et la classe des étoiles.

Lorsqu’un nouvel objet est ajouté à l’espace — dans ce cas un cœur vert — nous voulons que l’algorithme d’apprentissage automatique classe le cœur dans une certaine classe.

Lorsque nous choisissons k = 3, l’algorithme trouvera les trois voisins les plus proches du cœur vert afin de le classer soit dans la classe des diamants, soit dans la classe des étoiles.
Dans notre diagramme, les trois voisins les plus proches du cœur vert sont un diamant et deux étoiles. Par conséquent, l’algorithme classera le cœur dans la classe des étoiles.
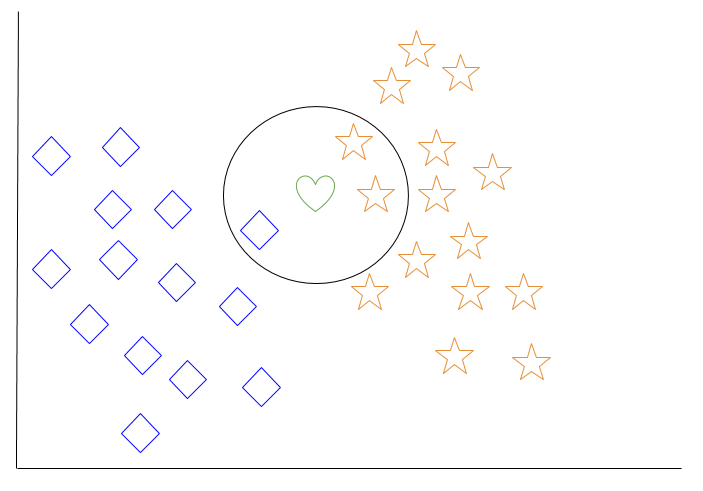
Parmi les algorithmes d’apprentissage automatique les plus élémentaires, les k plus proches voisins sont considérés comme une forme d' »apprentissage paresseux », car la généralisation au-delà des données d’entraînement ne se produit pas tant qu’une requête n’est pas faite au système.
Apprentissage par arbre de décision
Pour une utilisation générale, les arbres de décision sont utilisés pour représenter visuellement les décisions et montrer ou informer la prise de décision. Lorsqu’on travaille avec l’apprentissage automatique et la fouille de données, les arbres de décision sont utilisés comme modèle prédictif. Ces modèles mettent en correspondance des observations sur les données avec des conclusions sur la valeur cible des données.
L’objectif de l’apprentissage par arbre de décision est de créer un modèle qui prédira la valeur d’une cible en fonction des variables d’entrée.
Dans le modèle prédictif, les attributs des données qui sont déterminés par l’observation sont représentés par les branches, tandis que les conclusions sur la valeur cible des données sont représentées dans les feuilles.
Lors de « l’apprentissage » d’un arbre, les données source sont divisées en sous-ensembles basés sur un test de valeur d’attribut, qui est répété sur chacun des sous-ensembles dérivés de manière récursive. Une fois que le sous-ensemble à un nœud a la même valeur que sa valeur cible, le processus de récursion est complet.
Examinons un exemple de diverses conditions pouvant déterminer si quelqu’un devrait aller pêcher. Cela inclut les conditions météorologiques ainsi que les conditions de pression barométrique.
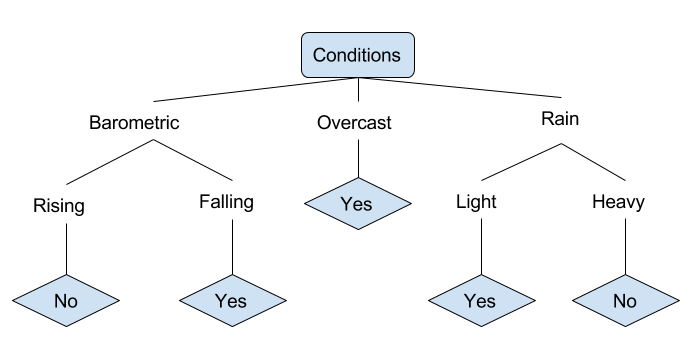
Dans l’arbre de décision simplifié ci-dessus, un exemple est classé en le faisant passer à travers l’arbre jusqu’au nœud feuille approprié. Cela renvoie alors la classification associée à la feuille particulière, qui dans ce cas est soit un Oui soit un Non. L’arbre classe les conditions d’une journée en fonction de leur adéquation pour aller pêcher.
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
Apprentissage Profond
L’apprentissage profond tente d’imiter comment le cerveau humain peut traiter la lumière et les stimuli sonores en vision et audition. Une architecture d’apprentissage profond est inspirée par les réseaux neuronaux biologiques et se compose de plusieurs couches dans un réseau neuronal artificiel composé de matériel et de GPU.
L’apprentissage profond utilise une cascade de couches d’unités de traitement non linéaires afin d’extraire ou de transformer des caractéristiques (ou des représentations) des données. La sortie d’une couche sert d’entrée à la couche suivante. En apprentissage profond, les algorithmes peuvent être soit supervisés et servir à classer les données, soit non supervisés et effectuer une analyse de motifs.
Parmi les algorithmes d’apprentissage automatique actuellement utilisés et développés, l’apprentissage profond absorbe le plus de données et a pu surpasser les humains dans certaines tâches cognitives. En raison de ces attributs, l’apprentissage profond est devenu une approche ayant un potentiel significatif dans le domaine de l’intelligence artificielle
La vision par ordinateur et la reconnaissance vocale ont toutes deux réalisé des progrès significatifs grâce aux approches d’apprentissage profond. IBM Watson est un exemple bien connu d’un système qui tire parti de l’apprentissage profond.
Langages de programmation
Lors du choix d’un langage pour se spécialiser en apprentissage automatique, vous voudrez peut-être tenir compte des compétences répertoriées dans les annonces d’emploi actuelles ainsi que des bibliothèques disponibles dans divers langages pouvant être utilisées pour les processus d’apprentissage automatique.
Python est l’une des langues les plus populaires pour travailler avec l’apprentissage automatique en raison des nombreux frameworks disponibles, notamment TensorFlow, PyTorch et Keras. En tant que langage doté d’une syntaxe lisible et de la capacité à être utilisé comme langage de script, Python s’avère puissant et simple à la fois pour le prétraitement des données et le travail direct avec les données. La bibliothèque d’apprentissage automatique scikit-learn est construite sur plusieurs packages Python existants que les développeurs Python peuvent déjà connaître, à savoir NumPy, SciPy et Matplotlib.
Pour commencer avec Python, vous pouvez lire notre série de tutoriels sur « Comment coder en Python 3« , ou lire spécifiquement sur « Comment créer un classificateur de machine learning en Python avec scikit-learn » ou « Comment effectuer un transfert de style neuronal avec Python 3 et PyTorch. »
Java est largement utilisé dans la programmation d’entreprise et est généralement utilisé par les développeurs d’applications de bureau en front-end qui travaillent également sur le machine learning au niveau de l’entreprise. Habituellement, ce n’est pas le premier choix pour ceux qui débutent en programmation et qui veulent apprendre sur le machine learning, mais il est préféré par ceux qui ont une formation en développement Java pour l’appliquer au machine learning. En termes d’applications de machine learning dans l’industrie, Java a tendance à être utilisé plus que Python pour la sécurité réseau, y compris dans les cas d’utilisation d’attaques informatiques et de détection de fraudes.
Parmi les bibliothèques d’apprentissage machine pour Java se trouvent Deeplearning4j, une bibliothèque d’apprentissage profond open-source et distribuée écrite pour Java et Scala; MALLET (MAchine Learning for LanguagE Toolkit) permet des applications d’apprentissage machine sur le texte, y compris le traitement du langage naturel, la modélisation de sujet, la classification de documents et le clustering; et Weka, une collection d’algorithmes d’apprentissage machine à utiliser pour les tâches de fouille de données.
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
Biais humains
Bien que les données et l’analyse computationnelle puissent nous faire penser que nous recevons des informations objectives, ce n’est pas le cas; être basé sur des données ne signifie pas que les sorties d’apprentissage machine sont neutres. Le biais humain joue un rôle dans la manière dont les données sont collectées, organisées et, en fin de compte, dans les algorithmes qui déterminent comment l’apprentissage machine interagira avec ces données.
Si, par exemple, les gens fournissent des images de « poissons » en tant que données pour former un algorithme, et que ces personnes sélectionnent massivement des images de carpes dorées, un ordinateur pourrait ne pas classer un requin comme un poisson. Cela créerait un biais contre les requins en tant que poissons, et les requins ne seraient pas comptés comme des poissons.
Lors de l’utilisation de photographies historiques de scientifiques comme données d’entraînement, un ordinateur peut ne pas classer correctement les scientifiques qui sont aussi des personnes de couleur ou des femmes. En fait, des recherches récentes et évaluées par des pairs ont indiqué que les programmes d’intelligence artificielle et d’apprentissage automatique présentent des biais d’apparence humaine qui incluent des préjugés de race et de genre. Voir, par exemple, « Les sémantiques issues automatiquement des corpus linguistiques contiennent des biais similaires à ceux des humains » et « Les hommes aiment aussi faire du shopping : réduire l’amplification des biais de genre à l’aide de contraintes au niveau du corpus » [PDF].
Alors que l’apprentissage automatique est de plus en plus utilisé dans les affaires, les biais non détectés peuvent perpétuer des problèmes systémiques qui peuvent empêcher les personnes de se qualifier pour des prêts, de voir des annonces pour des opportunités d’emploi à haut salaire, ou de recevoir des options de livraison le jour même.
Parce que les préjugés humains peuvent avoir un impact négatif sur les autres, il est extrêmement important de les connaître et de travailler à leur élimination autant que possible. Une façon d’y parvenir est de s’assurer qu’il y a des personnes diverses travaillant sur un projet et que des personnes diverses le testent et le relisent. D’autres ont appelé à la surveillance et l’audit des algorithmes par des tiers réglementaires, la construction de systèmes alternatifs qui peuvent détecter les préjugés et les examens éthiques en tant que partie intégrante de la planification des projets de science des données. Sensibiliser à la question des préjugés, être conscient de nos propres préjugés inconscients et structurer l’équité dans nos projets et pipelines d’apprentissage automatique peut contribuer à combattre le préjugé dans ce domaine.

Conclusion
Ce tutoriel a passé en revue certains des cas d’utilisation de l’apprentissage automatique, les méthodes courantes et les approches populaires utilisées dans le domaine, les langages de programmation d’apprentissage automatique appropriés, et a également couvert certaines choses à garder à l’esprit en termes de préjugés inconscients reproduits dans les algorithmes.
Parce que l’apprentissage automatique est un domaine qui est en constante évolution, il est important de garder à l’esprit que les algorithmes, les méthodes et les approches continueront de changer.
En plus de lire nos tutoriels sur « Comment construire un classifieur d’apprentissage automatique en Python avec scikit-learn » ou « Comment réaliser une transfert de style neuronal avec Python 3 et PyTorch« , vous pouvez en savoir plus sur le travail avec les données dans l’industrie technologique en lisant nos tutoriels Analyse de données.
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning