













A l’ère des données en temps réel, la capacité de traiter et d’analyser des informations en continu est devenue cruciale pour les entreprises. Apache Kafka, une puissante plateforme distribuée d’événements en continu, est souvent au cœur de ces pipelines en temps réel. Mais travailler avec des flux de données bruts peut être complexe. C’est là qu’intervient le Streaming SQL : il permet aux utilisateurs d’interroger et de transformer les sujets Kafka avec la simplicité du SQL.
Qu’est-ce que le Streaming SQL ?
Le Streaming SQL fait référence à l’application du langage de requête structuré (SQL) pour traiter et analyser des données en mouvement. Contrairement au SQL traditionnel, qui interroge des ensembles de données statiques dans des bases de données, le Streaming SQL traite continuellement les données au fur et à mesure de leur passage dans un système. Il prend en charge des opérations telles que le filtrage, l’agrégation, la jointure et la fenêtrage en temps réel.
Avec Kafka en tant que colonne vertébrale des pipelines de données en temps réel, le Streaming SQL permet aux utilisateurs d’interroger directement les sujets Kafka, facilitant ainsi l’analyse et l’exploitation des données sans avoir à écrire de code complexe.
Principaux composants du Streaming SQL sur Kafka
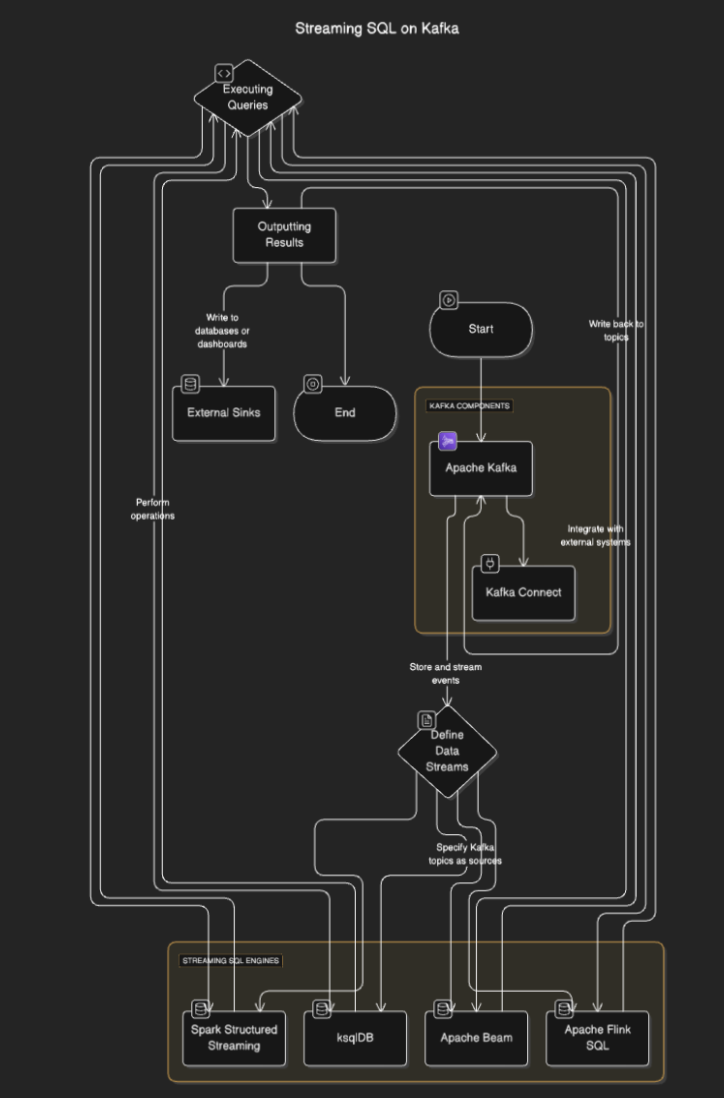
1. Apache Kafka
Kafka stocke et diffuse des événements en temps réel via des sujets. Les producteurs écrivent des données dans les sujets, et les consommateurs s’abonnent pour traiter ou analyser ces données. La durabilité, la scalabilité et la tolérance aux pannes de Kafka en font un choix idéal pour les données en continu.
2. Kafka Connect
Kafka Connect facilite l’intégration avec des systèmes externes tels que des bases de données, des magasins d’objets ou d’autres plateformes de streaming. Il permet une ingestion ou une exportation transparente de données vers/depuis les topics Kafka.
3. Moteurs SQL de streaming
Plusieurs outils permettent le Streaming SQL sur Kafka, notamment :
- ksqlDB : Un moteur SQL de streaming natif de Kafka construit sur Kafka Streams.
- Apache Flink SQL : Un framework polyvalent de traitement de flux avec des capacités avancées en SQL.
- Apache Beam : Fournit du SQL pour le traitement par lots et en continu, compatible avec divers moteurs d’exécution.
- Spark Structured Streaming : Prend en charge le SQL pour le traitement de données en temps réel et par lots.
Comment fonctionne le Streaming SQL ?
Le Streaming SQL se connecte à Kafka pour lire les données des topics, les traiter en temps réel et envoyer les résultats vers d’autres topics, bases de données ou systèmes externes. Le processus implique généralement les étapes suivantes :
- Définition des flux de données : Les utilisateurs définissent des flux ou des tables en spécifiant des topics Kafka comme sources.
- Exécution des requêtes : Les requêtes SQL sont exécutées pour effectuer des opérations telles que le filtrage, l’agrégation et la jointure des flux.
- Résultats de sortie: Les résultats peuvent être écrits de nouveau dans des sujets Kafka ou des destinations externes comme des bases de données ou des tableaux de bord.
Diagramme de flux
Outils de Streaming SQL pour Kafka
ksqlDB
ksqlDB est conçu spécifiquement pour Kafka et fournit une interface SQL pour traiter les sujets Kafka. Il simplifie les opérations comme le filtrage des messages, la jointure des flux et l’agrégation des données. Les principales fonctionnalités incluent :
- Requêtes SQL déclaratives: Définir des transformations en temps réel sans coder.
- Vues matérialisées: Persister les résultats des requêtes pour des recherches rapides.
- Native à Kafka: Optimisé pour un traitement à faible latence.
Exemple:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink est un puissant framework de traitement de flux qui fournit des capacités SQL pour les données en mode batch et en streaming. Il prend en charge des opérations complexes comme le traitement du temps d’événement et les fenêtrages avancés.
Exemple:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark Structured Streaming
Spark Structured Streaming permet le traitement de flux basé sur SQL et s’intègre bien avec les autres composants Spark. Il est idéal pour les pipelines de données complexes combinant le traitement par lots et en continu.
Exemple:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
Cas d’utilisation pour le SQL en streaming sur Kafka
- Analyses en temps réel. Surveiller l’activité des utilisateurs, les ventes ou les données des capteurs IoT avec des tableaux de bord en direct.
- Transformation des données. Nettoyer, filtrer ou enrichir les données pendant leur passage dans les sujets Kafka.
- Détection de fraude. Identifier les transactions suspectes ou les modèles en temps réel.
- Alertes dynamiques. Déclencher des alertes lorsque des seuils ou des conditions spécifiques sont atteints.
- Enrichissement des pipelines de données. Joindre des flux avec des ensembles de données externes pour créer des sorties de données enrichies
Avantages du SQL en streaming sur Kafka
- Développement simplifié. Le SQL est familier à de nombreux développeurs, réduisant la courbe d’apprentissage.
- Traitement en temps réel. Permet des insights immédiats et des actions sur les données en streaming.
- Scalabilité. Tirer parti de l’architecture distribuée de Kafka garantit la scalabilité.
- Intégration. S’intègre facilement avec les pipelines existants basés sur Kafka.
Défis et considérations
- Gestion de l’état. Les requêtes complexes peuvent nécessiter la gestion de grands états, ce qui pourrait affecter les performances.
- Optimisation des requêtes. Assurez-vous que les requêtes sont efficaces pour gérer des flux à haut débit.
- Sélection des outils. Choisissez le bon moteur SQL en fonction de vos besoins (par exemple, latence, complexité).
- Tolérance aux pannes. Les moteurs SQL en streaming doivent gérer les défaillances de nœuds et garantir la cohérence des données.
Conclusion
Le streaming SQL sur Kafka permet aux entreprises de tirer parti des données en temps réel avec la simplicité du SQL. Des outils tels que ksqlDB, Apache Flink et Spark Structured Streaming permettent de construire des pipelines de données robustes, évolutifs et à faible latence sans une expertise approfondie en programmation.
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka