













Les grandes organisations où le nombre d’utilisateurs accédant à des données cruciales est assez élevé doivent faire face à de nombreux défis en matière de gestion de l’accès détaillé.
Une variété de services AWS tels que IAM, Lake Formation et les ACL S3 peuvent aider à contrôler l’accès détaillé. Cependant, il existe des scénarios où une seule entité contenant les données mondiales doit être accessible par plusieurs groupes d’utilisateurs à travers le système avec un accès restrictif. De plus, les organisations ayant une présence mondiale peuvent travailler dans différents environnements et avec différents ensembles d’outils, ce qui rend le déplacement et le catalogage des données très fastidieux.
Par exemple, un utilisateur souhaite accéder aux données de ventes à partir d’une table à des fins analytiques, mais il devrait être restreint à n’accéder qu’aux données de ventes liées à la région de l’Australie. Aucune autre donnée ne devrait lui être visible. De plus, il souhaite accéder aux données à partir d’une plateforme cloud différente pour des opérations DML multiples, il doit donc importer les données et les transformer dans le format natif de l’outil pour le traitement, ce qui entraîne des retards.
Pour ce type de scénario, nous avons besoin d’un contrôle des données au niveau des attributs et des données à travers les environnements pour prendre en charge les formats natifs des outils et permettre un accès plus rapide.
Nous avons franchi une étape pour relever ces défis et fournir une solution de transformation cloud en utilisant Lake Formation pour la gouvernance des données sur les tables Apache Iceberg, qui peuvent être interrogées et cataloguées dans AWS S3 et accessibles sur différentes plateformes et clouds.
En utilisant l’option de filtrage des données dans Lake Formation, nous pouvons garantir la sécurité au niveau des colonnes, la sécurité au niveau des lignes et la sécurité au niveau des cellules.
Qu’est-ce que le format de table Iceberg ?
Iceberg est un format de table open-source avec les avantages suivants :
- Iceberg prend en charge pleinement les commandes SQL flexibles, rendant possible la mise à jour, la fusion et la suppression des données. Iceberg peut être utilisé pour réécrire les fichiers de données afin d’améliorer les performances de lecture et utiliser les deltas de suppression pour accélérer le rythme des mises à jour.
- Iceberg prend en charge l’évolution complète du schéma. Les mises à jour de schéma dans les tables Iceberg ne changent que les métadonnées, laissant les fichiers de données eux-mêmes inchangés. Les changements d’évolution de schéma incluent des ajouts, des suppressions, des renommages, des réordonnancements et des promotions de type.
- Les données stockées dans une architecture de lac de données ou de maillage de données sont disponibles pour plusieurs applications indépendantes au sein d’une organisation simultanément.
- Iceberg est conçu pour être utilisé avec d’énormes ensembles de données analytiques. Il offre plusieurs fonctionnalités visant à augmenter la vitesse et l’efficacité des requêtes, y compris la planification rapide des analyses, l’élagage des fichiers de métadonnées inutiles et la capacité de filtrer les fichiers de données qui ne contiennent pas de données correspondantes.
Présentation de la solution
La solution que nous avons proposée consiste à utiliser le service Lake Formation pour créer des filtres de données sur lesquels nous pouvons accorder des autorisations aux utilisateurs pour accéder. Le cœur de la solution repose sur l’utilisation du format de table Iceberg, qui est catalogué puis ajouté avec des conditions de filtre pour régir l’accès.

Flux de données
- DMS ou Glue est utilisé pour récupérer les données des dépôts du système source afin de les stocker dans un bucket S3 désigné.
- L’architecture basée sur des événements déclenche un événement lorsque S3 envoie des données pour appeler la fonction Lambda respective et démarrer le processus ETL.
- Les données seront stockées au format de table Iceberg et seront cataloguées.
- Les données peuvent être traitées et transformées à l’aide de Glue, en tirant parti des modèles prêts à l’emploi de GenAI.
- Les données traitées seront stockées dans Redshift pour consommation.
- Les tables Iceberg cataloguées seront ajoutées avec la colonne de balise (la valeur de la balise est mappée au groupe d’utilisateurs).
L’image ci-dessous décrit un exemple de filtre de données et à quoi il ressemble. Nous pouvons également limiter le nombre de colonnes en utilisant les filtres de données.
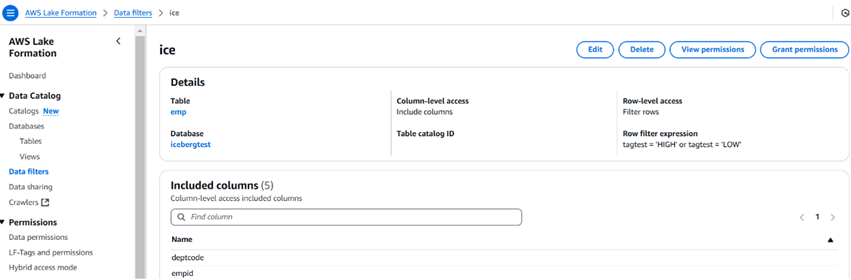
Une fois le filtre créé, nous pouvons ensuite utiliser l’option d’octroi de permission pour donner des autorisations aux utilisateurs, rôles, groupes et comptes. L’utilisateur peut utiliser Athena pour interroger les données.
Les diverses fonctionnalités de notre solution sont :
- Capacité de gérer efficacement le contrôle fin de l’accès aux données.
- Réutilisabilité des filtres de données pour plusieurs groupes d’utilisateurs.
- Nous pouvons atteindre la sécurité au niveau des colonnes, des lignes et des cellules.
- Utilisation efficace des fonctionnalités du format de table Apache Iceberg pour un contrôle transparent sur les données et leur accès.
- Efficacité et efficience dans la préparation des données.
- Gestion centralisée de l’accès et gouvernance en utilisant lake formation.
- Moins d’intervention manuelle dans la solution entièrement intégrée.
- Livraison de bout en bout des données en utilisant une solution agnostique au cloud et des composants serverless pour fournir évolutivité et rentabilité.
Avantages
- Efficacité opérationnelle. L’utilisation de composants serverless réduit les frais généraux opérationnels et de maintenance liés à sa gestion.
- Optimisation des efforts. Réduction des efforts jusqu’à 20-30 % en utilisant les modèles GenAI pour générer des scripts ETL standardisés et efficaces.
- Avantages en matière de gouvernance et conformité. Le contrôle basé sur les attributs dans lake formation aide à respecter les réglementations standard et à fournir des capacités d’audit et de journalisation.
Utilisation industrielle
La gouvernance au niveau des attributs utilisant les tables Apache Iceberg peut être mise en œuvre de manière très fluide dans le secteur financier, comme une banque ou une compagnie d’assurance, où les clients doivent avoir un accès restreint aux données, garantissant l’authenticité et la sécurité des données. Le secteur de la santé peut l’utiliser pour générer et partager rapidement le dossier de santé électronique du patient, en garantissant la sensibilité des données, ce qui peut conduire à un traitement et une médication en temps opportun.
Conclusion
Ainsi, la solution globale fournira une gouvernance au niveau des attributs à grande échelle avec une préparation des données de manière rapide en utilisant le format de table Apache Iceberg nécessaire pour la plupart des organisations et en mettant en œuvre la solution en s’appuyant sur les services Cloud d’Amazon, qui offre l’avantage de gains rapides, de coûts optimaux et d’une évolutivité illimitée.
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables