













Introduction
La régression linéaire multiple est une technique statistique fondamentale utilisée pour modéliser la relation entre une variable dépendante et plusieurs variables indépendantes. En Python, des outils comme scikit-learn et statsmodels offrent des implémentations robustes pour l’analyse de régression. Ce tutoriel vous guidera à travers l’implémentation, l’interprétation et l’évaluation des modèles de régression linéaire multiple en utilisant Python.
Prérequis
Avant de plonger dans l’implémentation, assurez-vous de disposer des éléments suivants :
- Une compréhension de base de Python. Vous pouvez vous référer au Tutoriel Python pour débutants.
- Familiarité avec scikit-learn pour les tâches d’apprentissage automatique. Vous pouvez vous référer au Tutoriel Python scikit-learn.
- Compréhension des concepts de visualisation des données en Python. Vous pouvez consulter Comment tracer des données en Python 3 en utilisant matplotlib et Analyses et visualisations de données avec pandas et Jupyter Notebook en Python 3.
- Python 3.x est installé avec les bibliothèques suivantes
numpy,pandas,matplotlib,seaborn,scikit-learn, etstatsmodelsinstallées.
Qu’est-ce que la régression linéaire multiple?
La régression linéaire multiple (MLR) est une méthode statistique qui modélise la relation entre une variable dépendante et deux ou plusieurs variables indépendantes. C’est une extension de la régression linéaire simple, qui modélise la relation entre une variable dépendante et une seule variable indépendante. En MLR, la relation est modélisée à l’aide de la formule:
.png)
Où:
.png)
Exemple : Prédire le prix d’une maison en fonction de sa taille, du nombre de chambres et de l’emplacement. Dans ce cas, il y a trois variables indépendantes, c’est-à-dire la taille, le nombre de chambres et l’emplacement, et une variable dépendante, c’est-à-dire le prix, qui est la valeur à prédire.
Hypothèses de la régression linéaire multiple
Avant de mettre en œuvre la régression linéaire multiple, il est essentiel de s’assurer que les hypothèses suivantes sont respectées :
-
Linéarité: La relation entre la variable dépendante et les variables indépendantes est linéaire.
-
Indépendance des erreurs: Les résidus (erreurs) sont indépendants les uns des autres. Cela est souvent vérifié à l’aide du test de Durbin-Watson.
-
Homoscédasticité: La variance des résidus est constante à tous les niveaux des variables indépendantes. Un graphique des résidus peut aider à vérifier cela.
-
Aucune Multicolinéarité: Les variables indépendantes ne sont pas fortement corrélées. Facteur d’Inflation de Variance (VIF) est couramment utilisé pour détecter la multicolinéarité.
-
Normalité des Résidus: Les résidus doivent suivre une distribution normale. Cela peut être vérifié à l’aide d’un diagramme Q-Q.
-
Influence des Valeurs Abérantes: Les valeurs aberrantes ou les points à forte influence ne doivent pas influencer de manière disproportionnée le modèle.
Ces hypothèses garantissent que le modèle de régression est valide et que les résultats sont fiables. Le non-respect de ces hypothèses peut conduire à des résultats biaisés ou trompeurs.
Prétraiter les données
Dans cette section, vous apprendrez à utiliser le modèle de régression linéaire multiple en Python pour prédire les prix des maisons en fonction des caractéristiques du Jeu de données sur le logement en Californie. Vous apprendrez comment prétraiter les données, ajuster un modèle de régression et évaluer sa performance en traitant des défis courants tels que la multicolinéarité, les valeurs aberrantes et la sélection des caractéristiques.
Étape 1 – Charger le jeu de données
Vous utiliserez le Jeu de données sur le logement en Californie, un ensemble de données populaire pour les tâches de régression. Cet ensemble de données contient 13 caractéristiques sur des maisons dans les banlieues de Boston et leur prix médian correspondant.
Tout d’abord, installons les packages nécessaires :
Vous devriez observer la sortie suivante du jeu de données :
Voici la signification de chacun des attributs :
| Variable | Description |
|---|---|
| MedInc | Revenu médian dans le bloc |
| HouseAge | Âge médian des maisons dans le bloc |
| AveRooms | Nombre moyen de pièces |
| AveBedrms | Nombre moyen de chambres |
| Population | Population du bloc |
| AveOccup | Taux d’occupation moyen des maisons |
| Latitude | Latitude du bloc de maisons |
| Longitude | Longitude du bloc de maisons |
Étape 2 – Prétraiter les Données
Vérifiez les Valeurs Manquantes
Assurez-vous qu’il n’y a pas de valeurs manquantes dans le jeu de données qui pourraient affecter l’analyse.
Sortie :
Sélection des Caractéristiques
Commençons par créer une matrice de corrélation pour comprendre les dépendances entre les variables.
Sortie :
Vous pouvez analyser la matrice de corrélation ci-dessus pour sélectionner les variables dépendantes et indépendantes pour notre modèle de régression. La matrice de corrélation fournit des informations sur les relations entre chaque paire de variables dans le jeu de données.
Dans la matrice de corrélation donnée, MedHouseValue est la variable dépendante, car c’est la variable que nous essayons de prédire. Les variables indépendantes ont une corrélation significative avec MedHouseValue.
Sur la base de la matrice de corrélation, vous pouvez identifier les variables indépendantes suivantes qui ont une corrélation significative avec MedHouseValue :
MedInc: Cette variable a une forte corrélation positive (0.688075) avecMedHouseValue, indiquant qu’à mesure que le revenu médian augmente, la valeur médiane des maisons a également tendance à augmenter.AveRooms: Cette variable a une corrélation positive modérée (0.151948) avecMedHouseValue, suggérant qu’à mesure que le nombre moyen de chambres par ménage augmente, la valeur médiane des maisons a également tendance à augmenter.AveOccup: Cette variable a une faible corrélation négative (-0,023737) avecMedHouseValue, ce qui indique qu’à mesure que l’occupation moyenne par ménage augmente, la valeur médiane des maisons tend à diminuer, mais l’effet est relativement faible.
En sélectionnant ces variables indépendantes, vous pouvez construire un modèle de régression qui capture les relations entre ces variables et MedHouseValue, nous permettant de faire des prédictions sur la valeur médiane des maisons en fonction du revenu médian, du nombre moyen de pièces et de l’occupation moyenne.
Vous pouvez également tracer la matrice de corrélation en Python en utilisant le code ci-dessous :
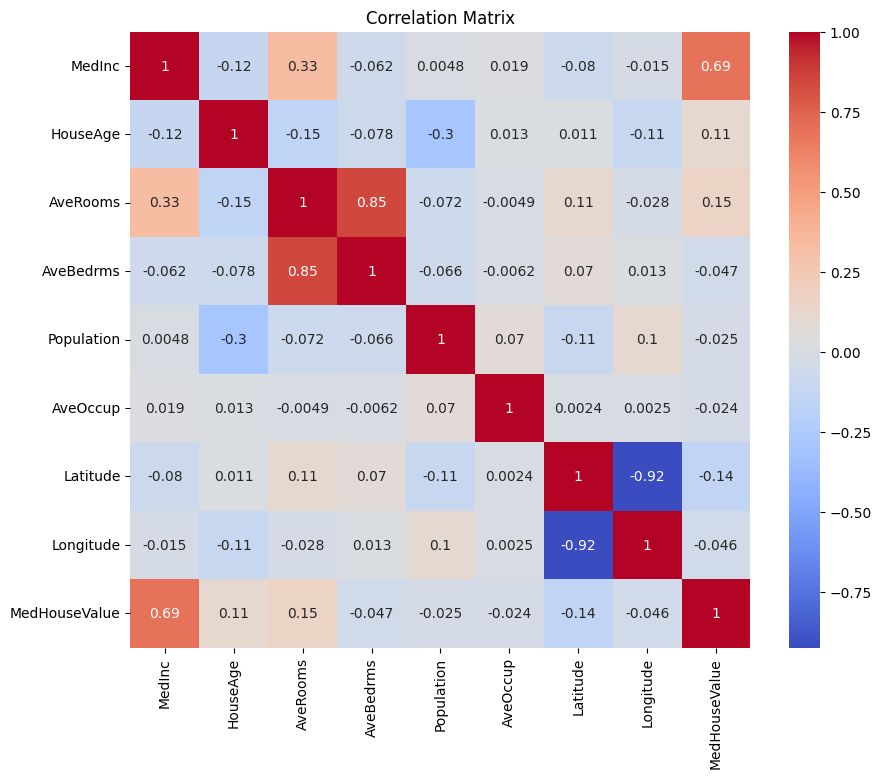
Vous vous concentrerez sur quelques caractéristiques clés pour la simplicité, basées sur ce qui précède, telles que MedInc (revenu médian), AveRooms (nombre moyen de pièces par ménage) et AveOccup (occupation moyenne par ménage).
Le bloc de code ci-dessus sélectionne des caractéristiques spécifiques du DataFrame housing_df pour analyse. Les caractéristiques sélectionnées sont MedInc, AveRooms et AveOccup, qui sont stockées dans la liste selected_features.
Le DataFrame housing_df est ensuite sous-ensemble pour inclure uniquement ces caractéristiques sélectionnées et le résultat est stocké dans la liste X.
La variable cible MedHouseValue est extraite de housing_df et stockée dans la liste y.
Normalisation des caractéristiques
Vous utiliserez la standardisation pour garantir que toutes les caractéristiques sont sur la même échelle, améliorant ainsi la performance et la comparabilité du modèle.
La standardisation est une technique de prétraitement qui met à l’échelle les caractéristiques numériques pour avoir une moyenne de 0 et un écart type de 1. Ce processus garantit que toutes les caractéristiques sont sur la même échelle, ce qui est essentiel pour les modèles d’apprentissage automatique sensibles à l’échelle des caractéristiques d’entrée. En standardisant les caractéristiques, vous pouvez améliorer la performance et la comparabilité du modèle en réduisant l’effet des caractéristiques ayant de grandes plages qui dominent le modèle.
Sortie:
La sortie représente les valeurs mises à l’échelle des caractéristiques MedInc, AveRooms et AveOccup après l’application du StandardScaler. Les valeurs sont désormais centrées autour de 0 avec un écart type de 1, garantissant que toutes les caractéristiques sont sur la même échelle.
La première ligne [ 2.34476576 0.62855945 -0.04959654] indique que pour le premier point de données, la valeur mise à l’échelle de MedInc est 2.34476576, AveRooms est 0.62855945, et AveOccup est -0.04959654. De même, la deuxième ligne [ 2.33223796 0.32704136 -0.09251223] représente les valeurs mises à l’échelle pour le deuxième point de données, et ainsi de suite.
Les valeurs mises à l’échelle varient d’environ -1,14259331 à 2,34476576, ce qui indique que les caractéristiques sont désormais normalisées et comparables. Cela est essentiel pour les modèles d’apprentissage automatique qui sont sensibles à l’échelle des caractéristiques d’entrée, car cela empêche les caractéristiques avec de grandes plages de dominer le modèle.
Implémenter la régression linéaire multiple
Maintenant que vous avez terminé le prétraitement des données, implémentons la régression linéaire multiple en Python.
La fonction train_test_split est utilisée pour diviser les données en ensembles d’entraînement et de test. Ici, 80 % des données sont utilisées pour l’entraînement et 20 % pour le test.
Le modèle est évalué à l’aide de l’erreur quadratique moyenne et du R-carré. L’erreur quadratique moyenne (MSE) mesure la moyenne des carrés des erreurs ou des écarts.
Le R-carré (R2) est une mesure statistique qui représente la proportion de la variance d’une variable dépendante qui est expliquée par une variable indépendante ou des variables dans un modèle de régression.
Sortie :
La sortie ci-dessus fournit deux indicateurs clés pour évaluer la performance du modèle de régression linéaire multiple :
Erreur quadratique moyenne (EQM) : 0.7006855912225249
L’EQM mesure la différence moyenne au carré entre les valeurs prédites et les valeurs réelles de la variable cible. Un EQM plus bas indique de meilleures performances du modèle, car cela signifie que le modèle fait des prédictions plus précises. Dans ce cas, l’EQM est 0.7006855912225249, ce qui indique que le modèle n’est pas parfait mais possède un niveau de précision raisonnable. Les valeurs de l’EQM devraient généralement se rapprocher de 0, des valeurs plus basses indiquant de meilleures performances.
R-carré (R2) : 0.4652924370503557
R-carré mesure la proportion de la variance dans la variable dépendante qui peut être prédite à partir des variables indépendantes. Il varie de 0 à 1, où 1 représente une prédiction parfaite et 0 indique qu’il n’y a aucune relation linéaire. Dans ce cas, la valeur de R-carré est 0.4652924370503557, ce qui indique qu’environ 46,53 % de la variance de la variable cible peut être expliquée par les variables indépendantes utilisées dans le modèle. Cela suggère que le modèle est capable de capturer une partie significative des relations entre les variables mais pas toutes.
Examinons quelques graphiques importants :

.png)
Utilisation de statsmodels
La bibliothèque Statsmodels en Python est un outil puissant pour l’analyse statistique. Elle offre un large éventail de modèles et de tests statistiques, y compris la régression linéaire, l’analyse des séries chronologiques et des méthodes non paramétriques.
Dans le cadre de la régression linéaire multiple, statsmodels peut être utilisé pour ajuster un modèle linéaire aux données, puis pour effectuer divers tests et analyses statistiques sur le modèle. Cela peut être particulièrement utile pour comprendre les relations entre les variables indépendantes et dépendantes, et pour faire des prédictions basées sur le modèle.
Sortie:
Voici le résumé du tableau ci-dessus :
Résumé du modèle
Le modèle est un modèle de régression des moindres carrés ordinaires, qui est un type de modèle de régression linéaire. La variable dépendante est MedHouseValue, et le modèle a une valeur de R² de 0,485, ce qui indique qu’environ 48,5 % de la variation de MedHouseValue peut être expliquée par les variables indépendantes. La valeur ajustée de R² est de 0,484, qui est une version modifiée de R² qui pénalise le modèle pour l’inclusion de variables indépendantes supplémentaires.
Ajustement du modèle
Le modèle a été ajusté en utilisant la méthode des moindres carrés, et la statistique F est de 5173, ce qui indique que le modèle est bien ajusté. La probabilité d’observer une statistique F au moins aussi extrême que celle observée, en supposant que l’hypothèse nulle est vraie, est d’environ 0. Cela suggère que le modèle est statistiquement significatif.
Coefficients du modèle
Les coefficients du modèle sont les suivants :
- Le terme constant est de 2,0679, ce qui indique que lorsque toutes les variables indépendantes sont à 0, la
MedHouseValueprédite est d’environ 2,0679. - Le coefficient pour
x1(dans ce cas,MedInc) est de 0,8300, ce qui indique que pour chaque augmentation d’une unité deMedInc, laMedHouseValueprédite augmente d’environ 0,83 unités, en supposant que toutes les autres variables indépendantes sont maintenues constantes. - Le coefficient pour
x2(dans ce casAveRooms) est de -0,1000, ce qui indique que pour chaque augmentation d’une unité dex2, la valeur prédite deMedHouseValuediminue d’environ 0,10 unité, en supposant que toutes les autres variables indépendantes sont maintenues constantes. - Le coefficient pour
x3(dans ce casAveOccup) est de -0,0397, ce qui indique que pour chaque augmentation d’une unité dex3, la valeur prédite deMedHouseValuediminue d’environ 0,04 unité, en supposant que toutes les autres variables indépendantes sont maintenues constantes.
Diagnostic du modèle
Les diagnostics du modèle sont les suivants :
- La statistique du test Omnibus est de 3981,290, ce qui indique que les résidus ne suivent pas une distribution normale.
- La statistique de Durbin-Watson est de 1,983, ce qui indique qu’il n’y a pas d’autocorrélation significative dans les résidus.
- La statistique du test de Jarque-Bera est de 11583,284, ce qui indique que les résidus ne suivent pas une distribution normale.
- La skewness des résidus est de 1,260, ce qui indique qu’ils sont asymétriques vers la droite.
- La kurtosis des résidus est de 6,239, ce qui indique qu’ils sont leptokurtiques (c’est-à-dire qu’ils ont un pic plus élevé et des queues plus lourdes qu’une distribution normale).
- Le nombre de condition est de 1,42, ce qui indique que le modèle n’est pas sensible aux petites variations des données.
.png)
Gestion de la multicolinéarité
La multicolinéarité est un problème courant dans la régression linéaire multiple, où deux ou plusieurs variables indépendantes sont fortement corrélées entre elles. Cela peut conduire à des estimations instables et peu fiables des coefficients.
Pour détecter et gérer la multicolinéarité, vous pouvez utiliser le Facteur d’Inflation de Variance. Le VIF mesure combien la variance d’un coefficient de régression estimé augmente si vos prédicteurs sont corrélés. Un VIF de 1 signifie qu’il n’y a pas de corrélation entre un prédicteur donné et les autres prédicteurs. Des valeurs VIF dépassant 5 ou 10 indiquent une quantité problématique de collinéarité.
Dans le bloc de code ci-dessous, calculons le VIF pour chaque variable indépendante de notre modèle. Si une valeur VIF est supérieure à 5, vous devriez envisager de supprimer la variable du modèle.
Sortie:
Les valeurs VIF pour chaque caractéristique sont les suivantes :
MedInc: La valeur VIF est 1.120166, indiquant une très faible corrélation avec les autres variables indépendantes. Cela suggère queMedIncn’est pas fortement corrélé avec les autres variables indépendantes dans le modèle.AveRooms: La valeur VIF est 1.119797, indiquant une très faible corrélation avec les autres variables indépendantes. Cela suggère queAveRoomsn’est pas fortement corrélé avec les autres variables indépendantes dans le modèle.AveOccup: La valeur VIF est de 1,000488, ce qui indique qu’il n’y a pas de corrélation avec les autres variables indépendantes. Cela suggère queAveOccupn’est pas corrélé avec les autres variables indépendantes du modèle.
En général, ces valeurs VIF sont toutes inférieures à 5, ce qui indique qu’il n’y a pas de multicollinéarité significative entre les variables indépendantes du modèle. Cela suggère que le modèle est stable et fiable, et que les coefficients des variables indépendantes ne sont pas significativement affectés par la multicollinéarité.
.png)
Techniques de validation croisée
La validation croisée est une technique utilisée pour évaluer les performances d’un modèle d’apprentissage automatique. Il s’agit d’une procédure de rééchantillonnage utilisée pour évaluer un modèle lorsque nous disposons d’un échantillon de données limité. La procédure a un seul paramètre appelé k qui fait référence au nombre de groupes dans lesquels un échantillon de données donné doit être divisé. En tant que telle, la procédure est souvent appelée validation croisée k-fold.
Sortie :
Les scores de validation croisée indiquent la performance du modèle sur des données invisibles. Les scores varient de 0,31191043 à 0,51269138, ce qui indique que les performances du modèle varient d’un pli à l’autre. Un score plus élevé indique de meilleures performances.
Le score moyen CV R^2 est de 0.41864482644003276, ce qui suggère qu’en moyenne, le modèle explique environ 41,86 % de la variance de la variable cible. C’est un niveau d’explication modéré, indiquant que le modèle est quelque peu efficace pour prédire la variable cible mais pourrait bénéficier d’une amélioration ou d’un perfectionnement supplémentaire.
Ces scores peuvent être utilisés pour évaluer la généralisabilité du modèle et identifier les domaines potentiels d’amélioration.
.png)
Méthodes de sélection de caractéristiques
La méthode Élimination Récursive de Caractéristiques est une technique de sélection de caractéristiques qui élimine de manière récursive les caractéristiques les moins importantes jusqu’à ce qu’un nombre spécifié de caractéristiques soit atteint. Cette méthode est particulièrement utile lorsqu’il s’agit d’un grand nombre de caractéristiques et que l’objectif est de sélectionner un sous-ensemble des caractéristiques les plus informatives.
Dans le code fourni, vous importez d’abord la classe RFE de sklearn.feature_selection. Ensuite, créez une instance de RFE avec un estimateur spécifié (dans ce cas, LinearRegression) et définissez n_features_to_select à 2, indiquant que nous voulons sélectionner les 2 meilleures caractéristiques.
Ensuite, nous adaptons l’objet RFE à nos fonctionnalités mises à l’échelle X_scaled et à la variable cible y. L’attribut support_ de l’objet RFE renvoie un masque booléen indiquant quelles fonctionnalités ont été sélectionnées.
Pour visualiser le classement des fonctionnalités, vous créez un DataFrame avec les noms des fonctionnalités et leurs classements correspondants. L’attribut ranking_ de l’objet RFE renvoie le classement de chaque fonctionnalité, les valeurs plus basses indiquant des fonctionnalités plus importantes. Vous tracez ensuite un graphique à barres des classements des fonctionnalités, triées par leurs valeurs de classement. Ce graphique nous aide à comprendre l’importance relative de chaque fonctionnalité dans le modèle.
Sortie:
.png)
Basé sur le graphique ci-dessus, les 2 fonctionnalités les plus adaptées sont MedInc et AveRooms. Cela peut également être vérifié par la sortie du modèle ci-dessus car la variable dépendante MedHouseValue dépend principalement de MedInc et AveRooms.
FAQs
Comment implémenter une régression linéaire multiple en Python?
Pour implémenter une régression linéaire multiple en Python, vous pouvez utiliser des bibliothèques telles que statsmodels ou scikit-learn. Voici un aperçu rapide en utilisant scikit-learn:
Ceci démontre comment ajuster le modèle, obtenir les coefficients et faire des prédictions.
Quelles sont les hypothèses de la régression linéaire multiple en Python ?
La régression linéaire multiple repose sur plusieurs hypothèses pour garantir des résultats valides :
- Linéarité : La relation entre les variables prédictives et la variable cible est linéaire.
- Indépendance : Les observations sont indépendantes les unes des autres.
- Homoscédasticité : La variance des résidus (erreurs) est constante à tous les niveaux des variables indépendantes.
- Normalité des résidus : Les résidus suivent une distribution normale.
- Pas de Multicolinéarité: Les variables indépendantes ne sont pas fortement corrélées entre elles.
Vous pouvez tester ces hypothèses en utilisant des outils tels que des graphiques résiduels, le Facteur d’Inflation de la Variance (VIF), ou des tests statistiques.
Comment interpréter les résultats de la régression multiple en Python?
Les principales métriques des résultats de la régression comprennent:
- Coefficients (coef_): Indiquent le changement de la variable cible pour un changement unitaire du prédicteur correspondant, en maintenant les autres variables constantes.
Exemple: Un coefficient de 2 pour X1 signifie que la variable cible augmente de 2 pour chaque augmentation de 1 unité de X1, en maintenant les autres variables constantes.
2.Intercept (intercept_): Représente la valeur prédite de la variable cible lorsque tous les prédicteurs sont nuls.
3.R-carré: Explique la proportion de la variance de la variable cible expliquée par les prédicteurs.
Exemple: Un R^2 de 0,85 signifie que 85% de la variabilité de la variable cible est expliquée par le modèle.
4.Valeurs P (dans statsmodels): Évaluent la signification statistique des prédicteurs. Une valeur p< 0,05 indique généralement qu’un prédicteur est significatif.
Quelle est la différence entre la régression linéaire simple et multiple en Python?
| Feature | Simple Linear Regression | Multiple Linear Regression |
|---|---|---|
| Nombre de variables indépendantes | Une | Plus d’une |
| Équation du modèle | y = β0 + β1x + ε | y = β0 + β1×1 + β2×2 + … + βnxn + ε |
| Hypothèses | Les mêmes que pour la régression linéaire multiple, mais avec une seule variable indépendante | Les mêmes que pour la régression linéaire simple, mais avec des hypothèses supplémentaires pour plusieurs variables indépendantes |
| Interprétation des coefficients | Le changement de la variable cible pour un changement unitaire de la variable indépendante, tout en maintenant les autres variables constantes (non applicable en régression linéaire simple) | Le changement de la variable cible pour un changement unitaire d’une variable indépendante, tout en maintenant les autres variables indépendantes constantes |
| Complexité du modèle | Moins complexe | Plus complexe |
| Flexibilité du modèle | Moins flexible | Plus flexible |
| Risque de surajustement | Moins élevé | Plus élevé |
| Interprétabilité | Plus facile à interpréter | Plus difficile à interpréter |
| Applicabilité | Adapté aux relations simples | Adapté aux relations complexes avec plusieurs facteurs |
| Exemple | Prédire les prix des maisons en fonction du nombre de chambres | Prédire les prix des maisons en fonction du nombre de chambres, de la superficie et de l’emplacement |
Conclusion
Dans ce tutoriel complet, vous avez appris à mettre en œuvre la régression linéaire multiple en utilisant le jeu de données sur le logement en Californie. Vous avez abordé des aspects cruciaux tels que la multicolinéarité, la validation croisée, la sélection des caractéristiques et la régularisation, offrant une compréhension approfondie de chaque concept. Vous avez également appris à incorporer des visualisations pour illustrer les résidus, l’importance des caractéristiques et les performances globales du modèle. Vous pouvez désormais facilement construire des modèles de régression robustes en Python et appliquer ces compétences à des problèmes concrets.
Source:
https://www.digitalocean.com/community/tutorials/multiple-linear-regression-python