













Dans cet article court, nous explorerons les approbations de prêts en utilisant une variété d’outils et de techniques. Nous commencerons par analyser les données de prêt et appliquer la régression logistique pour prédire les sorties de prêt. En s’appuyant sur cela, nous intégrerons BERT pour le traitement du langage naturel afin d’améliorer l’accuracité de la prédiction. Pour interpréter les prédictions, nous utiliserons les cadres d’explication SHAP et LIME, offrant des insights sur l’importance des caractéristiques et le comportement du modèle. Enfin, nous explorerons le potentiel du traitement du langage naturel par le biais de LangChain pour automatiser les predictions de prêts, en utilisant la force de l’IA conversationnelle.
Le fichier notebook utilisé dans cet article est disponible sur GitHub.
Introduction
Dans cet article, nous explorerons diverses techniques pour les approbations de prêts, en utilisant des modèles tels que la régression logistique et BERT, et en appliquant SHAP et LIME pour l’interprétation du modèle. Nous verrons également le potentiel d’utiliser LangChain pour automatiser les prédictions de prêts avec l’IA conversationnelle.
Créer un Compte SingleStore Cloud
Un article précédent a montré les étapes pour créer un compte SingleStore Cloud gratuit. Nous utiliserons la Tranche Partagée Gratuite et prendremos les noms par défaut pour le Workspace et la Base de données.
Importer le Notebook
Nous téléchargerons le notebook de GitHub (lien mentionné plus tôt).
Dans la navigateur du portail SingleStore Cloud, situé dans la barre de navigation de gauche, nous sélectionnerons DEVELOP > Data Studio.
En haut à droite de la page web, nous sélectionnerons New Notebook > Import From File. Nous utiliserons l’assistant pour localiser et importer le carnet que nous avons téléchargé depuis GitHub.
Exécuter le Carnet
Apres avoir vérifié que nous sommes connectés à notre espace de travail SingleStore, nous exécuterons les cellules une par une.
Nous commencerons par installer les bibliothèques nécessaires et importer les dépendances, suivi du chargement des données de prêt depuis un fichier CSV contenant environ 600 lignes. Comme certaines lignes contiennent des données manquantes, nous supprimerons les cellules incomplètes pour l’analyse initiale, réduisant le jeu de données à environ 500 lignes.
Ensuite, nous préparerons davantage les données et séparons les caractéristiques et les variables cibles.
Les visualisations peuvent fournir de grands aperçus des données, et nous commencerons par créer une carte des chaleurs montrant la corrélation entre les caractéristiques numériques uniquement, comme illustré dans la Figure 1.
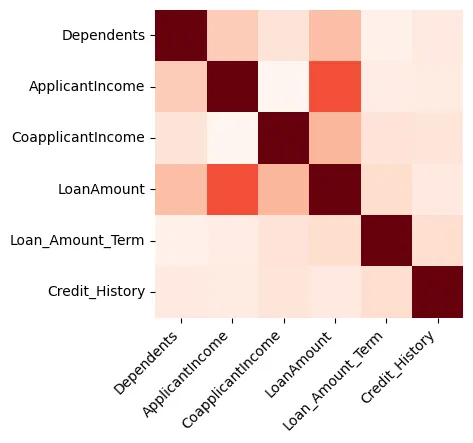
Figure 1 : Carte des chaleurs
Nous pouvons voir que le Montant du prêt et le Revenu de la demandeuse sont fortement corrélés.
Si nous traceons le Montant du prêt contre le Revenu de la demandeuse, nous pouvons voir que la plupart des points de données se trouvent dans le coin inférieur gauche du diagramme de dispersion, comme illustré dans la Figure 2.
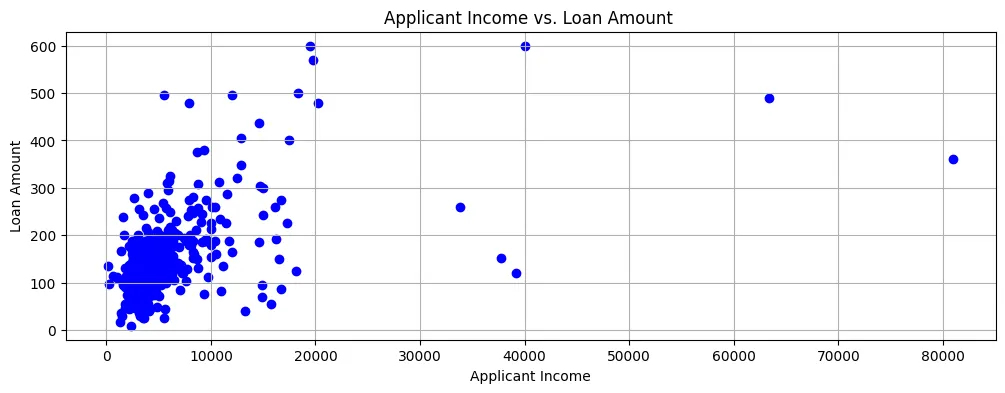
Figure 2 : Diagramme de dispersion
Ainsi, les revenus sont généralement assez bas et les demandes de prêt sont également pour des montants relativement petits.
Nous pouvons également créer un nuage de points pour le Montant du prêt, le Revenu du demandeur et le Revenu du co-demandeur, comme illustré sur la Figure 3.
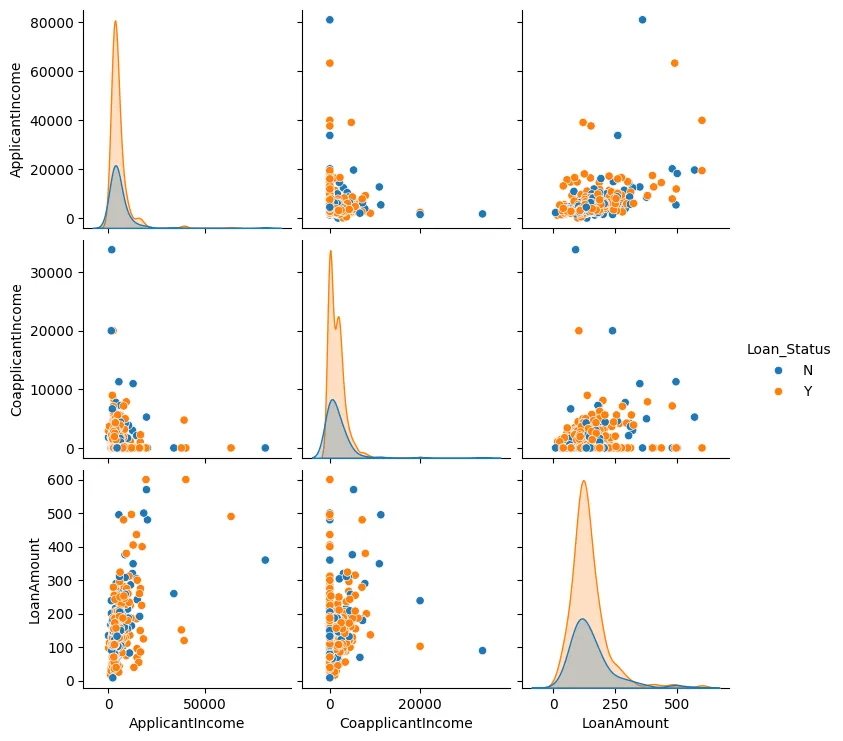
Figure 3 : Nuage de points
En général, nous observons que les points de données tendent à se regrouper et qu’il y a généralement peu d’outliers.
Nous effectuons maintenant une ingénierie des caractéristiques. Nous identifierons les valeurs catégorielles et les convertirons en valeurs numériques, et nous utiliserons également l’encodage one-hot où nécessaire.
Ensuite, nous créerons un modèle à l’aide de Régression logistique puisque deux résultats seulement sont possibles : soit le prêt est approuvé, soit il est refusé.
Si nous visualisons l’importance des caractéristiques, nous pouvons faire quelques observations intéressantes, comme illustré sur la Figure 4.
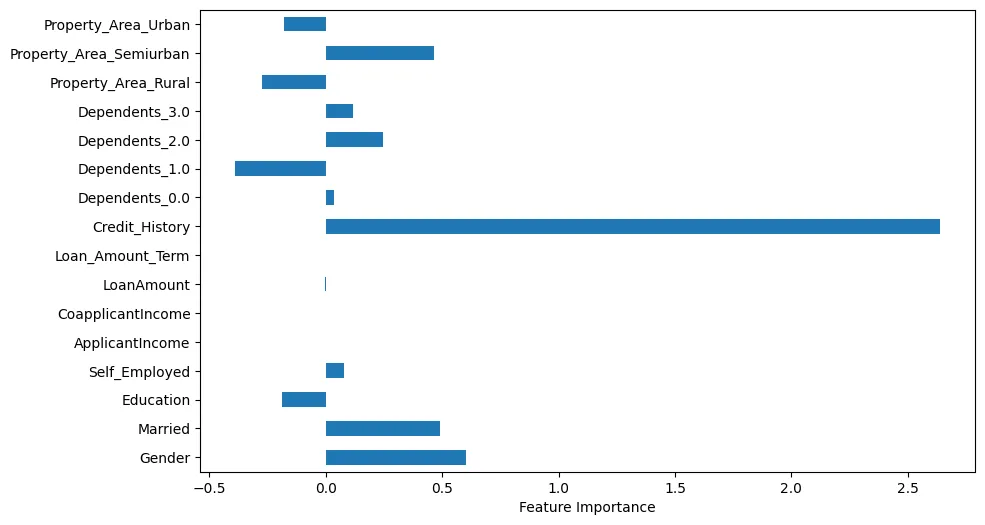
Figure 4 : Importance des caractéristiques
Par exemple, nous pouvons voir que Historique de crédit est manifestement très important. Cependant, Statut matrimonial et Le sexe sont également importants.
Nous ferons maintenant des prédictions à l’aide d’un échantillon de test.
Nous générerons un résumé de la demande de prêt à l’aide de Bidirectional Encoder Representations from Transformers (BERT) avec l’échantillon de test. Exemple de sortie :
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
En utilisant le résumé généré par BERT, nous créerons un nuage de mots comme illustré sur la Figure 5.

Nous pouvons voir que le nom du demandeur, son revenu et son historique de crédit sont plus grands et plus importants.
Une autre méthode que nous pouvons utiliser pour analyser les données de notre échantillon de test est l’utilisation de SHapley Additive exPlanations (SHAP). Dans la Figure 6, nous pouvons visualiser graphiquement les caractéristiques importantes.

Figure 6 : SHAP
Un diagramme de force SHAP est une autre méthode que nous pourrions utiliser pour analyser les données, comme illustré dans la Figure 7.
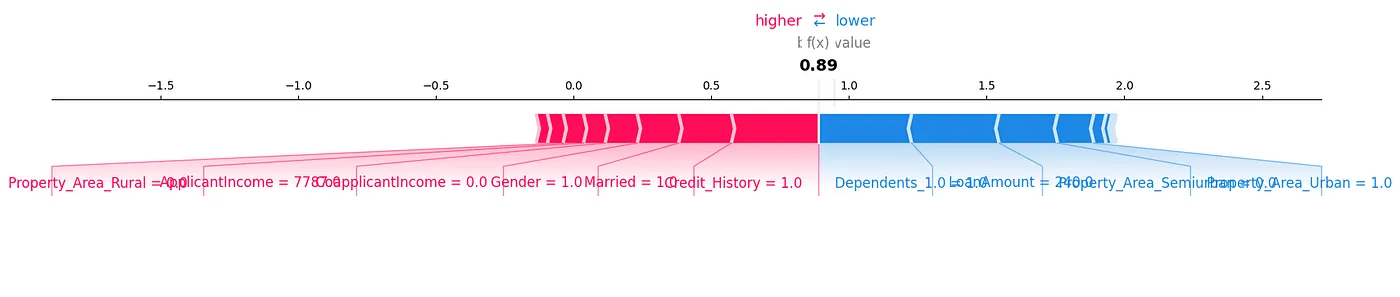
Figure 7 : Diagramme de force
Nous pouvons voir comment chaque caractéristique contribue à une prédiction particulière pour notre échantillon de test en montrant les valeurs SHAP de manière visuelle.
Une autre bibliothèque très utile est Local Interpretable Model-Agnostic Explanations (LIME). Les résultats pour cela peuvent être générés dans le notebook associé à cet article.
Ensuite, nous créerons une Matrice de confusion (Figure 8) pour notre modèle de régression logistique et générerons un rapport de classification.
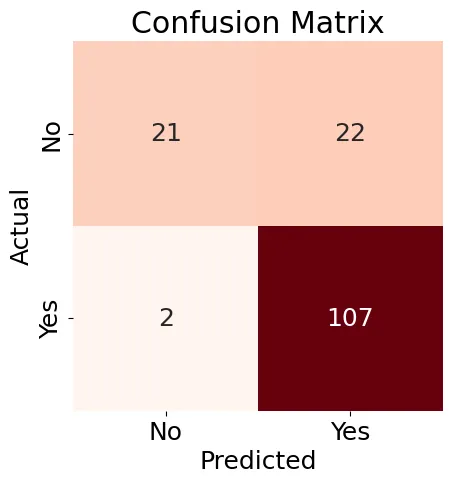
Figure 8 : Matrice de confusion
Les résultats affichés dans la Figure 8 sont un peu mixtes, mais le rapport de classification contient quelques bonnes résultats :
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
Globalement, nous pouvons constater que l’utilisation d’outils et de techniques de Machine Learning existants nous offre de nombreuses manières possibles d’analyser les données et de trouver des relations intéressantes, notamment au niveau d’un échantillon de test individuel.
Ensuite, essayons de utiliser LangChain et une LLM pour faire également des prédictions de prêt.
Une fois que nous avons configuré et réglé LangChain, nous le testerons avec deux exemples, mais limitant l’accès à la quantité de données pour ne pas dépasser les limites de jetons et de taux. Voici l’exemple suivant :
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
Dans ce cas, la demande a été approuvée dans l’ensemble de données original.
Voici le deuxième exemple :
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
Dans ce cas, la demande a été rejetée dans les données originales.
En exécutant ces requêtes, nous pourrions obtenir des résultats incohérents. Cela pourrait être dû au fait que la quantité de données utilisable est limitée. Nous pouvons également utiliser le mode verbeux dans LangChain pour voir les étapes utilisées pour construire un modèle d’approbation de prêt, mais à ce niveau initial, il n’y a pas suffisamment d’information sur les étapes détaillées créant ce modèle.
Il faut plus de travail avec l’IA conversationnelle, car de nombreux pays ont des règles de prêt équitable et nous aurions besoin d’une explication détaillée sur pourquoi l’IA a approuvé ou rejeté une demande de prêt particulière.
Résumé
Aujourd’hui, de nombreuses puissantes outils et techniques améliorent le Machine Learning (ML) pour des aperçus plus profonds dans les données et les modèles de prédiction de prêts. L’IA, grâce aux Grands Modèles de Langue (LLMs) et aux frameworks modernes, offre un grand potentiel pour augmenter ou même remplacer les approches traditionnelles de ML. Cependant, pour avoir plus de confiance dans les recommandations de l’IA et pour se conformer aux exigences légales et de prêt équitable dans de nombreux pays, il est crucial de comprendre la logique et le processus de décision de l’IA.
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals