













Les data scientists commencent rapidement à apprendre SQL. Cela est comprisable étant donné la ubiquité et l’utilité supérieure des informations tabulaires. Cependant, il existe d’autres formats de base de données couramment utilisés, tels que les bases de données graphes, pour stocker des données connectées qui ne s’inscrivent pas dans une base de données relationnelle SQL. Dans ce tutoriel, nous apprendrons à propos de Neo4j, un système de gestion de base de données graphe populaire que vous pouvez utiliser pour créer, gérer et interroger des bases de données graphes en Python.
Quelles sont les bases de données graphes ?
Avant de parler de Neo4j, essayons de mieux comprendre les bases de données graphes. Nous avons un article complet expliquant quelles sont les bases de données graphes, donc nous résumons les points clés ici.
Les bases de données graphes sont un type de base de données NoSQL (elles n’utilisent pas SQL) conçues pour gérer des données connectées. Contrairement aux bases de données relationnelles traditionnelles qui utilisent des tables et des lignes, les bases de données graphes utilisent des structures de graphes composées de :
- Noeuds (entités) tels que les personnes, les lieux, les concepts
- Frontières (relations) qui connectent différents noeuds comme personne VIE DANS un endroit, ou un footballeur A RATÉ UN BUT dans un match.
- Propriétés (attributs pour les nœuds/arêtes) telles que l’age d’une personne, ou au moment de la réalisation du but dans le match.
Cette structure rend les bases de données de graphes idéales pour gérer des données interconnectées dans les domaines et applications telles que les réseaux sociaux, les recommandations, la détection de fraude, etc., souvent supérieures aux BD relationnelles en termes de performance de requête. Voici la structure d’une base de données de graphe exemple pour une base de données de football :
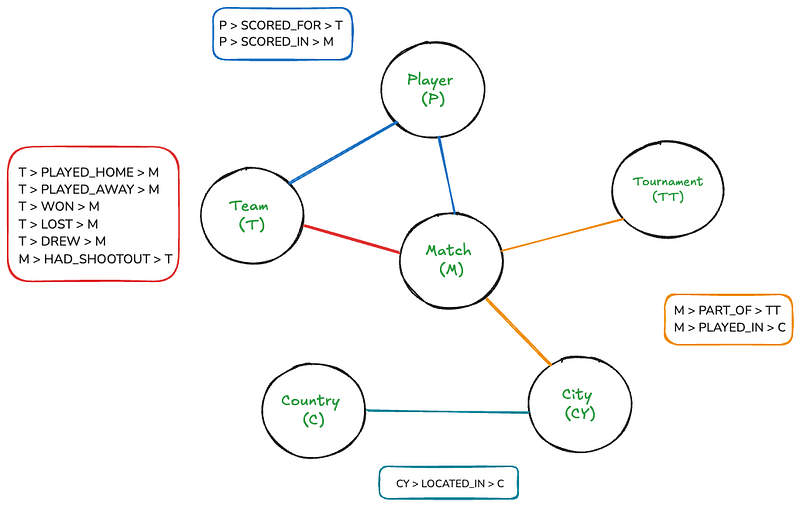
Bien que ce graphique représente quelque chose de relativement intuitif pour les humains, il peut devenir assez compliqué s’il est dessiné sur un canevas. Cependant, avec Neo4j, parcourir ce graphique sera aussi simple que d’écrire desjointures SQL.
Le graphique comporte six nœuds : Match, Equipe, Tournoi, Joueur, Pays et Ville. Les rectangles listent les relations existantes entre les nœuds. Il y a également quelques propriétés de nœuds et de relations :
- Match: date, but des points de domicile, points de l’équipe visiteuse
- Équipe: nom
- Joueur: nom
- Tournoi: nom
- Ville: nom
- Pays: nom
- POINTS_FAITS, POINTS_RECUS: minute, but_contre, pénalty
- A_EFFECTUÉ_UN_TIRAGE_ au_sort: gagnant, tireur_premier
Ce schéma nous permet de représenter :
- Tous les matchs avec leurs scores, dates et lieux
- Les équipes participant à chaque match (à domicile et à l’extérieur)
- Les joueurs marquant des buts, y compris des détails comme la minute, les buts contre son camp et les penaltys
- Les tournois dans lesquels les matchs se déroulent
- Les villes et pays où les matchs sont joués
- Informations sur les défis de tir, y compris les gagnants et les premiers tireurs (lorsqu’il s’en trouve)
Le schéma capture la nature hiérarchique des lieux (Ville au sein du Pays) et les diverses relations entre entités (p. ex., Équipes jouant des Matchs, Joueurs inscrivant des buts pour des Équipes dans des Matchs).
Cette structure permet des requêtes flexibles, telles que trouver tous les matchs entre deux équipes, tous les buts inscrits par un joueur ou tous les matchs dans un tournoi ou un endroit spécifique.
Mais ne nous écarterons pas de notre objet. Pour commencer, que sont Neo4j et pourquoi l’utiliser ?
Qu’est-ce que Neo4j ?
Neo4j, le nom de marque leader dans le domaine de la gestion de BDD graphe, est connu pour ses puissantes fonctionnalités et sa polyvalence.
Au cœur de Neo4j, on utilise un stockage de graphe natif, qui est hautement optimisé pour effectuer des opérations de graphe. Sa efficacité dans la gestion de relations complexes le rend supérieur à les bases de données traditionnelles pour les données connectées. La scalabilité de Neo4j est véritablement impressionnante : il peut gérer facilement des milliards d’nodes et de relations, ce qui le rend adapté à des projets petits comme à des entreprises grandes.
Un autre aspect clé de Neo4j est l’intégrité des données. Il est pleinement conforme à l’ACID (Atomicité, Consistance, Isolation, Durabilité), offrant ainsi une fiabilité et une cohérence dans les transactions.
En parlant de transactions, sa langue de requête, Cypher, offre une syntaxe très intuitive et déclarative conçue pour les schémas de graphe. Pour cette raison, sa syntaxe a été surnommée l’« art ASCII ». Cypher sera facile à apprendre, en particulier si vous connaissez SQL.
Avec Cypher, il est facile d’ajouter de nouveaux nœuds, relations ou propriétés sans craindre de briser les requêtes ou le schéma existants. Il est adaptable aux besoins changeants rapides des environnements de développement modernes.
Neo4j bénéficie d’un soutien écosystémique dynamique. Il dispose de documentation extensive, d’outils complets pour visualiser les graphes, d’une communauté active et d’intégrations avec d’autres langages de programmation telles que Python, Java et JavaScript.
Configuration de Neo4j et d’un environnement Python
Avant de plonger dans l’utilisation de Neo4j, nous devons configurer notre environnement. Cette section vous guidera à travers la création d’une instance cloud pour héberger les bases de données Neo4j, la configuration d’un environnement Python et l’établissement d’une connexion entre les deux.
Ne pas installer Neo4j
Si vous souhaitez travailler avec des bases de données graphiques locales dans Neo4j, alors vous devrez les télécharger et les installer localement, ainsi que leurs dépendances telles que Java. Cependant, dans la plupart des cas, vous serez en interaction avec une base de données Neo4j existante située sur un environnement cloud distant.
Pour cette raison, nous ne installerons pas Neo4j sur notre système. Au lieu de cela, nous créerons une instance de base de données gratuite sur Aura, le service cloud entièrement géré de Neo4j. Ensuite, nous utiliserons labibliothèque cliente Python de Neo4j pour se connecter à cette base de données et la remplir des données.
Création d’une instance de base de données Neo4j Aura
Pour héberger une base de données graphique gratuite sur Aura DB, veuillez visiter sa page de produit et cliquer sur “Commencer gratuitement.”
Une fois que vous êtes enregistré, vous serez présenté les plans disponibles, et vous devriez choisir l’option gratuite. Vous serez ensuite fourni une nouvelle instance avec un nom d’utilisateur et un mot de passe pour vous connecter :
Copiez votre mot de passe, nom d’utilisateur et l’URI de connexion.
Ensuite, créez un nouveau répertoire de travail et un .env fichier pour stocker vos identifiants :
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
Collez le contenu suivant à l’intérieur du fichier :
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
Configuration de l’environnement Python
Maintenant, nous installerons la bibliothèque de client Python neo4j dans un nouvel environnement Conda :
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # Pour ajouter l'environnement à Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
Les commandes installent également ipykernel la bibliothèque et l’utilisent pour ajouter le nouvel environnement Conda créé à Jupyter en tant que noyau. Ensuite, nous installons le neo4j client Python pour interagir avec les bases de données Neo4j et python-dotenv pour gérer nos informations d’identification Neo4j de manière sécurisée.
Ajout de données de football à une instance AuraDB
La ingestion de données dans une base de données graphique est un processus complexe qui nécessite des connaissances de base en Cypher. Comme nous n’avons pas encore appris les bases de Cypher, vous utiliserez un script Python que j’ai préparé pour l’article qui ingérera automatiquement des données historiques de football réelles. Le script utilisera les identifiants que vous avez stockés pour se connecter à votre instance AuraDB.
Les données de football proviennent de ce jeu de données Kaggle sur les matchs internationaux de football disputés entre 1872 et 2024. Les données sont disponibles dans un format CSV, donc le script les décompose et les convertit en format graphique en utilisant Cypher et Neo4j. Plus tard dans l’article, lorsque nous serons suffisamment confortables avec ces technologies, nous passerons en revue le script ligne par ligne afin que vous puissiez comprendre comment convertir des informations tabulaires en un graphe.
Voici les commandes à exécuter (assurez-vous d’avoir configuré l’instance AuraDB et stocké vos informations d’identification dans un fichier .env dans votre répertoire de travail) :
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
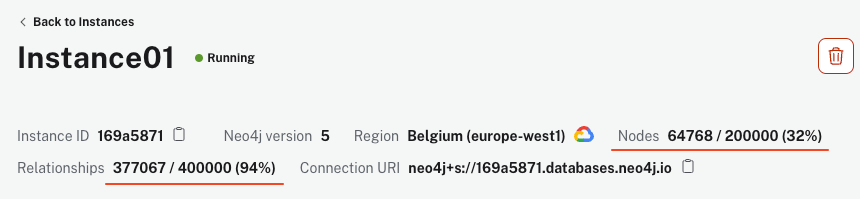
Le script peut prendre quelques minutes à s’exécuter, en fonction de votre machine et de votre connexion Internet. Cependant, une fois terminé, votre instance AuraDB doit afficher plus de 64 ko d’objets noeuds et 340 ko de relations.
Se connecter à Neo4j depuis Python
Maintenant, nous sommes prêts à nous connecter à notre instance Aura DB. Premièrement, nous lirons nos informations d’identification depuis le fichier .env à l’aide de dotenv :
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
Maintenant, essayons de établir une connexion :
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
Sortie :
Connection successful!
Voici une explication du code :
- Nous importons
GraphDatabasedeneo4jpour interagir avec Neo4j. - Nous utilisons les variables d’environnement précédemment chargées pour configurer notre connexion (
uri,username,password). - Nous créons un objet conducteur en utilisant
GraphDatabase.driver(), en établissant une connexion à notre base de données Neo4j. - Sous un
withbloc, nous utilisons laverify_connectivity()fonction pour vérifier si une connexion est établie. Par défaut,verify_connectivity()ne retourne rien si la connexion est réussie.
Une fois que l’exemple est terminé, appelez driver.close()pour arrêter la connexion et libérer les ressources. Les objets Driver sont coûteux à créer, vous devez donc créer un seul objet pour votre application.
Critères essentiels de requête Cypher
La syntaxe de Cypher est conçue pour être intuitive et représenter visuellement les structures de graphe. Elle repose sur le type de syntaxe en ASCII-art suivant :
(nodes)-[:CONNECT_TO]->(other_nodes)
Division de l’exemple général de requête :
1. Nœuds
Dans une requête Cypher, un mot-clé entre parenthèses signifie le nom d’un nœud. Par exemple, (Joueur) correspond à tous les nœuds Joueur. Presque toujours, les noms de nœuds sont références avec des alias pour rendre les requêtes plus lisibles, plus faciles à écrire et plus compactes. Vous pouvez ajouter un alias à un nom de nœud en mettant un point-virgule avant : (m:Match).
Dans les parenthèses, vous pouvez spécifier une ou plusieurs propriétés de nœuds pour un match précis en utilisant une syntaxe similaire à un dictionnaire. Par exemple :
// Tous les nœuds tournoi qui sont la Coupe du Monde FIFA (t:Tournament {name: "FIFA World Cup"})
Les propriétés des nœuds sont écrites telles quelles, tandis que la valeur que vous souhaitez leur attribuer doit être une chaîne de caractères.
2. Les relations
Les relations connectent les nœuds entre eux, et elles sont entourées de crochets et d’flèches :
// Associe les nœuds qui font partie de quelque tournoi (m:Match)-[PART_OF]->(t:Tournament)
Vous pouvez également ajouter des alias et des propriétés aux relations :
// Associe les équipes du Brésil ayant participé à un tirage au sort et ayant été le premier tireur (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
Les relations sont encadrées par des flèches -[RELATIONSHIP]->. Encore une fois, vous pouvez inclure des propriétés aliasées dans des crochets. Par exemple :
// Tous les joueurs qui ont marqué un but contre leur propre équipe (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. Clauses
Comme COUNT(*) FROM table_name ne retournerait rien sans une SELECT clause dans SQL, (node) - [RELATIONSHIP] -> (node) ne récupérerait pas de résultats. Ainsi, comme en SQL, Cypher possède différentes clauses pour structurer la logique de votre requête comme en SQL :
MATCH: Correspondance de modèle dans le grapheWHERE: Filtrer les résultatsRETURN: Définir ce qui doit être inclus dans le ensemble de résultatsCREATE: Créer de nouveaux nœuds ou relationsMERGE: Créer des nœuds ou des relations uniquesDELETE: Enlever des nœuds, des relations ou des propriétésSET: Mettre à jour des étiquettes et des propriétés
Voici une requête exemple montrant ces concepts :
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
Cette requête recense tous les joueurs ayant marqué des buts contre leur propre équipe dans des matchs de Coupe du Monde après la 80e minute. Elle ressemble presque à du SQL, mais son équivalent SQL implique au moins un JOIN.
Utilisation du pilote Python Neo4j pour analyser une base de données graphe
Exécution de requêtes avec execute_query
Le pilote Python Neo4j est la bibliothèque officielle qui interagit avec une instance Neo4j à travers des applications Python. Il vérifie et communique les requêtes Cypher écrites en chaînes de Python simples avec un serveur Neo4j et retourne les résultats dans un format unifié.
Cela commence par la création d’un objet pilote avec la classe GraphDatabase. De là, nous pouvons commencer à envoyer des requêtes en utilisant la méthode execute_query.
Pour notre première requête, demandons une question intéressante : Quelle équipe a remporté le plus de matches de Coupe du Monde ?
# Renvoie l'équipe qui a remporté le plus de matches de Coupe du Monde query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
Commençons par décomposer la requête :
- Le
MATCHfermé définit le modèle que nous désirons : Equipe -> Victoires -> Match -> Partie de -> Tournoi RETOURest l’équivalent de l’instruction SQLSELECToù nous pouvons retourner les propriétés des noeuds et des relations retournés. Dans cette clause, vous pouvez également utiliser toute fonction d’agrégation prise en charge dans Cypher. Ci-dessus, nous utilisonsCOUNT.ORDER BYclause fonctionne de la même manière que dans SQL.LIMITest utilisé pour contrôler la longueur des enregistrements retournés.
Après avoir défini la requête comme une chaîne de plusieurs lignes, nous l’affectons à la méthode execute_query() de l’objet pilote et spécifions le nom de la base de données (par défaut est neo4j). La sortie contient toujours trois objets :
records: Une liste d’objets Record, chacun représentant une ligne du jeu de résultats. Chaque enregistrement est un objet semblable à une paire nommée où vous pouvez accéder aux champs par nom ou par index.résumé: Un objet ResultSummary contenant des métadonnées sur l’exécution de la requête, telles que les statistiques de requête et les informations de temps d’exécution.clés: Une liste de chaînes de caractères représentant les noms de colonnes dans le jeu de résultats.
Nous aborderons plus tard l’objet summary car nous sommes principalement intéressés à les enregistrements, qui contiennent des objets Record . Nous pouvons récupérer leurs informations en appelant leur méthode data() :
for record in records: print(record.data())
Sortie :
{'Team': 'Brazil', 'MatchesWon': 76}
Le résultat montre correctement que le Brésil a remporté le plus grand nombre de matchs de Coupe du Monde.
Transmission de paramètres de requête
Notre dernière requête n’est pas réutilisable, car elle ne permet que de trouver l’équipe la plus victorieuse de l’histoire de la Coupe du Monde. Que faire si nous voulons trouver l’équipe la plus victorieuse de l’histoire de l’Euro ?
C’est ici qu’entrent en jeu les paramètres de requête :
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
Dans cette version de la requête, nous introduisons deux paramètres en utilisant le symbole $ :
tournamentlimit
Pour passer des valeurs aux paramètres de requête, nous utilisons des arguments nommés à l’intérieur de execute_query :
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
Sortie :
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
Il est toujours recommandé d’utiliser des paramètres de requête chaque fois que vous envisagez d’intégrer des valeurs changeantes dans votre requête. Cette meilleure pratique protège vos requêtes contre les injections Cypher et permet à Neo4j de les mettre en cache.
Écrire dans les bases de données à l’aide des clauses CREATE et MERGE.
Écrire de nouvelles informations dans une base de données existante est effectué de même avec execute_query en utilisant une clause CREATE dans la requête. Par exemple, let’s créer une fonction qui ajoutera un nouveau type de noeud – les entraîneurs d’équipes :
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
La fonction add_new_coach prend cinq paramètres :
- driver: Objet pilote Neo4j utilisé pour se connecter à la base de données.
coach_name: Le nom du nouvel entraîneur à ajouter.team_name: Le nom de l’équipe avec laquelle l’entraîneur sera associé.start_date: La date à laquelle l’entraîneur commence à entraîner l’équipe.end_date: La date à laquelle la période d’engagement de l’entraîneur avec l’équipe se termine.
La requête Cypher dans la fonction effectue les opérations suivantes :
- Correspond à un noeud Equipe existant avec le nom d’équipe donné.
- Créé un nouveau noeud Entraîneur avec le nom d’entraîneur fourni.
- Créé une relation COACHES entre les nœuds Coach et Team.
- Définit les
start_dateetend_datepropriétés sur la relationCOACHES.
L’exécution de la requête s’effectue en utilisant la méthode execute_query qui prend en argument la chaîne de requête et un dictionnaire de paramètres.
Après l’exécution, la fonction affiche :
- Un message de confirmation comportant les noms de l’entraîneur et de l’équipe et la date de début.
- Le nombre de nœuds créés (devrait être 1 pour le nouveau nœud Entraîneur).
- Le nombre de relations créées (devrait être 1 pour la nouvelle relation
COACHES).
Faisons-le pour l’un des entraîneurs les plus couronnés de succès de l’histoire du football international, Lionel Scaloni, qui a remporté trois compétitions internationales majeures consécutives (Coupe du Monde et deux Copa Amériques) :
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
Dans l’extrait ci-dessus, nous utilisons la classe DateTime du module neo4j.time pour passer une date correctement dans notre requête Cypher. Le module contient d’autres types de données temporelles utiles que vous pourriez vouloir vérifier.
En dehors deCREATE, il existe également la clauseMERGE pour créer de nouveaux nœuds et relations. La principale différence entre elles est :
CREATEcréé toujours de nouveaux nœuds/relations, ce qui peut entraîner des doublons.MERGEne crée des nœuds/relations que s’ils n’existent pas déjà.
Par exemple, dans notre script d’ingestion de données, comme vous le verrez plus tard :
- Nous avons utilisé
MERGEpour les équipes et les joueurs afin d’éviter les doublons. - Nous avons utilisé
CREATEpourSCORED_FORetSCORED_INparce qu’un joueur peut marquer plusieurs fois dans un seul match. - Ces éléments ne sont pas des véritables doublons car ils ont des propriétés différentes (par exemple, le minute du but).
Cette approche garantit l’intégrité des données tout en permettant plusieurs relations similaires mais distinctes.
Exécuter vos propres transactions
Lorsque vous exécutez execute_query, le pilote crée une transaction à l’arrière-plan. Une transaction est une unité de travail qui est soit complètement exécutée, soit annulée en cas d’échec. Cela signifie que lorsque vous créez des milliers de nœuds ou de relations dans une seule transaction (ce qui est possible) et que vous rencontrez une erreur au milieu, la transaction entière échoue sans écrire de nouvelle donnée dans le graphique.
Pour avoir un contrôle plus fin sur chaque transaction, vous devez créer des objets de session. Par exemple, créons une fonction pour trouver les K meilleurs buteurs dans un tournoi donné en utilisant un objet de session :
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
Tout d’abord, nous créons top_goal_scorers qui accepte trois paramètres, le plus important étant l’objet de transaction tx qui sera obtenu en utilisant un objet de session.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
Sortie :
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
Ensuite, dans un gestionnaire de contexte créé avec la session() méthode, nous utilisons execute_read(), en passant la top_goal_scorers() fonction, ainsi que tous les paramètres requis par la requête.
La sortie de execute_read est une liste d’objets Record qui montrent correctement les 5 meilleurs buteurs de l’histoire de la Coupe du Monde, y compris des noms comme Miroslav Klose, Ronaldo Nazário et Lionel Messi.
L’homologue de execute_read() pour l’ingestion de données est execute_write().
Ceci dit, voyons maintenant le script d’ingestion que nous avons utilisé plus tôt pour comprendre comment fonctionne l’ingestion de données avec le pilote Python Neo4j.
Ingestion de données en utilisant le pilote Python Neo4j
Le ingest_football_data.py fichier commence avec des déclarations d’importation et le chargement des fichiers CSV nécessaires :
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging # Chemins des fichiers CSV results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" # Configurer le journal logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") # Charger les données results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
Ce bloc de code configure également un journal. Les prochaines lignes de code lisent mes informations d’identification Neo4j en utilisant dotenv et créent un objet Driver :
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
Puisque notre base de données contient plus de 48k correspondances, nous définissons un paramètre BATCH_SIZE pour ingérer les données en petits échantillons.
Ensuite, nous définissons une fonction appelée create_indexes qui accepte un objet de session :
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Les indexs Cypher sont des structures de base de données qui améliorent les performances des requêtes dans Neo4j. Ils accélèrent le processus de recherche de nœuds ou de relations sur la base de propriétés spécifiques. Nous avons besoin d’eux pour :
- Une exécution de requête plus rapide
- Des performances de lecture améliorées sur de grands jeux de données
- Un alignement de modèles efficient
- Enforcement des contraintes uniques
- Meilleure scalabilité au fur et à mesure que la base de données grandit
Dans notre cas, les index sur les noms d’équipes, les ID de matchs et les noms de joueurs aideront nos requêtes à s’exécuter plus rapidement lorsque nous recherchons des entités spécifiques ou lorsque nous effectuons des jointures entre différents types de nœuds. Il est une pratique courante de créer de tels index pour vos propres bases de données.
Ensuite, nous avons la fonction ingest_matches Elle est importante, donc passons-y à bloc par bloc :
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
La première chose que vous remarquerez est leUNWINDmot-clé, qui est utilisé pour traiter un lot de données. Il prend le$batchparamètre (qui sera nos lignes de DataFrame) et itère sur chaque ligne, ce qui nous permet de créer ou de mettre à jour plusieurs nœuds et relations dans une seule transaction. Cette approche est plus efficiente que de traiter chaque ligne individuellement, en particulier pour de grandes ensembles de données.
La suite de la requête est familière, car elle utilise plusieurs MERGE clause. Ensuite, nous atteignons la WITH clause, qui utilise des FOREACH constructs avec des IN CASE statements. Ces derniers sont utilisés pour créer conditionnellement des relations en fonction du résultat du match. Si l’équipe de domicile gagne, il crée une relation ‘WON’ pour l’équipe de domicile et une relation ‘LOST’ pour l’équipe visiteuse, et l’inverse est vrai. En cas de match nul, les deux équipes obtiennent une relation ‘DREW’ avec le match.
La suite de la fonction divise le DataFrame reçu en matches et construit les données qui seront passées à la $batch requête paramètre :
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals et les fonctions ingest_shootouts utilisent des structures similaires. Cependant, les fonctions ingest_goals incluent une gestion supplémentaire des erreurs et des valeurs manquantes.
A la fin du script, nous avons la main() fonction qui exécute toutes nos fonctions d’ingestion avec un objet de session :
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
Conclusion et Prochaines étapes
Nous avons couvert les aspects clés du travail avec les bases de données graphes Neo4j en utilisant Python :
- Concepts et structure des bases de données graphes
- Installation de Neo4j AuraDB
- Fondamentaux de la langue de requête Cypher
- Utilisation du pilote Python pour Neo4j
- Ingestion de données et optimisation des requêtes
Pour pousser plus loin votre aventure Neo4j, explorez ces ressources :
- Documentation Neo4j
- Bibliothèque de sciences des données graphiques Neo4j
- Manuel de Cypher pour Neo4j
- « Documentation du pilote Python pour Neo4j »
- Certification professionnelle en ingénierie des données
- Introduction à NoSQL
- Tutoriel complet sur les bases de données NoSQL à l’aide de MongoDB
Souviens-toi, la force des bases de données graphes réside dans la représentation et la recherche de relations complexes. Continue à expérimenter différents modèles de données et à explorer les fonctionnalités avancées de Cypher.