













Las grandes organizaciones donde el número de usuarios que acceden a datos cruciales es bastante alto deben enfrentarse a muchos desafíos en la gestión de acceso granular.
Una variedad de servicios de AWS como IAM, Lake Formation y S3 ACL pueden ayudar en el control de acceso granular. Pero hay escenarios donde una única entidad que contiene los datos globales necesita ser accesible por múltiples grupos de usuarios en todo el sistema con acceso restrictivo. Además, las organizaciones con presencia global pueden estar trabajando en diferentes entornos y con diferentes conjuntos de herramientas, por lo que el movimiento de datos y la catalogación se vuelven muy tediosos.
Por ejemplo, un usuario quiere acceder a los datos de ventas de una tabla con fines de análisis, pero debe estar restringido a acceder solo a los datos de ventas relacionados con la región de Australia. No se deben mostrar otros datos. Además, quiere acceder a los datos desde una plataforma de nube diferente para múltiples operaciones DML, por lo que necesita traer los datos y transformarlos al formato nativo de la herramienta para su procesamiento, lo que causa retrasos.
Para este tipo de escenario, requerimos control de datos a nivel de atributo y datos a través de entornos para soportar los formatos de herramientas nativas y permitir un acceso más rápido.
Tomamos un paso adelante para abordar estos desafíos y ofrecer una solución de transformación en la nube aprovechando Lake Formation para la gobernanza de datos en la tabla Apache Iceberg, la cual puede ser consultada y catalogada en AWS S3 misma y puede ser accedida en diferentes plataformas y nubes.
Utilizando la opción de filtro de datos en Lake Formation, podemos garantizar seguridad a nivel de columna, a nivel de fila y a nivel de celda.
¿Qué es el formato de tabla Iceberg?
Iceberg es un formato de tabla de código abierto con los siguientes beneficios:
- Iceberg soporta completamente comandos SQL flexibles, lo que hace posible actualizar, fusionar y eliminar los datos. Iceberg puede ser utilizado para reescribir archivos de datos para mejorar el rendimiento de lectura y utilizar deltas de eliminación para acelerar la velocidad de las actualizaciones.
- Iceberg soporta una evolución completa de esquema. Las actualizaciones de esquema en las tablas Iceberg cambian solo los metadatos, sin afectar a los archivos de datos en sí. Los cambios de evolución de esquema incluyen adiciones, eliminaciones, renombramientos, reordenamientos y promociones de tipo.
- Los datos almacenados en un lago de datos o en una arquitectura de malla de datos están disponibles para múltiples aplicaciones independientes en una organización simultáneamente.
- Iceberg está diseñado para su uso con grandes conjuntos de datos analíticos. Ofrece múltiples características diseñadas para aumentar la velocidad y eficiencia de las consultas, incluyendo planificación de escaneo rápido, poda de archivos de metadatos que no son necesarios y la capacidad de filtrar archivos de datos que no contienen datos coincidentes.
Descripción de la Solución
La solución que hemos propuesto es utilizar el servicio Lake Formation para crear filtros de datos sobre los cuales podemos otorgar permisos al usuario para el acceso. El corazón de la solución es utilizar el formato de tabla Iceberg, que está catalogado y luego se le añaden condiciones de filtro para gobernar el acceso.

Flujo de Datos
- DMS o Glue se utilizan para obtener datos de los repositorios del sistema fuente y almacenarlos en un bucket S3 designado.
- La arquitectura basada en eventos desencadena un evento cuando S3 empuja para llamar a la función Lambda respectiva para iniciar el proceso ETL.
- Los datos se almacenarán en formato de tabla Iceberg y se catalogarán.
- Los datos pueden ser procesados y transformados utilizando Glue, aprovechando los modelos listos de GenAI.
- Los datos procesados se almacenarán en Redshift para su consumo.
- Las tablas Iceberg catalogadas se añadirán con la columna de etiqueta (el valor de la etiqueta se asigna al grupo de usuarios).
La imagen a continuación describe un filtro de datos de ejemplo y cómo se ve. También podemos limitar el número de columnas utilizando los filtros de datos.
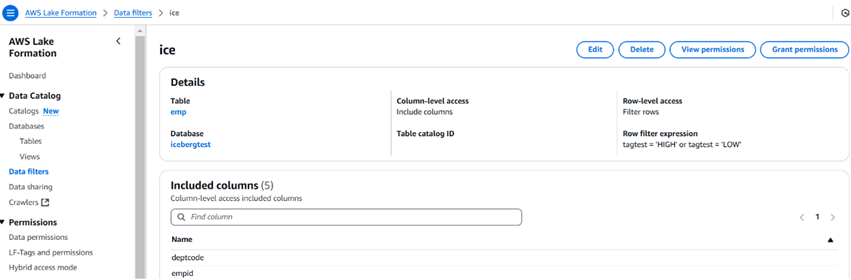
Una vez que se crea el filtro, podemos usar la opción de otorgar permisos para dar permiso a usuarios, roles, grupos y cuentas. El usuario puede utilizar Athena para consultar los datos.
Las diversas capacidades de nuestra solución son:
- Capacidad para gestionar de manera efectiva el control detallado del acceso a los datos.
- Reutilización de los filtros de datos para múltiples grupos de usuarios.
- Podemos lograr seguridad a nivel de columna, seguridad a nivel de fila y seguridad a nivel de celda.
- Uso efectivo de las características del formato de tabla Apache Iceberg para un control continuo sobre los datos y su acceso.
- Efficiencia y efectividad en la preparación de datos.
- Gestión centralizada de acceso y gobernanza mediante lake formation.
- Menor intervención manual en la solución completamente integrada.
- Entrega de datos de extremo a extremo utilizando una solución agnóstica de la nube y componentes sin servidor para proporcionar escalabilidad y rentabilidad.
Beneficios
- Eficiencia operativa. El uso de componentes sin servidor reduce los costos operativos y de mantenimiento involucrados en su gestión.
- Optimización del esfuerzo. Reducción de hasta un 20-30% en el esfuerzo al utilizar modelos GenAI para generar scripts de ETL estandarizados y eficientes.
- Beneficios de gobernanza y cumplimiento. El control basado en atributos en lake formation ayuda a cumplir con las regulaciones estándar y proporcionar capacidades de auditoría y registro.
Uso industrial
El gobierno a nivel de atributos utilizando la tabla Apache Iceberg se puede implementar de manera muy fluida en el sector financiero, como un banco o una compañía de seguros, donde los clientes necesitan tener acceso restringido a los datos, garantizando la autenticidad y seguridad de los mismos. El sector de la salud puede utilizarlo para generar y compartir el expediente médico electrónico del paciente de manera rápida, asegurando la sensibilidad de los datos, lo que puede llevar a un tratamiento y medicación oportunos.
Conclusión
Por lo tanto, la solución general entregará un gobierno a nivel de atributos a escala con preparación de datos de manera rápida utilizando el formato de tabla Apache Iceberg necesario para la mayoría de las organizaciones e implementando la solución aprovechando los servicios de la nube de Amazon, que ofrece el beneficio de victorias rápidas, costos óptimos y escalabilidad ilimitada.
Source:
https://dzone.com/articles/attribute-level-governance-apache-iceberg-tables