













En este breve artículo, exploraremos las aprobaciones de préstamos utilizando una variedad de herramientas y técnicas. Comenzaremos analizando los datos del préstamo y aplicando Regresión Logística para predecir los resultados del préstamo. Basándonos en esto, integraremos BERT para Procesamiento de Lenguaje Natural para mejorar la precisión de predicción. Para interpretar las predicciones, usaremos los marcos de explicación SHAP y LIME, proporcionando insights sobre la importancia de las características y el comportamiento del modelo. Finalmente, exploraremos el potencial de Procesamiento de Lenguaje Natural a través de LangChain para automatizar las predicciones de préstamos, usando el poder de la inteligencia artificial conversacional.
El archivo de cuaderno utilizado en este artículo está disponible en GitHub.
Introducción
En este artículo, exploraremos varias técnicas para las aprobaciones de préstamos, utilizando modelos como Regresión Logística y BERT, y aplicando SHAP y LIME para la interpretación del modelo. También investigaremos el potencial de usar LangChain para automatizar las predicciones de préstamos con inteligencia artificial conversacional.
Crear una Cuenta de SingleStore Cloud
Un artículo anterior mostró los pasos para crear una cuenta de SingleStore Cloud gratuita. Utilizaremos la Capa Compartida Gratuita y tomaremos los nombres predeterminados para el Workspace y la Base de Datos.
Importar el Cuaderno
Descargaremos el cuaderno de GitHub (enlace provisto anteriormente).
Desde el panel de navegación izquierdo del portal SingleStore Cloud, seleccionaremos DEVELOP > Data Studio.
En la esquina superior derecha de la página web, seleccionaremos New Notebook > Import From File. Utilizaremos el asistente para localizar y importar la hoja de cálculo que descargamos de GitHub.
Ejecutar la Hoja de Cálculo
Después de verificar que estamos conectados a nuestro espacio de trabajo SingleStore, ejecutaremos las celdas una por una.
Empezaremos instalando las bibliotecas necesarias e importando las dependencias, seguido de cargar los datos del préstamo de un archivo CSV que contiene cerca de 600 filas. Dado que algunas filas tienen datos faltantes, descartaremos las incompletas para el análisis inicial, reduciendo el conjunto de datos a unas 500 filas.
A continuación, prepararemos los datos adicionales y separaremos las características y las variables objetivo.
Las visualizaciones pueden proporcionar un gran insight en los datos y empezaremos creando un mapa de calor que muestra la correlación entre las características numéricas, como se muestra en la Figura 1.
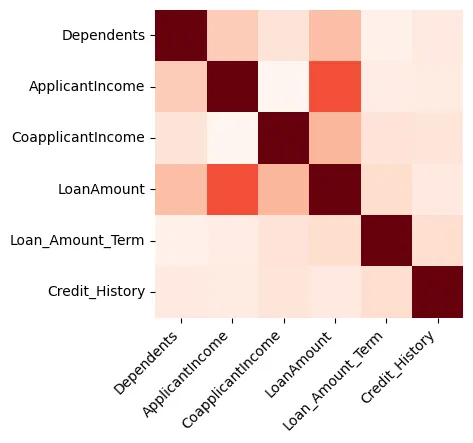
Figura 1: Mapa de Calor
Podemos ver que el Monto del Préstamo y el Ingreso del Solicitante están fuertemente relacionados.
Si creamos un gráfico de Monto del Préstamo contra Ingreso del Solicitante, podemos ver que la mayoría de los puntos de datos están en la parte inferior izquierda del diagrama de dispersión, como se muestra en la Figura 2.
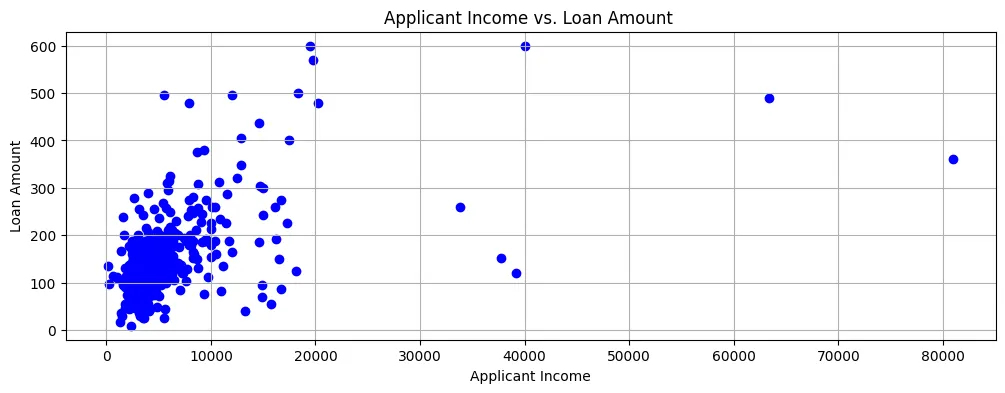
Figura 2: Diagrama de Dispersión
Así, los ingresos son generalmente bastante bajos y las solicitudes de préstamos también son para cantidades relativamente pequeñas.
También podemos crear un diagrama de dispersión para la Cantidad del Préstamo, el Ingreso del Solicitante, y el Ingreso del Acudiente, como se muestra en la Figura 3.
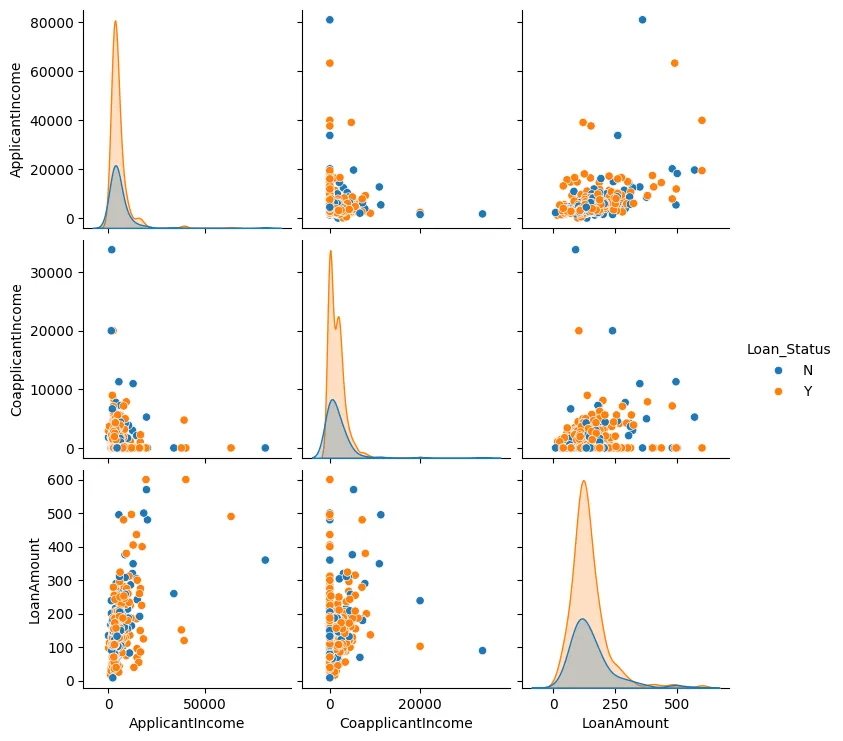
Figura 3: Diagrama de dispersión
En la mayoría de los casos, podemos ver que los puntos de datos tienden a agruparse juntos y generalmente hay pocos outliers.
Ahora realizaremos algunos procesos de ingeniería de características. Identificaremos los valores categóricos y convertiremos estos en valores numéricos, así también usaremos la codificación one-hot donde sea necesario.
A continuación, crearemos un modelo utilizando Regresión Logística ya que solo hay dos resultados posibles: o la solicitud de préstamo es aprobada o es rechazada.
Si visualizamos la importancia de las características, podemos hacer algunas observaciones interesantes, como se muestra en la Figura 4.
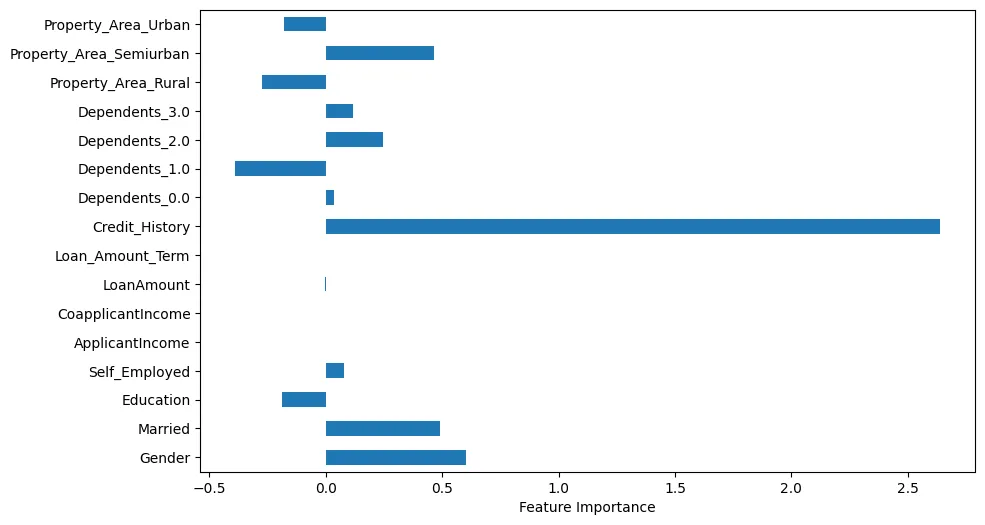
Figura 4: Importancia de las características
Por ejemplo, podemos ver que Historial Crediticio es obviamente muy importante. Sin embargo, Estado Civil y Género también son importantes.
Ahora realizaremos predicciones utilizando un solo muestra de prueba.
Generaremos un resumen de la solicitud de préstamo utilizando Bidirectional Encoder Representations from Transformers (BERT) con la muestra de prueba. Ejemplo de salida:
BERT-Generated Loan Application Summary
applicant : mr blobby income : $ 7787. 0 credit history : 1. 0 loan amount : $ 240. 0 property area : urban area
Model Prediction ('Y' = Approved, 'N' = Denied): Y
Loan Approval Decision: Approved
Usando el resumen generado por BERT, crearemos un word cloud como se muestra en la Figura 5.

Podemos ver que el nombre del solicitante, el ingreso y el historial crediticio son más grandes y destacados.
Otra forma en la que podemos analizar los datos de nuestra muestra de prueba es utilizando SHapley Additive exPlanations (SHAP). En la Figura 6 podemos visualmente ver las características que son importantes.

Figura 6: SHAP
Un diagrama de fuerza SHAP es otra forma en la que podríamos analizar los datos, como se muestra en la Figura 7.
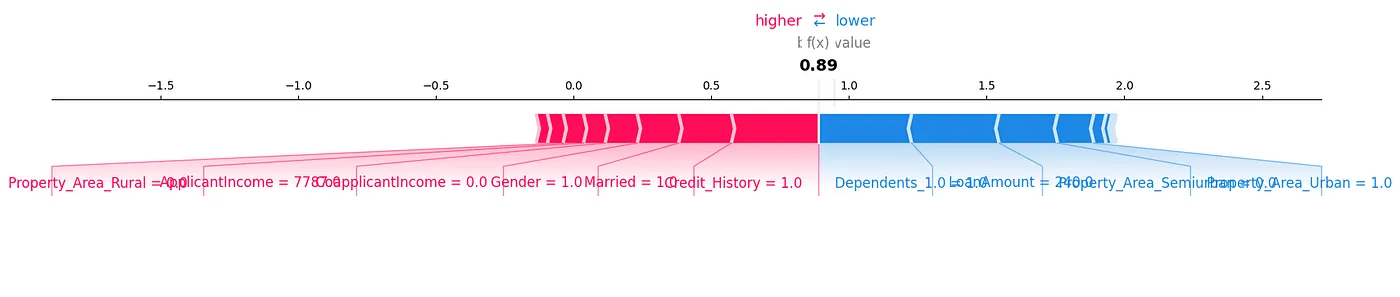
Figura 7: Diagrama de fuerza
Podemos ver cómo cada característica contribuye a una predicción particular para nuestra muestra de prueba mostrando los valores SHAP de manera visual.
Otra biblioteca muy útil es Local Interpretable Model-Agnostic Explanations (LIME). Los resultados para esto pueden generarse en el cuaderno adjunto a este artículo.
A continuación, crearemos una Matriz de Confusión (Figura 8) para nuestro modelo de Regresión Logística y generaremos un informe de clasificación.
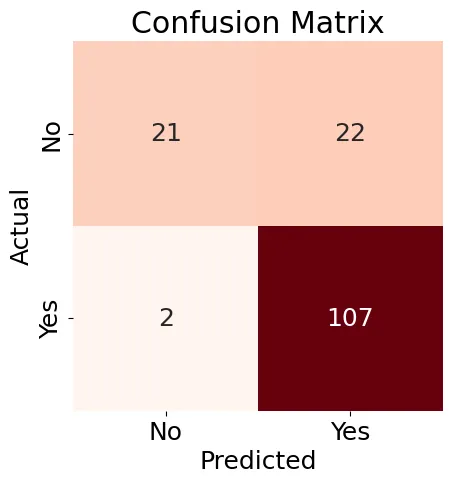
Figura 8: Matriz de Confusión
Los resultados mostrados en la Figura 8 son un poco mixtos, pero el informe de clasificación contiene algunos buenos resultados:
Accuracy: 0.84
Precision: 0.83
Recall: 0.98
F1-score: 0.90
Classification Report:
precision recall f1-score support
N 0.91 0.49 0.64 43
Y 0.83 0.98 0.90 109
accuracy 0.84 152
macro avg 0.87 0.74 0.77 152
weighted avg 0.85 0.84 0.82 152
En general, podemos ver que el uso de herramientas y técnicas de Aprendizaje Automático existentes nos ofrece muchas maneras posibles de analizar los datos y encontrar relaciones interesantes, particularmente a nivel de una muestra de prueba individual.
A continuación, vamos a utilizar LangChain y una LLM y ver si también podemos hacer predicciones de préstamos.
Una vez que haya configurado y configurado LangChain, probaremos dos ejemplos, pero restringirá el acceso a la cantidad de datos para que no supere los límites de tokens y tasas. Aquí está el primer ejemplo:
query1 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Male
ApplicantIncome: 7787.0
Credit_History: 1
LoanAmount: 240.0
Property_Area_Urban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result1 = run_agent_query(query1, agent_executor, error_string)
print(result1)
En este caso, la solicitud fue aprobada en el conjunto de datos original.
Aquí está el segundo ejemplo:
query2 = (
"""
Build a loan approval model.
Limit your access to 10 rows of the table.
Use your model to determine if the following loan would be approved:
Gender: Female
ApplicantIncome: 5000.0
Credit_History: 0
LoanAmount: 103.0
Property_Area_Semiurban: 1
Limit your reply to either 'Approved' or 'Denied'.
"""
)
result2 = run_agent_query(query2, agent_executor, error_string)
print(result2)
En este caso, la solicitud fue rechazada en el conjunto de datos original.
Ejecutando estas consultas, podríamos obtener resultados inconsistentes. Esto podría deberse a la restricción de la cantidad de datos que se puede utilizar. También podemos usar el modo detallado en LangChain para ver las etapas que se están utilizando para construir un modelo de aprobación de préstamos, pero en este nivel inicial no hay información suficiente sobre los pasos detallados para crear ese modelo.
Se necesita más trabajo con la IA conversacional, ya que muchos países tienen reglas de préstamos justos y necesitaríamos una explicación detallada sobre por qué la IA aprobó o rechazó una solicitud de préstamo particular.
Resumen
Hoy en día, muchas herramientas y técnicas poderosas refuerzan la Aprendizaje Automático (AA) para obtener insights más profundos en los datos y los modelos de predicción de préstamos. La IA, a través de Modelos de Lenguaje Largos (LLMs) y frameworks modernos, ofrece gran potencial para ampliar o incluso reemplazar los enfoques tradicionales de AA. Sin embargo, para tener mayor confianza en las recomendaciones de la IA y cumplir con los requisitos legales y de préstamos justos en muchos países, es crucial entender el proceso de razonamiento y toma de decisiones de la IA.
Source:
https://dzone.com/articles/building-predictive-analytics-for-loan-approvals