













Los científicos de datos comienzan aprendiendo acerca de SQL pronto. Es comprensible, dada la ubicidad y la alta utilidad de la información tabular. Sin embargo, existen otras formatos de base de datos exitosos, como las bases de datos de grafos, para almacenar datos conectados que no encajan en una base de datos relacional SQL. En este tutorial, aprenderemos sobre Neo4j, un popular sistema de gestión de bases de datos de grafos que puedes usar para crear, gestionar y consultar bases de datos de grafos en Python.
¿Qué son las bases de datos de grafos?
Antes de hablar de Neo4j, dediquemos un momento para entender mejor las bases de datos de grafos. Tenemos un artículo completo explicando cuáles son las bases de datos de grafos, así que resumiremos los puntos clave aquí.
Las bases de datos grafos son un tipo de base de datos NoSQL (no utilizan SQL) diseñadas para gestionar datos conectados. A diferencia de las bases de datos relacionales tradicionales que utilizan tablas y filas, las bases de datos grafos utilizan estructuras de grafo que están compuestas por:
- Nodos (entidades) como personas, lugares, conceptos
- Bordes (relaciones) que conectan diferentes nodos como persona VIVE EN un lugar, o un futbolista HA ANOTADO EN un partido.
- Propiedades (atributos para nodos/aristas) como la edad de una persona, o cuándo se marcó el gol en el partido.
Esta estructura hace que las bases de datos de grafos sean ideales para manejar datos interconectados en campos y aplicaciones como redes sociales, recomendaciones, detección de fraudes, etc., a menudo superando a las bases de datos relacionales en términos de eficiencia de consulta. Aquí se muestra la estructura de una base de datos de gráfico de muestra para un conjunto de datos de fútbol:
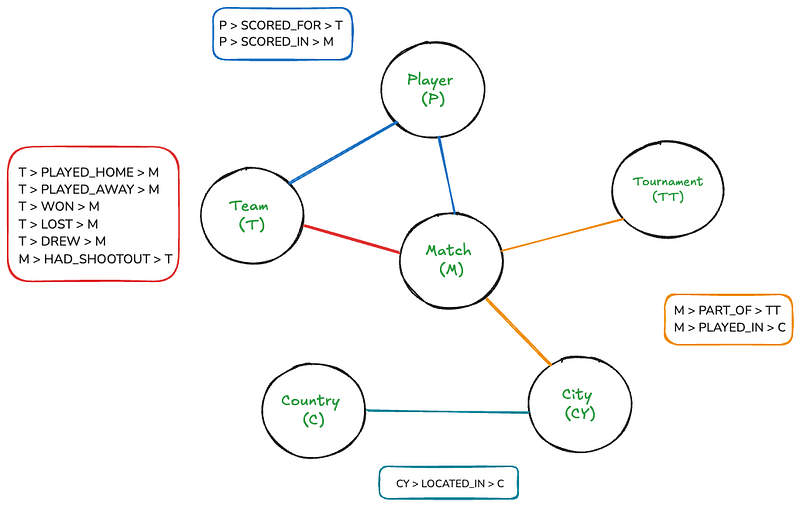
Aunque este gráfico represente algo bastante intuitivo para los seres humanos, puede resultar muy complicado si se dibuja en lienzo. Sin embargo, con Neo4j, recorrer este gráfico será tan directo como escribir unosjoin de SQL.
El gráfico tiene seis nodos: Match, Team, Tournament, Player, Country y City. Los rectángulos enumeran las relaciones que existen entre nodos. También hay algunas propiedades de nodo y relación:
- Partido: fecha, visita_puntos, local_puntos
- Equipo: nombre
- Jugador: nombre
- Torneo: nombre
- Ciudad: nombre
- País: nombre
- PUNTUACIÓN, PUNTUACIÓN_EN: minuto, gol_propio, penalti
- TIENE_Empate_Por_Lanzamientos_de_penalti: ganador, primer_tirador
Este esquema nos permite representar:
- Todos los partidos con sus puntuaciones, fechas y ubicaciones
- Los equipos participantes en cada partido (local y visitante)
- Los jugadores que marcan goles, incluyendo detalles como el minuto, los goles en propia meta y los penaltis
- Torneos que comprenden los partidos
- Ciudades y países donde se juegan los partidos
- Información de shootout, incluyendo ganadores y primeros tiradores (cuando estén disponibles)
El esquema captura la naturaleza jerárquica de las ubicaciones (Ciudad dentro de País) y las varias relaciones entre entidades (por ejemplo, Equipos que juegan Partidos, Jugadores que anotan para Equipos en Partidos).
Esta estructura permite consultas flexibles, como encontrar todos los partidos entre dos equipos, todos los goles anotados por un jugador o todos los partidos en un torneo o ubicación específicos.
Pero no saltemos de antemano. Por comienzos, ¿qué es Neo4j y por qué utilizarlo?
¿Qué es Neo4j?
Neo4j, la principal referencia en el mundo de la gestión de bases de datos de grafo, es conocida por sus poderosas características y versatilidad.
En su núcleo, Neo4j utiliza un almacenamiento de grafo nativo, que está altamente optimizado para realizar operaciones de grafo. Su eficiencia en la manejo de relaciones complejas lo hace superar a las bases de datos tradicionales para datos conectados. La escalabilidad de Neo4j es realmente impresionante: puede manejar fácilmente miles de millones de nodos y relaciones, lo que lo hace adecuado tanto para proyectos pequeños como para empresas grandes.
Otro aspecto clave de Neo4j es la integridad de los datos. Ensure full ACID (Atomicity, Consistency, Isolation, Durability) compliance, providing reliability and consistency in transactions.
Cuando se trata de transacciones, su lenguaje de consulta, Cypher, ofrece una sintaxis muy intuitiva y declarativa diseñada para patrones de grafo. Por eso, su sintaxis ha sido apodada como “ASCII art”. Cypher no será un problema para aprender, especialmente si estás familiarizado con SQL.
Con Cypher, es fácil agregar nuevos nodos, relaciones o propiedades sin preocuparse por romper consultas existentes o esquemas. Es adaptable a los requerimientos cambiantes rápidos de los entornos de desarrollo modernos.
Neo4j tiene un fuerte soporte de ecosistema. Cuenta con una documentación extensa, herramientas comprensivas para visualizar gráficos, una comunidad activa y integraciones con otras lenguajes de programación como Python, Java y JavaScript.
Configuración de Neo4j y un entorno de Python
Antes de que nos adentremos en el trabajo con Neo4j, necesitamos configurar nuestro entorno. Esta sección guiará a través de la creación de una instancia en la nube para alojar bases de datos de Neo4j, la configuración de un entorno de Python y la establecimiento de una conexión entre ambos.
No instalar Neo4j
Si desea trabajar con bases de datos locales de grafos en Neo4j, entonces necesitaría descargar y instalarlo localmente, junto con sus dependencias como Java. Sin embargo, en la mayoría de los casos, interactuará con una base de datos remota de Neo4j existente en algún entorno de nube.
Por esa razón, no instalaremos Neo4j en nuestro sistema. En su lugar, crearemos una instancia de base de datos gratuita en Aura, el servicio en la nube totalmente administrado de Neo4j. Después, utilizaremos la neo4j biblioteca de cliente de Python para conectarnos a esta base de datos y poblársela con datos.
Creando una instancia de base de datos Neo4j Aura
Para alojar una base de datos gráfica gratuita en Aura DB, visitar su página de producto y hacer clic en “Empezar gratis.”
Una vez registrado, se le presentarán los planes disponibles, y debe elegir la opción gratuita. A continuación, le proporcionarán una nueva instancia con un nombre de usuario y contraseña para conectarse a él:
Copie su contraseña, nombre de usuario y la URI de conexión.
Entonces, cree un nuevo directorio de trabajo y un .env archivo para almacenar sus credenciales:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
Coloque el siguiente contenido dentro del archivo:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
Configurando el Entorno de Python
Ahora, instalaremos la neo4j biblioteca de cliente de Python en un nuevo entorno Conda:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # Para agregar el entorno a Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
Los comandos también instalanipykernel la biblioteca y la usan para agregar el entorno Conda recién creado a Jupyter como un núcleo. Después, instalamos elneo4j cliente de Python para interactuar con bases de datos Neo4j ypython-dotenv para administrar nuestras credenciales Neo4j de manera segura.
Populando una instancia de AuraDB con datos de fútbol
La ingesta de datos en una base de datos de grafos es un proceso complicado que requiere conocimientos de fundamentos de Cypher. Puesto que aún no hemos aprendido sobre los conceptos básicos de Cypher, utilizarás un script de Python que he preparado para el artículo que automáticamente ingirá datos históricos reales de fútbol. El script utilizará las credenciales que has almacenado para conectarte a tu instancia de AuraDB.
Los datos de fútbol provienen de este conjunto de datos de Kaggle sobre partidos internacionales de fútbol disputados entre 1872 y 2024. Los datos están disponibles en formato CSV, por lo que el script los desglosa y los convierte en formato gráfico utilizando Cypher y Neo4j. Al final del artículo, cuando tengamos suficiente confianza en estas tecnologías, recorremos la línea a línea del script para que puedas comprender cómo convertir información tabular en un gráfico.
Aquí están los comandos para ejecutar (asegrerate de haber configurado la instancia de AuraDB y de haber almacenado tus credenciales en un .env archivo en tu directorio de trabajo):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
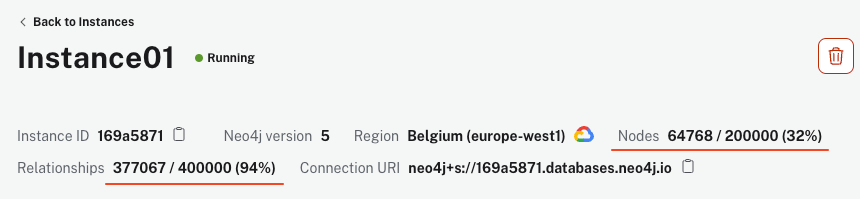
El script puede tardar unos minutos en ejecutarse, dependiendo de tu máquina y de tu conexión a Internet. Sin embargo, una vez que finaliza, tu instancia de AuraDB debe mostrar más de 64k nodos y 340k relaciones.
Conectando a Neo4j Desde Python
Ahora, estamos listos para conectarnos a nuestra instancia de Aura DB. Primero, leeramos nuestras credenciales del archivo .env usando dotenv:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
Ahora, vamos a establecer una conexión:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
Salida:
Connection successful!
Aquí tienes una explicación del código:
- Importamos
GraphDatabasedesdeneo4jpara interactuar con Neo4j. - Usamos las variables de entorno previamente cargadas para configurar nuestra conexión (
uri,username,password). - Creamos un objeto de controlador usando
GraphDatabase.driver(), estableciendo una conexión a nuestra base de datos Neo4j. - Bajo un
withbloque, utilizamos la funciónverify_connectivity()para verificar si se ha establecida una conexión. Por defecto,verify_connectivity()no devuelve nada si la conexión es exitosa.
Una vez que finaliza el tutorial, llama driver.close() para finalizar la conexión y liberar recursos. Los objetos de Driver son costosos de crear, así que solo deberías crear un solo objeto para tu aplicación.
Elementos básicos del Lenguaje de Consulta Cypher
La sintaxis de Cypher está diseñada para ser intuitiva y representativa visualmente de las estructuras de grafo. Se basa en la siguiente tipografía de arte ASCII:
(nodes)-[:CONNECT_TO]->(other_nodes)
Vamos a desglosar los componentes clave de este patrón de consulta general:
1. Nodos
En una consulta Cypher, un keyword entre paréntesis significa un nombre de nodo. Por ejemplo, (Jugador) encuentra todos los nodos de Jugador. Casi siempre, los nombres de nodos se refieren con alias para hacer las consultas más legibles, más fáciles de escribir y compactas. Puede agregar un alias a un nombre de nodo poniendo un signo de dos puntos delante de él: (m:Partido).
Dentro de los paréntesis, puede especificar una o más propiedades de nodo para un ajuste preciso usando una sintaxis similar a un diccionario. Por ejemplo:
// Todos los nodos de torneo que son la Copa del Mundo FIFA (t:Tournament {name: "FIFA World Cup"})
Las propiedades de los nodos se escriben tal cual, mientras que el valor que desea que tengan debe ser una cadena.
2. Relaciones
Las relaciones conectan nodos entre sí, y están rodeadas de corchetes y flechas:
// Coincide con los nodos que son PART_OF algún torneo (m:Match)-[PART_OF]->(t:Tournament)
También puede agregar alias y propiedades a las relaciones:
// Coincide con los partidos en los que Brasil participó en una tanda de penaltis y fue el primer tirador (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
Las relaciones se envuelven con flechas -[RELACIÓN]->. De nuevo, puede incluir propiedades alias dentro de los paréntesis. Por ejemplo:
// Todos los jugadores que marcaron un gol en propia meta (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. Clausulas
Al igual que COUNT(*) FROM table_name no devolvería nada sin una SELECT cláusula en SQL, (node) - [RELATIONSHIP] -> (node) tampoco cogería ningún resultado. Así que, al igual que en SQL, Cypher tiene diferentes cláusulas para estructurar tu lógica de consulta como en SQL:
COINCIDENCIAS: Coincidencia de patrones en el gráficoDONDE: Filtrar los resultadosRETORNAR: Especificar qué incluir en el conjunto de resultadosCREAR: Crear nuevos nodos o relacionesMERGE: Crear nodos o relaciones únicosDELETE: Eliminar nodos, relaciones o propiedadesSET: Actualizar etiquetas y propiedades
Aquí tienes una consulta de muestra que demuestra estos conceptos:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
Esta consulta encuentra a todos los jugadores que anotaron goles en propia Meta en partidos de la Copa del Mundo después del minuto 80. Tiene casi el aspecto de SQL, pero su equivalente en SQL implica al menos un JOIN.
Uso del Controlador de Neo4j en Python para Analizar una Base de Datos de Gráfico
Ejecutando consultas con execute_query
El controlador de Neo4j en Python es la biblioteca oficial que interactúa con una instancia de Neo4j a través de aplicaciones de Python. Verifica y comunica consultas de Cypher escritas en cadenas de texto planas en un servidor de Neo4j y recupera los resultados en un formato unificado.
Todo comienza creando un objeto de controlador con la clase GraphDatabase. Desde allí, podemos comenzar a enviar consultas usando el método execute_query.
Para nuestra primera consulta, preguntemos una pregunta interesante: ¿Qué equipo ha ganado más partidos de la Copa del Mundo?
# Devuelve el equipo que ha ganado el mayor número de partidos de la Copa del Mundo query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
Primero, descompongamos la consulta:
- El
MATCHcercano define el patrón que queremos: Equipo -> Ganas -> Partido -> Parte de -> Torneo RETURNes equivalente a la instrucción SQLSELECTdonde podemos devolver las propiedades de los nodos y relaciones devueltos. En esta cláusula, también se puede utilizar cualquier función de agregación admitida en Cypher. Anteriormente, estamos utilizandoCOUNT.- La cláusula
ORDER BYfunciona de la misma manera que la cláusula SQL. LIMITse utiliza para controlar la longitud de los registros devueltos.
Después de definir la consulta como una cadena de múltiples líneas, la pasamos a la execute_query() método del objeto driver y especificamos el nombre de la base de datos (predeterminado es neo4j). La salida siempre contiene tres objetos:
records: Una lista de objetos Record, cada uno representando una fila en el conjunto de resultados. Cada Record es un objeto similar a una tupla con nombre donde puede acceder a los campos por nombre o índice.resumen: Un objeto ResultSummary que contiene metadatos sobre la ejecución de la consulta, como estadísticas de consulta y información de tiempo.claves: Una lista de strings que representan los nombres de columnas en el conjunto de resultados.
Tocaremos elsummary objeto más adelante porque nuestro interés principal está enrecords, que contienenobjetos Record. Podemos recuperar su información llamando a sudata() método:
for record in records: print(record.data())
Salida:
{'Team': 'Brazil', 'MatchesWon': 76}
El resultado correctamente muestra que Brasil ha ganado la mayoría de los partidos de la Copa del Mundo.
Pasando parámetros de consulta
Nuestra última consulta no es reutilizable, ya que solo encuentra al equipo más exitoso de la historia de la Copa del Mundo. ¿Qué pasa si queremos encontrar el equipo más exitoso de la historia del Euro?
Este es el momento en el que entran los parámetros de consulta:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
En esta versión de la consulta, introducimos dos parámetros utilizando el signo $:
tournamentlimit
Para pasar valores a los parámetros de consulta, utilizamos argumentos de palabra clave dentro de execute_query:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
Salida:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
Siempre se recomienda usar parámetros de consulta cada vez que se esté pensando en ingestar valores cambiantes en su consulta. Esta mejor práctica protege sus consultas contra inyecciones de Cypher y permite a Neo4j cacharlas.
Escritura en bases de datos con las cláusulas CREATE y MERGE.
Escribir nueva información en una base de datos existente se realiza de manera similar con execute_query pero utilizando una CREATE cláusula en la consulta. Por ejemplo, vamos a crear una función que agregará un nuevo tipo de nodo – entrenadores de equipos:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
La función add_new_coach toma cinco parámetros:
- driver: El objeto driver de Neo4j utilizado para conectarse a la base de datos.
coach_name: El nombre del entrenador nuevo que se va a agregar.team_name: El nombre del equipo con el que se asociará el entrenador.start_date: La fecha en la que el entrenador comienza a entrenar al equipo.end_date: La fecha en la que finaliza el período de entrenamiento del entrenador con el equipo.
La consulta Cypher en la función realiza lo siguiente:
- Coincide con un nodo de Equipo existente que tenga el nombre de equipo dado.
- Crea un nuevo nodo de Entrenador con el nombre de entrenador proporcionado.
- Crea una relación COACHES entre los nodos Coach y Team.
- Establece las propiedades
start_dateyend_dateen la relaciónCOACHES.
La consulta se ejecuta usando la execute_query metodo, que toma la cadena de consulta y un diccionario de parametros.
Despues de la ejecucion, la funcion imprime:
- Un mensaje de confirmacion con los nombres del entrenador y del equipo y la fecha de inicio.
- El numero de nodos creados (deberia ser 1 para el nuevo nodo de Entrenador).
- El numero de relaciones creadas (deberia ser 1 para la nueva relacion
COACHES).
Vamos a trabajar con uno de los entrenadores más exitosos de la historia del fútbol internacional, Lionel Scaloni, quien ganó tres torneos internacionales importantes consecutivos (Copa del Mundo y dos Copas Américas):
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
En el fragmento de arriba, estamos utilizando la clase DateTime del módulo neo4j.time para pasar una fecha correctamente a nuestra consulta Cypher. El módulo contiene otros tipos de datos temporales útiles que puede que desee ver.
Además deCREATE, también existe laMERGE cláusula para crear nuevos nodos y relaciones. Su diferencia clave es:
CREATEsiempre crea nodos/relaciones nuevas, potencialmente llevando a duplicados.MERGEsólo crea nodos/relaciones si no existen ya.
Por ejemplo, en nuestro script de ingestión de datos, como lo verán más adelante:
- Usamos
MERGEpara equipos y jugadores para evitar duplicados. - Usamos
CREATEparaSCORED_FORySCORED_INdebido a que un jugador puede anotar varias veces en un mismo partido. - Estos no son verdaderos duplicados ya que tienen propiedades diferentes (por ejemplo, minuto del gol).
Este enfoque garantiza la integridad de los datos al permitir múltiples relaciones similares pero distintas.
Ejecución de tus propias transacciones
Cuando ejecutas execute_query, el controlador crea una transacción debajo de la capa. Una transacción es una unidad de trabajo que se ejecuta en su totalidad o se deshace como un fallo. Esto significa que cuando estás creando miles de nodos o relaciones en una sola transacción (es posible) y se encuentra algún error en el medio, toda la transacción falla sin escribir ningún nuevo dato en el grafo.
Para tener un control más fino sobre cada transacción, necesitas crear objetos de sesión. Por ejemplo, vamos a crear una función para encontrar los mejores K marcadores de gol en un torneo dado usando un objeto de sesión:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
Primero, creamostop_goal_scorersfunción que acepta tres parámetros, el más importante de los cuales es eltxobjeto de transacción que se obtendrá usando un objeto de sesión.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
Salida:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
Entonces, dentro de un contexto administrador creado con lasession()método, utilizamosexecute_read(), pasando latop_goal_scorers()función, junto con cualquier parámetro que la consulta requiera.
La salida de execute_read es una lista de objetos Record que correctamente muestran los 5 máximos goleadores de la historia de la Copa del Mundo, incluyendo nombres como Miroslav Klose, Ronaldo Nazário y Lionel Messi.
El equivalente de execute_read() para la ingesta de datos es execute_write().
Con esto dicho, vamos a echar un vistazo ahora al script de ingestión que utilizamos anteriormente para familiarizarnos con cómo funciona la ingestión de datos con el controlador de Neo4j en Python.
Ingestión de Datos Utilizando el Controlador de Neo4j en Python
El ingest_football_data.py archivo comienza con declaraciones de importación y carga de los archivos CSV necesarios:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging # Rutas de archivos CSV results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" # Configurar registro de actividad logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") # Cargar datos results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
Este bloque de código también establece un registrador. Las próximas líneas de código leen mis credenciales de Neo4j utilizando dotenv y crea un objeto Driver:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
Como hay más de 48k coincidencias en nuestra base de datos, definimos un parámetro BATCH_SIZE para ingestionar datos en pequeños lotes.
Entonces, definimos una función llamada create_indexes que acepta un objeto de sesión:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Los índices de Cypher son estructuras de base de datos que mejoran el rendimiento de las consultas en Neo4j. Ellos aceleran el proceso de búsqueda de nodos o relaciones basadas en propiedades específicas. Necesitamos estos para:
- Mejor rendimiento de ejecución de consultas
- Mejor rendimiento de lectura en conjuntos de datos grandes
- Eficiente coincidencia de patrones
- Implementación de restricciones únicas
- Mejor escalabilidad a medida que la base de datos crece
En nuestro caso, índices en nombres de equipos, ID de partidos y nombres de jugadores ayudarán a que nuestras consultas se ejecuten más rápido al buscar entidades específicas o al realizar unir operaciones entre diferentes tipos de nodos. Es una mejor práctica crear tales índices para sus propias bases de datos.
Después, tenemos la función ingest_matches . Es grande, así que vamos a desglosarla bloque por bloque:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
La primera cosa que notará es elUNWINDpalabra clave, que se utiliza para procesar un lote de datos. Toma el$batchparámetro (que serán nuestras filas de DataFrame) y recorre cada fila, permitiéndonos crear o actualizar varios nodos y relaciones en una sola transacción. Este enfoque es más eficiente que procesar cada fila individualmente, especialmente para conjuntos de datos grandes.
La otra parte de la consulta es familiar ya que utiliza varios MERGE cláusulas. Entonces, llegamos a la WITH cláusula, que utiliza FOREACH construcciones con IN CASE declaraciones. Estas se utilizan para crear relaciones condicionalmente basadas en el resultado de la coincidencia. Si el equipo local gana, crea una relación ‘GANÓ’ para el equipo local y una relación ‘PERDIÓ’ para el equipo visitante, y viceversa. En caso de empate, ambos equipos obtienen una relación ‘EMPATÓ’ con el partido.
La otra función divide el DataFrame recibido en partes que concuerdan y construye los datos que se pasarán a la $batch variable de consulta:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals y lasingest_shootouts funciones utilizan constructos similares. Sin embargo,ingest_goals tienen un manejo adicional de errores y valores faltantes.
Al final del script, tenemos la función main() que ejecuta todas nuestras funciones de ingestión con un objeto de sesión:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
Conclusión y próximos pasos
Hemos cubierto los aspectos clave de trabajo con bases de datos de grafos Neo4j utilizando Python:
- Conceptos y estructura de las bases de datos de grafos
- Configuración de Neo4j AuraDB
- Básicos del lenguaje de consulta Cypher
- Uso del controlador Neo4j para Python
- Ingestión de datos y optimización de consultas
Para avanzar en tu viaje con Neo4j, explora estos recursos:
- Documentación de Neo4j
- Biblioteca de Ciencia de Datos de Grafos de Neo4j
- Manual de Neo4j Cypher
- Documentación del Driver de Neo4j para Python
- Certificación de Carrera en Ingeniería de Datos
- Introducción a NoSQL
- Un tutorial integral de NoSQL utilizando MongoDB
Recuerde, el poder de las bases de datos de grafos radica en la representación y consulta de relaciones complejas. Continúe experimentando con diferentes modelos de datos y explorando las características avanzadas de Cypher.