













Wie in meinem vorherigen Artikel über Datenarchitekturen mit Schwerpunkt auf aufkommenden Trends diskutiert, ist die Datenverarbeitung eine der Schlüsselkomponenten in der modernen Datenarchitektur. Dieser Artikel behandelt verschiedene Alternativen zur Pandas-Bibliothek für bessere Leistung in Ihrer Datenarchitektur.
Die Datenverarbeitung und Datenanalyse sind entscheidende Aufgaben im Bereich der Datenwissenschaft und Datenverarbeitung. Mit wachsenden und komplexeren Datensätzen können traditionelle Tools wie Pandas mit Leistung und Skalierbarkeit zu kämpfen haben. Dies hat zur Entwicklung mehrerer alternativer Bibliotheken geführt, von denen jede dazu entwickelt wurde, spezifische Herausforderungen bei der Datenmanipulation und -analyse anzugehen.
Einführung
Die folgenden Bibliotheken haben sich als leistungsstarke Werkzeuge für die Datenverarbeitung erwiesen:
- Pandas – Das traditionelle Arbeitstier für die Datenmanipulation in Python
- Dask – Erweitert Pandas für die großangelegte, verteilte Datenverarbeitung
- DuckDB – Eine In-Process-Analyse-Datenbank für schnelle SQL-Abfragen
- Modin – Ein Ersatz für Pandas mit verbesserter Leistung
- Polars – Eine leistungsstarke DataFrame-Bibliothek, die auf Rust aufgebaut ist
- FireDucks – Eine compilerbeschleunigte Alternative zu Pandas
- Datatable – Eine leistungsstarke Bibliothek für die Datenmanipulation
Jede dieser Bibliotheken bietet einzigartige Funktionen und Vorteile, die verschiedenen Anwendungsfällen und Leistungsanforderungen gerecht werden. Lassen Sie uns jede im Detail erkunden:
Pandas
Pandas ist eine vielseitige und etablierte Bibliothek in der Datenwissenschaftsgemeinschaft. Sie bietet robuste Datenstrukturen (DataFrame und Series) und umfassende Tools für die Datenbereinigung und -transformation. Pandas glänzt bei der Datenexploration und -visualisierung mit umfangreicher Dokumentation und Community-Unterstützung.
Es hat jedoch Leistungsprobleme bei großen Datensätzen, ist auf Single-Thread-Operationen beschränkt und kann bei großen Datensätzen einen hohen Speicherverbrauch haben. Pandas eignet sich ideal für kleinere bis mittelgroße Datensätze (bis zu einigen GB) und wenn umfangreiche Datenmanipulation und -analyse erforderlich sind.
Dask
Dask erweitert pandas für die Verarbeitung großer Datenmengen, indem es paralleles Rechnen über mehrere CPU-Kerne oder Cluster und Out-of-Core-Berechnungen für Datensätze ermöglicht, die größer sind als der verfügbare RAM. Es skaliert pandas-Operationen auf Big Data und integriert sich gut in das PyData-Ökosystem.
Allerdings unterstützt Dask nur eine Teilmenge der pandas-API und kann komplex in der Einrichtung und Optimierung für verteiltes Rechnen sein. Es eignet sich am besten für die Verarbeitung extrem großer Datensätze, die nicht in den Speicher passen oder verteilte Rechenressourcen erfordern.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
Für bessere Leistung, laden Sie Daten mit Dask unter Verwendung von
dd.from_dict(data, npartitions=4anstelle des Pandas-Datenrahmensdd.from_pandas(df_pandas, npartitions=4)
Ausgabe
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB ist eine analytische Datenbank im Prozess, die schnelle analytische Abfragen mit einer spaltenbasierten, vektorisierenden Abfrage-Engine bietet. Sie unterstützt SQL mit zusätzlichen Funktionen und hat keine externen Abhängigkeiten, was die Einrichtung einfach macht. DuckDB bietet außergewöhnliche Leistung für analytische Abfragen und eine einfache Integration mit Python und anderen Sprachen.
Allerdings ist es nicht geeignet für transaktionale Arbeitslasten mit hohem Volumen und hat begrenzte Optionen für Parallelität. DuckDB glänzt bei analytischen Arbeitslasten, insbesondere wenn SQL-Abfragen bevorzugt werden.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
Ausgabe
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin zielt darauf ab, ein direkter Ersatz für pandas zu sein, der mehrere CPU-Kerne nutzt, um eine schnellere Ausführung zu ermöglichen und pandas-Operationen über verteilte Systeme zu skalieren. Es sind minimale Codeänderungen erforderlich, um es zu übernehmen, und es bietet das Potenzial für erhebliche Geschwindigkeitsverbesserungen auf Mehrkernsystemen.
Allerdings kann Modin in einigen Szenarien begrenzte Leistungsverbesserungen aufweisen und befindet sich noch in aktiver Entwicklung. Es ist am besten für Benutzer geeignet, die bestehende pandas-Workflows ohne größere Codeänderungen beschleunigen möchten.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
Ausgabe
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars ist eine leistungsstarke DataFrame-Bibliothek, die auf Rust basiert und ein speichereffizientes spaltenbasiertes Layout sowie eine Lazy-Evaluation-API für optimierte Abfrageplanung bietet. Es bietet außergewöhnliche Geschwindigkeit für Datenverarbeitungsaufgaben und Skalierbarkeit beim Umgang mit großen Datensätzen.
Allerdings hat Polars eine andere API als pandas, was ein gewisses Lernen erfordert, und könnte mit extrem großen Datensätzen (über 100 GB) Schwierigkeiten haben. Es ist ideal für Datenwissenschaftler und Ingenieure, die mit mittelgroßen bis großen Datensätzen arbeiten und Leistung priorisieren.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
Ausgabe
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks bietet volle Kompatibilität mit der pandas-API, multithreaded Ausführung und Lazy-Ausführung zur effizienten Optimierung des Datenflusses. Es verfügt über einen Laufzeit-Compiler, der die Codeausführung optimiert und erhebliche Leistungsverbesserungen im Vergleich zu pandas bietet. FireDucks ermöglicht eine einfache Übernahme aufgrund seiner Kompatibilität mit der pandas-API und der automatischen Optimierung von Datenoperationen.
Jedoch ist es relativ neu und hat möglicherweise weniger Community-Unterstützung und begrenzte Dokumentation im Vergleich zu etablierteren Bibliotheken.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
Ausgabe
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Datatable
Datatable ist eine leistungsstarke Bibliothek zur Datenmanipulation, die eine spaltenorientierte Datenspeicherung, eine nativ in C implementierte Unterstützung für alle Datentypen und mehrfädige Datenverarbeitung bietet. Sie bietet außergewöhnliche Geschwindigkeit für Datenverarbeitungsaufgaben, effiziente Speichernutzung und ist für die Verarbeitung großer Datensätze (bis zu 100 GB) konzipiert. Die API von Datatable ähnelt der von R’s data.table.
Allerdings weist sie im Vergleich zu pandas eine weniger umfassende Dokumentation, weniger Funktionen und keine Kompatibilität mit Windows auf. Datatable eignet sich ideal für die Verarbeitung großer Datensätze auf einer einzelnen Maschine, insbesondere wenn Geschwindigkeit entscheidend ist.
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
Ausgabe
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
Leistungsvergleich
- Datenladen: 34 Mal schneller als pandas für einen Datensatz von 5,7 GB
- Datensortierung: 36 Mal schneller als pandas
- Gruppenoperationen: 2 Mal schneller als pandas
Datatable glänzt in Szenarien mit groß angelegter Datenverarbeitung und bietet signifikante Leistungsverbesserungen gegenüber pandas für Operationen wie Sortierung, Gruppierung und Datenladen. Ihre mehrfädigen Verarbeitungsfähigkeiten machen sie besonders effektiv für die Nutzung moderner Multi-Core-Prozessoren
Schlussfolgerung
Zusammenfassend hängt die Wahl der Bibliothek von Faktoren wie der Datensatzgröße, den Leistungsanforderungen und den spezifischen Anwendungsfällen ab. Während pandas für kleinere Datensätze vielseitig bleibt, bieten Alternativen wie Dask und FireDucks starke Lösungen für die Verarbeitung von großen Datenmengen. DuckDB ist bei analytischen Abfragen überlegen, Polars bietet hohe Leistung für mittelgroße Datensätze, und Modin zielt darauf ab, pandas-Operationen mit minimalen Codeänderungen zu skalieren.
Das folgende Balkendiagramm zeigt die Leistung der Bibliotheken, wobei das DataFrame zum Vergleich verwendet wird. Die Daten sind normiert, um die Prozentsätze anzuzeigen.
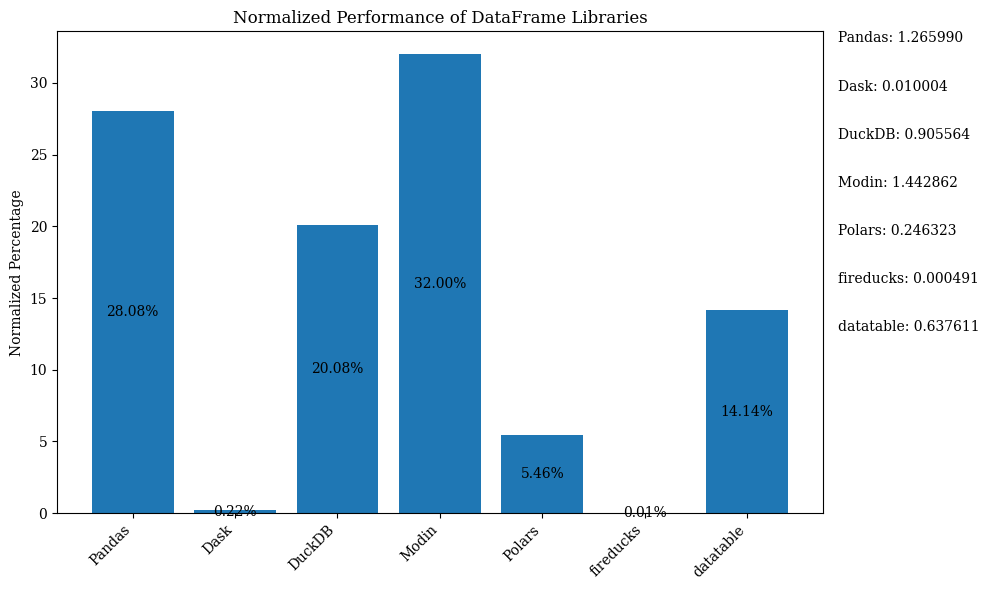
Für den Python-Code, der das oben genannte Balkendiagramm mit normierten Daten zeigt, siehe das Jupyter Notebook. Verwenden Sie Google Colab, da FireDucks nur unter Linux verfügbar ist.
Vergleichstabelle
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | Moderat | Niedrig | N/V (Original) | Kleine bis mittelgroße Datensätze, Datenexploration | Vielseitigkeit, reichhaltiges Ökosystem | Langsam bei großen Datensätzen, einsträngig |
| Dask | Hoch | Sehr hoch | Hoch | Große Datensätze, verteiltes Rechnen | Skaliert pandas-Operationen, verteilte Verarbeitung | Komplexe Einrichtung, teilweise pandas API-Unterstützung |
| DuckDB | Sehr hoch | Moderat | Niedrig | Analytische Abfragen, SQL-basierte Analyse | Schnelle SQL-Abfragen, einfache Integration | Nicht für transaktionale Arbeitslasten, begrenzte Parallelität |
| Modin | Hoch | Hoch | Sehr hoch | Beschleunigung bestehender Pandas-Workflows | Einfache Einführung, Multi-Core-Nutzung | Begrenzte Verbesserungen in einigen Szenarien |
| Polars | Sehr hoch | Hoch | Moderat | Mittlere bis große Datensätze, leistungskritisch | Außergewöhnliche Geschwindigkeit, moderne API | Lernkurve, Schwierigkeiten mit sehr großen Daten |
| FireDucks | Sehr hoch | Hoch | Sehr hoch | Große Datensätze, Pandas-ähnliche API mit Leistung | Automatische Optimierung, Pandas-Kompatibilität | Neuere Bibliothek, weniger Unterstützung aus der Community |
| Datatable | Sehr hoch | Hoch | Moderat | Große Datensätze auf einer einzelnen Maschine | Schnelle Verarbeitung, effiziente Speichernutzung | Begrenzte Funktionen, kein Windows-Support |
Diese Tabelle bietet einen schnellen Überblick über die Stärken, Einschränkungen und besten Anwendungsfälle jeder Bibliothek und ermöglicht einen einfachen Vergleich verschiedener Aspekte wie Leistung, Skalierbarkeit und API-Ähnlichkeit zu Pandas.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas