













In den letzten Jahren haben Transformer das NLP-Feld im maschinellen Lernen transformiert. Modelle wie GPT und BERT haben neue Maßstäbe im Verständnis und der Generierung menschlicher Sprache gesetzt. Nun wird dasselbe Prinzip auf das Gebiet des Computersehens angewendet.
Eine kürzliche Entwicklung im Bereich des Computersehens sind Vision-Transformer oder ViTs. Wie im Artikel „Ein Bild ist 16×16 Wörter wert: Transformer für die Bilderkennung im großen Maßstab“ detailliert beschrieben, sind ViTs und auf Transformer basierende Modelle entwickelt worden, um Faltungsneuronale Netze (CNNs) zu ersetzen.
Vision-Transformer sind ein neuer Ansatz zur Lösung von Problemen im Bereich des Computersehens. Anstatt sich auf herkömmliche Faltungsneuronale Netze (CNNs) zu verlassen, die jahrzehntelang das Rückgrat bildbezogener Aufgaben waren, verwenden ViTs die Transformer-Architektur zur Verarbeitung von Bildern. Sie behandeln Bildausschnitte wie Wörter in einem Satz, was dem Modell ermöglicht, die Beziehungen zwischen diesen Ausschnitten zu erlernen, ähnlich wie es den Kontext in einem Textabsatz erlernt.
Im Gegensatz zu CNNs unterteilen ViTs Eingabebilder in Patches, serialisieren sie zu Vektoren und reduzieren ihre Dimensionalität durch Matrixmultiplikation. Ein Transformer-Encoder verarbeitet dann diese Vektoren als Token-Einbettungen. In diesem Artikel werden wir Vision-Transformer und ihre Hauptunterschiede zu faltenden neuronalen Netzen erkunden. Was sie besonders interessant macht, ist ihre Fähigkeit, globale Muster in einem Bild zu verstehen, was für CNNs eine Herausforderung darstellen kann.
Voraussetzungen
- Grundlagen neuronaler Netze: Verständnis dafür, wie neuronale Netze Daten verarbeiten.
- Faltende neuronale Netze (CNNs): Vertrautheit mit CNNs und ihrer Rolle in der Computer Vision.
- Transformer-Architektur: Wissen über Transformer, insbesondere deren Verwendung in der NLP.
- Bildverarbeitung: Verständnis grundlegender Konzepte wie Bildrepräsentation, Kanäle und Pixelarrays.
- Aufmerksamkeitsmechanismus: Verständnis von Selbst-Aufmerksamkeit und ihrer Fähigkeit, Beziehungen zwischen Eingaben zu modellieren.
Was sind Vision-Transformer?
Vision-Transformer verwenden das Konzept der Aufmerksamkeit und Transformer, um Bilder zu verarbeiten – ähnlich wie Transformer im Kontext der natürlichen Sprachverarbeitung (NLP). Anstelle von Tokens wird das Bild jedoch in Patches aufgeteilt und als Sequenz von linearen Einbettungen bereitgestellt. Diese Patches werden genauso behandelt wie Tokens oder Wörter in NLP.
Statt das gesamte Bild gleichzeitig zu betrachten, schneidet ein ViT das Bild in kleine Stücke wie ein Puzzle. Jedes Stück wird in eine Liste von Zahlen (einem Vektor) umgewandelt, die seine Merkmale beschreiben, und dann betrachtet das Modell alle Stücke und ermittelt, wie sie zueinander in Beziehung stehen, mithilfe eines Transformer-Mechanismus.
Im Gegensatz zu CNNs funktionieren ViTs, indem spezifische Filter oder Kernel über ein Bild angewendet werden, um spezifische Merkmale wie Kantenmuster zu erkennen. Dies ist der Faltungsprozess, der sehr ähnlich ist wie das Scannen eines Bildes durch einen Drucker. Diese Filter gleiten durch das gesamte Bild und heben wichtige Merkmale hervor. Das Netzwerk stapelt dann mehrere Schichten dieser Filter übereinander und identifiziert allmählich komplexere Muster.
Bei CNNs verkleinern Pooling-Schichten die Größe der Merkmalskarten. Diese Schichten analysieren die extrahierten Merkmale, um Vorhersagen für die Bilderkennung, Objekterkennung usw. zu treffen. Allerdings haben CNNs ein festes rezeptives Feld, was die Fähigkeit zur Modellierung von langen Abhängigkeiten einschränkt.
Wie betrachtet CNN Bilder?
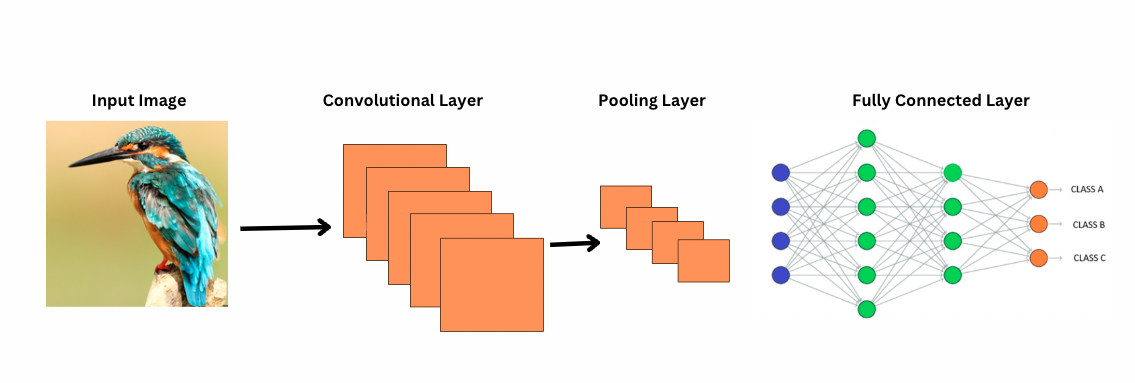
ViTs, obwohl sie mehr Parameter haben, verwenden Selbst-Aufmerksamkeitsmechanismen für eine bessere Merkmalsrepräsentation und reduzieren die Notwendigkeit für tiefere Schichten. CNNs erfordern eine deutlich tiefere Architektur, um eine ähnliche Repräsentationsleistung zu erreichen, was zu erhöhten Rechenkosten führt.
Zusätzlich können CNNs keine globalen Bildmuster erfassen, da ihre Filter sich auf lokale Regionen eines Bildes konzentrieren. Um das gesamte Bild oder entfernte Beziehungen zu verstehen, verlassen sich CNNs darauf, viele Schichten zu stapeln und Pooling durchzuführen, um das Sichtfeld zu erweitern. Dieser Prozess kann jedoch globale Informationen verlieren, da er schrittweise Details aggregiert.
ViTs hingegen unterteilen das Bild in Patches, die als einzelne Eingabetoken behandelt werden. Mit Selbst-Aufmerksamkeit vergleichen ViTs alle Patches gleichzeitig und lernen, wie sie sich zueinander verhalten. Dies ermöglicht es ihnen, Muster und Abhängigkeiten über das gesamte Bild hinweg zu erfassen, ohne sie Schicht für Schicht aufzubauen.
Was ist ein induktives Bias?
Bevor wir weitermachen, ist es wichtig, das Konzept des induktiven Bias zu verstehen. Der induktive Bias bezieht sich auf die Annahme, die ein Modell über die Datenstruktur trifft; während des Trainings hilft dies dem Modell, verallgemeinert zu werden und Vorurteile zu reduzieren. Bei CNNs umfassen induktive Bias Eigenschaften wie:
- Lokalität: Merkmale in Bildern (wie Kanten oder Texturen) sind innerhalb kleiner Regionen lokalisiert.
- Zweidimensionale Nachbarschaftsstruktur: Benachbarte Pixel sind wahrscheinlich miteinander verbunden, daher operieren Filter auf räumlich benachbarten Regionen.
- Translationsäquivarianz: Merkmale, die in einem Teil des Bildes erkannt werden, wie beispielsweise eine Kante, behalten dieselbe Bedeutung, wenn sie in einem anderen Teil erscheinen.
Diese Vorurteile machen CNNs für Bildaufgaben äußerst effizient, da sie inhärent darauf ausgelegt sind, die räumlichen und strukturellen Eigenschaften von Bildern auszunutzen.
Vision-Transformer (ViTs) weisen wesentlich weniger bildspezifische induktive Vorurteile als CNNs auf. In ViTs:
- Globale Verarbeitung: Self-Attention-Schichten operieren auf dem gesamten Bild, wodurch das Modell globale Beziehungen und Abhängigkeiten erfasst, ohne durch lokale Regionen eingeschränkt zu sein.
- Minimale 2D-Struktur: Die 2D-Struktur des Bildes wird nur zu Beginn verwendet (wenn das Bild in Patches unterteilt wird) und während des Feintunings (um Positionsembettierungen für unterschiedliche Auflösungen anzupassen). Anders als bei CNNs wird in ViTs nicht angenommen, dass benachbarte Pixel zwangsläufig miteinander verbunden sind.
- Gelernte räumliche Beziehungen: Positionsembettierungen in ViTs kodieren zu Beginn keine spezifischen 2D-räumlichen Beziehungen. Stattdessen lernt das Modell während des Trainings alle räumlichen Beziehungen aus den Daten.
Wie Vision-Transformer funktionieren
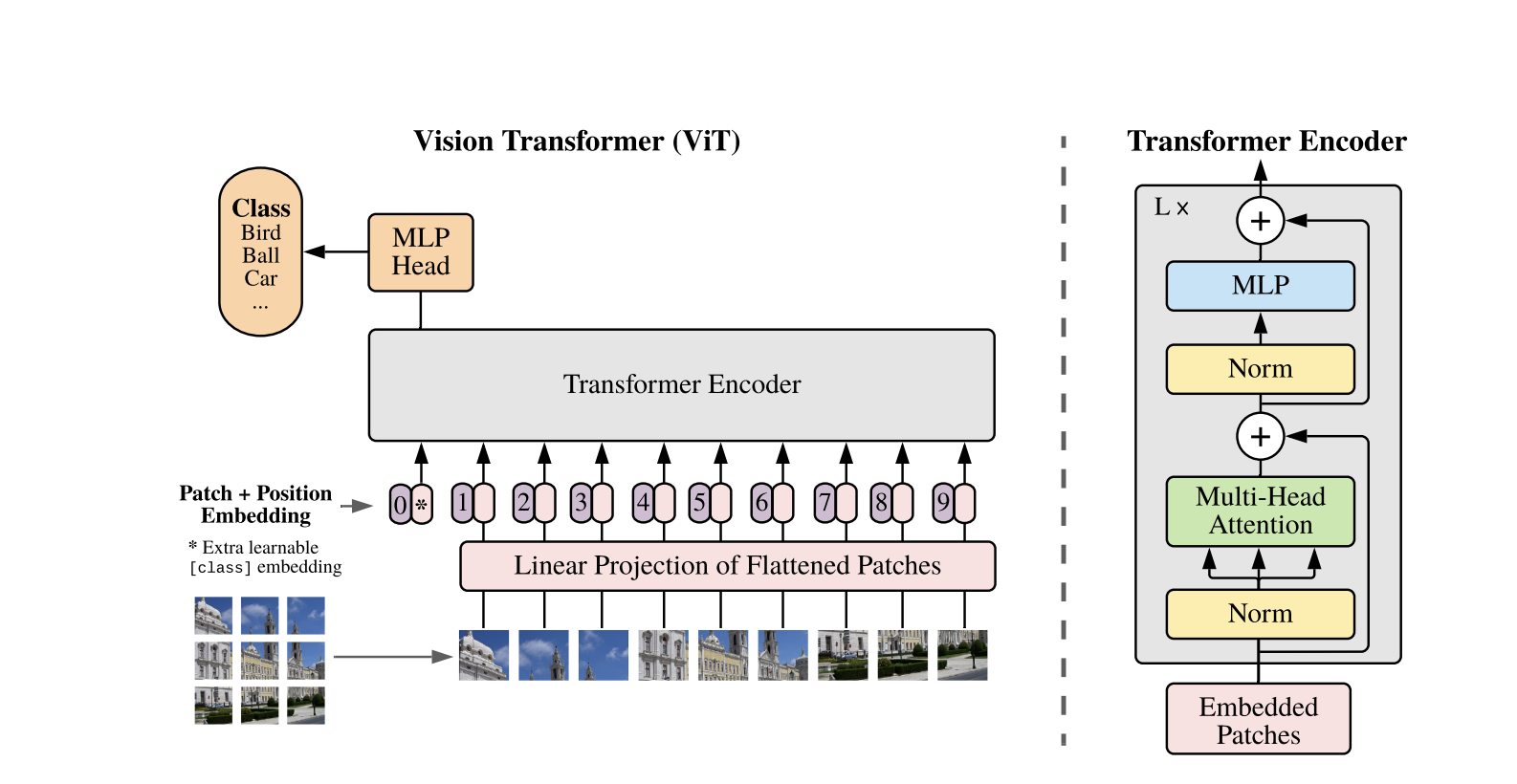
Vision Transformers verwenden die Standard-Transformer-Architektur, die für 1D-Textsequenzen entwickelt wurde. Um 2D-Bilder zu verarbeiten, werden sie in kleinere Patches fester Größe, wie z.B. P x P Pixel, unterteilt, die zu Vektoren umgeformt werden. Wenn das Bild die Abmessungen H x W mit C-Kanälen hat, ist die Gesamtanzahl der Patches N = H x W / P x P die effektive Eingabesequenzlänge für den Transformer. Diese flachen Patches werden dann linear in einen festen dimensionsbehafteten Raum D projiziert, der als Patch-Embeddings bezeichnet wird.
Ein spezielles erlernbares Token, ähnlich dem [CLS]-Token in BERT, wird der Sequenz von Patch-Embeddings vorangestellt. Dieses Token erlernt eine globale Bildrepräsentation, die später für die Klassifizierung verwendet wird. Zusätzlich werden den Patch-Embeddings positionale Embeddings hinzugefügt, um Positionsinformationen zu kodieren, was dem Modell hilft, die räumliche Struktur des Bildes zu verstehen.
Die Sequenz der Einbettungen wird durch den Transformer-Encoder geleitet, der zwischen zwei Hauptoperationen abwechselt: Mehrköpfige Selbst-Aufmerksamkeit (MSA) und ein feedforward neuronales Netzwerk, auch MLP-Block genannt. Jede Schicht enthält Schichtnormalisierung (LN), die vor diesen Operationen angewendet wird, und Residualverbindungen, die danach hinzugefügt werden, um das Training zu stabilisieren. Die Ausgabe des Transformer-Encoders, speziell der Zustand des [CLS]-Tokens, wird als Repräsentation des Bildes verwendet.
Ein einfacher Kopf wird dem finalen [CLS]-Token für Klassifizierungsaufgaben hinzugefügt. Während des Pretrainings handelt es sich bei diesem Kopf um ein kleines Multi-Layer-Perzeptron (MLP), während es beim Feintuning typischerweise um eine einzige lineare Schicht handelt. Diese Architektur ermöglicht es ViTs, globale Beziehungen zwischen Patches effektiv zu modellieren und die volle Kraft der Selbst-Aufmerksamkeit für das Verständnis von Bildern zu nutzen.
In einem hybriden Vision-Transformer-Modell wird anstelle von der direkten Unterteilung von Rohbildern in Patches die Eingabesequenz aus von einem CNN generierten Merkmalskarten abgeleitet. Das CNN verarbeitet das Bild zuerst und extrahiert bedeutungsvolle räumliche Merkmale, die dann verwendet werden, um Patches zu erstellen. Diese Patches werden flachgelegt und projiziert in einen festen-dimensionalen Raum mithilfe derselben trainierbaren linearen Projektion wie bei herkömmlichen Vision-Transformern. Ein spezieller Fall dieses Ansatzes ist die Verwendung von Patches der Größe 1×1, wobei jeder Patch einer einzelnen räumlichen Position in der Merkmalskarte des CNN entspricht.
In diesem Fall werden die räumlichen Dimensionen der Merkmalskarte abgeflacht, und die resultierende Sequenz wird in die Eingabedimension des Transformers projiziert. Wie beim Standard-ViT werden ein Klassifikationstoken und Positionscodierungen hinzugefügt, um Positionsinformationen beizubehalten und ein globales Bildverständnis zu ermöglichen. Dieser hybride Ansatz nutzt die lokalen Merkmalsextraktionsstärken von CNNs und kombiniert sie mit den globalen Modellierungsfähigkeiten von Transformern.
Code-Demo
Hier ist der Codeblock zur Verwendung der Vision-Transformer auf Bildern.
Das ViT-Modell verarbeitet das Bild. Es besteht aus einem BERT-ähnlichen Encoder und einem linearen Klassifikationskopf, der sich oben auf dem endgültigen versteckten Zustand des [CLS]-Tokens befindet.
Hier ist eine grundlegende Implementierung eines Vision-Transformers (ViT) unter Verwendung von PyTorch. Dieser Code enthält die Kernkomponenten: Patch-Einbettung, Positionscodierung und den Transformer-Encoder. Dies kann für einfache Klassifizierungsaufgaben verwendet werden.
Schlüsselkomponenten:
- Patch-Einbettung: Bilder werden in kleinere Patches unterteilt, flach gemacht und linear in Einbettungen transformiert.
- Positionscodierung: Positionsinformationen werden den Patch-Einbettungen hinzugefügt, da Transformer positionsunabhängig sind.
- Transformer-Encoder: Wendet Selbst-Aufmerksamkeit und Feed-Forward-Schichten an, um Beziehungen zwischen den Patches zu lernen.
- Klassifikationskopf: Gibt die Klassenwahrscheinlichkeiten unter Verwendung des CLS-Token aus.
Sie können dieses Modell auf jedem Bild Datensatz mit einem Optimierer wie Adam und einer Verlustfunktion wie Kreuzentropie trainieren. Für bessere Leistung sollten Sie in Erwägung ziehen, das Modell zunächst auf einem großen Datensatz vor dem Feintuning vorzutrainieren.
Beliebte Folgearbeiten
-
DeiT (Daten-effiziente Bild-Transformer) von Facebook AI: Dies sind Vision-Transformer, die effizient mit Wissensvermittlung trainiert wurden. DeiT bietet vier Varianten: deit-tiny, deit-small und zwei deit-base Modelle. Verwenden Sie
DeiTImageProcessorzur Vorbereitung von Bildern. -
BEiT (BERT-Vorbereitung von Bildtransformatoren) von Microsoft Research: Inspiriert von BERT verwendet BEiT selbstüberwachte maskierte Bildmodellierung und übertrifft überwachte ViTs. Es verlässt sich auf VQ-VAE für das Training.
-
DINO (Training von selbstüberwachten Vision-Transformern) von Facebook AI: Mit DINO trainierte ViTs können Objekte segmentieren, ohne explizites Training. Checkpoints sind online verfügbar.
-
MAE (Maskierte Autoencoder) von Facebook trainiert ViTs vor, indem maskierte Patches (75%) rekonstruiert werden. Bei Feinabstimmung übertrifft diese einfache Methode überwachte Vorabtrainings.
Schlussfolgerung
Zusammenfassend sind ViTs eine ausgezeichnete Alternative zu CNNs, da sie Transformer für die Bilderkennung anwenden, induktive Bias minimieren und Bilder als Sequenz-Patches behandeln. Dieser einfache, aber skalierbare Ansatz hat auf vielen Bildklassifizierungstests Spitzenleistungen gezeigt, insbesondere wenn er mit Vorabtrainings auf großen Datensätzen kombiniert wird. Es bleiben jedoch potenzielle Herausforderungen, darunter die Erweiterung von ViTs auf Aufgaben wie Objekterkennung und Segmentierung, die weitere Verbesserung von selbstüberwachten Vorabtrainingsmethoden und die Erkundung des Potenzials der Skalierung von ViTs für noch bessere Leistungen.
Zusätzliche Ressourcen
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision