













Einführung
Hallo Leserinnen und Leser, dies ist eine weitere Folge von Beiträgen, die wir zu PyTorch verfassen. Dieser Beitrag ist auf PyTorch-Nutzer zugeschnitten, die mit den Grundlagen von PyTorch vertraut sind und sich auf einen mittleren Niveau bewegen möchten. Obwohl wir in einem früheren Beitrag erklärt haben, wie man eine grundlegende Klassifikator in PyTorch implementiert, geht es in diesem Beitrag darum, komplexere Deep Learning-Funktionalität mit PyTorch zu implementieren. Einige der Ziele dieses Beitrags sind es, Ihnen zu vermitteln:.
- Wie unterscheidet sich die PyTorch-Klasse wie
nn.Module,nn.Functional,nn.Parameterund in welchem Fall welche zu verwenden - Wie man seine Trainingsoptionen anpassen kann, wie z.B. unterschiedliche Lernraten für verschiedene Schichten, unterschiedliche Lernratepläne
- Benutzerdefinierte Gewichtsinitialisierung
Also, lassen Sie uns beginnen.
nn.Module vs nn.Functional
Das ist was, was häufig genug ist, besonders, wenn Sie open-source-Code lesen. In PyTorch sind Layers oft als entweder eine der torch.nn.Module-Objekte oder torch.nn.Functional-Funktionen implementiert. Welches sollte man verwenden? Welches ist besser?
Wie wir in Teil 2 gesehen haben, ist torch.nn.Module die grundlegende Struktur von PyTorch. Der Arbeitsweise geht es darum, zunächst ein nn.Module-Objekt zu definieren und dann seine forward-Methode aufzurufen, um es zu betreiben. Dies ist ein objektorientierter Ansatz.
Andrerseits bietet nn.functional einige Schichten/Aktivierungen in Form von Funktionen, die direkt auf das Eingabetensor angewendet werden können, anstatt ein Objekt zu definieren. Zum Beispiel, um ein Bildtensor neu skalieren zu können, ruft man torch.nn.functional.interpolate auf einem Bildtensor auf.
Wie wir also wählen, was wir wann verwenden? Wenn die Schicht/Aktivierung/Verlust, die wir implementieren, einen Verlust enthält.
Verständnis von Stateful-ness
Normalerweise kann jede Schicht als Funktion betrachtet werden. Zum Beispiel ist eine konvolutionelle Operation nur eine Ansammlung von Multiplikationen und Additionen. Es ergibt also Sinn, sie als Funktion zu implementieren. Aber warten Sie mal, die Schicht behält Gewichte, die gespeichert und während der Trainingsperiode aktualisiert werden müssen. Daher ist eine Schicht programmiertechnisch mehr als nur eine Funktion. Sie muss auch Daten aufnehmen, die sich während des Trainings unserer Netze ändern.
Ich möchte nun hervorheben, dass die Daten, die vom Konvolutionslayer gehalten werden, veränderlich sind. Dies bedeutet, dass der Layer einen Zustand hat, der während der Trainingszeit verändert wird. Um eine Funktion zu implementieren, die die Konvolutionsoperation durchführt, müssten wir zusätzlich eine Datenstruktur definieren, um die Gewichte des Layers separat von der Funktion selbst zu halten. Und dann diese externe Datenstruktur als Eingaben für unsere Funktion machen.
Oder um die Mühe zu ersparen, könnten wir einfach eine Klasse definieren, um die Datenstruktur zu halten, und die Konvolutionsoperation als Mitgliedsfunktion aufweisen. Dies würde unser Arbeit wirklich erleichtern, da wir uns nicht Sorgen machen müssen, ob außerhalb der Funktion stateful-Variablen existieren. In solchen Fällen bevorzugen wir die nn.Module-Objekte, in denen Gewichte oder andere Zustände existieren, die das Verhalten des Layers möglicherweise definieren. Zum Beispiel verhalten sich eine Dropout-/Batch-Norm-Schicht unterschiedlich während der Trainings- und Inferenzphasen.
Andersseits kann man, wenn kein Zustand oder Gewichte erforderlich sind, die nn.functional verwenden. Beispiele dafür sind die Vergrößerung (nn.functional.interpolate) und die lineare Poolschießen (nn.functional.AvgPool2d).
Trotz der obigen Begründung haben die meisten nn.Module-Klassen ihre nn.functional-Gegenstücke. Allerdings sollte die oben genannte Reihenfolge von Argumenten in der Praxis beachtet werden.
nn.Parameter
Eine wichtige Klasse in PyTorch ist die Klasse nn.Parameter, die zu meiner Überraschung in den Einführungstexten zu PyTorch nur selten behandelt wird. Betrachten wir den folgenden Fall.
Jeder nn.Module hat eine Funktion parameters(), die, wie es sich vermuten lässt, seine trainierbaren Parameter zurückgibt. Wir müssen implizit definieren, was diese Parameter sind. In der Definition von nn.Conv2d haben die Entwickler von PyTorch die Gewichte und Vorzeichen als Parameter einer Schicht festgelegt. Allerdings bemerken Sie, dass, wenn wir net definiert haben, wir die parameters von nn.Conv2d nicht direkt zu den parameters von net hinzugefügt haben. Dies ist implizit durch die Aufnahme des nn.Conv2d-Objekts als Bestandteil des net-Objekts erfolgt.
Dies wird intern durch die Klasse nn.Parameter unterstützt, die eine Unterklasse der Klasse Tensor ist. Wenn wir die Funktion parameters() the eines nn.Module-Objekts aufrufen, wird es alle Mitglieder zurückgeben, die nn.Parameter-Objekte sind.
Tatsächlich sind alle trainierten Gewichte der nn.Module-Klassen als nn.Parameter-Objekte implementiert. Wenn ein nn.Module (nn.Conv2d in unserem Fall) als Mitglied eines anderen nn.Module festgelegt wird, werden die „Parameter“ des Zielobjekts (d.h. die Gewichte von nn.Conv2d) ebenfalls den „Parameter“ des Zielobjekts hinzugefügt (Parameter des net-Objekts). Dies wird als Registrierung der „Parameter“ eines nn.Module bezeichnet.
Wenn du versuchst, einen Tensor einem nn.Module-Objekt zuzuweisen, wird er in der Methode parameters() nicht aufgeführt,除非 du ihn als nn.Parameter-Objekt definierst. Dies wurde durchgeführt, um Szenarien zu erleichtern, in denen du einen nicht-differenzierbaren Tensor cachen möchtest, beispielsweise den vorherigen Ausgang bei RNNs.
nn.ModuleList und nn.ParameterList()
Ich erinnere mich, dass ich eine nn.ModuleList verwendet habe, als ich YOLO v3 in PyTorch implementierte. Ich musste die Netzwerkarchitektur aus einem Textdatei parsen, die die Architektur enthielt. Ich habe alle nn.Module-Objekte in einer Python-Liste gespeichert und dann die Liste zu einem Mitglied meines nn.Module-Objekts, das das Netz repräsentiert, gemacht.
Zum Vereinfachen, etwas wie dies.
Wie du siehst, unterscheidet sich die Registrierung eines Python-Listens von der Registrierung einzelner Module. Um dies zu beheben, wrappiere ich meine Liste mit der Klasse `nn.ModuleList` und weise sie als Mitglied der Netzwerkklasse zu.
Ähnlichermaßen kann eine Liste von Tensoren registriert werden, indem die Liste innerhalb einer Klasse `nn.ParameterList` wrappiert wird.
Gewichtser initialisierung
Die Gewichtser initialisierung kann die Ergebnisse Ihrer Trainings beeinflussen. Es gibt auch verschiedene Initialisierungsstrategien für verschiedene Arten von Schichten, die mit den Funktionen `modules` und `apply` realisiert werden können. `modules` ist ein Mitgliedsfunktion der Klasse `nn.Module`, die ein Iterator zurückgibt, der alle Mitgliedsobjekte der Klasse `nn.Module` enthält. Anschließend kann die Funktion `apply` auf jedes `nn.Module` angewendet werden, um die Initialisierung zu setzen.
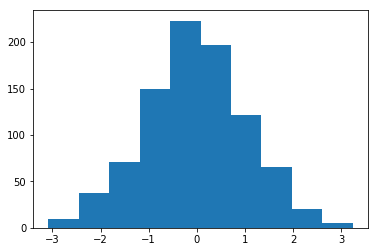
Histogramm der mit Mittelwert = 1 und Standardabweichung = 1 initialisierten Gewichte
Es gibt eine Vielzahl von inplace-Initialisierungsfunktionen im Modul `torch..nn.init`.
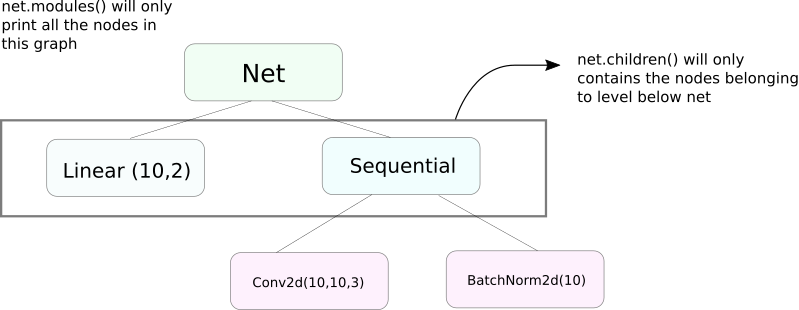
Modulen() vs Kinderen()
Eine sehr ähnliche Funktion wie modules ist children. Der Unterschied ist zwar ein kleiner, aber ein wichtiger. Wie wir wissen, kann ein nn.Module Objekt andere nn.Module Objekte als Datenmitglieder enthalten.
children() wird nur eine Liste der nn.Module Objekte liefern, die Datenmitglieder des Objekts sind, auf dem children aufgerufen wird.
Andererseits lädt nn.Modules rekursiv in jedes nn.Module Objekt ein, erstellt eine Liste jedes nn.Module Objektes, das auf dem Weg kommt, bis es keine nn.module Objekte mehr gibt. Beachten Sie, dass modules() auch das nn.Module aufruft, das es selbst ist, als Teil der Liste zurückgibt.
Beachten Sie, dass der oben genannte Satz für alle Objekte/Klassen gilt, die von der Klasse nn.Module abgeleitet sind.
Also, wenn wir die Gewichte initialisieren, möglicherweise modules() Funktion verwenden, da wir nicht in das nn.Sequential Objekt gehen und die Gewichte für seine Mitglieder initialisieren können.
Drucken von Informationen über das Netz
Wir möglicherweise Informationen über das Netz drucken, ob es sich um Benutzerinformationen oder um Zwecke der Debugging handelt. PyTorch bietet eine sehr nette Methode, um viele Informationen über unser Netz auszugeben, indem Sie seine named_* Funktionen verwenden. Es gibt 4 solcher Funktionen.
named_parameters. Gibt einen Iterator zurück, der ein Tupel enthält, das die Name der Parameter enthält (wenn eine konvolutionelle Schicht alsself.conv1zugewiesen ist, dann würden ihre Parameterconv1.weightundconv1.biassein) und den Wert zurückliefern, der von der__repr__Funktion desnn.Parameterentnommen wird.
2. named_modules. Identisch wie oben, aber der Iterator gibt Module zurück, wie die modules() Funktion tut.
3. named_children Identisch wie oben, aber der Iterator gibt Module zurück, wie die children() Funktion zurückgibt.
4. named_buffers Gibt Puffer-Tensoren zurück, wie den laufenden Durchschnitt eines Batch-Norm-Layers.
Unterschiedliche Lernraten für verschiedene Schichten
In diesem Abschnitt lernen wir, wie wir unterschiedliche Lernraten für unsere verschiedenen Schichten verwenden können. Im Allgemeinen werden wir erfahren, wie verschiedene Hyperparameter für verschiedene Parametergruppen verwendet werden können, ob es sich um unterschiedliche Lernraten für verschiedene Schichten oder unterschiedliche Lernraten für Verzerrungen und Gewichte handelt.
Der Gedanke, solche Dinge zu implementieren, ist relativ einfach. In unserem vorherigen Beitrag haben wir eine CIFAR-Klassifikator implementiert und alle Netzparameter als Ganzes an den Optimiererobjekt übergeben.
Allerdings erlaubt die Klasse `torch.optim` es uns, verschiedene Parametergruppen mit unterschiedlichen Lernraten in Form eines Wörterbuchs anzugeben.
In dem obigen Szenario verwendet das Parameter `fc1` eine Lernrate von 0.01 und einen Momentschritt von 0.99. Wenn für eine Parametergruppe kein Hyperparameter angegeben ist (wie `fc2`), nutzen sie die Standardwerte dieses Hyperparameters, die als Eingangsargument für die Optimiererfunktion gegeben sind. Man könnte Parameterlisten auf der Basis verschiedener Schichten oder entweder ob das Parameter ein Gewicht oder ein Verzögerungsparameter ist erstellen, indem die Funktion `named_parameters()` verwendet wird, die wir oben behandelt haben.
Lernrateplanung
Die Planung Ihrer Lernrate ist eine Haupthyperparameter, der Sie justieren möchten. PyTorch bietet Unterstützung für die Planung von Lernraten mit dem Modul `torch.optim.lr_scheduler` an, das eine Vielzahl von Lernrateplänen bereitstellt. Der folgende Beispiel demonstriert einen solchen Fall.
Der oben genannte Scheduler multipliziert die Lernrate durch gamma bei jeder Rekursion, wenn wir Epochen erreichen, die in der milestones-Liste enthalten sind. In unserem Fall wird die Lernrate bei der 10. und 20. Epoche durch 0.1 multipliziert. Du musst auch die Zeile scheduler.step in deinem Code schreiben, der in den Epochen iteriert, sodass die Lernrate aktualisiert wird.
Allgemein besteht ein Trainingsoberschwung aus zwei verschachtelten Schleifen, wobei eine Schleife über die Epochen geht und die andere in dieser Epoche über die Batches geht. Stelle sicher, dass du scheduler.step am Anfang der Epochenschleife aufrufst, sodass deine Lernrate aktualisiert wird. Vorsicht, nicht in der Batch-Schleife zu schreiben, andernfalls könnte deine Lernrate beim 10. Batch aktualisiert werden und nicht beim 10. Epochen.
Erinner dich auch daran, dass scheduler.step kein Ersatz für optim.step ist und du optim.step jedes Mal aufrufen musst, wenn du rückwärts propagierst. (Dies würde in der „Batch“-Schleife sein).
Model abspeichern
Möglicherweise möchtest du dein Modell später für Inferenzen nutzen oder einfach Checkpoints für die Training absetzen. Beim Speichern von Modellen in PyTorch hat man zwei Optionen.
Die erste Option ist das Verwenden von torch.save. Dies ist gleichbedeutend mit der Serialisierung des gesamten nn.Module-Objekts mit Pickle. Dies speichert das gesamte Modell auf der Festplatte. Du kannst dieses Modell später im Speicher mit torch.load laden.
Der obige Abschnitt speichert die gesamte Modelle mit Gewichten und Architektur. Wenn Sie nur die Gewichte speichern möchten und nicht das gesamte Model, können Sie stattdessen nur den state_dict des Models speichern. Der state_dict ist grundsätzlich ein Dictionary, das die nn.Parameter-Objekte einer Netzwerkkarte auf ihre Werte abbildet.
Wie oben gezeigt, kann man ein vorhandenes state_dict in ein nn.Module-Objekt laden. Beachten Sie, dass dies nicht das gesamte Modell speichert, sondern nur die Parameter. Sie müssen das Netz mit Schichten erstellen, bevor Sie den state dict laden. Wenn die Netzwerkarchitektur nicht exakt dieselbe ist, wie das, dessen state_dict Sie gespeichert haben, werfen PyTorch einen Fehler aus.
Ein Optimizer-Objekt von torch.optim hat auch einen state_dict-Objekt, das zur Speicherung der Hyperparameter der Optimierungsalgorithmen verwendet wird. Es kann in einer ähnlichen Weise gespeichert und geladen werden, indem auf ein Optimizer-Objekt die Methode load_state_dict aufgerufen wird.
Fazit
Dadurch ist unser Gespräch über einige der fortschrittlicheren Features von PyTorch beendet. Ich hoffe, dass die Dinge, die Sie in diesem Beitrag gelesen haben, Ihnen helfen werden, kompliziertere Deep Learning-Ideen zu implementieren, die Sie selbst erdacht haben. Hier sind Links für weitere Studien, sollten Sie dazu interessiert sein.
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced