













كما تم مناقشته في مقالي السابق حول هياكل البيانات التي تبرز الاتجاهات الناشئة، تعتبر معالجة البيانات واحدة من المكونات الأساسية في هيكلة البيانات الحديثة. يناقش هذا المقال بدائل مختلفة لمكتبة Pandas لتحقيق أداء أفضل في هيكلة بياناتك.
تعتبر معالجة البيانات وتحليل البيانات مهام حاسمة في مجال علم البيانات وهندسة البيانات. مع تزايد حجم وتعقيد مجموعات البيانات، يمكن أن تواجه الأدوات التقليدية مثل Pandas صعوبات في الأداء وقابلية التوسع. وقد أدى ذلك إلى تطوير العديد من المكتبات البديلة، كل منها مصمم لمعالجة تحديات محددة في معالجة وتحليل البيانات.
مقدمة
ظهرت المكتبات التالية كأدوات قوية لمعالجة البيانات:
- Pandas – الحصان التقليدي لعمليات معالجة البيانات في بايثون
- Dask – توسع pandas لمعالجة البيانات على نطاق واسع وموزع
- DuckDB – قاعدة بيانات تحليلية داخل العملية لاستعلامات SQL السريعة
- Modin – بديل مباشر لـ pandas مع تحسينات في الأداء
- بولارز – مكتبة DataFrame عالية الأداء مبنية على لغة Rust
- فاير داكس – بديل معزز بواسطة المترجم لمكتبة pandas
- بيانات الجدول – مكتبة عالية الأداء لمعالجة البيانات
كل واحدة من هذه المكتبات تقدم ميزات وفوائد فريدة، تلبي حالات استخدام ومتطلبات أداء مختلفة. دعونا نستكشف كل واحدة بالتفصيل:
باندا
باندا هي مكتبة متعددة الاستخدامات ومثبتة جيداً في مجتمع علوم البيانات. تقدم هياكل بيانات قوية (DataFrame و Series) وأدوات شاملة لتنظيف البيانات وتحويلها. تتميز باندا في استكشاف البيانات والتصور، مع وثائق واسعة ودعم مجتمعي.
ومع ذلك، تواجه مشاكل في الأداء مع مجموعات البيانات الكبيرة، ومقيدة بالعمليات ذات الخيط الواحد، ويمكن أن يكون لديها استخدام عالي للذاكرة لمجموعات البيانات الكبيرة. باندا مثالية لمجموعات البيانات الصغيرة إلى المتوسطة (حتى عدة جيجابايت) وعندما تكون هناك حاجة إلى معالجة وتحليل بيانات واسعة النطاق.
داك
داكس يوسع باندا لمعالجة البيانات على نطاق واسع، حيث يقدم حوسبة متوازية عبر نوى وحدة المعالجة المركزية المتعددة أو الكتل، وحسابات خارج الذاكرة لمجموعات البيانات التي تفوق الذاكرة المتاحة. يقوم بتوسيع عمليات باندا لتناسب البيانات الكبيرة ويتكامل بشكل جيد مع نظام بيانات باي.
ومع ذلك، يدعم داكس فقط مجموعة فرعية من واجهة برمجة تطبيقات باندا وقد يكون من المعقد إعدادها وتحسينها للحوسبة الموزعة. إنه الأنسب لمعالجة مجموعات البيانات الكبيرة للغاية التي لا تتناسب مع الذاكرة أو تتطلب موارد حوسبة موزعة.
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
للحصول على أداء أفضل، قم بتحميل البيانات باستخدام داكس باستخدام
dd.from_dict(data, npartitions=4بدلاً من إطار بيانات بانداdd.from_pandas(df_pandas, npartitions=4)
الإخراج
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
داك دي بي
داك دي بي هو قاعدة بيانات تحليلية تعمل داخل العملية تقدم استعلامات تحليلية سريعة باستخدام محرك استعلام عمودي موجه. يدعم SQL مع ميزات إضافية وليس لديه تبعيات خارجية، مما يجعل الإعداد بسيطًا. يوفر داك دي بي أداءً استثنائيًا للاستعلامات التحليلية وتكاملًا سهلًا مع بايثون ولغات أخرى.
ومع ذلك، فإنه ليس مناسبًا لأحمال المعاملات عالية الحجم وله خيارات تزامن محدودة. يتفوق داك دي بي في أحمال العمل التحليلية، خاصة عندما تفضل استعلامات SQL.
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
الإخراج
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
مودين
يهدف Modin إلى أن يكون بديلاً سهلاً لـ pandas، مستخدمًا عدة نوى CPU لتحقيق تنفيذ أسرع وتوسيع عمليات pandas عبر الأنظمة الموزعة. يتطلب تغييرات رمزية قليلة للتبني ويقدم إمكانيات لتحسين سرعة كبيرة على الأنظمة متعددة النوى.
ومع ذلك، قد يكون لدى Modin تحسينات أداء محدودة في بعض السيناريوهات ولا يزال قيد التطوير النشط. إنه الأفضل للمستخدمين الذين يتطلعون إلى تسريع سير عمل pandas الحالي دون تغييرات كبيرة في الشفرة.
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
الإخراج
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars هي مكتبة DataFrame عالية الأداء مبنية على Rust، تتميز بتخطيط ذاكرة عمودي موفر للذاكرة وواجهة API للتقييم الكسول لتخطيط الاستعلام المحسن. تقدم سرعة استثنائية لمهام معالجة البيانات وقابلية التوسع للتعامل مع مجموعات بيانات كبيرة.
ومع ذلك، لدى Polars واجهة API مختلفة عن pandas، مما يتطلب بعض التعلم، وقد تواجه صعوبة مع مجموعات البيانات الكبيرة جدًا (أكثر من 100 جيجابايت). إنها مثالية لعلماء البيانات والمهندسين الذين يعملون مع مجموعات بيانات متوسطة إلى كبيرة ويعطون الأولوية للأداء.
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
الإخراج
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
تقدم FireDucks توافقًا كاملاً مع واجهة API الخاصة بـ pandas، وتنفيذ متعدد الخيوط، وتنفيذ كسول لتحسين تدفق البيانات بكفاءة. تتميز بمجمع وقت التشغيل الذي يُحسن تنفيذ الشفرة، مما يوفر تحسينات أداء كبيرة مقارنةً بـ pandas. تتيح FireDucks تبنيًا سهلاً نظرًا لتوافقها مع واجهة API الخاصة بـ pandas والتحسين التلقائي لعمليات البيانات.
ومع ذلك، فهي جديدة نسبيًا وقد تحظى بدعم مجتمعي أقل ووثائق محدودة مقارنة بالمكتبات الأكثر رسوخًا.
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
الإخراج
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Datatable
Datatable هي مكتبة عالية الأداء لمعالجة البيانات، تتميز بتخزين البيانات على أساس الأعمدة، وتنفيذ بلغة C الأصلية لجميع أنواع البيانات، ومعالجة البيانات المتعددة الخيوط. تقدم سرعة استثنائية لمهام معالجة البيانات، واستخدام فعال لذاكرة الحاسوب، وصممت للتعامل مع مجموعات بيانات كبيرة (تصل إلى 100 جيجابايت). واجهة برمجة التطبيقات الخاصة بـ Datatable مشابهة لتلك الخاصة بـ data.table في R.
ومع ذلك، فإنها تحتوي على وثائق أقل شمولاً مقارنة بـ pandas، وميزات أقل، وليست متوافقة مع نظام ويندوز. Datatable مثالية لمعالجة مجموعات البيانات الكبيرة على جهاز واحد، خاصة عندما تكون السرعة حاسمة.
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
الإخراج
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
مقارنة الأداء
- تحميل البيانات: أسرع 34 مرة من pandas لمجموعة بيانات بحجم 5.7 جيجابايت
- فرز البيانات: أسرع 36 مرة من pandas
- عمليات التجميع: أسرع مرتين من pandas
تتفوق Datatable في السيناريوهات التي تتطلب معالجة بيانات على نطاق واسع، حيث تقدم تحسينات كبيرة في الأداء مقارنة بـ pandas لعمليات مثل الفرز والتجميع وتحميل البيانات. إن قدراتها في المعالجة متعددة الخيوط تجعلها فعالة بشكل خاص في الاستفادة من المعالجات الحديثة متعددة النوى
الخاتمة
في الختام، يعتمد اختيار المكتبة على عوامل مثل حجم مجموعة البيانات، ومتطلبات الأداء، والحالات الاستخدام المحددة. بينما تظل مكتبة “باندا” متعددة الاستخدامات لمجموعات البيانات الصغيرة، تقدم بدائل مثل “داستك” و”فايرداكس” حلولاً قوية لمعالجة البيانات على نطاق واسع. تتفوق “داك دي بي” في الاستعلامات التحليلية، بينما توفر “بولارس” أداءً عاليًا لمجموعات البيانات المتوسطة الحجم، وتهدف “مودين” إلى توسيع عمليات “باندا” مع تغييرات طفيفة في الشيفرة.
يوضح الرسم البياني أدناه أداء المكتبات، باستخدام “DataFrame” للمقارنة. تم تطبيع البيانات لإظهار النسب المئوية.
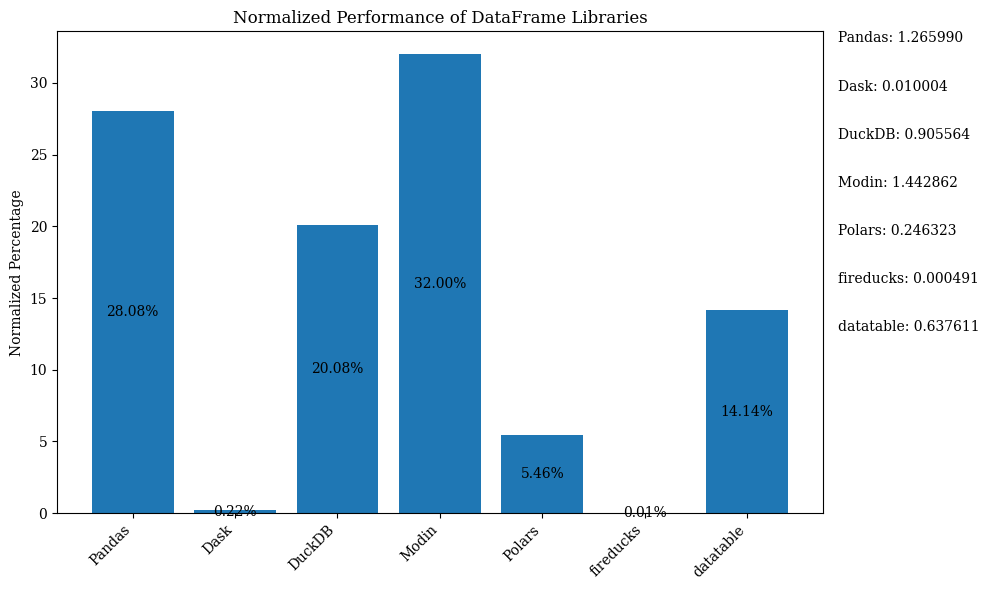
للحصول على كود بايثون الذي يعرض الرسم البياني الشريطي أعلاه مع البيانات المطبوعة، يرجى الرجوع إلى دفتر جوبتر. استخدم “جوجل كولاب” حيث أن “فايرداكس” متاحة فقط على نظام لينكس
رسم بياني للمقارنة
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| باندا | متوسطة | منخفضة | غير متاحة (أصلية) | مجموعات بيانات صغيرة إلى متوسطة، استكشاف البيانات | تعدد الاستخدامات، نظام بيئي غني | بطيئة مع مجموعات البيانات الكبيرة، خيط واحد |
| داستك | عالية | عالية جداً | عالية | مجموعات بيانات كبيرة، حوسبة موزعة | توسيع عمليات باندا، معالجة موزعة | إعداد معقد، دعم جزئي لواجهة برمجة تطبيقات باندا |
| داك دي بي | عالية جداً | متوسطة | منخفضة | استعلامات تحليلية، تحليل قائم على SQL | استعلامات SQL سريعة، تكامل سهل | غير مخصص لأحمال العمل المعاملات، تزامن محدود |
| مودين | عالي | عالي | عالي جداً | تسريع سير العمل الحالي لـ pandas | اعتماد سهل، استخدام متعدد النواة | تحسينات محدودة في بعض السيناريوهات |
| بولارس | عالي جداً | عالي | معتدل | مجموعة بيانات متوسطة إلى كبيرة، حرجة من حيث الأداء | سرعة استثنائية، واجهة برمجة تطبيقات حديثة | منحنى تعلم، صعوبات مع البيانات الكبيرة جداً |
| فاير داكس | عالي جداً | عالي | عالي جداً | مجموعة بيانات كبيرة، واجهة برمجة تطبيقات مشابهة لـ pandas مع أداء | تحسين تلقائي، توافق مع pandas | مكتبة جديدة، دعم مجتمع أقل |
| جدول البيانات | عالي جداً | عالي | معتدل | مجموعة بيانات كبيرة على جهاز واحد | معالجة سريعة، استخدام فعال للذاكرة | ميزات محدودة، عدم دعم لنظام ويندوز |
يوفر هذا الجدول نظرة سريعة على نقاط القوة والقيود وحالات الاستخدام المثلى لكل مكتبة، مما يسمح بمقارنة سهلة عبر جوانب مختلفة مثل الأداء، قابلية التوسع، وتشابه واجهة برمجة التطبيقات مع pandas.
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas