













مقدمة
مرحبا يا قراءة، هذه من أشياء أخرى في سلسلة نشر نحن نقوم بها بـ PyTorch. هذا المقال يهدف للمستخدمين المتأهلين بPyTorch والذين يرغبون في تحرك إلى مستوى متوسط. بينما قمنا بتغطية كيفية تنفيذ مصنف بسيط في مقال سابق، في هذا المقال سنتحدث عن كيفية تنفيذ وظائف عميقة أكثر للتعلم العميق باستخدام PyTorch. بعض أهداف هذه المقالة هو منحك فهم.
- ما هو فرق الأقسام التي يمكن أن تكون مثل
nn.Module،nn.Functional،nn.Parameterوأين يتم استخدام كل منها ولماذا - كيفية تخصيص خيارات تعلمك مثل معدلات تعلم مختلفة للطبقات مختلفة، جداول تنظيم المعدلات المختلفة
- توليد الوزنات الشخصية الخاصة
إذاً، دعونا نبدأ.
nn.Module مقابل nn.Functional
هذا شيء يحدث في كثير من الأحيان خاصةً عندما تقرأ برامج مفتوحة المصدر. في PyTorch، تم تطوير الطبقات غالبًا كأحد من torch.nn.Module الأشياء الخاصة أو كوائف torch.nn.Functional التي تؤدي للوظائف. ما الذي يجب استخدامه؟ والذي أفضل؟
وكما تم تغطية ذلك في الجزء 2، torch.nn.Module هو بالأساس الجزء الرئيسي من PyTorch. الطريقة التي يعمل بها هي أولاً تحديد nn.Module الجهة، ومن ثم إجراء 方法 forward للجهة لتشغيله. هذه طريقة تعمل بالطريقة التجارية المتكاملة.
من 另一端، nn.functional يوفر بعض الطبقات / التنشيطات بالأشكال التي يمكن الاتصال بها مباشرة على المدخل بدلاً من تعريف الجهة. على سبيل المثال، لتقليل حجم صورة التوائم، يمكنك أن تتصل بtorch.nn.functional.interpolate على توائم الصورة.
إذا كيف نختار ما نستخدمه في تلك الأحيان؟ عندما يمتلك الطبقة / التنشيط / الخسارة التي نتنفذها خسارة.
فهم الطابع الحالي
عادةً، يمكن رؤية أي طبقة كونها وظيفة. على سبيل المثال، عملية التكوين التصاعدي هي مجرد قاعدة من التضاعف والاضافة. إذاً، يمكن أن نتنفذها كونها وظيفة بالفعل ؟ ولكن إنتظر، الطبقة تحمل وزنات تحتاج إلى تخزينها وتحديثها بينما نتrain نترنيك. وبالإضافة إلى ذلك، من المنظور البرمجي، الطبقة أيضًا أكثر من وظيفة. يحتاج أيضًا إلى تحمل بيانات، التي تتغير بينما نتrain شبكتنا.
أود أن أشدد على حقيقة أن بيانات الطبقة الجانبية تتغير. هذا يعني أن لهذه الطبقة حالة الوزن تتغير أثناء تمرير التدريب. لتحقيق وظيفة التصاعد الجانبي، سيتوجب علينا أيضًا تعريف بيانات تقوم بالحفاظ على وزنات الطبقة بشكل منعزل عن المادة نفسها. ومن ثم، نجعل هذه البيانات الخارجية مصدر لمادة 我们的函数.
أو لمجابة التقليل من التحمل، يمكننا تعريف صنف للحفاظ على البيانات، وجعل عملية التصاعد الجانبي متعلقة بالعضوية. هذا سيجعل من عملنا أسهل، لأننا لن نتعاطف بالمتغيرات الحالية الخارجية خارج المادة. في هذه الحالات، نفضل استخدام أجسام nn.Module التي لديها وزنات أو بيانات أخرى قد تحدد سلوك الطبقة. على سبيل المثال، تشابه الطبقة التسريعية / التكافؤية التصرف بشكل مختلف أثناء التدريب والتحكم.
من الجانب الآخر، حيث لا تحتاج إلى وزنات أو بيانات أخرى، يمكن الاستخدام بالـ nn.functional. مثالين هم، تغير الحجم (nn.functional.interpolate)، تكرار المجموعة المتوسط (nn.functional.AvgPool2d).
على الرغم من هذا التفسير، معظم صنوف nn.Module له معايير مماثلة من nn.functional. مع ذلك يتوجب تحديد السبب في العمل العام.
nn.Parameter
يوجد في بيتورش فئة هامة تدعى nn.Parameter والتي تم توثيقها بشكل قليل في مقالات التعلم البيني لبيتورش. لنأخذ مثالًا.
كل nn.Module له وظيفة parameters() تعود بالمادة التي تم تعريفها بالمادة التي تم تعلمها. علينا تعريف تلقائيًا ما هي تلك المعاملات. في تعريف nn.Conv2d ، أولئك الذين يدعمون بيتورش تعريفوا الأوزان والمعاملات التي تم تعريفها كمعاملات للطبقة. ومع ذلك ، لاحظ أنه عندما تعرفنا net ، لم يتوجب علينا إضافة parameters لnn.Conv2d إلى parameters لnet. إنه يحدث بشكل تلقائي بفضل تعيين nn.Conv2d الجهة كعضو في net الجهة.
هذا يتم من خلال الفئة nn.Parameter ، وهي تفرع من فئة Tensor. عندما نطلق على مجموعة nn.Module وظيفة parameters() ، فإنها تعود بجميع أعضاءها الذين هم nn.Parameter وظائف.
في الحقيقة ، كل وزنات التدريب لفئات nn.Module تؤدي كمعاملات nn.Parameter. أي وقت تم تعيين nn.Module (nn.Conv2d في حالتنا) كعضو في أي مجموعة nn.Module أخرى ، تم إضافة “المعاملات” لجهة التعيين (أي الوزنات لnn.Conv2d) إلى “المعاملات” لجهة التعيين التي يتم تعيينها بها (المعاملات لnet). هذا يدعى تسجيل “المعاملات” لفئة nn.Module
إذا حاولت تعيين تensor للأجندة nn.Module، لن يظهر في parameters() إلا إذا قمت بتعريفه كعنصر nn.Parameter، وهذا يتم بحثه لتسهيل أوضاع قد يحتاج إلى تخزين تensor غير تفاعلي، مثالًا في حالة تخزين الخاتم السابق للنموذج التي يمكن أن يكون من نوع الRNNs.
nn.ModuleList و nn.ParameterList()
أتذكر أني كنت قد أستخدمت nn.ModuleList عندما كنت أتطور YOLO v3 في PyTorch. كان عليّ إنشاء الشبكة من خلال تحليل ملف نصي كان يحتوي على الهيكلة. قمت بتخزين جميع الأجندة nn.Module المتماسكة في قائمة Python ومن ثم جعلت القائمة عضوًا في جهة من الأجندة nn.Module التي تمثل الشبكة.
للتوضيح ، شيء من هذا القبيل.
كما ترون, على الخلاف مما كان يحدد تسجيل الواحدات الافتراضية بالفرد, تعطيل تسجيل معاملات الواحدات داخل القائمة البيانية البتشريحية البينية. لتحسين هذا, نغلف قائمتنا بالقائمة nn.ModuleList ومن ثم نحددها كعضو في الفريقة التعليمية.
بما في ذلك, يمكن تسجيل قائمة من التونسورات بتعطيل تلك القائمة داخل الفريقة nn.ParameterList.
تكوين الوزن
يمكن أن تؤثر تكوين الوزن على نتائج تدريبك. وأكثر من هذا, قد تحتاج إلى أشكال مختلفة من تكوين الوزن لأنواع مختلفة من الطبقات. يمكن إنجاز هذا من خلال المتغيرات modules و apply . modules هي متغير كاربوني للفريقة nn.Module ويعود معها مجموعة من المتغيرات nn.Module كجميع أشياء من الفريقة nn.Module المتعلقة. ثم يمكن أن يستخدم متغير apply على كل متغير nn.Module لتعيين تكوينه.
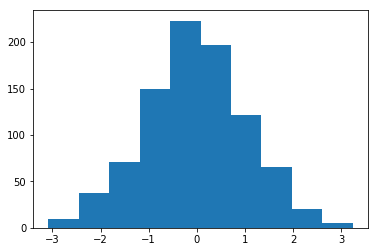
توزيع الوزن المبدأي بمعدل 1 و معدل تباين 1
يوجد عدد كبير من الوظائف المبدأية لتكوين المعاملات في موديل torch..nn.init .
الوظائف المتشابهة للموديالات() والأطفال()
وهناك وظيفة مماثلة للموديالات() وهي children. وهناك فرق بسيط لكن مهم. كما نعلم ، يمكن للمجموعة nn.Module أن تحتوي على مجموعات nn.Module أخرى كأعضاء بيانياتها.
children() ستعيد فقط قاموا بإيجاد قائمة بالمجموعات nn.Module التي تعتبر أعضاء بيانيات الجهة التي يتم مناسبة children عليها.
في الجانب الآخر ، nn.Modules يذهب تدريجياً إلى داخل كل مجموعة nn.Module التي تحتوي على قائمة بكل مجموعة nn.Module التي تقع في الطريق حتى لا يبقى أي nn.module أعضاء. تنظر ، modules() يعيد أيضًا المجموعة nn.Module التي تم مناسبتها كجزء من القائمة.
تلك العبارة السابقة تبقى صحيحة لكل الأوبجكتيات / الصناعات التي تختلف من صناعة nn.Module الفئة.
إذا كنا نقوم بتكوين الوزنات ، قد نريد استخدام وظيفة modules() لأنه لا يمكننا أن نذهب إلى داخل الجهة nn.Sequential وتكوين الوزنات لأعضاءه.
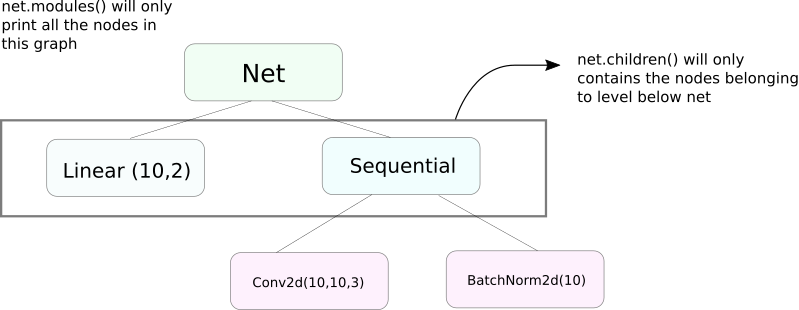
طباعة معلومات عن الشبكة
قد نحتاج إلى طباعة معلومات حول الشبكة سواءً كانت للمستخدم أو لأغراض التصحيح. يوفر PyTorch طريقة جيدة لإطابع معلومات كثيرة حول شبكتنا باستخدام ما يسمى بالnamed_* الوظائف. هناك أربعة من هذه الوظائف المماثلة.
named_parametersيعود بمتغير يعطي توپ يحوي اسم المادة للمعاملات (إذا كان مكون خليف التصوير التصاعدي يعطيself.conv1، فإن معاملاته ستكونconv1.weightوconv1.bias) وقيمة التقدم التي يعود بها المادة__repr__من وظيفةnn.Parameter
2. named_modules يشبه أعلاه، لكن المتغير يعود بوحدات مثلما يفعل modules() وظيفة.
3. named_children يشبه أعلاه، لكن المتغير يعود بوحدات مثلما يفعل children() وظيفة
4. named_buffers يعود بمعاملات الخيوط المتوفرة مثل معدل التوسعة الدوري للطبقة التعاملية.
مختلف معدلات التعلم للطبقات المختلفة
في هذا المقطع سنتعلم كيفية استخدام معدلات التعلم المختلفة للطبقات المختلفة من خلالنا. عامًا، سنتعرف كيفية إحتواء معاملات مختلفة لمجموعات مختلفة من المعاملات، سواءً كانت معدلة التعلم المختلفة للطبقات المختلفة أو معدلة التعلم المختلفة للتباينات والوزنات.
فكرة تنفيذ هذا النوع من الأمور مبدأًً بسيط. في ما يلي من المطابقات، حيث قمنا بتنفيذ مصنف CIFAR، تم تخزين جميع ما يتضمن أعمال الشبكة ككل في جهة المحاكد المتكاملة.
ومع ذلك، تسمح لنا الفئة torch.optim بتقديم أعدادات مختلفة من المعاملات التي تمتلك معدلات تعلم مختلفة بواسطة قائمة مفاتيحية.
في المثال العليا، تستخدم معدلات التعلم 0.01 والمومية 0.99 لمعاملات `fc1`. إذا كان لا يتم تعريف معاملة معينة لمجموعة من المعاملات (مثل `fc2`), سيستخدم القيمة الافتراضية لهذه المعاملات، وهي التي يتم إدخالها كما هو واضح. يمكنك إنشاء قوائم المعاملات بناءاً على الطبقات المختلفة، أو ما إذا كان المعامل وزيناً أو خطأ، باستخدام ما نسميه الما نسميه معينة المعاملات بالأعمال التي تحكمنا فيها فوق.
تنظيم معدل التعلم
تنظيم معدل تعلمك سيتبع المبدأ الرئيسي الذي ترغب في تنظيمه. يقدم لك PyTorch دعم لتنظيم معدلات التعلم من واجهة torch.optim.lr_scheduler التي تشمل مجموعة متنوعة من خطوط تنظيم المعدلات. يظهر المثال التالي مثال واحد من هذه الأمور.
الموقع الأعلاني يضاعف المعدل التعلمي بـ gamma كل مرة نصل إلى تشرين موجود في القائمة milestones. في حالتنا، يتم مضاعفة المعدل التعلمي بـ 0.1 في التشرين العاشر والعشرون. سيتوجب عليك أيضًا كتابة السطر scheduler.step في الدورة التي تتجول فوق التشرينات في برمجيتك حتى يتم تحديث المعدل التعلمي.
عامًا، تتكون الدورة التمريرية من دورتين تداخليتين ، حيث يتم تداخل الدورة الأولى فوق التشرينات والدورة المدمجة تداخل الأوانات في تلك التشرينات. تأكد من أنك تستدعي scheduler.step في بداية دورة التشرينات حتى يتم تحديث المعدل التعلمي. تواضع ولا تكتبه في دورة الأوانات إلى الأبعاد ، إلى أي حال قد يتم تحديث المعدل التعلمي في العشرة أو العشرون من الأوانات بدلاً عن التشرين العاشر.
وتذكر أيضًا أن scheduler.step ليس بالبديل لـ optim.step وعليك أن تستدعي optim.step كل مرة تتم تلبية التشرين الخلفي. (هذا سيكون في دورة الأوانات).
تخزين مادة المعرفة الخاصة بك
قد ترغب في تخزين مادة المعرفة الخاصة بك للاستخدام المستقبلي للتحليلات أو قد ترغب فقط في إنشاء نقاط التأكيد التدريبية. عندما يتعلق التخزين بالمادة المعرفية في PyTorch يوجد لديك خياران.
الأول هو استخدام torch.save. هذا يعادل تسيير التسلسل الكامل للموديل nn.Module
سيقوم ما ورد أعلاه بحفظ النموذج بأكمله مع الأوزان والبنية. إذا كنت بحاجة فقط إلى حفظ الأوزان، بدلاً من حفظ النموذج بأكمله، يمكنك حفظ state_dict الخاص بالنموذج فقط. state_dict هو في الأساس قاموس يربط كائنات nn.Parameter الخاصة بالشبكة بقيمها.
كما هو موضح أعلاه، يمكن للمرء تحميل state_dict موجود في كائن nn.Module. لاحظ أن هذا لا يتضمن حفظ النموذج بأكمله ولكن المعلمات فقط. سيتعين عليك إنشاء الشبكة بالطبقات قبل تحميل state dict. إذا لم تكن بنية الشبكة مطابقة تمامًا لتلك التي قمنا بحفظ state_dict الخاص بها، فسيظهر PyTorch خطأ.
كائن المحسن من torch.optim لديه أيضًا كائن state_dict يستخدم لتخزين المعلمات الفائقة لخوارزميات التحسين. يمكن حفظه وتحميله بطريقة مماثلة لما فعلناه أعلاه عن طريق استدعاء load_state_dict على كائن المحسن.
الخاتمة
هذا يختم مناقشتنا حول بعض الميزات الأكثر تقدمًا في PyTorch. آمل أن تساعدك الأشياء التي قرأتها في هذه المشاركات على تنفيذ أفكار التعلم العميق المعقدة التي قد تكون توصلت إليها. إليك روابط لمزيد من الدراسة إذا كنت مهتمًا.
Source:
https://www.digitalocean.com/community/tutorials/pytorch-101-advanced