













يبدأ العلماء الرائدون في البيانات بتعلم الSQL مبكرًا. وهذا مفهوم، بما أن معلومات الجدول واسعة التواجد والفائدة الكبيرة منها. ومع ذلك، توجد أساليب قاعدات البيانات الأخرى الناجحة، مثل قاعدات البيانات التعلقية، لتخزين البيانات المترابطة التي لا تتوافق مع قاعدة البيانات الاشباعية الرابطة بSQL. في هذه الدرس التورية، سنتعلم عن Neo4j، نظام إدارة قاعدة البيانات التعلقية المعروف والذي يمكنك استخدامه لخلق، إدارة، وإعادة استعمال قواعد البيانات التعلقية في Python.
ما هي قواعد البيانات التعلقية؟
قبل الحديث عن Neo4j، دعونا نقضي دقيقة لفهم البيانات التعلقية بشكل أفضل. لدينا مقال كامل يexplains ما هي قواعد البيانات التعلقية، لذا سنختار أهم الأحداث هنا.
تعني أن البيانات الشبكية هي نوع من البيانات اللا SQL (لا تستخدم SQL) تهدف إلى إدارة البيانات المترابطة. بخلاف البيانات الرياضية التقليدية التي تستخدم الجداول والأسطر، تستخدم البيانات الشبكية هيكلات الشبكة التي تتكون من:
- النقاط (الأكوان) مثل البشر، الأماكن، المفاهيم
- الحواجز (العلاقات) التي تربط أنواع مختلفة من النقاط مثل شخص يعيش في مكان, أو لاعب كرة القدم أسباب في مبارة.
- الخصائص (خصائص للعناصر/الخطوط)مثل عمر شخص ما أو متى تم ما إذا أدى المرء في المباراة الهدف.
هذا الهيكل التي جعلت القاعدات التوجيهية مناسبة لمعالجة البيانات المترابطة في مجالات وتطبيقات مثل الشبكات الاجتماعية، التوصيات، كشف الخدع، وهكذا، وغالبًا تتسبب في أفضل أداء من القاعدات ال relational فيما يتعلق بكفاءة البحث. هذا هو الهيكل لقاعدة بيانات مثالية لمجموعة بيانات لعبة القدم:
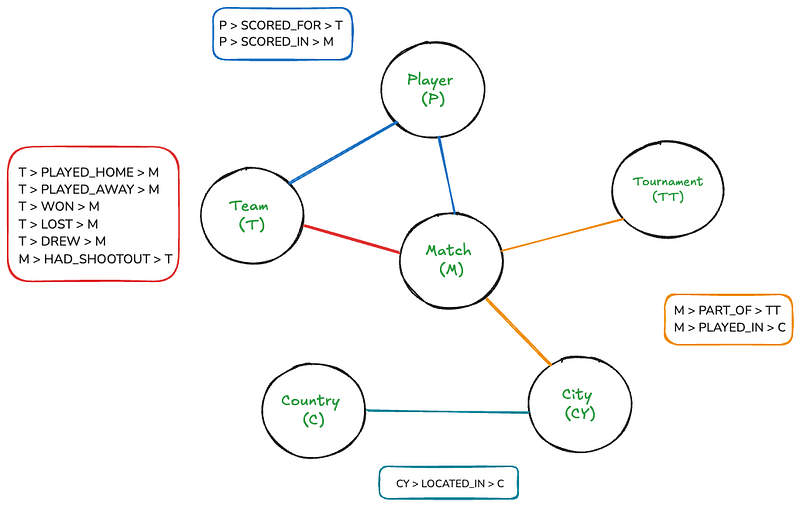
بالرغم من أن هذا الرسم البياني يمكن أن يبدو بسيطًا للبشر، لكنه يمكن أن يصبح معقدًا للغاية إذا رسم في القماش. ومع Neo4j، سيكون تنقل هذا الرسم البياني بسهولة تقريبًا مثل كتابة الجمل البسيطةمقاربات SQL.
يوجد ست نقاط في الرسم البياني: مطابقة، فريق، تورنمنت، لاعب، دولة، ومدينة. يوجد مجموعة من المراتب التي تودع العلاقات بين النقاط. وهناك أيضًا بعض خصائص النقاط والعلاقات:
- الموافقة: تاريخ، نقطة_المنزل، نقطة_الخارج
- الفريق: اسم
- اللاعب: اسم
- المسابقة: اسم
- المدينة: اسم
- الدولة: اسم
- تحقق النقاط، تحقق النقاط داخل: دقيقة، الغول، التعدية
- حاول المعركة: الرابح، شخص الاطلاق الأول
هذا النموذج يسمح لنا بممارسة:
- جميع المباريات بجميع نقاطها وتاريخها ومواقعها
- المجموعات التي تشارك في كل مبارية (الداخلية والخارجية)
- اللاعبين الذين يحتفظون بالجولات بشكل جميز، بما في تفاصيل مثل الدقيقة، الأهداف الخاصة والأخرى
- التورنمات التي يختلف منها بعض المباريات
- المدن والدول التي يجري بها المباريات
- معلومات المعركة، بما في ذلك الأنتاجية وأولئك الذين يمكن أن يكونوا قاتلين المعركة (عندما يكون متاحاً)
يتم تغليف النموذج بشكل تسلسلي للأماكن (مدينة داخل البلد) والعلاقات المتنوعة بين الأشياء (على سبيل المثال، فريقان يلعبون مسابقات، لاعبون يحققون نقاط لفرقهم في المسابقات).
هذا البنية تسمح بالبحث المرن، مثل إيجاد جميع المباريات بين فريقين من عدد ما، جميع النقاط التي يحققها لاعب ما، أو جميع المسابقات في منافسة معينة أو مكان معين.
ولكن لا نتجاوز أنفسنا. لنبدأ بما هو نيو4جو ولماذا نستخدمه؟
ما هو نيو4جو؟
نيو4جو، الاسم الرئيسي في عالم إدارة البيانات التصادرية، يشهد على خصائصه القوية والتنوع.
في جوهرها، يستخدم Neo4j تخزين الجرافات الأصليّ، الذي يُحسّن بشكل كبير للتنفيذ العمليات الجرافية. كفاية فعاليته في التعامل مع العلاقات المعقدة تجعله يتميز على الأسلاك القديمة لقواعد البيانات المتصلة. قابلية Neo4j للتوسعة مدهشة حقاً: يستطيع التعامل مع بلايين العقد والعلاقات بكل سهولة، مما يجعله مناسباً للمشاريع الصغيرة والشركات الكبيرة.
وجهة نظر أخرى هامة لNeo4j هي الصلة البيانات. يؤكد على الموافقة الكاملة مع ACID (الأتومية، الإتمام، الإقلال، الديمومة)، مما يوفر الاعتمادية والتزامن في المعاملات.
بالحديث عن المعاملات، يقدم لغة الاستعلام، سايفر، سيntax رائع وتعريفي تصمم لأنماط الجرافات. لهذا السبب، تم تسميت سيntaxه بالقيمة “ASCII art”. سيفر سيستطيع تعلمه بسهولة، خاصة إذا كنت تألف بSQL.
بواسطة كيبر، من السهل جدًا إضافة أقطاب جديدة أو علاقات أو خصائص دون قلق بشأن تعطيل أساليب قد يوجد بالفعل أو ال架构. إنه قابل للتأقلم مع تغيرات التطور السريعة للبيئات التطويرية الحديثة.
يمتلك Neo4j دعم بيئة حيوية واسع. وتوفر وثيقات واسعة وأدوات شاملة لتصور الشبكات ومجموعة من المجتمع نشطة وتندمج مع لغات البرمجيات الأخرى مثل Python و Java و JavaScript.
إعداد Neo4j وبيئة Python
قبل أن نغوص في العمل مع Neo4j، يتوجب علينا إعداد بيئتنا. سيقودكم هذا المقطع خلال إنشاء نسخة سحابية لتوفر قاعدات Neo4j، وإعداد بيئة Python، وإنشاء اتصال بين الاثنين.
عدم تثبيت Neo4j.
إذا كنت ترغب في العمل مع قواعد البيانات المحلية في Neo4j، فسيكون عليك تحميلها وتثبيتها محلياً، بالإضافة إلى أدواتها المتعلقة مثل Java. ولكن في معظم الحالات، سوف تتفاعل مع قواعد البيانات Neo4j البعيدة الموجودة في بيئة سحابة معينة.
ولهذا السبب لن نinstalar Neo4j على نظامنا. بدلاً من ذلك، سننشر مثالية عنصر قاعدة البيانات الحرة على Aura، خدمة السحابة المباشرة تمامًا المديرة لNeo4j. من ثم، سنستخدم الneo4j مكتبة البرمجيات البيانية الخاصة بPython للاتصال بهذه القاعدة البياناتية وتعبئتها بالبيانات.
إنشاء مثالية قاعدة البيانات Neo4j Aura
لإضافة قاعدة بيانات الرسم البياني المجانية على Aura DB، قم بزيارة صفحة المنتج وانقر على “ابدأ مجاناً”.
بمجرد التسجيل، ستظهر لك الخطط المتاحة، ويجب عليك الاختيار للخيار المجاني. وبعد ذلك ستعطى مثيل جديد بإسم مستخدم وكلمة مرور للاتصال به:
انسخ كلمة المرور، إسم المستخدم، وURI الاتصال.
ثم، قم بإنشاء مجلد عمل جديد وملف .env لتخزين معلوماتك:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
قم ب粘贴محتويات الملف التالية داخل الملف:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
إعداد بينماويك للبيئة
الآن، سن Instance the neo4j مكتبة ال client للبيانات البينماوية في بيئة جديدة Conda:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # لإضافة البيئة إلى Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
يتم أيضًا تثبيت ipykernel وإستخدامه لإضافة بيئة Conda جديدة إلى Jupyter كنيرال. ثم نثبيت neo4j للتواصل مع قاعدات Neo4j وpython-dotenv لإدارة معلومات بيانات التسجيل الخاصة بنا بشكل آمن.
تعمير نسخة من AuraDB ببيانات الفوتبول.
إتلاف البيانات إلى قاعدة بيانات الرسم البياني هو عملية معقدة تتطلب معرفة مبادئ Cypher الأساسية. لأننا لم نتعلم بعد عن مبادئ Cypher الأساسية، ستستخدم نصوص برمجية Python قمت بتحضيرها للمقالة التي ستقوم بتلقيح البيانات الحقيقية عن تاريخ الكرة تلقائياً. سيستخدم النص البرمجي البيانات الشخصية التي حفظتها للاتصال بمثيل AuraDB الخاص بك.
يأتي البيانات المتعلقة بالكرة الأرضية من هذه المجموعة الخاصة على Kaggle حول المبارات الدولية لكرة الأرضية التي تم مباراةها بين عام 1872 و2024. البيانات متاحة بالتشكيل الCSV، لذا يقوم الscript بتجزأتها وتحويلها إلى تشكيل الشبكة باستخدام Cypher وNeo4j. في نهاية المقالة، عندما نكون مرتاحين بما فيه الكفاية مع هذه التكنولوجيات، سنسرد على الscript خطوة بخطوة حتى يمكنك معرفة كيفية تحويل المعلومات الجداولية إلى شبكية.
وهنا توجد الأوامر التي يتم بعثها (يتوجب أن تأكد من إنشاء نسخة من AuraDB وتخزين بياناتك في ملف .env في مجلدك العملي).
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
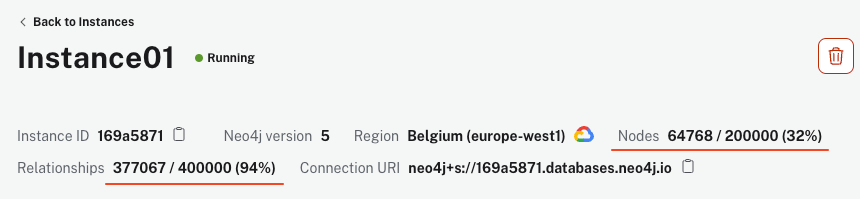
قد يستغرق ال脚本 بعض الدقائق للتنفيذ، وهذا يعتمد على آلة الكمبيوتر الخاصة بك واتصالك بالإنترنت. ومع ذلك، بمجرد انتهاء العملية، يتوجب على نسخة AuraDB الخاصة بك أن تظهر أكثر من 64k عقد و 340k علاقة.
الاتصال بNeo4j من Python
الآن، نحن جاهزون للاتصال بinstance Aura DB الخاص بنا. أولاً، سنقرأ بياناتنا الشخصية من ملف .env باستخدام dotenv:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
الآن، دعونا نوسع اتصال:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
الخريطة:
Connection successful!
هذه تفسير للشيء المكتوب:
- نحن نقدم
GraphDatabaseمنneo4jللتفاعل مع Neo4j. - نستخدم ما تم تحميله من المتغيرات البيئية السابقة لإعداد اتصالنا (
uri,username,password). - نحن نخلق مجسم المستخدم باستخدام
GraphDatabase.driver(), مع إنشاء اتصال بقاعدة البيانات Neo4j الخاصة بنا. - تحت
withشريط، نستخدم ما بعد الverify_connectivity()ما إذا كان هناك اتصال. بشكل متأخر،verify_connectivity()لا يعود بأي شيء إذا كان الاتصال ناجحاً.
بمجرد انتهاء التعليمات، اسمع driver.close()لإنهاء الاتصال وتخليل موارد. وهذه الأيات التي تم إنشاؤها تكلف مواردا كثيرة، لذا يجب عليك إنشاء قطعة واحدة فقط لتطبيقك.
جوانب أساسية لللغة السؤالية Cypher
تم تصميم نمط السؤالية Cypher ليكون واجه وبديهي ويمثل بشكل بصري بنيات المعلومات الجغرافية. وهي تعتمد على النمط التالي للرسوم البيانية التي تشبه الرسوم البيانية الASCII:
(nodes)-[:CONNECT_TO]->(other_nodes)
دعونا نفك العناصر الرئيسية من هذا النمط العام للسؤال:
1. نقاط.
في طرح كايبر، تشير كلمة رئيسية في أقواس إلى اسم نقطة. على سبيل المثال، (لاعب) تتطابق مع جميع الأنواع النقطية التي تدعى “لاعب”. في الغالبية من الأحيان، يتم إستعمال الاسماء المستعارة للنقاط لجعل الأسئلة أكثر قابلية للقراءة، وأسهل للكتابة، وأكثر تركيبية. يمكنك إضافة مسمى مستعار لأسم نقطة بوضع نقطة علامة في أقلامها: (m:مطار).
وفي الأقواس، يمكنك تحديد خاصية واحدة أو أكثر من النقاط باستخدام نمط شبيه بالقواميس للتطابق بالدقة. على سبيل المثال:
// جميع النقاط التي تدعى "تورنمنت فيدرال" وهي الكأس العالمي للفيفا العالمية (t:Tournament {name: "FIFA World Cup"})
تم كتابة خصائص النقاط كما هي، بينما يتوجب أن يكون قيمة التي تريد أن تملكها نص من النوى.
2. العلاقات
تربط العلاقات النقاط بعضها بعضًا، وتم تغليفها بأقاصير وأوسامات:
// تطابق النقاط التي تكون جزءًا من بعض التورنمات (m:Match)-[PART_OF]->(t:Tournament)
يمكنك أيضًا إضافة اسماء مستعارة وخصائص للعلاقات:
// تطابق أن برازيل شاركت في مصاريف تعاقب وكانت الشارك الأول (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
تلك العلاقات مغلفة بالأسهم-[RELATIONSHIP]->. مرة أخرى، يمكنك أن تضم خصائص أسماء مختلفة داخل الأقواس. على سبيل المثال:
// جميع اللاعبين الذين أخذوا أعطال شهداء (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. الأشعار.
وكماCOUNT(*) FROM table_name لن يعطي أي نتيجة بدونSELECT شرط في الSQL،(node) - [RELATIONSHIP] -> (node) لن يجلب أي نتائج. إذا ، كما في الSQL، يوجد في Cypher جميع الشروط المختلفة لتشكيل منطقة التحقق مثل الSQL:
تطابق: تطابق النمط في الرسم البيانيحيث: تصفية النتائجإرجاع: تحديد ما يتم تضمينه في مجموعة النتائجإنشاء: إنشاء عناصر جديدة أو علاقاتMERGE: إنشاء نقاط فريدة أو علاقاتDELETE: إزالة نقاط أو علاقات أو خصائصSET: تحديث تصنيفات وخصائص
هذه عينة من البحث التي تبرر هذه المفاهيم:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
y>
هذا الاستعلام يجد جميع اللاعبين الذين أنتجوا أهدافا خاصة في مباريات الكأس العالمي بعد الدقيقة ال80. يبدو تقريبا كما SQL، ولكن المكافئ له في SQL يتضمن على الأقل عملية JOIN واحدة.
استخدام جهاز Neo4j Python Driver لتحليل قاعدة البيانات الرسمية
تشغيل الاستعلامات مع execute_query
جهاز Neo4j Python هو المكتبة الرسمية التي تتفاعل مع مثيل Neo4j عن طريق تطبيقات Python. يتحقق ويتواصل بالاستعلامات Cypher المكتوبة في نصوص Python البسيطة مع خادم Neo4j ويرجع النتائج في تنسيق موحد.
يبدأ كل شيء بإنشاء جهة ما بواسطة الGraphDatabase ومن ثم يمكننا بدء الإرسال للأسئلة باستخدام الexecute_query والتي يمكننا بها إجراء الأسئلة
لأول سؤال سوف نسأل سؤالًا مثيرًا للاهتمام: ماذا هو ما أكثر فريقًا ربما للمبارات العالمية؟
# ترجي إلى الفريق الذي ربح العديد من مبارات العالمية query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
أولاً دعونا نفك السؤال:
- يعرف ال
الموافقةالبناء القريب يحدد النمط الذي نريده: فريق -> انتصار -> مباراة -> جزء من -> مسابقة RETURNهو مماثل للأعمال المسموعة في SQL لـSELECTالاعمال، حيث يمكننا إرجاع خصائص العقارات المرجعة والعلاقات. في هذا الجملة، يمكنك أيضًا استخدام أي وظيفة تجميع مدعومة في Cypher. في الأعلى، نستخدمCOUNT.ORDER BYتعمل بنفس الطريقة كما يفعل القولORDER BYفي SQL.LIMITيستخدم لمسيطرة على طول السجلات التي تعود.
بعد أن نحدد التعاقد كسلسلة متعددة ال行, نقوم بتقديمها إلى execute_query() مéthod من مجموعة القادرين ونحدد اسم القاعدة التعليمية (الإفتراضي هو neo4j). سيحوي الناتج دائمًا ثلاثة أشياء:
records: قائمة بأشياء التسجيل التي تمثل كل سطر في مجموعة الناتج. كل تسجيل هو جهة تشكيل تعامل مع أسماء أو تسلسل، حيث يمكنك الوصول إلى الحقول بالإسم أو بالتسلسل.توافير: جهة توافير تحويل البيانات إلى تقارير مفهومة باللغة العربية.أسماء الأعمدات: قائمة من الأحرف التي تمثل أسماء الأعمدات في المجموعة الناتجة.
سنتلخيص المجموعة ما بعد ذلك لأننا مهتمون فقط بالسجلات, التي تحتوي علىالعناصر من النوعRecord. يمكننا استعادة معلوماتها بمهام الdata() لها:
for record in records: print(record.data())
الخريطة:
{'Team': 'Brazil', 'MatchesWon': 76}
توثيق النتيجة الصحيحة لأن برازيل ربحت العديد من مبارايات الكومبيوتر العالمية.
تحميل معاملات التساؤل التقاريرية
أخر تساؤلنا غير قابل للإستخدام مرة أخرى ، لأنه يجد الفريق الأكثر نجاحا في تاريخ الكومبيوتر العالمي. ماذا لو أردنا إيجاد أكثر فريق نجاحا في تاريخ الإروپا؟
هنا يأتي دور معاملات التساؤل التقاريرية:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
في هذه الإصدارة من التساؤل، نقدم ما يلي ما يمكن أن نستخدمه من المادة من خلال إستخدام علامة ال$:
tournamentlimit
لتحميل قيم لما يلي ما يمكن أن نستخدمه من المادة للمتغيرات التساؤلية، نستخدم ما يلي ما يمكن أن نستخدمه من المادة من خلال إستخدام ما يلي ما يمكن أن نستخدمه من المادة من خلال إستخدام علامة الexecute_query:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
الخريطة:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
يوجد دائمًا توصية باستخدام المادة المتغيرة في المتغيرات التي تفكر في تفريغها في معاملتك البحثية. هذه الممارسة الأفضل تحمي معاملاتك من التهديد المتبادل وتسمح ل Neo4j بالتخزين لها.
كتابة البيانات باستخدام الفرعونات CREATE و MERGE.
يمكن كتابة معلومات جديدة إلى قاعدة بيانات موجودة بشكل مماثل من خلال execute_query ولكن باستخدام عقدة CREATE في التعبير. على سبيل المثال، دعونا نخلق وظيفة ستأخذ خمس ما بعيدات:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
تلك الوظيفة add_new_coach تتطلب خمس ما بعيدات:
- القادر: ما يمكن أستخدامه لتواصل مع القاعدة.
coach_name: إسم المدرب الجديد الذي سيضيف.team_name: إسم الفريق الذي سيتم ربط المدرب به.start_date: تاريخ بدء خدمة المدرب للفريق.end_date: تاريخ إنتهاء مدة خدمة المدرب مع الفريق.
تشغيل المعادلة Cypher في الوظيفة يحدد التالي:
- يتطابق بالفريق الموجود مع اسم الفريق المعطا.
- ينشئ عقد جديد مع اسم المدرب المقدم.
- يخلق علاقة COACHES بين العميل المدرب والنقطة الفريدة للفريق.
- يضبط
start_dateوend_dateللخصائص في العلاقةCOACHES.
تُنفذ الاستعلام باستخدام الطريقة execute_query التي تأخذ سلسلة الاستعلام وقومة المعلمات.
بعد الإنجاز، يطبع الوظيفة:
- رسالة تأكيد بأسماء المدرب والفريق وتاريخ البدء.
- عدد العقدة المُنشأة (يجب أن يكون 1 للعقدة الجديدة للمدرب).
- عدد العلاقات المُنشأة (يجب أن يكون 1 للعلاقة الجديدة
COACHES).
لنقم بتنفيذ ذلك لأحد أكثر المدربين نجاحًا في تاريخ الكرة الدولية، ليونيل سكالوني، الذي فاز بثلاثة بطولات دولية متتالية (كأس العالم وكأس أمريكاين):
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
في الفقرة السابقة، نحن نستخدم فئة DateTime من neo4j.time الوحدة لتمرير تاريخ صحيحاً إلى استعلام Cypher الخاص بنا. ال وحدة تحتوي على أنواع البيانات الزمنية الأخرى المفيدة التي قد ترغب في التحقق منها.
بعيداً عنCREATE, وهناك أيضًا الMERGE التي لإنشاء عقد جديد و علاقة جديدة. فارقهما الرئيسي هو:
CREATEدائمًا يؤدي إلى إنشاء عقد جديد أو علاقة جديدة ممكنًا تولي تكرارات.MERGEتؤدي فقط إلى إنشاء نقاط/علاقات إذا لم يكن موجودتاهم بالفعل.
على سبيل المثال، في 脚本 التسجيل البياناتي الخاص بنا، كما سترون لاحقاً:
- لقد استخدمنا
MERGEلمجموعات ولللعبيين لتجنب التكرارات. - لقد استخدمنا
CREATEللعلاقاتSCORED_FORوSCORED_INلأن يمكن لللاعب أن يكون مرتدياً معدلاً عالٍ في محادثة واحدة فقط. - هذه ليست تكرارات حقيقية لأنها تمتلك خصائص مختلفة (على سبيل المثال، دقيقة الغاية).
هذه المقاربة تضمن التكامل الدائم للبيانات بينما تسمح للعديد من العلاقات المماثلة ولكن مختلفة.
تنفيذ معاملاتك الخاصة
حين تقوم بتنفيذexecute_query, يؤدي الماكينة معاملةالمعاملات تحت القمامة. يعني أن المعاملة هي وحدة العمل التي يتم تنفيذها بالكامل أو تم رد الفشل علىها. هذا يعني أنه عندما تقوم بإنشاء الآلاف من النقاط أو العلاقات في معاملة واحدة فقط (وهو ممكن) ويواجه خطأ في المنتصف، فينفيذ المعاملة بالفشل دون كتابة أي بيانات جديدة إلى الخريطة.
للحصول على تحكم أدق في كل معاملة، تحتاج إلى إنشاء كائنات الجلسة. على سبيل المثال، دعونا نصنع وظيفة لإيجاد أعلى K أنجازات الغلة في بطولة محددة باستخدام كائن جلسة:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
أولا، نقوم بإنشاء top_goal_scorers التي تتقبل ثلاثة معايرات، والأهم منها هو الكائن tx للمعاملة الذي سيحصل عليه باستخدام كائن جلسة.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
الناتج:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
ثم، تحت مدير السياق الذي تم إنشاؤه بواسطة session()، نستخدم execute_read()، مع الإشارة إلى top_goal_scorers()، وبالإضافة إلى أي الараметرات تحتاجها الاستعلام.
الخروجexecute_readهو قائمة بالأوبجكسر التي تظهر بشكل صحيح أفضل 5 مُجموعي الأولويات في التاريخ العالمي للكرة القدمية بما فيها أسماء مثل
المماثل لexecute_read()للتخزين البياناتي هوexecute_write().
ومع هذا القول، دعونا ننظر الآن إلى 脚本 التنصيب الذي استخدمناه مؤخرًا للإحساس بكيفية تنصيب البيانات مع 驱动程序 Neo4j Python.
تنصيب البيانات باستخدام 驱动程序 Neo4j Python
ال ingest_football_data.py ملف يبدأ بعدد من الأعطال التي تحمل تحميل الملفات CSV الضرورية:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging # مسارات ملفات CSV results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" # إعداد المسجل التجاري logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") # تحميل البيانات results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
هذا القطع البرمجي يقوم أيضًا بإنشاء مسجل. الأخر أشياء من البرمجيات تقرأ معلومات المرور الخاصة بي ل Neo4j باستخدام dotenv وتوليد عنصر مجالي:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
ولأن هناك أكثر من 48,000 تطابقاً في قاعدتنا البيانات، فنحن نتعرف على ما تمثله BATCH_SIZE ما يتم به تسليم البيانات بعدد صغير جدًا.
ومن ثم نعرف وظيفة تسمىcreate_indexes والتي تقبل جهة تعامل جهة:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
المصادر الشاملة هي هياكل قاعدة البيانات التي تحسن أداء التحقيقات في Neo4j. إنها تسرع عملية إيجاد النقاط أو العلاقات بسبب خصائص specific. نحتاجها ل:
- تنفيذ التحقيقات الأسرع
- الأداء الأفضل في القراءة لأعدادات كبيرة
- التطابق الفعال والكفيف
- تأكيد القيود الفريدة
- القابلية للتنمية أفضل وأقوى وفيما يزال البيانوست ينمو
في حالتنا، سيساعد مؤشرات الفرق، معرفي المباراة، وأسماء اللاعبين على تسريع أساليبنا للبحث عن الأكوان المحددة أو القيام بالترابط عبر أنواع مختلفة من العقد. وهي ممارسة أفضل لإنشاء مثل هذه المؤشرات في بases البيانات الخاصة بك.
ومن ثم، نحن نملك الingest_matches الوظيفة. إنه كبير، لذا دعونا نفكر فيها من قِمة إلى قمة:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
ستلاحظ أولًا الكلمة المفردة التفريغ، وهي تستخدم لمعالجة مجموعة من البيانات. إنها تأخذ $batch المادة (والتي ستكون أسطرات قاعدة البيانات الخاصة بنا) وتتجه إلى كل سطر، مما يسمح لنا بإنشاء أو تحديث عدد من العقارات والعلاقات في تجارة واحدة. هذه المقاربة أكثر فعالية من معالجة كل سطر بمفرده ، خاصة لأعدادات كبيرة.
يبدو بالنسبة لبقية الاستعلام أكثر أعجابًا لأنه يستخدم عدة MERGE البندان. ومن ثم نصل إلى WITH البند ، الذي يستخدم FOREACH بناءات مع IN CASE الإعلانات. يستخدمون هذه لإنشاء علاقات بشكل 条件ي وفقًا للنتائج المطابقة. إذا كان الفريق المنزلي يربح، فإنه يخلق علاقة ‘WON’ للفريق المنزلي وعلاقة ‘LOST’ للفريق الأخر، والعكس بالمقدار. في حالة تواصل، يحصل كلا الفرق على علاقة ‘DREW’ مع المباراة.
يتم توزيع الDataFrame المصادر بين الماتشات وبناء البيانات التي ستتم تقديمها ل$batch ماركاتر السؤال:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals و ingest_shootouts تستخدم بنيات مماثلة. مع ذلك ، لدى ingest_goals خدمات إضافية لمعالجة الأخطاء و القيم المفقودة.
في نهاية ال脚本 ، لدينا الmain() 函数 التي تنفذ جميع 函数 الاستيراد مع جهة المراسلة:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
خلاصة والخطوات القادمة
لقد شاهدنا جوانب رئيسية من العمل مع قاعدات الشبكة Neo4j باستخدام Python:
- مفاهيم قاعدات الشبكات التربية والبنية
- إعداد Neo4j AuraDB
- أساسيات لغة الاستعمال Cypher
- استخدام مشغل نيو4ج برمجة بايثون
- استيراد البيانات وتحسين الاستعلام
لمتابعة رحلتك بنيو4ج، اكتشف الموارد التالية:
- وثائق نيو4ج
- مكتبة نيو4ج لعلم البيانات الرئيسية
- معلومات مارشال نيو4ج
- وثيقة مساعدة دافع Neo4j للبرمجيات الباسلية
- شهادة مهنية للهندسة البيانية الخاصة بالبيانات
- تقديم للبيانات اللاشيخوخية (NoSQL)
- درس شامل للبيانات اللاستوديوية (NoSQL) باستخدام مونجوDB
تذكر، قوة قاعدات الجوانب تكمن في تمثيل والبحث في علاقات معقدة. واستمر في التجربة مع أنماط البيانات المختلفة واستكشاف ميزات متقدمة لـ Cypher.