













高效的数据處理對於依賴大數據分析來做出明智決策的企業和組織至關重要。一個關鍵因素,對數據處理的性能有著显著影響的是數據的存儲格式。本文探討了在不同存儲格式,具體來說是Parquet、Avro和ORC對Google Cloud Platform (GCP)上大數據環境中查詢性能和成本的影響。本文提供了一起績效指標,討論了成本含义,並根據特定使用場景提供選擇適當格式的建議。
大數據存儲格式简介
數據存儲格式是任何大數據處理環境的脊梁。它們確定數據如何存儲、讀取和寫入,直接影響存儲效率、查詢性能和數據搜救速度。在大型數據生態系統中,如Parquet和ORC的列式格式以及如Avro的行式格式,因其針對特定類型的查詢和處理任務優化性能而被廣泛使用。
- Parquet: Parquet是一種優化於讀取操作和分析的列式存儲格式。在壓縮和編碼方面非常高效,使其成為在读取性能和存儲效率為優先考慮的场景下理想的選擇。
- Avro: Avro是一種行式存儲格式,設計用於數據序列化。它以其模式演變功能而聞名,常用於寫入操作較多的場景,其中數據需要快速序列化和反序列化。
- ORC(優化列式):ORC是一種列式存儲格式,類似於Parquet,但優化於讀寫操作。ORC在壓縮效率方面表現极高,有助於節約存儲成本及加快數據擷取。
研究目標
本研究的主要目標是評估不同的存儲格式(Parquet、Avro、ORC)在大數據環境中对查詢性能和成本的影響。本文旨在提供根據各種查詢類型和數據量度制定的 benchmark,以幫助數據工程師和架構師為其特定的使用案例選擇最合適的格式。
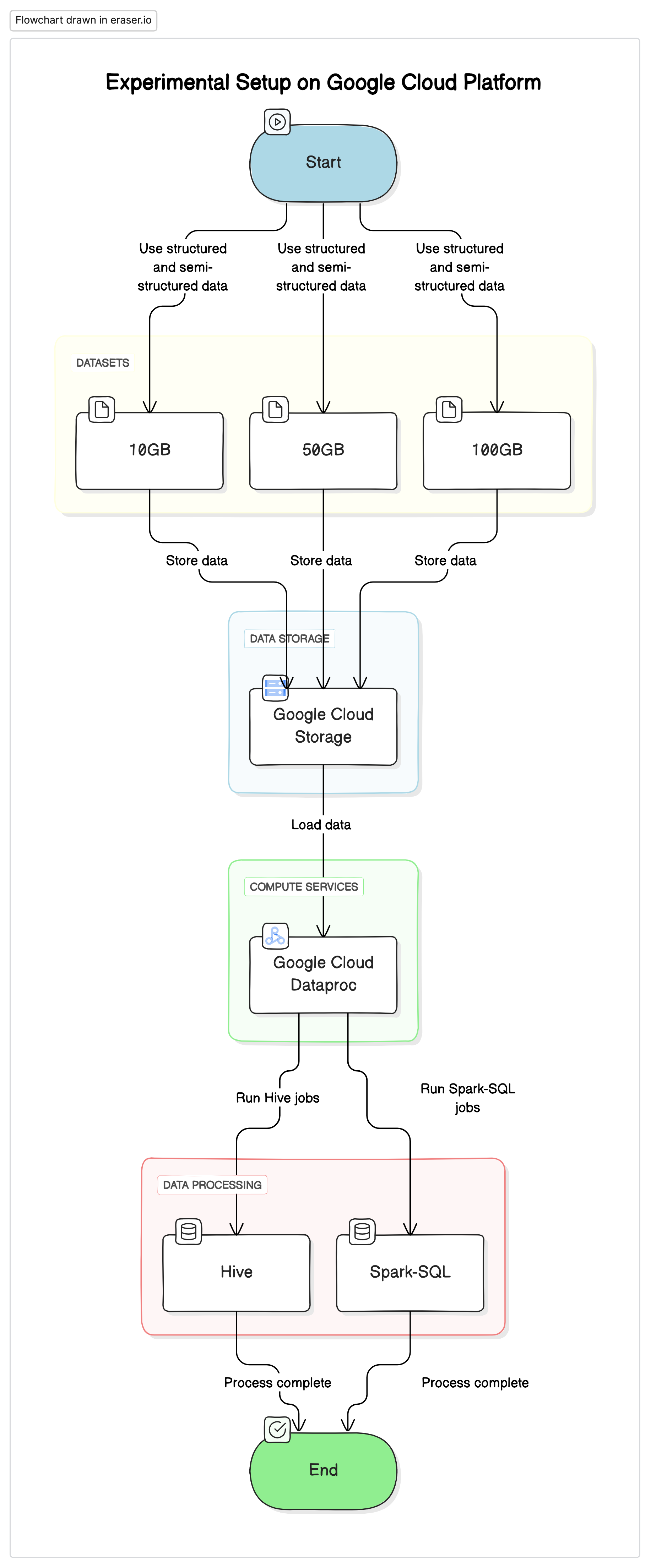
實驗環境
為了進行本研究,我們在Google Cloud Platform (GCP)上使用標準化環境,以Google Cloud Storage作為數據庫,並使用Google Cloud Dataproc執行Hive和Spark-SQL作业。实验中使用的數據是結構化與半結構化數據集的混合,以模擬现实世界的场景。
关键组件
- Google Cloud Storage:用於存儲不同格式(Parquet、Avro、ORC)的數據集
- Google Cloud Dataproc:一套管理的Apache Hadoop和Apache Spark服務,用於執行Hive和Spark-SQL作业。
- 數據集:三種不同大小的數據集(10GB、50GB、100GB),並含有混合數據類型。
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
測試查詢
- 簡單的SELECT查詢: 從表中基本收回所有列
- 過濾查詢: 带有WHERE子句的SELECT查詢以過濾特定行
- 聚合查詢: 涉及GROUP BY和像SUM、AVG等聚合函數的查詢..
- 連接查詢: Join two or more tables on a common key的查詢
結果與分析
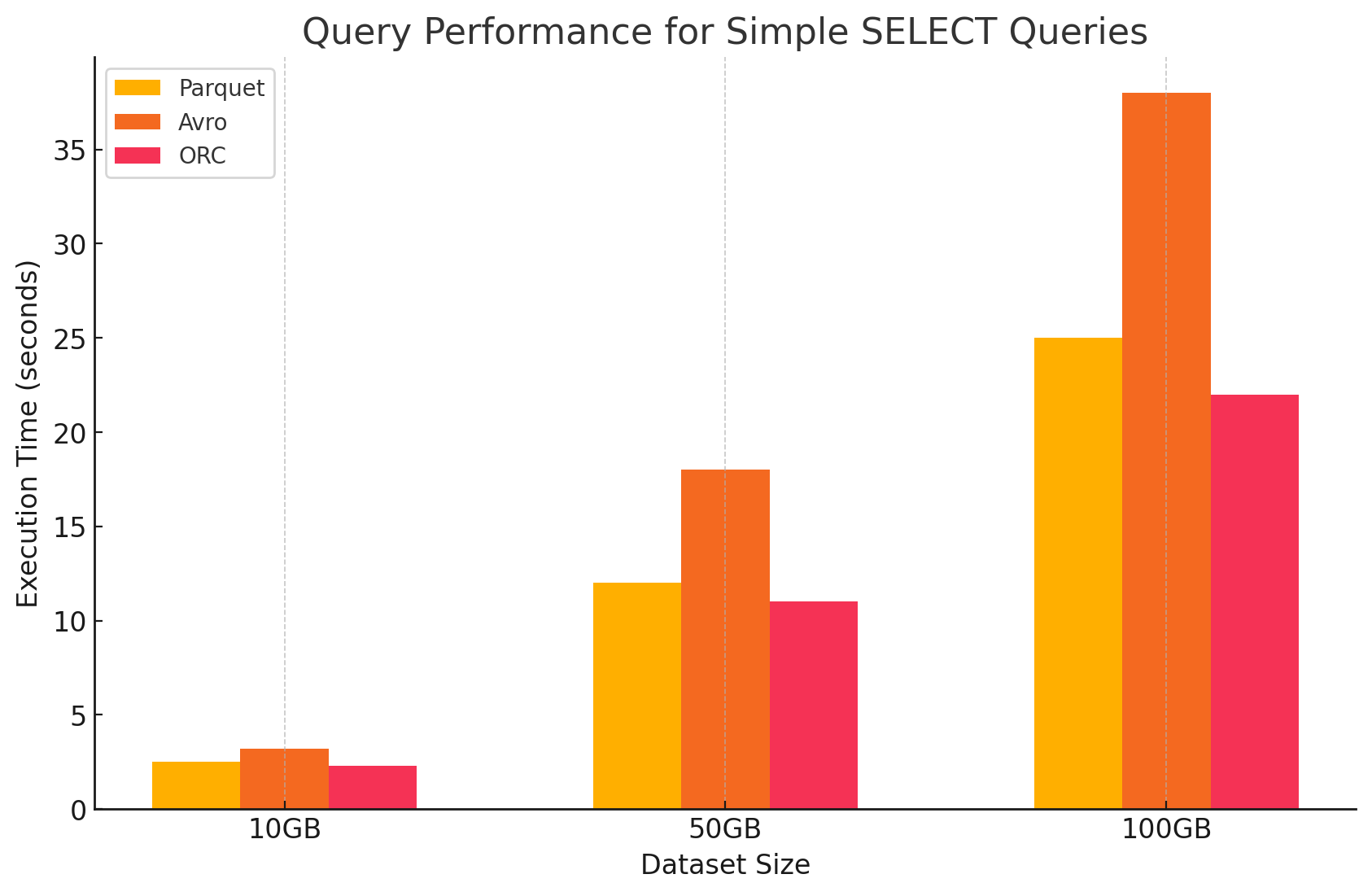
1. 簡單的SELECT查詢
- Parquet: 由於其列式存儲格式,它表现得非常出色,這使得可以快速扫瞄特定列。Parquet文件高度壓縮,減少從硬盤讀取的数据量,從而導致更快的查詢執行時間。
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro: Avro表现得中庸。作為行式格式,Avro需要讀取整個行,即使只需要特定列。這增加了I/O操作,導致與Parquet和ORC相比,查詢性能較慢。
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC: ORC的性能與Parquet相似,略有更好的壓縮和優化的存儲技術,從而提高讀取速度。ORC文件也是列式的,使它們適合於只收回特定列的SELECT查詢。
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
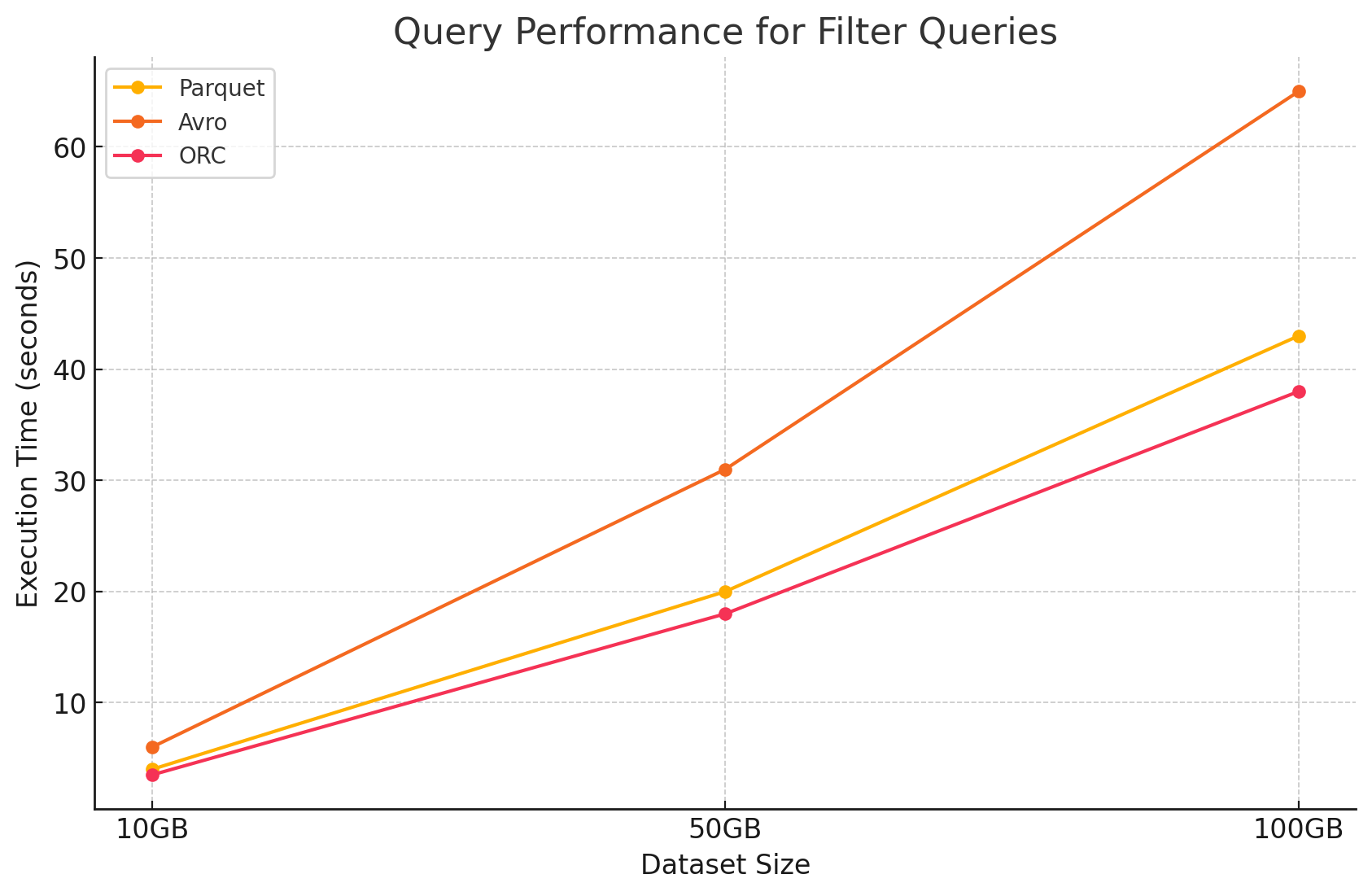
2. 過濾查詢
- Parquet: 由於其列式本質和快速跳過無關列的能力,Parquet保持了其性能优势。然而,由於需要扫瞄更多行以應用過濾器,性能略有影響。
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Avro:由於需要讀取整行並對所有列應用過濾器,性能進一步下降,增加了處理時間。
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ORC:由於其條件推送功能,ORC在過濾查詢中略微优于Parquet。此功能允許在數據被載入記憶體之前,直接在存儲層級上進行過濾。
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
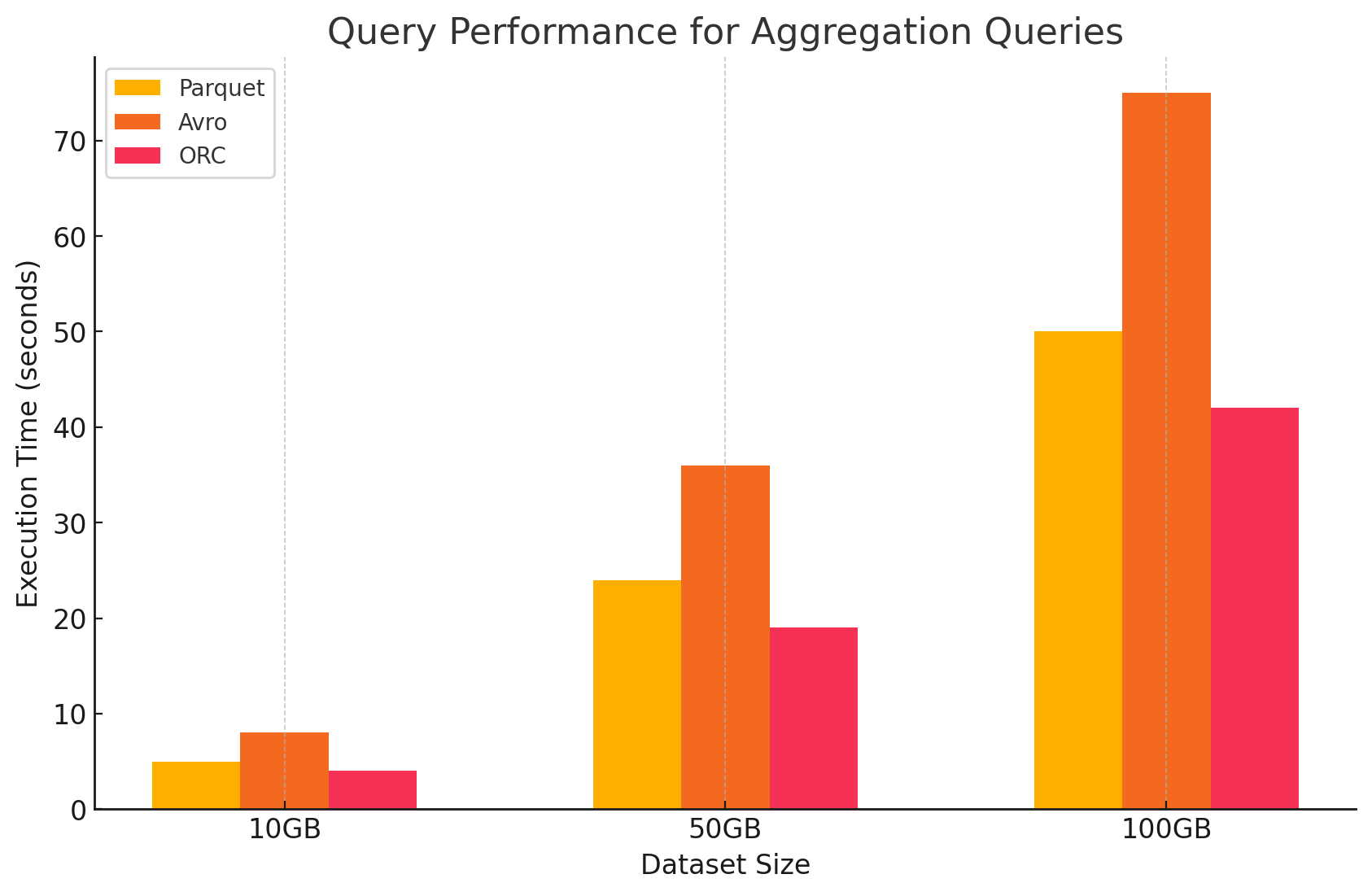
3. 聚合查询
- Parquet:Parquet表現良好,但效力略低於ORC。列式格式通過快速存取所需的列,有益於聚合操作,但Parquet缺乏ORC提供的某些內置優化。
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Avro:由於其基於行的存儲,每個行都需要掃瞄和處理所有列,增加了計算開銷,因此Avro落後。
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ORC:在聚合查询中,ORC超越了Parquet和Avro。ORC的進階索引和內置壓缩算法實現了更快的數據存取和減少I/O操作,使其非常適合聚合任務。
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
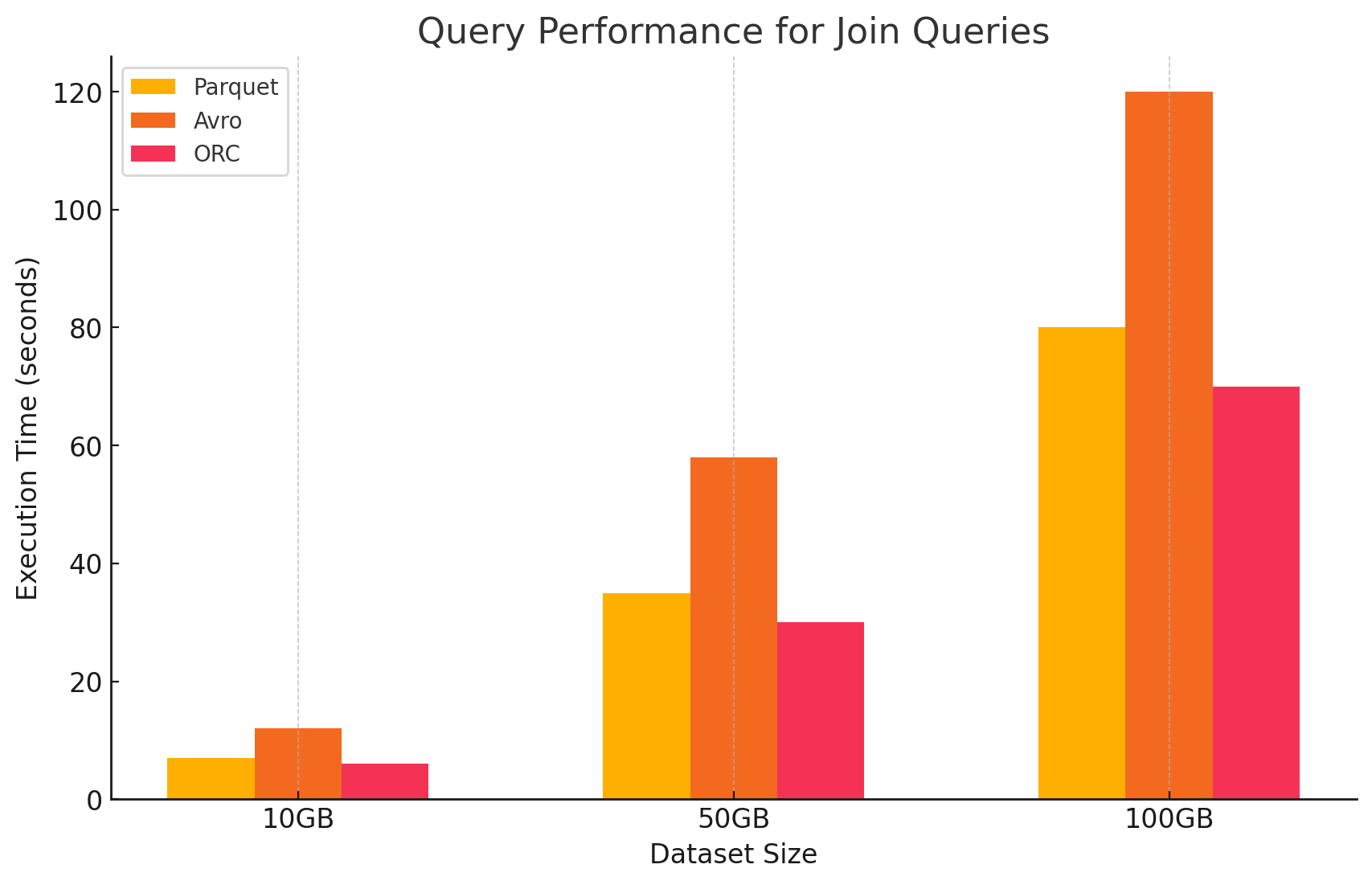
4. 连接查询
- Parquet:Parquet在连接操作中表現良好,但由於其對於連接條件的數據讀取較不優化,因此不如ORC高效。
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ORC:ORC在连接查询中表現出色,從進階索引和條件推送功能中受益,這者在連接操作中將扫瞄和處理的數據降到最低。
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Avro:Avro在联接操作上遇到了显著困难,主要是由于读取完整行的开销较大,以及对于联接键的列式优化不足。
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
存储格式對成本的影響
1. 存储效率和成本
- Parquet 和 ORC(列式格式)
- 压缩和存储成本:Parquet 和 ORC 都是列式存储格式,提供很高的压缩比率,尤其是对于列内有很多重复或相似值的 dataset。这种高压缩减少了整体数据大小,进而降低了存储成本,特别是在云环境中,存储是按 GB 计费的。
- 最适合分析工作負荷:由于它们的列式特性,这些格式非常适合分析工作負荷,其中只频繁查询特定列。这意味着从存储中读取的数据更少,从而减少了 I/O 操作和相关成本。
- Avro(列为基础格式)
- 壓縮和存儲成本:Avro的壓縮比例通常低於如Parquet和ORC的列式格式,因為它是按行存儲數據。對於含有大量列的大型數據集,這可能會導致更高的存儲成本,因為必須讀取一行中的所有數據,即使只需要其中幾列。
- 適合寫入密集型工作負荷:尽管Avro可能因為較低的壓縮而导致存儲成本上升,但它更適合寫入密集型工作負荷,在這些工作負荷中,數據持續地被寫入或追加。與此同時,數據序列化和反序列化的效率提升可能會抵消與存儲相關的成本。
2. 數據處理性能和成本
- Parquet 和 ORC(列式格式)
- 降低處理成本:這些格式針對讀取操作進行了優化,使其在查詢大型數據集時非常高效。由於它們允許只讀取查詢所需的相關列,減少了處理的數據量,從而降低了 CPU 使用率並加快了查詢執行時間。在雲端環境中,計算資源是按使用量計費的,這可以顯著降低計算成本。
- 成本優化的高級功能:尤其是 ORC,包含像謂詞下推和內建統計這樣的功能,使查詢引擎能夠跳過不必要的數據讀取,進一步減少 I/O 操作,加快查詢性能,優化成本。
- Avro(基於行的格式)
- 處理成本較高:由於Avro是基於行的格式,即使只需要少数欄位,讀取整個行通常也需要更多的I/O操作。這可能會導致因為CPU使用率提高和查詢執行時間延长而使得計算成本增加,特別是在讀取密集型的環境中。
- 適合串流和序列化:儘管對於查詢的處理成本較高,Avro對於串流和序列化任務來說非常適合,那裡快速寫入速度和架构演變更重要。
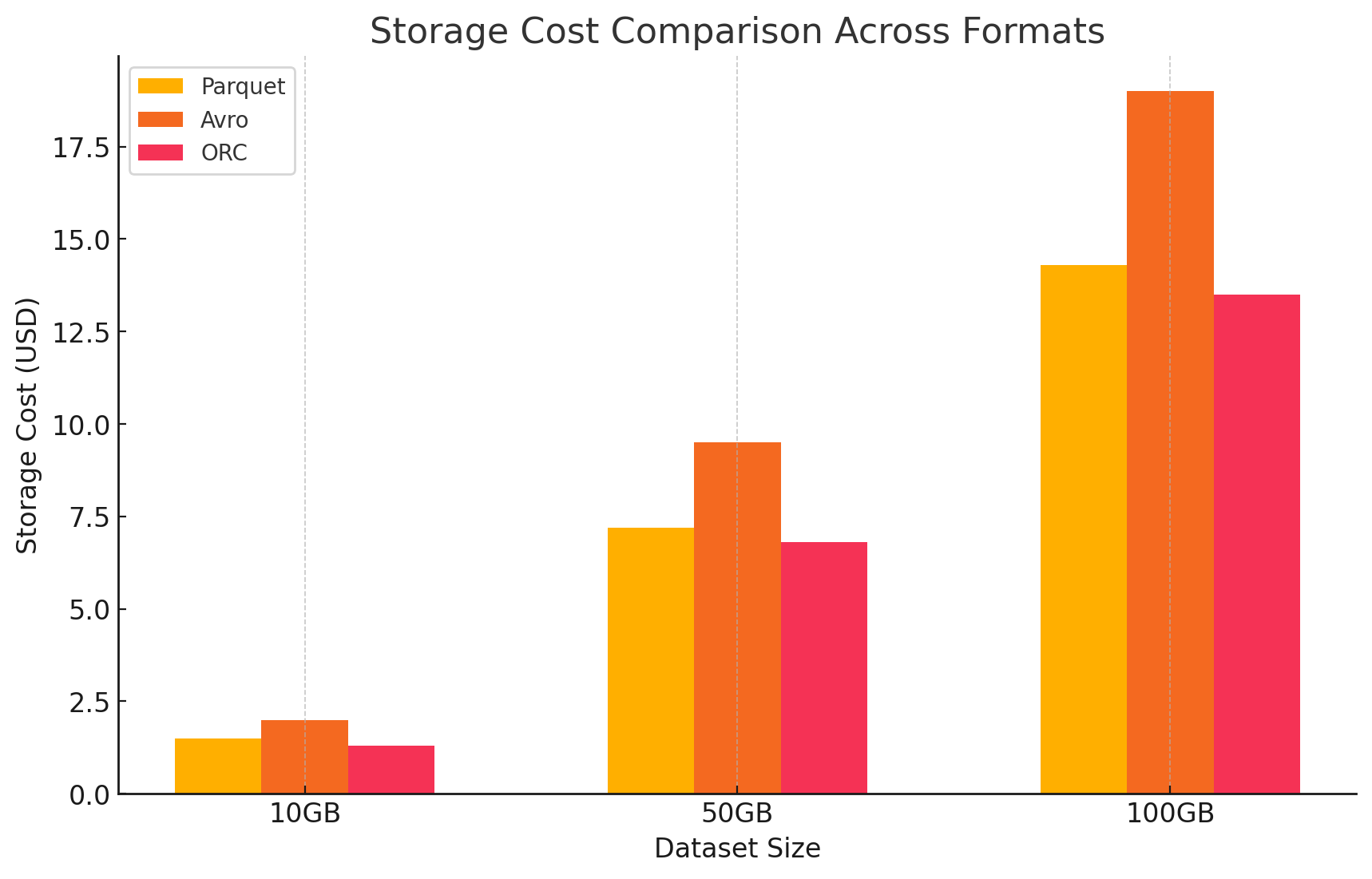
3. 成本分析與價格詳細信息
- 為了量化每種存儲格式對成本的影響,我們在GCP上進行了一項實驗。我們根據GCP的價格模型,對每種格式相關的存儲和數據處理成本進行計算。
- Google 云存儲成本
- 存儲成本: 这是根據每種格式存儲的數據量來計算的。GCP對於在Google 云存儲中存儲的數據,每個GB每月收取一次費用。每個格式實現的壓縮比率直接影響這些成本。如Parquet和ORC這類的列式格式通常比如Avro的行式格式有更好的壓縮比率,從而降低存儲成本。
- 以下是計算存儲成本的示例:
- Parquet: 高壓縮率導致數據量大為減少,從而降低存儲成本
- ORC: 與Parquet相似,ORC的先进壓縮也有效地降低了存儲成本
- Avro: 較低的壓縮效率導致與Parquet和ORC相比存儲成本較高
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
- 數據處理成本
- 數據處理成本是根據在GCP上使用Dataproc執行各種查詢所需的計算資源來計算的。GCP對Dataproc的 使用收取費用,這取決於集群的大小以及資源使用的持續時間。
- 計算成本:
- Parquet和ORC:由於它們具有高效的列式存儲,這些格式減少 了读取和處理的數據量,從而降低了計算成本。更快的查询执行时间也为节省成本做出了贡献,特別是對於涉及大量數據的复 杂查询。
- Avro:由于Avro采用的是行式格式,因此需要更多的計算資源,這增加了读取和處理的數據量。這导致了更高的成本,特别是在读取密集型操作中。
結論
大數據環境中儲存格式的選擇對查詢性能和成本有著顯著影響。上述研究與實驗展現以下關鍵點:
- Parquet 和 ORC:這些列式格式提供出色的壓縮,減少儲存成本。它们能夠有效僅讀取必要的列,大幅提高查詢性能和減少數據處理成本。由於 ORC 在某些查詢類型中由於其進階索引和優化功能而略优于 Parquet,因此對於需要高讀取和寫入性能的混合作業負荷,它是一個非常好的選擇。
- Avro: 雖然 Avro 在壓縮和查詢性能方面不如 Parquet 和 ORC 高效,但在需要快速寫入操作和結構演化的用例中表現出色。此格式適合於涉及數據序列化和串流的情況,其中寫入性能和靈活性比讀取效率更为重要。
- 成本效益: 在像 GCP 這樣的雲環境中,成本與儲存和計算使用 closely tied,選擇正確的格式可以導致顯著的成本節省。對於主要以讀取為主的分析作業負荷,Parquet 和 ORC 是最節省成本的選擇。對於需要快速數據吸入和靈活的結構管理應用程序,Avro 是一個適當的選擇,即使其儲存和計算成本較高。
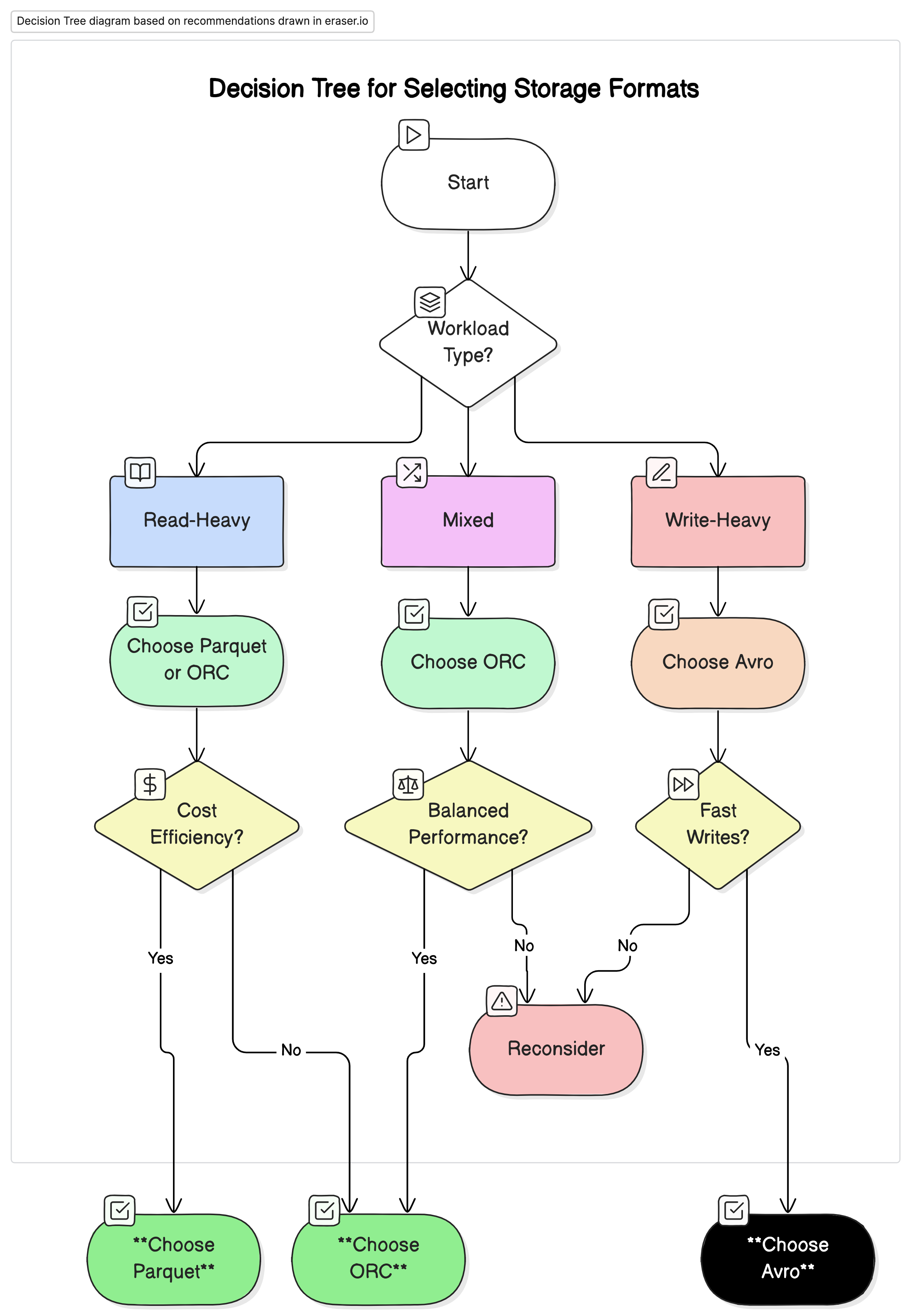
推荐
基於我們的分析,我們建議以下:
- 針對讀取密集型的分析工作負載:使用Parquet或ORC。 這些格式因其高壓縮和優化的查詢性能而提供優越的性能和成本效益。
- 針對寫入密集型的工作負載和序列化:使用Avro。它更適合於快速寫入和模式演進至關重要的情况,如數據流和消息系統。
- 對於混合工作負載:ORC為讀取和寫入操作提供了平衡的性能,使其成為數據工作負載多變環境的理想選擇。
最終思考
為大數據環境選擇正確的存儲格式對於優化性能和成本至關重要。了解每種格式的優勢和劣勢使數據工程師能夠針對特定使用案例定制他們的數據架構,從而最大化效率並最小化開支。隨著數據量的持續增長,關於存儲格式的明智決策將變得越來越重要,以保持可擴展和成本效益的數據解決方案。
通过仔細評估本文所呈現的性能基准測試和成本影響,組織可以選擇最适合其運作需求和財務目標的儲存格式。
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc